Auswählen Ihrer HA-Topologie
Es gibt verschiedene Möglichkeiten, die Hochverfügbarkeit von Datenbanken aufrechtzuerhalten. Sie können virtuelle IPs (VRRP) verwenden, um die Hostverfügbarkeit zu verwalten, Sie können Ressourcenmanager wie Zookeeper und Etcd verwenden, um Ihre Anwendungen (neu) zu konfigurieren, oder Load Balancer/Proxys verwenden, um die Arbeitslast auf alle verfügbaren Hosts zu verteilen.
Die virtuellen IPs benötigen entweder eine Anwendung, um sie zu verwalten (MHA, Orchestrator), einige Skripte (Keepalived, Pacemaker/Corosync) oder einen Techniker für ein manuelles Failover, und die Entscheidungsfindung in diesem Prozess kann komplex werden. Das virtuelle IP-Failover ist ein direkter und einfacher Prozess, bei dem die IP-Adresse von einem Host entfernt, einem anderen zugewiesen und mithilfe von Arping eine unentgeltliche ARP-Antwort gesendet wird. Theoretisch kann eine virtuelle IP innerhalb einer Sekunde verschoben werden, aber es dauert einige Sekunden, bis die Failover-Verwaltungsanwendung sicher ist, dass der Host ausgefallen ist, und entsprechend handelt. In Wirklichkeit sollte dies zwischen 10 und 30 Sekunden liegen. Eine weitere Einschränkung von virtuellen IPs besteht darin, dass einige Cloud-Anbieter Ihnen nicht erlauben, Ihre eigenen virtuellen IPs zu verwalten oder sie überhaupt zuzuweisen. Beispielsweise erlaubt Google dies nicht auf seinen Rechenknoten.
Ressourcenmanager wie Zookeeper und Etcd können Ihre Datenbanken überwachen und Ihre Anwendungen (neu) konfigurieren, sobald ein Host ausfällt oder ein Slave zum Master befördert wird. Im Allgemeinen ist dies eine gute Idee, aber die Implementierung Ihrer Überprüfungen mit Zookeeper und Etcd ist eine komplexe Aufgabe.
Ein Load Balancer oder Proxy sitzt zwischen der Anwendung und dem Datenbankhost und arbeitet transparent, als würde sich der Client direkt mit dem Datenbankhost verbinden. Genau wie bei den virtuellen IP- und Ressourcenmanagern müssen auch die Load Balancer und Proxys die Hosts überwachen und den Datenverkehr umleiten, wenn ein Host ausfällt. ClusterControl unterstützt zwei Proxys:HAProxy und ProxySQL, und beide werden für MySQL-Master-Slave-Replikation und Galera-Cluster unterstützt. HAProxy und ProxySQL haben beide ihre eigenen Anwendungsfälle, wir werden sie ebenfalls in diesem Beitrag beschreiben.
Warum brauchen Sie einen Load Balancer?
Theoretisch brauchen Sie keinen Load Balancer, aber in der Praxis werden Sie einen bevorzugen. Wir erklären warum.
Wenn Sie virtuelle IPs eingerichtet haben, müssen Sie Ihre Anwendung nur auf die richtige (virtuelle) IP-Adresse verweisen, und alles sollte in Bezug auf die Verbindung in Ordnung sein. Angenommen, Sie haben die Anzahl der Lesereplikate hochskaliert, möchten Sie möglicherweise aus Wartungs- oder Verfügbarkeitsgründen auch virtuelle IPs für jedes dieser Lesereplikate bereitstellen. Dies kann zu einem sehr großen Pool virtueller IPs werden, die Sie verwalten müssen. Wenn eine dieser Lesereplikate ausgefallen ist, müssen Sie die virtuelle IP einem anderen Host zuweisen, sonst verbindet sich Ihre Anwendung entweder mit einem ausgefallenen Host oder im schlimmsten Fall mit einem verzögerten Server mit veralteten Daten. Daher ist es erforderlich, den Replikationsstatus für die Anwendung beizubehalten, die die virtuellen IPs verwaltet.
Auch für Galera gibt es eine ähnliche Herausforderung:Sie können Ihrer Anwendungskonfiguration theoretisch so viele Hosts hinzufügen, wie Sie möchten, und einen zufällig auswählen. Das gleiche Problem tritt auf, wenn dieser Host ausfällt:Sie könnten am Ende eine Verbindung zu einem nicht verfügbaren Host herstellen. Auch die Verwendung aller Hosts sowohl für Lese- als auch für Schreibvorgänge kann aufgrund des optimistischen Sperrens in Galera zu Rollbacks führen. Wenn zwei Verbindungen gleichzeitig versuchen, in dieselbe Zeile zu schreiben, erhält eine von ihnen ein Rollback. Falls Ihr Workload über solche gleichzeitigen Updates verfügt, wird empfohlen, nur einen Knoten in Galera zum Schreiben zu verwenden. Daher möchten Sie einen Manager, der den internen Zustand Ihres Datenbank-Clusters verfolgt.
Sowohl HAProxy als auch ProxySQL bieten Ihnen die Funktionalität, die MySQL/MariaDB-Datenbankhosts zu überwachen und den Status Ihres Clusters und seiner Topologie zu halten. Für Replikations-Setups können sowohl HAProxy als auch ProxySQL die Verbindungen auf einen anderen Host umverteilen, falls eine Slave-Replik ausfällt. Aber wenn ein Replikations-Master ausgefallen ist, wird HAProxy die Verbindung verweigern und ProxySQL wird einen korrekten Fehler an den Client zurückgeben. Bei Galera-Setups können beide Load Balancer einen Master-Knoten aus dem Galera-Cluster auswählen und die Schreibvorgänge nur an diesen bestimmten Knoten senden.
An der Oberfläche scheinen HAProxy und ProxySQL ähnliche Lösungen zu sein, aber sie unterscheiden sich stark in den Funktionen und der Art und Weise, wie sie Verbindungen und Abfragen verteilen. HAProxy unterstützt eine Reihe von Ausgleichsalgorithmen wie Least Connections, Source, Random und Round-Robin, während ProxySQL Verbindungen mithilfe des gewichteten Round-Robin-Algorithmus verteilt (gleiches Gewicht bedeutet gleiche Verteilung). Da ProxySQL ein intelligenter Proxy ist, ist es datenbankbewusst und kann auch Ihre Abfragen analysieren. ProxySQL ist in der Lage, basierend auf Abfrageregeln eine Lese-/Schreibaufteilung durchzuführen, bei der Sie die Abfragen an die designierten Slaves oder Master in Ihrem Cluster weiterleiten können. ProxySQL enthält zusätzliche Funktionen wie das Umschreiben von Abfragen, Caching und eine Abfrage-Firewall mit detaillierter Echtzeit-Statistikerstellung über die Arbeitslast.
Das sollte genug Hintergrundinformationen zu diesem Thema sein, also sehen wir uns an, wie Sie sowohl Load Balancer für die MySQL-Replikation als auch Galera-Topologien bereitstellen können.
HAProxy bereitstellen
Die Verwendung von ClusterControl zur Bereitstellung von HAProxy auf einem Galera-Cluster ist einfach:Gehen Sie zum entsprechenden Cluster und wählen Sie „Load Balancer hinzufügen“:
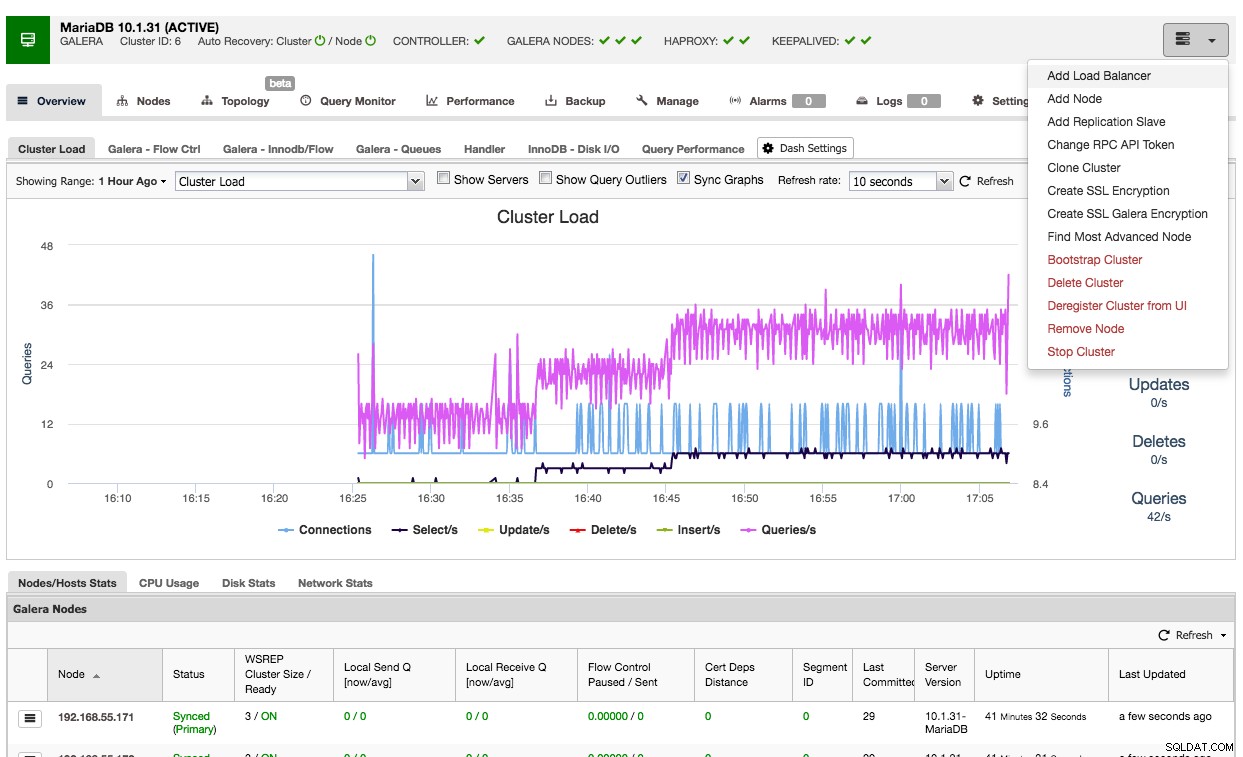
Und Sie können eine HAProxy-Instanz bereitstellen, indem Sie die Hostadresse hinzufügen und die Serverinstanzen auswählen, die Sie in die Konfiguration aufnehmen möchten:
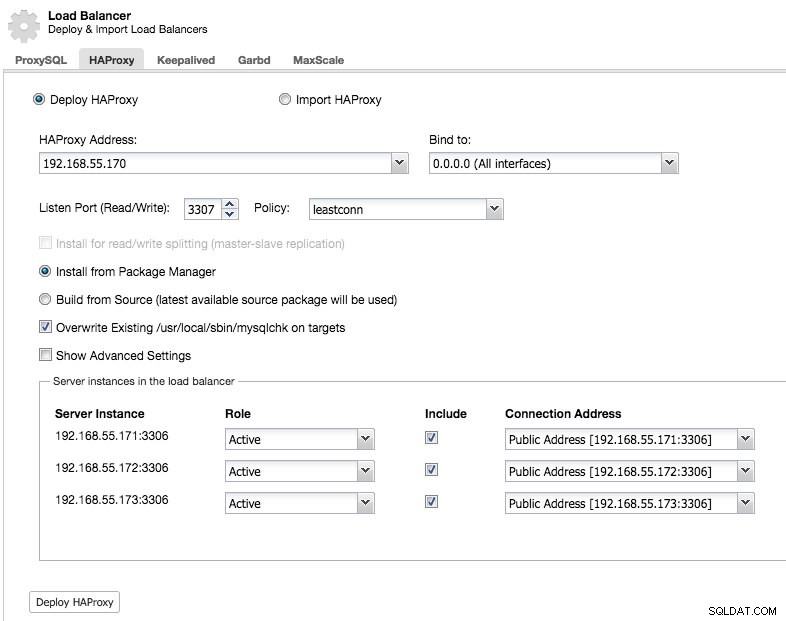
Standardmäßig wird die HAProxy-Instanz so konfiguriert, dass sie Verbindungen zu den Serverinstanzen sendet, die die wenigsten Verbindungen erhalten, aber Sie können diese Richtlinie entweder auf Round-Robin oder Quelle ändern.
Unter den erweiterten Einstellungen können Sie Timeouts und die maximale Anzahl an Verbindungen festlegen und sogar den Proxy sichern, indem Sie einen IP-Bereich für die Verbindungen auf die Whitelist setzen.
Unter der Registerkarte Knoten dieses Clusters erscheint der HAProxy-Knoten:
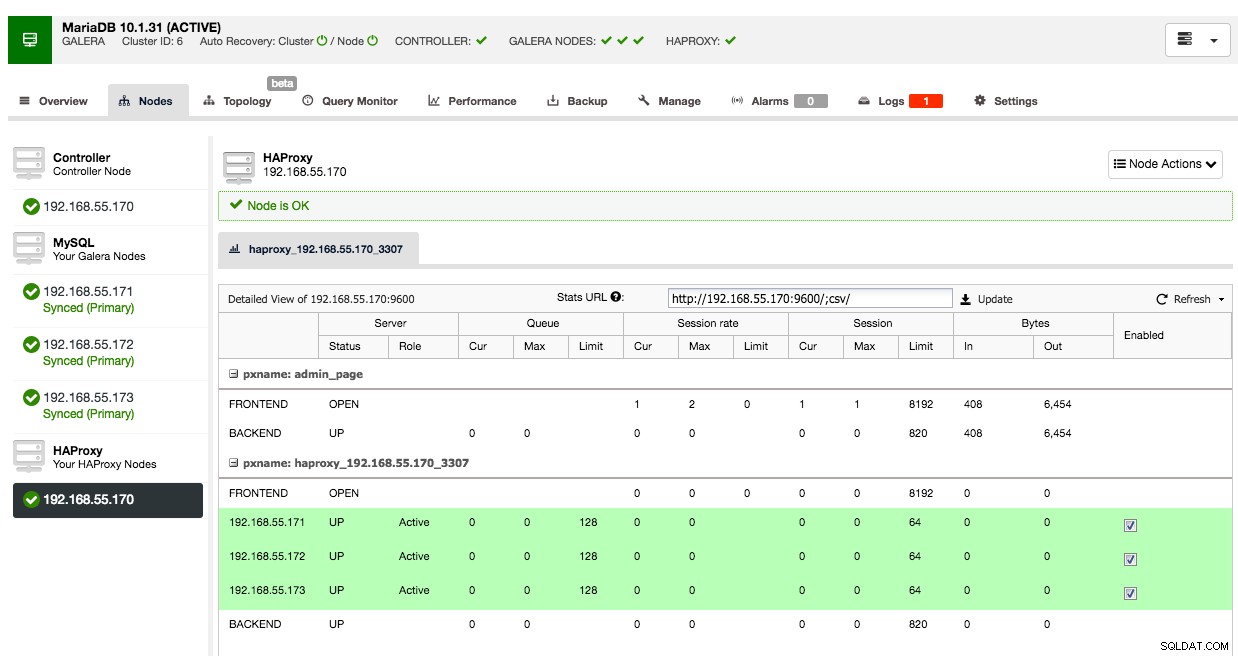
Jetzt ist Ihr Galera-Cluster auch über den neu bereitgestellten HAProxy-Knoten auf Port 3307 verfügbar. Vergessen Sie nicht, Ihrer Anwendung Zugriff von der HAProxy-IP zu GEWÄHREN, da der Datenverkehr jetzt vom Proxy statt von den Anwendungshosts eingeht. Denken Sie auch daran, Ihre Anwendungsverbindung auf den HAProxy-Knoten zu verweisen.
Angenommen, die eine Serverinstanz würde ausfallen, HAProxy wird dies innerhalb weniger Sekunden bemerken und aufhören, Datenverkehr an diese Instanz zu senden:
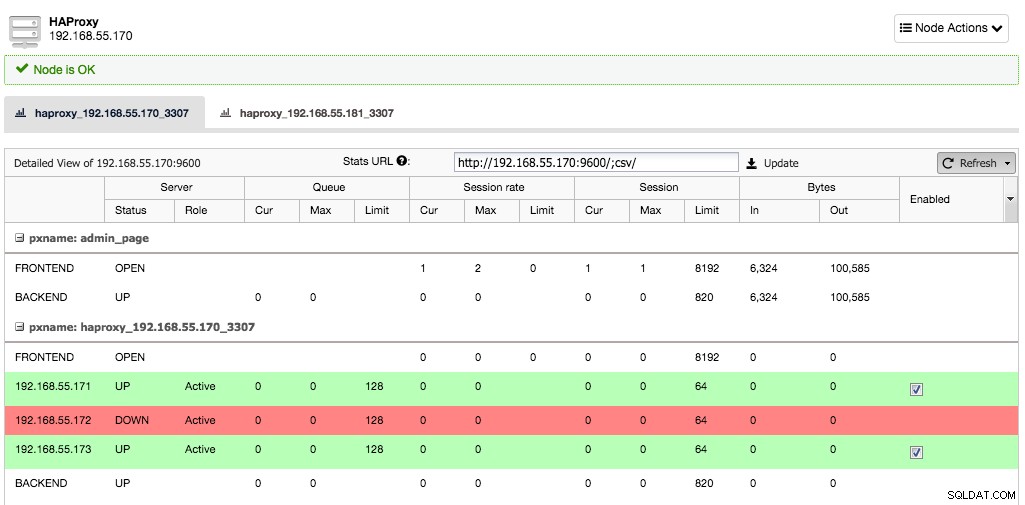
Die beiden anderen Knoten sind immer noch in Ordnung und werden weiterhin Datenverkehr empfangen. Dadurch bleibt der Cluster hochverfügbar, ohne dass der Client den Unterschied überhaupt bemerkt.
Bereitstellen eines sekundären HAProxy-Knotens
Nun, da wir die Verantwortung für die Aufrechterhaltung der Hochverfügbarkeit über die Datenbankverbindungen vom Client auf HAProxy verlagert haben, was passiert, wenn der Proxy-Knoten stirbt? Die Antwort ist, eine weitere HAProxy-Instanz zu erstellen und eine virtuelle IP zu verwenden, die von Keepalived gesteuert wird, wie in diesem Diagramm gezeigt:
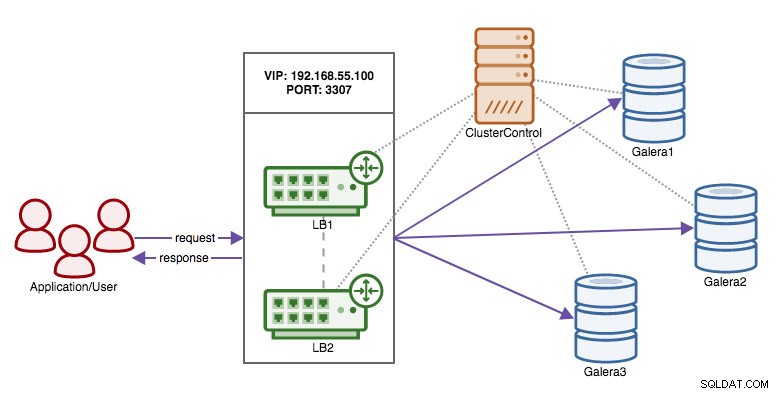
Der Vorteil gegenüber der Verwendung virtueller IPs auf den Datenbankknoten besteht darin, dass sich die Logik für MySQL auf der Proxy-Ebene befindet und das Failover für die Proxys einfach ist.
Stellen wir also einen sekundären HAProxy-Knoten bereit:
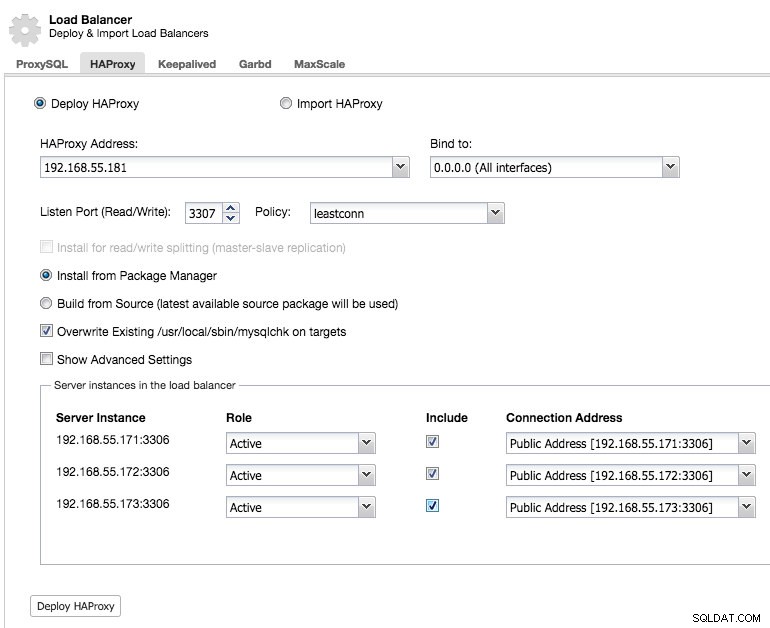
Nachdem wir einen sekundären HAProxy-Knoten bereitgestellt haben, müssen wir Keepalived:
hinzufügen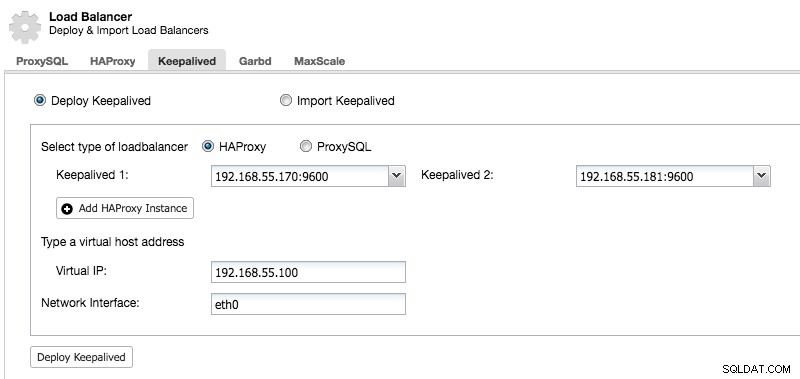
Und nachdem Keepalived hinzugefügt wurde, sieht Ihre Knotenübersicht so aus:
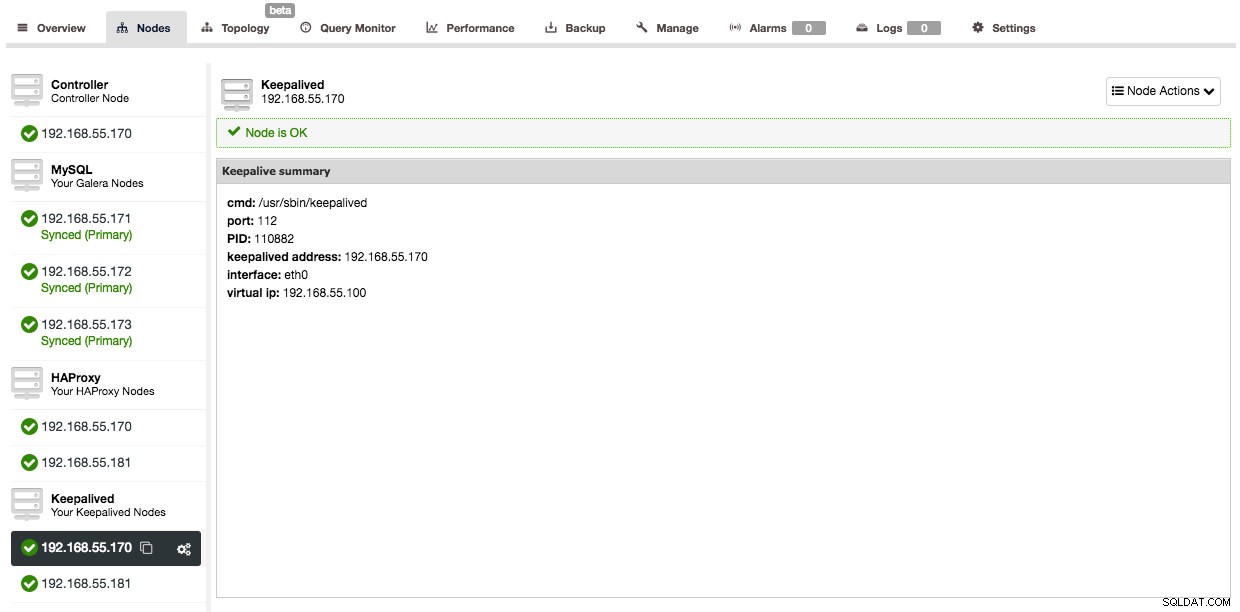
Anstatt also Ihre Anwendungsverbindungen direkt auf den HAProxy-Knoten zu verweisen, müssen Sie sie stattdessen auf die virtuelle IP verweisen.
In diesem Beispiel haben wir separate Hosts verwendet, auf denen HAProxy ausgeführt wird, aber Sie könnten sie auch problemlos zu vorhandenen Serverinstanzen hinzufügen. HAProxy bringt nicht viel Overhead, obwohl Sie bedenken sollten, dass Sie im Falle eines Serverausfalls sowohl den Datenbankknoten als auch den Proxy verlieren.
Bereitstellen von ProxySQL
Die Bereitstellung von ProxySQL in Ihrem Cluster erfolgt ähnlich wie bei HAProxy:„Load Balancer hinzufügen“ in der Clusterliste auf der Registerkarte „ProxySQL“.
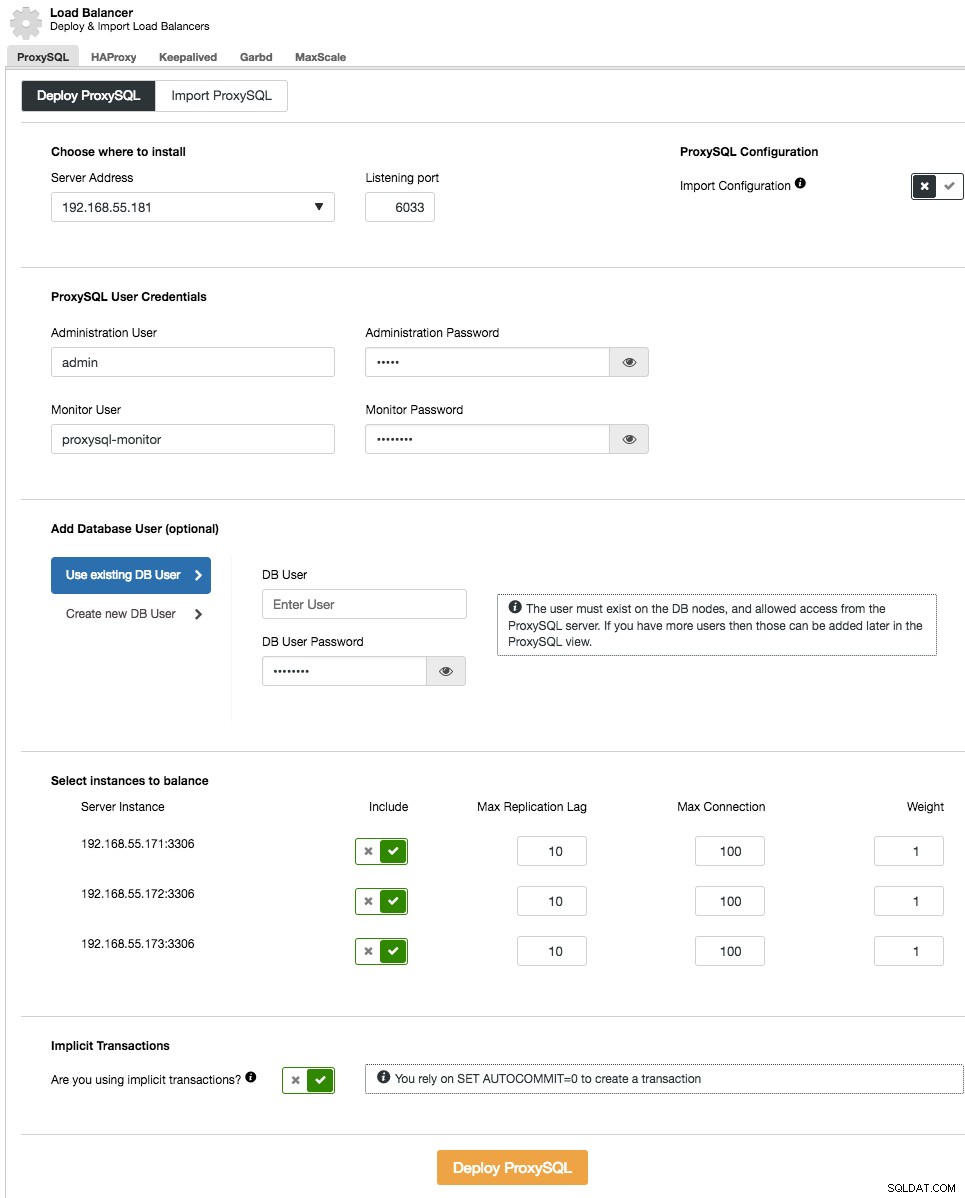
Geben Sie im Bereitstellungsassistenten an, wo ProxySQL installiert werden soll, den Benutzer/das Kennwort für die Verwaltung, den Benutzer/das Kennwort für die Überwachung, um eine Verbindung zu den MySQL-Backends herzustellen. Von ClusterControl aus können Sie entweder einen neuen Benutzer erstellen, der von der Anwendung verwendet werden soll (der Benutzer wird sowohl auf MySQL als auch auf ProxySQL erstellt) oder die vorhandenen Datenbankbenutzer verwenden (der Benutzer wird nur auf ProxySQL erstellt). Legen Sie fest, ob Sie implizite Transaktionen verwenden oder nicht. Wenn Sie SET autocommit=0 nicht verwenden, um eine neue Transaktion zu erstellen, konfiguriert ClusterControl grundsätzlich die Lese-/Schreibaufteilung.
Nachdem ProxySQL bereitgestellt wurde, ist es auf der Registerkarte „Knoten“ verfügbar:
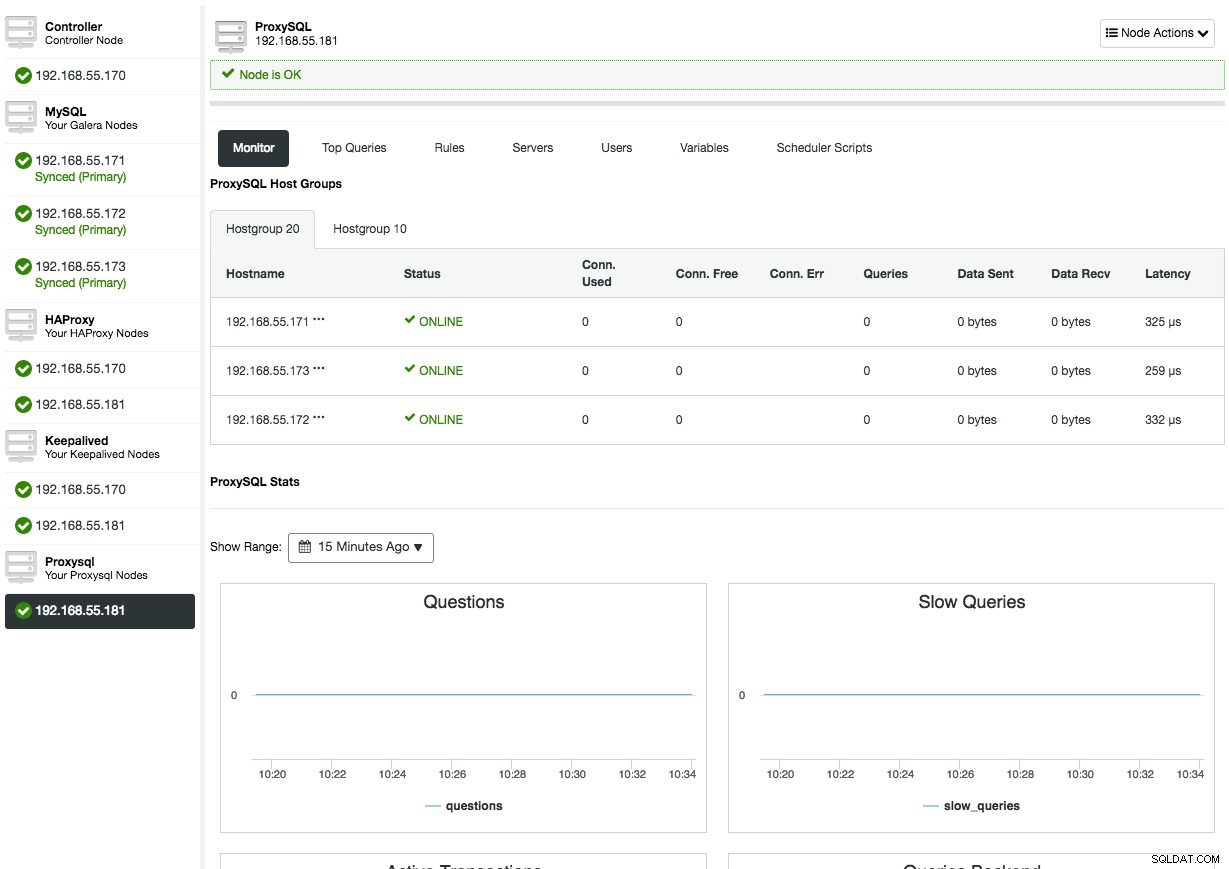
Wenn Sie die ProxySQL-Knotenübersicht öffnen, wird Ihnen die ProxySQL-Überwachungs- und Verwaltungsschnittstelle angezeigt, sodass es keinen Grund mehr gibt, sich bei ProxySQL auf dem Knoten anzumelden. ClusterControl deckt die meisten wichtigen ProxySQL-Statistiken wie Speichernutzung, Abfrage-Cache, Abfrageprozessor usw. sowie andere Metriken wie Hostgruppen, Backend-Server, Abfrageregeltreffer, Top-Abfragen und ProxySQL-Variablen ab. Bei der ProxySQL-Verwaltung können Sie Abfrageregeln, Backend-Server, Benutzer, Konfiguration und Planer direkt über die Benutzeroberfläche verwalten.
Sehen Sie sich unsere ProxySQL-Tutorial-Seite an, die ausführlich behandelt, wie Sie Datenbanklastenausgleich für MySQL und MariaDB mit ProxySQL durchführen.
Bereitstellen von Garbd
Galera implementiert einen Quorum-basierten Algorithmus, um eine primäre Komponente auszuwählen, durch die es Konsistenz erzwingt. Die primäre Komponente muss eine Mehrheit der Stimmen haben (50 % + 1 Knoten), sodass es in einem 2-Knoten-System keine Mehrheit geben würde, was zu einem Split Brain führen würde. Glücklicherweise ist es möglich, einen garbd (Galera Arbitrator Daemon) hinzuzufügen, einen leichtgewichtigen zustandslosen Daemon, der als ungerader Knoten fungieren kann. Der zusätzliche Vorteil durch das Hinzufügen des Galera Arbitrator besteht darin, dass Sie jetzt mit nur zwei Knoten in Ihrem Cluster auskommen.
Wenn ClusterControl feststellt, dass Ihr Galera-Cluster aus einer geraden Anzahl von Knoten besteht, erhalten Sie von ClusterControl die Warnung/den Hinweis, den Cluster auf eine ungerade Anzahl von Knoten zu erweitern:
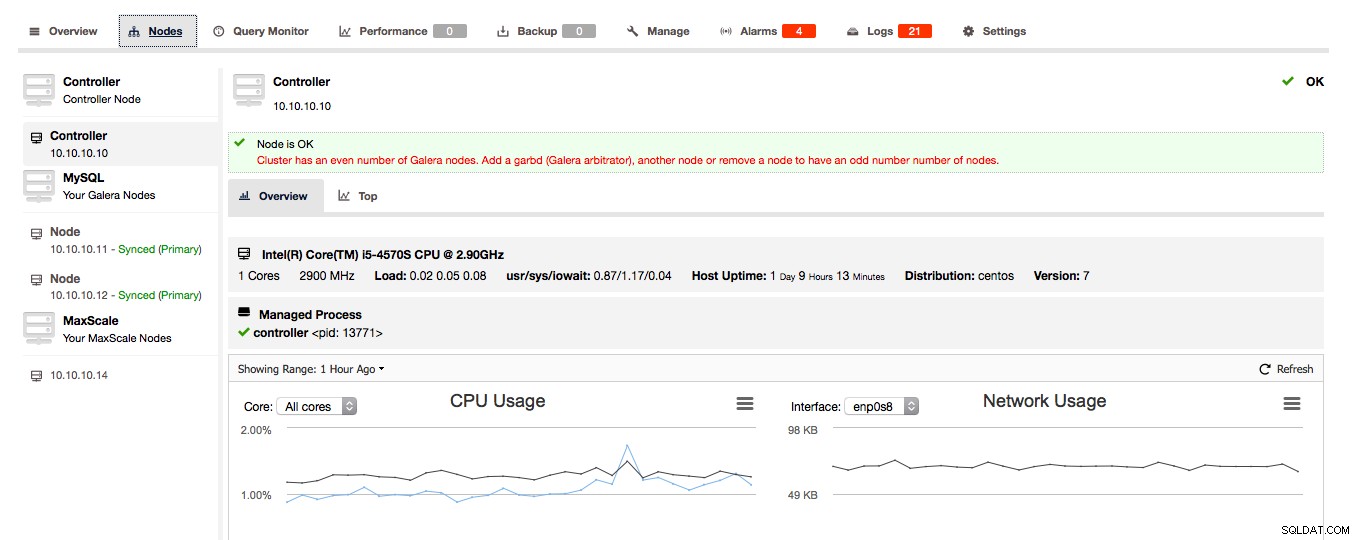
Wählen Sie den Host, auf dem garbd bereitgestellt werden soll, mit Bedacht aus, da er alle replizierten Daten erhält. Stellen Sie sicher, dass das Netzwerk den Datenverkehr verarbeiten kann und sicher genug ist. Sie können einen der HAProxy- oder ProxySQL-Hosts auswählen, auf dem garbd bereitgestellt wird, wie im folgenden Beispiel:
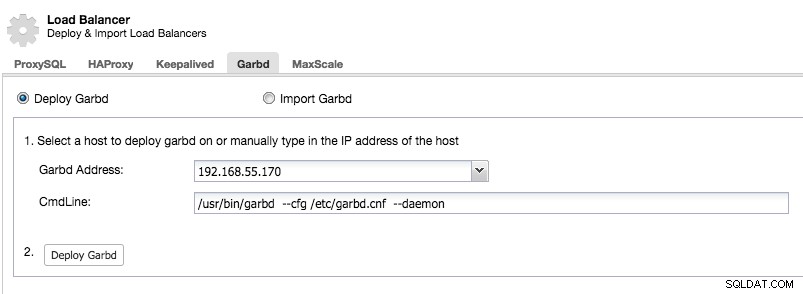
Beachten Sie, dass ab ClusterControl 1.5.1 garbd aufgrund des Risikos von Paketkonflikten nicht auf demselben Host wie ClusterControl installiert werden kann.
Nach der Installation von garbd erscheint es neben Ihren beiden Galera-Knoten:

Abschließende Gedanken
Wir haben Ihnen gezeigt, wie Sie Ihre MySQL-Master-Slave- und Galera-Cluster-Setups robuster machen und mit HAProxy und ProxySQL eine hohe Verfügbarkeit beibehalten können. Garbd ist auch ein netter Daemon, der den zusätzlichen dritten Knoten in Ihrem Galera-Cluster speichern kann.
Damit ist die Bereitstellungsseite von ClusterControl abgeschlossen. In unserem nächsten Blog zeigen wir Ihnen, wie Sie ClusterControl in Ihre Organisation integrieren können, indem Sie Gruppen verwenden und Benutzern bestimmte Rollen zuweisen.