Bereits 2012 habe ich hier einen Blogbeitrag geschrieben, in dem Ansätze zur Berechnung eines Medians hervorgehoben wurden. In diesem Beitrag habe ich mich mit dem sehr einfachen Fall befasst:Wir wollten den Median einer Spalte über eine ganze Tabelle finden. Seitdem wurde mir mehrfach gesagt, dass eine praktischere Anforderung darin besteht, einen partitionierten Median zu berechnen . Wie im Grundfall gibt es mehrere Möglichkeiten, dies in verschiedenen Versionen von SQL Server zu lösen. Es überrascht nicht, dass einige viel besser abschneiden als andere.
Im vorherigen Beispiel hatten wir nur die generischen Spalten id und val. Lassen Sie uns dies realistischer machen und sagen, wir haben Vertriebsmitarbeiter und die Anzahl der Verkäufe, die sie in einem bestimmten Zeitraum getätigt haben. Um unsere Abfragen zu testen, erstellen wir zunächst einen einfachen Heap mit 17 Zeilen und überprüfen, ob sie alle die erwarteten Ergebnisse liefern (SalesPerson 1 hat einen Median von 7,5 und SalesPerson 2 hat einen Median von 6,0):
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) VALUES (1, 6 ),(1, 11),(1, 4 ),(1, 4 ), (1, 15),(1, 14),(1, 4 ),(1, 9 ), (2, 6 ),(2, 11),(2, 4 ),(2, 4 ), (2, 15),(2, 14),(2, 4 );
Hier sind die Abfragen, die wir (mit viel mehr Daten!) mit dem obigen Heap sowie mit unterstützenden Indizes testen werden. Ich habe ein paar Abfragen aus dem vorherigen Test verworfen, die entweder überhaupt nicht skaliert oder den partitionierten Medianen nicht sehr gut zugeordnet wurden (nämlich 2000_B, die eine #temp-Tabelle verwendet, und 2005_A, die eine gegenüberliegende Zeile verwendet hat Zahlen). Ich habe jedoch ein paar interessante Ideen aus einem kürzlich erschienenen Artikel von Dwain Camps (@DwainCSQL) hinzugefügt, der auf meinem vorherigen Beitrag aufbaut.
SQL Server 2000+
Die einzige Methode aus dem vorherigen Ansatz, die auf SQL Server 2000 gut genug funktionierte, um sie überhaupt in diesen Test einzubeziehen, war der Ansatz „min von der einen Hälfte, max von der anderen“:
SELECT DISTINCT s.SalesPerson, Median = (
(SELECT MAX(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount) AS t)
+ (SELECT MIN(Amount) FROM
(SELECT TOP 50 PERCENT Amount FROM dbo.Sales
WHERE SalesPerson = s.SalesPerson ORDER BY Amount DESC) AS b)
) / 2.0
FROM dbo.Sales AS s; Ich habe wirklich versucht, die #temp-Tabellenversion nachzuahmen, die ich in dem einfacheren Beispiel verwendet habe, aber sie hat sich überhaupt nicht gut skalieren lassen. Bei 20 oder 200 Reihen hat es gut funktioniert; bei 2000 dauerte es fast eine Minute; bei 1.000.000 habe ich nach einer Stunde aufgegeben. Ich habe es hier für die Nachwelt eingefügt (zum Anzeigen klicken).
CREATE TABLE #x
(
i INT IDENTITY(1,1),
SalesPerson INT,
Amount INT,
i2 INT
);
CREATE CLUSTERED INDEX v ON #x(SalesPerson, Amount);
INSERT #x(SalesPerson, Amount)
SELECT SalesPerson, Amount
FROM dbo.Sales
ORDER BY SalesPerson,Amount OPTION (MAXDOP 1);
UPDATE x SET i2 = i-
(
SELECT COUNT(*) FROM #x WHERE i <= x.i
AND SalesPerson < x.SalesPerson
)
FROM #x AS x;
SELECT SalesPerson, Median = AVG(0. + Amount)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE SalesPerson = x.SalesPerson
AND x.i2 - (SELECT MAX(i2) / 2.0 FROM #x WHERE SalesPerson = x.SalesPerson)
IN (0, 0.5, 1)
)
GROUP BY SalesPerson;
GO
DROP TABLE #x; SQL Server 2005+ 1
Dabei werden zwei verschiedene Windowing-Funktionen verwendet, um eine Sequenz und eine Gesamtanzahl von Beträgen pro Verkäufer abzuleiten.
SELECT SalesPerson, Median = AVG(1.0*Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount),
c = COUNT(*) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2005+ 2
Dies kam aus dem Artikel von Dwain Camps, der das Gleiche tut wie oben, etwas ausführlicher. Dadurch werden die interessanten Zeilen in jeder Gruppe im Grunde unpivotiert.
;WITH Counts AS
(
SELECT SalesPerson, c
FROM
(
SELECT SalesPerson, c1 = (c+1)/2,
c2 = CASE c%2 WHEN 0 THEN 1+c/2 ELSE 0 END
FROM
(
SELECT SalesPerson, c=COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
) a
) a
CROSS APPLY (VALUES(c1),(c2)) b(c)
)
SELECT a.SalesPerson, Median=AVG(0.+b.Amount)
FROM
(
SELECT SalesPerson, Amount, rn = ROW_NUMBER() OVER
(PARTITION BY SalesPerson ORDER BY Amount)
FROM dbo.Sales a
) a
CROSS APPLY
(
SELECT Amount FROM Counts b
WHERE a.SalesPerson = b.SalesPerson AND a.rn = b.c
) b
GROUP BY a.SalesPerson; SQL Server 2005+ 3
Dies basierte auf einem Vorschlag von Adam Machanic in den Kommentaren zu meinem vorherigen Beitrag und wurde auch von Dwain in seinem obigen Artikel verbessert.
;WITH Counts AS
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales
GROUP BY SalesPerson
)
SELECT a.SalesPerson, Median = AVG(0.+Amount)
FROM Counts a
CROSS APPLY
(
SELECT TOP (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
b.Amount, r = ROW_NUMBER() OVER (ORDER BY b.Amount)
FROM dbo.Sales b
WHERE a.SalesPerson = b.SalesPerson
ORDER BY b.Amount
) p
WHERE r BETWEEN ((a.c - 1) / 2) + 1 AND (((a.c - 1) / 2) + (1 + (1 - a.c % 2)))
GROUP BY a.SalesPerson; SQL Server 2005+ 4
Dies ist ähnlich wie „2005+ 1“ oben, aber anstelle von COUNT(*) OVER() Um die Anzahl abzuleiten, führt es eine Selbstverknüpfung mit einem isolierten Aggregat in einer abgeleiteten Tabelle durch.
SELECT SalesPerson, Median = AVG(1.0 * Amount)
FROM
(
SELECT s.SalesPerson, s.Amount, rn = ROW_NUMBER() OVER
(PARTITION BY s.SalesPerson ORDER BY s.Amount), c.c
FROM dbo.Sales AS s
INNER JOIN
(
SELECT SalesPerson, c = COUNT(*)
FROM dbo.Sales GROUP BY SalesPerson
) AS c
ON s.SalesPerson = c.SalesPerson
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2)
GROUP BY SalesPerson; SQL Server 2012+ 1
Dies war ein sehr interessanter Beitrag von Peter „Peso“ Larsson (@SwePeso) von SQL Server MVP in den Kommentaren zu Dwains Artikel; es verwendet CROSS APPLY und das neue OFFSET / FETCH Funktionalität auf eine noch interessantere und überraschendere Weise als Itziks Lösung für die einfachere Medianberechnung.
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median); SQL Server 2012+ 2
Schließlich haben wir das neue PERCENTILE_CONT() Funktion, die in SQL Server 2012 eingeführt wurde.
SELECT SalesPerson, Median = MAX(Median)
FROM
(
SELECT SalesPerson,Median = PERCENTILE_CONT(0.5) WITHIN GROUP
(ORDER BY Amount) OVER (PARTITION BY SalesPerson)
FROM dbo.Sales
)
AS x
GROUP BY SalesPerson; Die wahren Tests
Um die Leistung der oben genannten Abfragen zu testen, erstellen wir eine viel umfangreichere Tabelle. Wir werden 100 einzelne Verkäufer mit jeweils 10.000 Verkaufszahlen haben, also insgesamt 1.000.000 Zeilen. Außerdem führen wir jede Abfrage für den Heap so aus, wie sie ist, mit einem hinzugefügten nicht geclusterten Index für (SalesPerson, Amount) , und mit einem gruppierten Index für dieselben Spalten. Hier ist die Einrichtung:
CREATE TABLE dbo.Sales(SalesPerson INT, Amount INT); GO --CREATE CLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --CREATE NONCLUSTERED INDEX x ON dbo.Sales(SalesPerson, Amount); --DROP INDEX x ON dbo.sales; ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales WITH (TABLOCKX) (SalesPerson, Amount) SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3;
Und hier sind die Ergebnisse der obigen Abfragen für den Heap, den Non-Clustered-Index und den Clustered-Index:
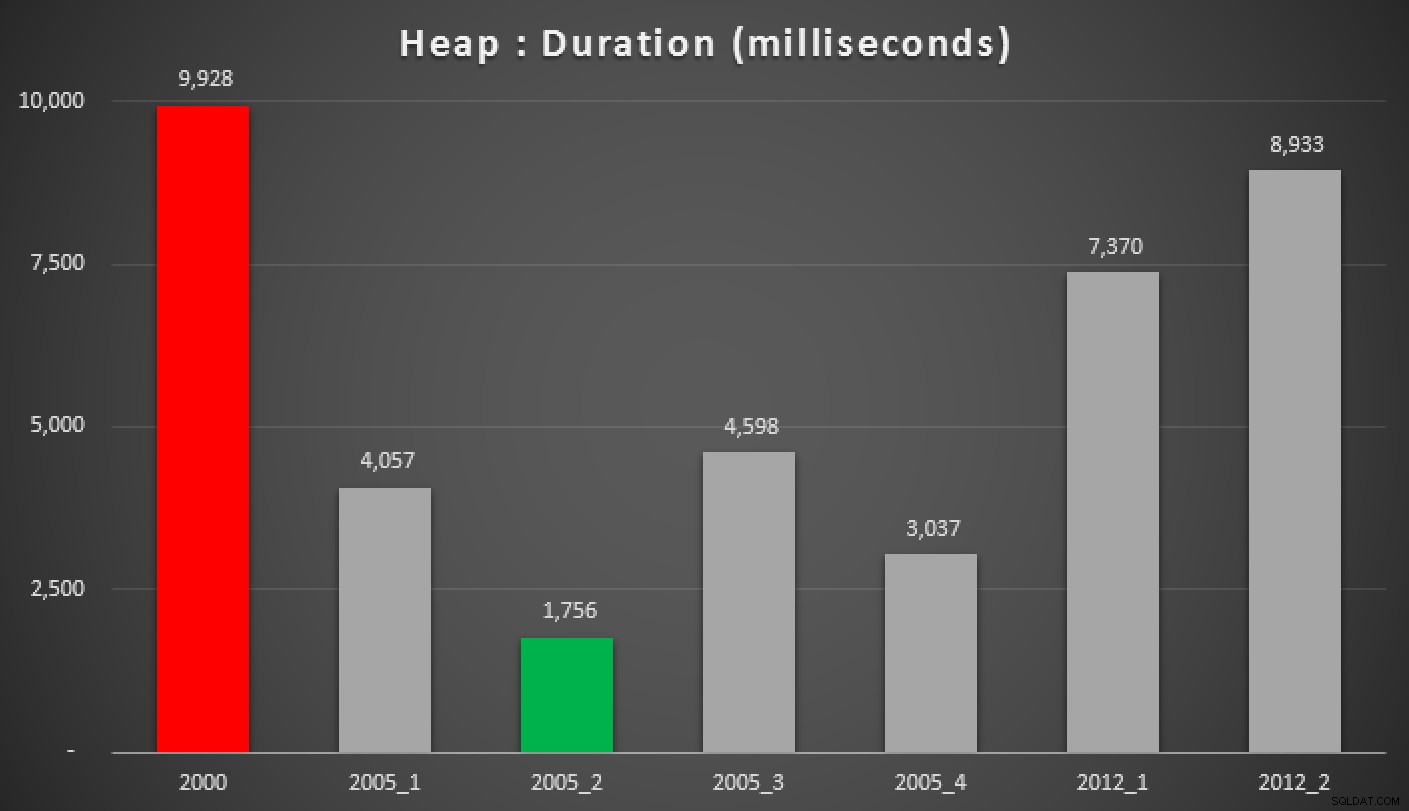
Dauer in Millisekunden verschiedener gruppierter Median-Ansätze (gegen a Haufen)
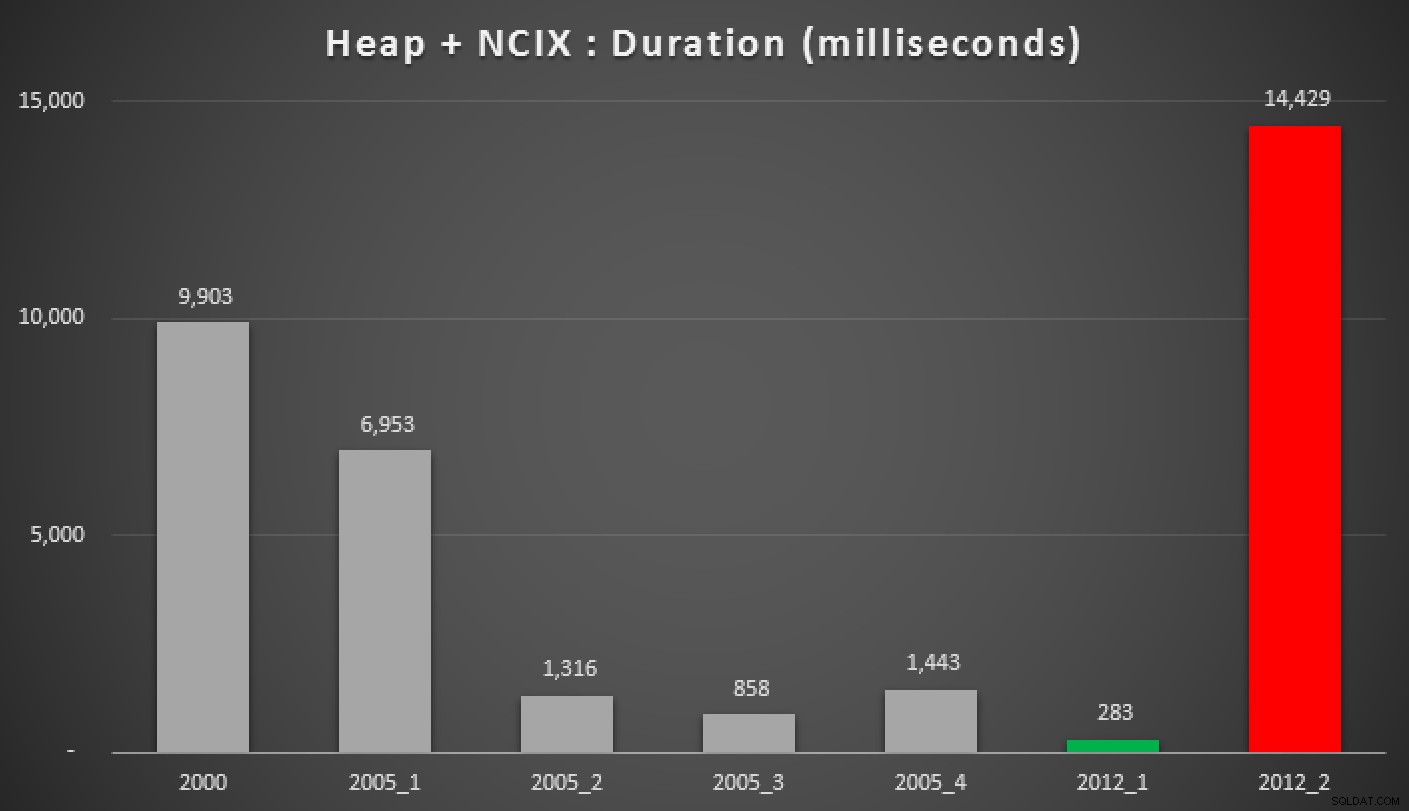
Dauer in Millisekunden verschiedener gruppierter Median-Ansätze (gegen a Heap mit einem nicht geclusterten Index)
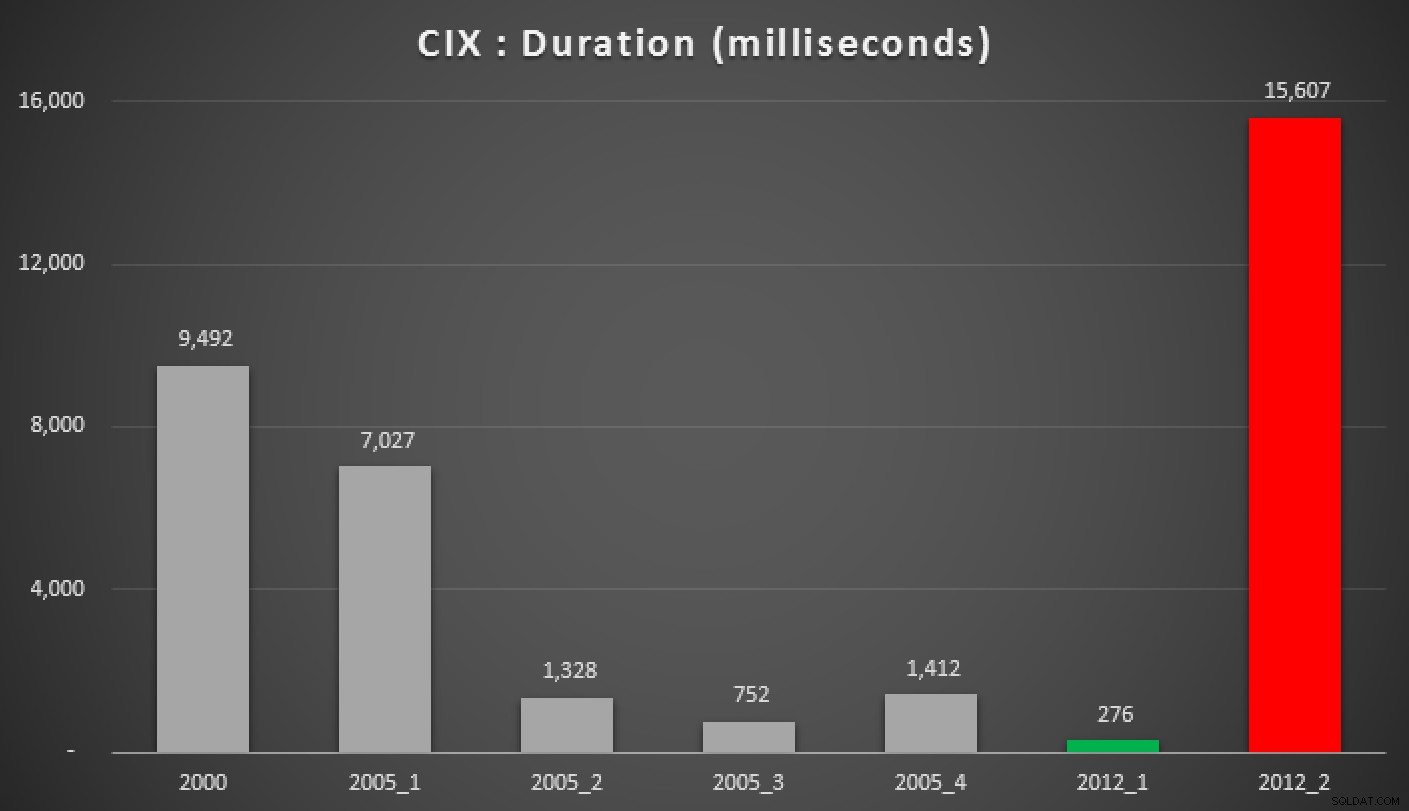
Dauer in Millisekunden verschiedener gruppierter Median-Ansätze (gegen a gruppierter Index)
Was ist mit Hekaton?
Natürlich war ich neugierig, ob dieses neue Feature in SQL Server 2014 bei einer dieser Abfragen helfen könnte. Also habe ich eine In-Memory-Datenbank erstellt, zwei In-Memory-Versionen der Sales-Tabelle (eine mit einem Hash-Index auf (SalesPerson, Amount) , und der andere auf nur (SalesPerson) ) und dieselben Tests erneut ausgeführt:
CREATE DATABASE Hekaton; GO ALTER DATABASE Hekaton ADD FILEGROUP xtp CONTAINS MEMORY_OPTIMIZED_DATA; GO ALTER DATABASE Hekaton ADD FILE (name = 'xtp', filename = 'c:\temp\hek.mod') TO FILEGROUP xtp; GO ALTER DATABASE Hekaton SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT ON; GO USE Hekaton; GO CREATE TABLE dbo.Sales1 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson, Amount) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO CREATE TABLE dbo.Sales2 ( ID INT IDENTITY(1,1) PRIMARY KEY NONCLUSTERED, SalesPerson INT NOT NULL, Amount INT NOT NULL, INDEX x NONCLUSTERED HASH (SalesPerson) WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO ;WITH x AS ( SELECT TOP (100) number FROM master.dbo.spt_values GROUP BY number ) INSERT dbo.Sales1 (SalesPerson, Amount) -- TABLOCK/TABLOCKX not allowed here SELECT x.number, ABS(CHECKSUM(NEWID())) % 99 FROM x CROSS JOIN x AS x2 CROSS JOIN x AS x3; INSERT dbo.Sales2 (SalesPerson, Amount) SELECT SalesPerson, Amount FROM dbo.Sales1;
Die Ergebnisse:
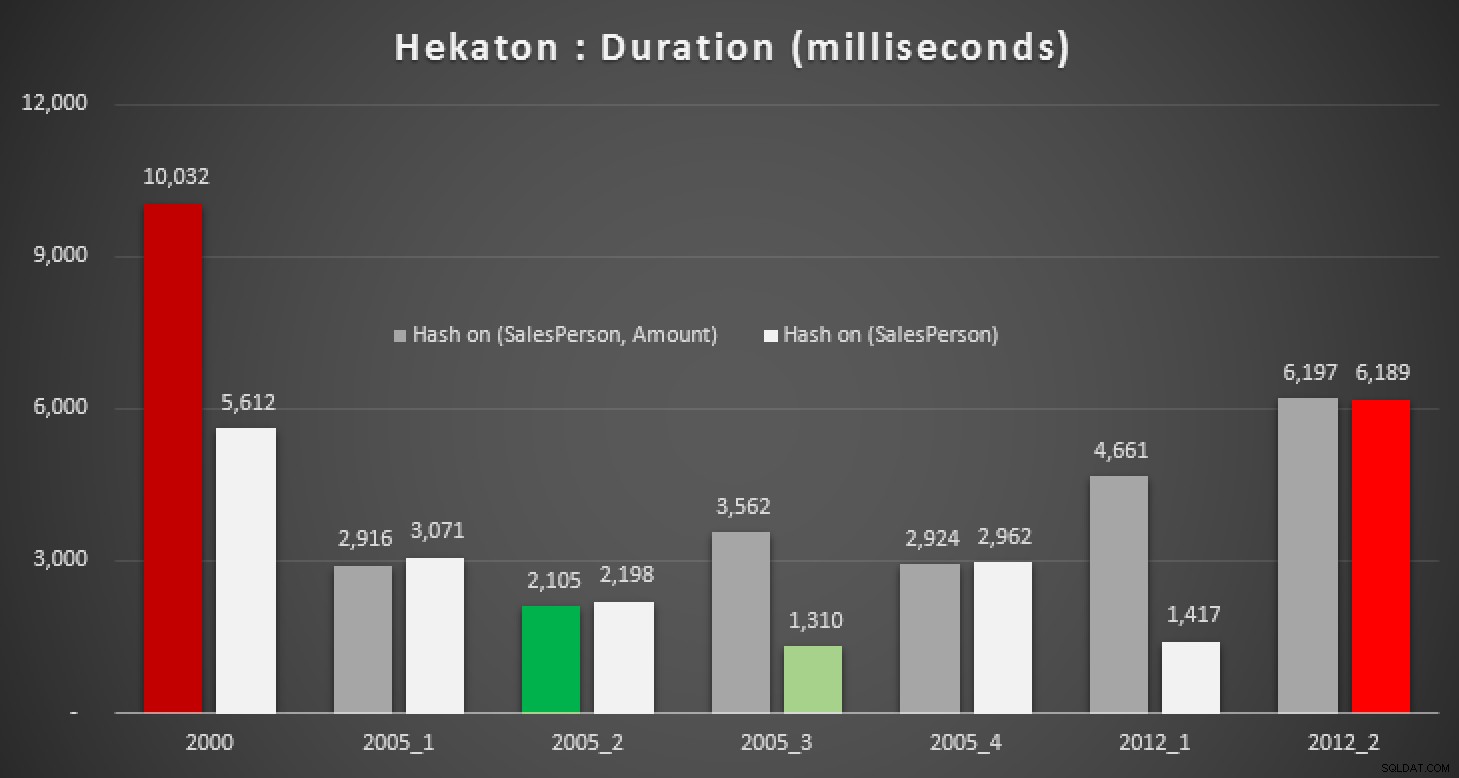
Dauer in Millisekunden für verschiedene Medianberechnungen im Vergleich zu In-Memory Tabellen
Selbst mit dem richtigen Hash-Index sehen wir keine wesentlichen Verbesserungen gegenüber einer herkömmlichen Tabelle. Darüber hinaus wird der Versuch, das Medianproblem mit einer nativ kompilierten gespeicherten Prozedur zu lösen, keine leichte Aufgabe sein, da viele der oben verwendeten Sprachkonstrukte nicht gültig sind (ich war auch über einige davon überrascht). Der Versuch, alle oben genannten Abfragevariationen zu kompilieren, führte zu dieser Fehlerparade; Einige traten mehrmals innerhalb jeder Prozedur auf, und selbst nach dem Entfernen von Duplikaten ist dies immer noch irgendwie komisch:
Msg 10794, Level 16, State 47, Procedure GroupedMedian_2000Die Option 'DISTINCT' wird bei nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2000
Unterabfragen ( Abfragen, die in einer anderen Abfrage verschachtelt sind) werden bei nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Msg 10794, Level 16, State 48, Procedure GroupedMedian_2000
Die Option 'PERCENT' wird bei nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
/>
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_1
Unterabfragen (in einer anderen Abfrage verschachtelte Abfragen) werden mit nativ kompilierten Stored Procedures nicht unterstützt.
Msg 10794, Level 16, State 91 , Prozedur GroupedMedian_2005_1
Die Aggregatfunktion 'ROW_NUMBER' wird von nativ kompilierten Stored Procedures nicht unterstützt.
Msg 10794, Level 16, State 56, Procedure GroupedMedian_2005_1
Der Operator 'IN' wird nicht unterstützt nativ kompilierte gespeicherte Prozeduren.
Msg 12310, Level 16, State 36, Procedure GroupedMedian_2005_2
Common Table Expressions (CTE) werden bei nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Msg 12309, Level 16, State 35, Procedure GroupedMedian_2005_2
Anweisungen des Formulars INSERT…VALUES…, die mehrere Zeilen einfügen, werden von nativ kompilierten Stored Procedures nicht unterstützt.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2005_2
Der Operator „APPLY“ wird von nativ kompilierten Stored Procedures nicht unterstützt.
Msg 12311, Ebene 16, Status 37, Prozedur GroupedMedian_2005_2
Unterabfragen (in einer anderen Abfrage verschachtelte Abfragen) werden mit nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Msg 10794, Ebene 16, Status 91, Prozedur GroupedMedian_2005_2
Die Aggregatfunktion „ROW_NUMBER“ wird mit nativ kompilierten Stored Procedures nicht unterstützt.
Msg 12310, Level 16, State 36, Procedure GroupedMedian_2005_3
Common Table Expressions (CTE) sind nicht unterstützt mit nativ kompilierten gespeicherten Prozeduren.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_3
Unterabfragen (in einer anderen Abfrage verschachtelte Abfragen) werden mit nativ kompilierten Stored Procedures nicht unterstützt.
Msg 10794, Level 16, State 91 , Prozedur GroupedMedian_2005_3
Die Aggregatfunktion 'ROW_NUMBER' wird von nativ kompilierten Stored Procedures nicht unterstützt.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2005_3
Der Operator 'APPLY' wird nicht unterstützt nativ kompilierte gespeicherte Prozeduren.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2005_4
Unterabfragen (in einer anderen Abfrage verschachtelte Abfragen) werden mit nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Msg 10794, Level 16, State 91, Procedure GroupedMedian_2005_4
Die Aggregatfunktion 'ROW_NUMBER' wird mit nativ kompilierten Stored Procedures nicht unterstützt.
Msg 10794, Level 16, State 56, Procedure GroupedMedian_2005_4
Der Operator 'IN' wird bei nativ kompiliertem Speicher nicht unterstützt ed Procedures.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_1
Unterabfragen (in einer anderen Abfrage verschachtelte Abfragen) werden mit nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Msg 10794, Level 16, State 38, Procedure GroupedMedian_2012_1
Der Operator 'OFFSET' wird bei nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Msg 10794, Level 16, State 53, Procedure GroupedMedian_2012_1
Der Operator 'APPLY' wird bei nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Msg 12311, Level 16, State 37, Procedure GroupedMedian_2012_2
Unterabfragen (in einer anderen Abfrage verschachtelte Abfragen) werden bei nativ kompilierten gespeicherten Prozeduren nicht unterstützt.
Msg 10794, Level 16, State 90, Procedure GroupedMedian_2012_2
Die Aggregatfunktion „PERCENTILE_CONT“ wird mit nativ kompilierten Stored Procedures nicht unterstützt.
Wie derzeit geschrieben, konnte keine dieser Abfragen in eine nativ kompilierte gespeicherte Prozedur portiert werden. Vielleicht etwas, das Sie für einen weiteren Folgebeitrag untersuchen sollten.
Schlussfolgerung
Verwerfen der Hekaton-Ergebnisse und wenn ein unterstützender Index vorhanden ist, Peter Larssons Abfrage ("2012+ 1") mit OFFSET/FETCH ging bei diesen Tests als klarer Sieger hervor. Dies ist zwar etwas komplexer als die entsprechende Abfrage in den nicht partitionierten Tests, stimmt aber mit den Ergebnissen überein, die ich beim letzten Mal beobachtet habe.
In denselben Fällen die 2000 MIN/MAX Ansatz und PERCENTILE_CONT() von 2012 kamen als echte Hunde heraus; wieder, genau wie meine vorherigen Tests gegen den einfacheren Fall.
Wenn Sie noch nicht auf SQL Server 2012 arbeiten, ist Ihre nächstbeste Option „2005+ 3“ (wenn Sie einen unterstützenden Index haben) oder „2005+ 2“, wenn Sie es mit einem Heap zu tun haben. Tut mir leid, dass ich mir dafür ein neues Namensschema einfallen lassen musste, hauptsächlich um Verwechslungen mit den Methoden in meinem vorherigen Post zu vermeiden.
Dies sind natürlich meine Ergebnisse anhand eines sehr spezifischen Schemas und Datensatzes – wie bei allen Empfehlungen sollten Sie diese Ansätze anhand Ihres Schemas und Ihrer Daten testen, da andere Faktoren unterschiedliche Ergebnisse beeinflussen können.
Noch eine Anmerkung
Abgesehen davon, dass es schlecht funktioniert und in nativ kompilierten gespeicherten Prozeduren nicht unterstützt wird, ist es ein weiterer Schwachpunkt von PERCENTILE_CONT() ist, dass es nicht in älteren Kompatibilitätsmodi verwendet werden kann. Wenn Sie es versuchen, erhalten Sie diesen Fehler:
Die Funktion PERCENTILE_CONT ist im aktuellen Kompatibilitätsmodus nicht zulässig. Es ist nur im Modus 110 oder höher erlaubt.



