Bevor Sie versuchen, Schemaänderungen an Ihren Produktionsdatenbanken vorzunehmen, sollten Sie sicherstellen, dass Sie über einen soliden Rollback-Plan verfügen. und dass Ihr Änderungsverfahren in einer separaten Umgebung erfolgreich getestet und validiert wurde. Gleichzeitig liegt es in Ihrer Verantwortung, sicherzustellen, dass die Änderung keine oder die geringstmöglichen Auswirkungen hat, die für das Unternehmen akzeptabel sind. Es ist definitiv keine leichte Aufgabe.
In diesem Artikel werfen wir einen Blick darauf, wie Datenbankänderungen auf MySQL und MariaDB kontrolliert durchgeführt werden können. Wir werden über einige gute Gewohnheiten in Ihrer täglichen DBA-Arbeit sprechen. Wir konzentrieren uns auf Voraussetzungen und Aufgaben während des eigentlichen Betriebs und auf Probleme, denen Sie möglicherweise gegenüberstehen, wenn Sie sich mit Änderungen des Datenbankschemas befassen. Wir werden auch über Open-Source-Tools sprechen, die Ihnen dabei helfen können.
Test- und Rollback-Szenarien
Sicherung
Es gibt viele Möglichkeiten, Ihre Daten zu verlieren. Schema-Upgrade-Fehler ist einer davon. Im Gegensatz zu Anwendungscode können Sie kein Bündel von Dateien löschen und erklären, dass eine neue Version erfolgreich bereitgestellt wurde. Sie können auch nicht einfach einen älteren Satz von Dateien zurücksetzen, um Ihre Änderungen rückgängig zu machen. Natürlich können Sie ein anderes SQL-Skript ausführen, um die Datenbank erneut zu ändern, aber es gibt Fälle, in denen die einzige genaue Methode zum Zurücksetzen von Änderungen darin besteht, die gesamte Datenbank aus einer Sicherung wiederherzustellen.
Was ist jedoch, wenn Sie es sich nicht leisten können, Ihre Datenbank auf die neueste Sicherung zurückzusetzen, oder Ihr Wartungsfenster nicht groß genug ist (unter Berücksichtigung der Systemleistung), sodass Sie vor der Änderung keine vollständige Datenbanksicherung durchführen können?
Man mag eine ausgeklügelte, redundante Umgebung haben, aber solange Daten sowohl an primären als auch an Standby-Standorten geändert werden, gibt es nicht viel zu tun. Viele Skripte können nur einmal ausgeführt werden, oder die Änderungen können nicht rückgängig gemacht werden. Der größte Teil des SQL-Änderungscodes fällt in zwei Gruppen:
- Einmal ausführen – Sie können dieselbe Spalte nicht zweimal zur Tabelle hinzufügen.
- Kann nicht rückgängig gemacht werden – sobald Sie diese Spalte abgelegt haben, ist sie weg. Sie könnten Ihre Datenbank zweifellos wiederherstellen, aber das ist nicht gerade ein Rückgängigmachen.
Sie können dieses Problem auf mindestens zwei mögliche Arten angehen. Eine wäre, das Binärlog zu aktivieren und ein Backup zu erstellen, das mit PITR kompatibel ist. Eine solche Sicherung muss vollständig, vollständig und konsistent sein. Für xtrabackup ist es PITR-kompatibel, solange es einen vollständigen Datensatz enthält. Für mysqldump gibt es eine Option, um es auch PITR-kompatibel zu machen. Bei kleineren Änderungen würde eine Variation von mysqldump backup darin bestehen, nur eine Teilmenge der zu ändernden Daten zu übernehmen. Dies kann mit der Option --where erfolgen. Das Backup sollte Teil der geplanten Wartung sein.
mysqldump -u -p --lock-all-tables --where="WHERE employee_id=100" mydb employees> backup_table_tmp_change_07132018.sqlEine andere Möglichkeit ist die Verwendung von CREATE TABLE AS SELECT.
Sie können Daten oder einfache Strukturänderungen in Form einer festen temporären Tabelle speichern. Mit diesem Ansatz erhalten Sie eine Quelle, wenn Sie Ihre Änderungen rückgängig machen müssen. Es kann sehr praktisch sein, wenn Sie nicht viele Daten ändern. Das Rollback kann durchgeführt werden, indem Daten daraus entnommen werden. Wenn beim Kopieren der Daten in die Tabelle Fehler auftreten, wird sie automatisch gelöscht und nicht erstellt. Stellen Sie also sicher, dass Ihre Anweisung eine Kopie erstellt, die Sie benötigen.
Natürlich gibt es auch einige Einschränkungen.
Da die Reihenfolge der Zeilen in den zugrunde liegenden SELECT-Anweisungen nicht immer bestimmt werden kann, werden CREATE TABLE ... IGNORE SELECT und CREATE TABLE ... REPLACE SELECT als unsicher für die anweisungsbasierte Replikation gekennzeichnet. Solche Anweisungen erzeugen eine Warnung im Fehlerprotokoll, wenn der anweisungsbasierte Modus verwendet wird, und werden im zeilenbasierten Format in das Binärprotokoll geschrieben, wenn der MIXED-Modus verwendet wird.
Ein sehr einfaches Beispiel einer solchen Methode könnte sein:
CREATE TABLE tmp_employees_change_07132018 AS SELECT * FROM employees where employee_id=100;
UPDATE employees SET salary=120000 WHERE employee_id=100;
COMMMIT;Eine weitere interessante Option könnte die Flashback-Datenbank MariaDB sein. Wenn ein falsches Update oder Löschen passiert und Sie zu einem bestimmten Zeitpunkt zu einem Zustand der Datenbank (oder nur einer Tabelle) zurückkehren möchten, können Sie die Flashback-Funktion verwenden.
Point-in-Time-Rollback ermöglicht DBAs eine schnellere Wiederherstellung von Daten, indem Transaktionen auf einen früheren Zeitpunkt zurückgesetzt werden, anstatt eine Wiederherstellung aus einem Backup durchzuführen. Basierend auf ROW-basierten DML-Ereignissen kann Flashback das Binärlog transformieren und Zwecke umkehren. Das bedeutet, dass es helfen kann, bestimmte Zeilenänderungen schnell rückgängig zu machen. Beispielsweise kann es DELETE-Ereignisse in INSERTs ändern und umgekehrt, und es wird WHERE- und SET-Teile der UPDATE-Ereignisse vertauschen. Diese einfache Idee kann die Wiederherstellung nach bestimmten Arten von Fehlern oder Katastrophen erheblich beschleunigen. Für diejenigen, die mit der Oracle-Datenbank vertraut sind, ist dies eine bekannte Funktion. Die Einschränkung von MariaDB-Flashback ist die fehlende DDL-Unterstützung.
Erstellen Sie einen verzögerten Replikations-Slave
Seit Version 5.6 unterstützt MySQL die verzögerte Replikation. Ein Slave-Server kann dem Master um mindestens eine bestimmte Zeitspanne hinterherhinken. Die Standardverzögerung beträgt 0 Sekunden. Verwenden Sie die Option MASTER_DELAY für CHANGE MASTER TO, um die Verzögerung auf N Sekunden einzustellen:
CHANGE MASTER TO MASTER_DELAY = N;Es wäre eine gute Option, wenn Sie keine Zeit hätten, ein geeignetes Wiederherstellungsszenario vorzubereiten. Sie müssen genügend Verzögerung haben, um die problematische Änderung zu bemerken. Der Vorteil dieses Ansatzes besteht darin, dass Sie Ihre Datenbank nicht wiederherstellen müssen, um Daten zu entfernen, die zum Beheben Ihrer Änderung erforderlich sind. Die Standby-DB ist betriebsbereit und bereit, Daten aufzunehmen, was die benötigte Zeit minimiert.
Erstellen Sie einen asynchronen Slave, der nicht Teil des Clusters ist
Beim Galera-Cluster ist das Testen von Änderungen nicht einfach. Alle Knoten führen dieselben Daten aus, und eine hohe Last kann die Flusssteuerung beeinträchtigen. Sie müssen also nicht nur prüfen, ob die Änderungen erfolgreich angewendet wurden, sondern auch, welche Auswirkungen sie auf den Clusterstatus hatten. Um Ihr Testverfahren so nah wie möglich an der Produktionsauslastung zu gestalten, möchten Sie möglicherweise einen asynchronen Slave zu Ihrem Cluster hinzufügen und Ihren Test dort ausführen. Der Test wirkt sich nicht auf die Synchronisierung zwischen Cluster-Knoten aus, da er technisch gesehen nicht Teil des Clusters ist, aber Sie haben die Möglichkeit, ihn mit echten Daten zu überprüfen. Ein solcher Slave kann einfach von ClusterControl hinzugefügt werden.
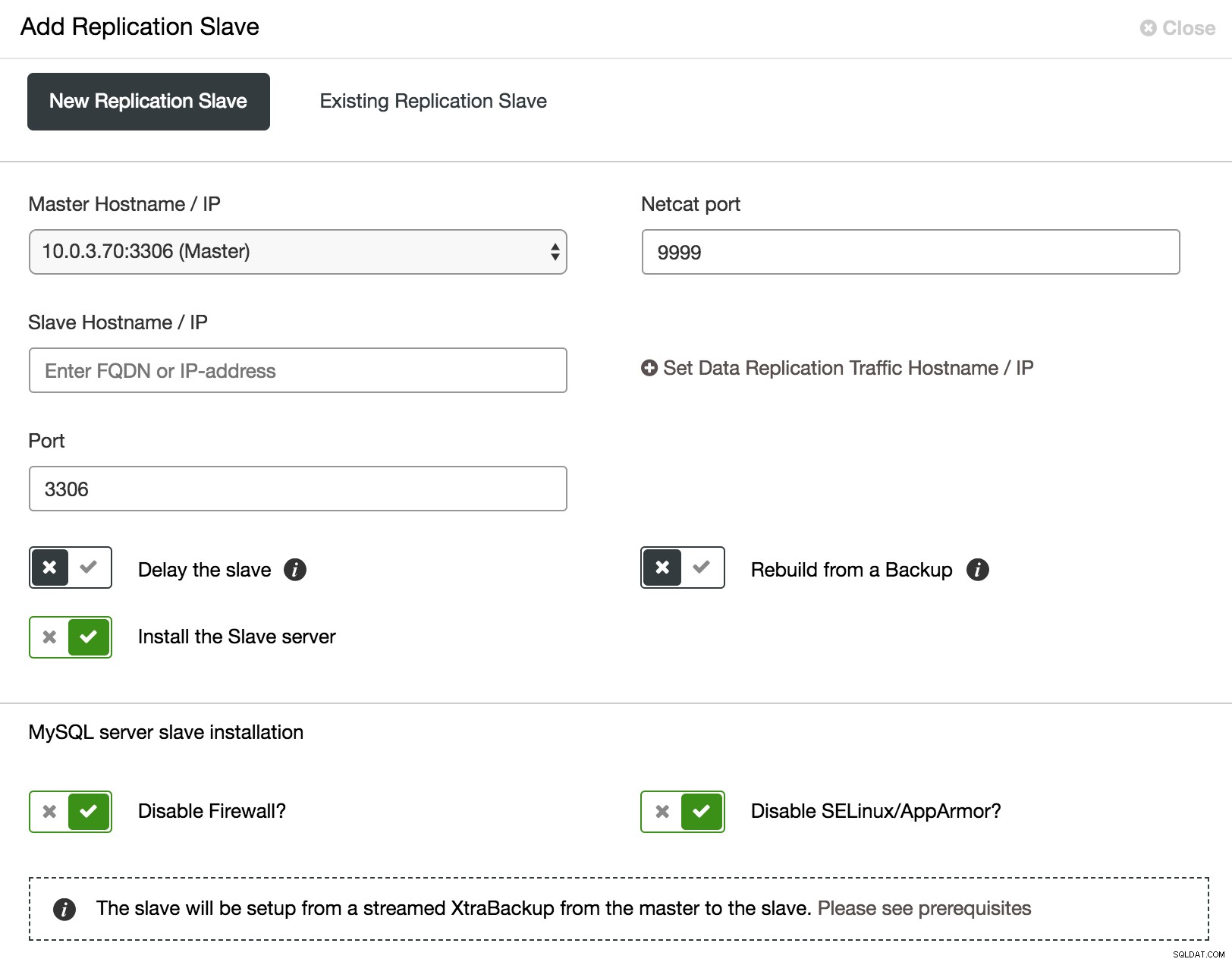 ClusterControl fügt asynchronen Slave hinzu
ClusterControl fügt asynchronen Slave hinzu Wie im obigen Screenshot gezeigt, kann ClusterControl den Vorgang des Hinzufügens eines asynchronen Slaves auf verschiedene Arten automatisieren. Sie können den Knoten zum Cluster hinzufügen, den Slave verzögern. Um die Auswirkungen auf den Master zu reduzieren, können Sie beim Erstellen des Slaves anstelle des Masters ein vorhandenes Backup als Datenquelle verwenden.
Datenbank klonen und Zeit messen
Ein guter Test sollte so nah wie möglich am Produktionswechsel sein. Am besten klonen Sie dazu Ihre bestehende Umgebung.
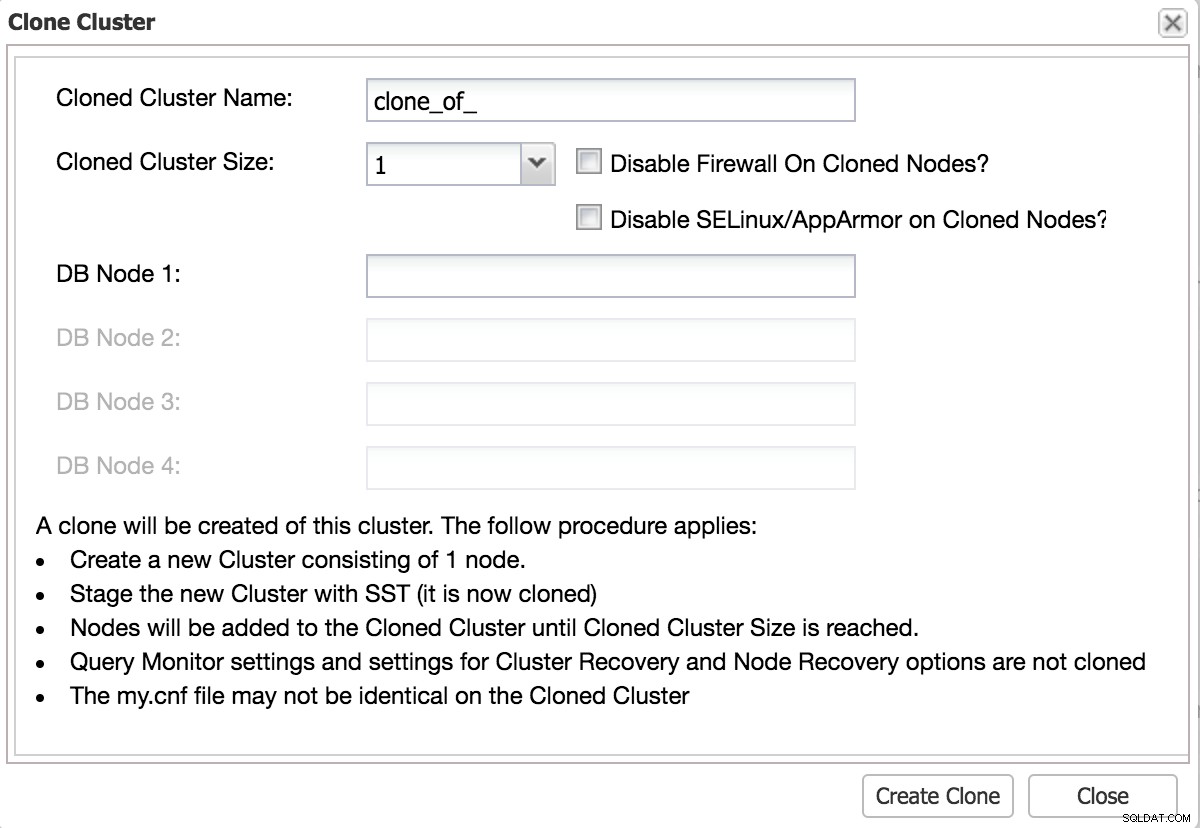 ClusterControl Clone-Cluster zum Testen
ClusterControl Clone-Cluster zum Testen Änderungen per Replikation durchführen
Um Ihre Änderungen besser kontrollieren zu können, können Sie sie vorab auf einem Slave-Server anwenden und dann die Umstellung vornehmen. Bei der anweisungsbasierten Replikation funktioniert dies gut, bei der zeilenbasierten Replikation kann dies jedoch bis zu einem gewissen Grad funktionieren. Die zeilenbasierte Replikation ermöglicht das Vorhandensein zusätzlicher Spalten am Ende der Tabelle, so dass sie in Ordnung ist, solange sie die ersten Spalten schreiben kann. Wenden Sie diese Einstellung zuerst auf alle Slaves an, führen Sie dann ein Failover auf einen der Slaves durch und implementieren Sie dann die Änderung auf den Master und hängen Sie diesen als Slave an. Wenn Ihre Änderung das Einfügen oder Entfernen einer Spalte in der Mitte der Tabelle beinhaltet, funktioniert sie mit zeilenbasierter Replikation.
Betrieb
Während des Wartungsfensters möchten wir keinen Anwendungsdatenverkehr in der Datenbank haben. Manchmal ist es schwierig, alle über das gesamte Unternehmen verteilten Anwendungen herunterzufahren. Alternativ möchten wir nur einigen bestimmten Hosts erlauben, remote auf MySQL zuzugreifen (z. B. das Überwachungssystem oder der Backup-Server). Zu diesem Zweck können wir die Linux-Paketfilterung verwenden. Um zu sehen, welche Paketfilterregeln verfügbar sind, können wir den folgenden Befehl ausführen:
iptables -L INPUT -vUm den MySQL-Port auf allen Schnittstellen zu schließen, verwenden wir:
iptables -A INPUT -p tcp --dport mysql -j DROPund um den MySQL-Port nach dem Wartungsfenster wieder zu öffnen:
iptables -D INPUT -p tcp --dport mysql -j DROPFür diejenigen ohne Root-Zugriff können Sie max_connection auf 1 ändern oder das Netzwerk überspringen.
Protokollierung
Um den Protokollierungsprozess zu starten, verwenden Sie den tee-Befehl an der MySQL-Client-Eingabeaufforderung wie folgt:
mysql> tee /tmp/my.out;Dieser Befehl weist MySQL an, sowohl die Eingabe als auch die Ausgabe Ihrer aktuellen MySQL-Anmeldesitzung in einer Datei namens /tmp/my.out zu protokollieren. Führen Sie dann Ihre Skriptdatei mit dem Quellbefehl aus.
Um eine bessere Vorstellung von Ihren Ausführungszeiten zu bekommen, können Sie es mit der Profiler-Funktion kombinieren. Starten Sie den Profiler mit
SET profiling = 1;Führen Sie dann Ihre Abfrage mit
ausSHOW PROFILES;Sie sehen eine Liste mit Abfragen, für die der Profiler Statistiken hat. Schließlich wählen Sie also aus, mit welcher Abfrage sie untersucht werden sollen
SHOW PROFILE FOR QUERY 1;Tools zur Schemamigration
Oftmals ist ein direktes ALTER auf dem Master nicht möglich – in den meisten Fällen verursacht es eine Verzögerung auf dem Slave, und dies ist möglicherweise für die Anwendungen nicht akzeptabel. Was jedoch getan werden kann, ist, die Änderung in einem rollierenden Modus auszuführen. Sie können mit Slaves beginnen und, sobald die Änderung auf den Slave angewendet wurde, einen der Slaves als neuen Master migrieren, den alten Master zu einem Slave degradieren und die Änderung darauf ausführen.
Ein Tool, das bei einer solchen Aufgabe helfen kann, ist pt-online-schema-change von Percona. Pt-online-schema-change ist unkompliziert – es erstellt eine temporäre Tabelle mit dem gewünschten neuen Schema (z. B. wenn wir einen Index hinzugefügt oder eine Spalte aus einer Tabelle entfernt haben). Dann erstellt es Trigger für die alte Tabelle. Diese Auslöser sind dazu da, Änderungen, die an der ursprünglichen Tabelle vorgenommen werden, an der neuen Tabelle zu spiegeln. Änderungen werden während des Schemaänderungsprozesses gespiegelt. Wenn der ursprünglichen Tabelle eine Zeile hinzugefügt wird, wird sie auch der neuen hinzugefügt. Es emuliert die Art und Weise, wie MySQL Tabellen intern ändert, aber es funktioniert mit einer Kopie der Tabelle, die Sie ändern möchten. Das bedeutet, dass die ursprüngliche Tabelle nicht gesperrt ist und Clients weiterhin Daten darin lesen und ändern können.
Wenn eine Zeile in der alten Tabelle geändert oder gelöscht wird, wird sie ebenfalls in der neuen Tabelle angewendet. Dann beginnt ein Hintergrundprozess zum Kopieren von Daten (unter Verwendung von LOW_PRIORITY INSERT) zwischen der alten und der neuen Tabelle. Sobald die Daten kopiert wurden, wird RENAME TABLE ausgeführt.
Ein weiteres interessantes Tool ist gh-ost. Ghost erstellt eine temporäre Tabelle mit dem geänderten Schema, genau wie pt-online-schema-change es tut. Es führt INSERT-Abfragen aus, die das folgende Muster verwenden, um Daten von der alten in die neue Tabelle zu kopieren. Trotzdem verwendet es keine Trigger. Leider können Trigger die Quelle vieler Einschränkungen sein. gh-ost verwendet den binären Log-Stream, um Tabellenänderungen zu erfassen, und wendet sie asynchron auf die Ghost-Tabelle an. Sobald wir überprüft haben, dass gh-ost unsere Schemaänderung korrekt ausführen kann, ist es an der Zeit, sie tatsächlich auszuführen. Denken Sie daran, dass Sie alte Tabellen, die während des Testens der Migration von gh-ost erstellt wurden, möglicherweise manuell löschen müssen. Sie können auch die Flags --initial-drop-ghost-table und --initial-drop-old-table verwenden, um gh-ost zu bitten, dies für Sie zu tun. Der letzte auszuführende Befehl ist genau derselbe, den wir zum Testen unserer Änderung verwendet haben, wir haben ihm nur --execute hinzugefügt.
pt-online-schema-change und gh-ost sind bei Galera-Nutzern sehr beliebt. Trotzdem hat Galera einige zusätzliche Optionen. Die beiden Methoden Total Order Isolation (TOI) und Rolling Schema Upgrade (RSU) haben ihre Vor- und Nachteile.
TOI – Dies ist die standardmäßige DDL-Replikationsmethode. Der Knoten, der den Writeset erzeugt, erkennt DDL zur Parsing-Zeit und sendet ein Replikationsereignis für die SQL-Anweisung, bevor er überhaupt mit der DDL-Verarbeitung beginnt. Schema-Upgrades werden auf allen Cluster-Knoten in derselben Gesamtreihenfolge ausgeführt, wodurch verhindert wird, dass andere Transaktionen für die Dauer des Vorgangs festgeschrieben werden. Diese Methode ist gut, wenn Sie möchten, dass Ihre Online-Schema-Upgrades durch den Cluster repliziert werden, und es Ihnen nichts ausmacht, die gesamte Tabelle zu sperren (ähnlich wie Standard-Schema-Änderungen in MySQL).
SET GLOBAL wsrep_OSU_method='TOI';RSU - Führen Sie die Schema-Upgrades lokal durch. Bei dieser Methode wirken sich Ihre Schreibvorgänge nur auf den Knoten aus, auf dem sie ausgeführt werden. Die Änderungen werden nicht auf den Rest des Clusters repliziert. Diese Methode eignet sich gut für Vorgänge ohne Konflikte und verlangsamt den Cluster nicht.
SET GLOBAL wsrep_OSU_method='RSU';Während der Knoten das Schema-Upgrade verarbeitet, wird er mit dem Cluster desynchronisiert. Wenn die Verarbeitung des Schema-Upgrades abgeschlossen ist, wendet es verzögerte Replikationsereignisse an und synchronisiert sich selbst mit dem Cluster. Dies könnte eine gute Option sein, um umfangreiche Indexerstellungen auszuführen.
Schlussfolgerung
Wir haben hier verschiedene Methoden vorgestellt, die Ihnen bei der Planung Ihrer Schemaänderungen helfen können. Natürlich hängt alles von Ihrer Anwendung und Ihren Geschäftsanforderungen ab. Sie können Ihren Änderungsplan entwerfen und die erforderlichen Tests durchführen, aber es besteht immer noch eine kleine Chance, dass etwas schief geht. Gemäß Murphys Gesetz „gehen in jeder Situation Dinge schief, wenn man ihnen eine Chance gibt“. Probieren Sie also verschiedene Möglichkeiten aus, um diese Änderungen vorzunehmen, und wählen Sie diejenige aus, mit der Sie sich am wohlsten fühlen.



