Eines der coolen Features in Galera ist die automatische Knotenbereitstellung und Mitgliedschaftskontrolle. Wenn ein Knoten ausfällt oder die Kommunikation verliert, wird er automatisch aus dem Cluster entfernt und bleibt außer Betrieb. Solange die Mehrheit der Knoten noch kommuniziert (Galera nennt diesen PC – primäre Komponente), besteht eine sehr hohe Wahrscheinlichkeit, dass der ausgefallene Knoten automatisch wieder beitreten, resynchronisieren und die Replikation wieder aufnehmen kann, sobald die Konnektivität wiederhergestellt ist.
Im Allgemeinen sind alle Galera-Knoten gleich. Sie haben denselben Datensatz und dieselbe Rolle wie Master und können dank Galera-Gruppenkommunikation und zertifizierungsbasiertem Replikations-Plugin gleichzeitig lesen und schreiben. Daher gibt es aufgrund dieses Gleichgewichts aus Datenbanksicht eigentlich kein Failover. Nur von der Anwendungsseite, die ein Failover erfordern würde, um die nicht funktionsfähigen Knoten zu überspringen, während der Cluster partitioniert wird.
In diesem Blogbeitrag werden wir untersuchen, wie Galera Cluster die Wiederherstellung von Knoten und Clustern durchführt, falls eine Netzwerkpartitionierung auftritt. Nur als Randnotiz, wir haben vor einiger Zeit ein ähnliches Thema in diesem Blogbeitrag behandelt. Codership hat das Wiederherstellungskonzept von Galera ausführlich auf der Dokumentationsseite Node Failure and Recovery erklärt.
Knotenausfall und -entfernung
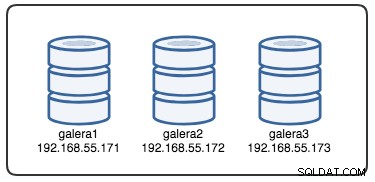
Um die Wiederherstellung zu verstehen, müssen wir zuerst verstehen, wie Galera den Knotenausfall und den Räumungsprozess erkennt. Lassen Sie uns dies in ein kontrolliertes Testszenario einfügen, damit wir den Räumungsprozess besser verstehen können. Angenommen, wir haben einen Galera-Cluster mit drei Knoten, wie unten dargestellt:
Der folgende Befehl kann verwendet werden, um unsere Galera-Anbieteroptionen abzurufen:
mysql> SHOW VARIABLES LIKE 'wsrep_provider_options'\GEs ist eine lange Liste, aber wir müssen uns nur auf einige der Parameter konzentrieren, um den Prozess zu erklären:
evs.inactive_check_period = PT0.5S;
evs.inactive_timeout = PT15S;
evs.keepalive_period = PT1S;
evs.suspect_timeout = PT5S;
evs.view_forget_timeout = P1D;
gmcast.peer_timeout = PT3S;Zunächst einmal folgt Galera der ISO 8601-Formatierung, um die Dauer darzustellen. P1D bedeutet, dass die Dauer einen Tag beträgt, während PT15S bedeutet, dass die Dauer 15 Sekunden beträgt (beachten Sie die Zeitbezeichnung T, die dem Zeitwert vorangeht). Zum Beispiel wenn man evs.view_forget_timeout erhöhen wollte auf anderthalb Tage würde man P1DT12H oder PT36H einstellen.
Da nicht alle Hosts mit Firewall-Regeln konfiguriert wurden, verwenden wir das folgende Skript mit dem Namen block_galera.sh auf galera2, um einen Netzwerkausfall zu/von diesem Knoten zu simulieren:
#!/bin/bash
# block_galera.sh
# galera2, 192.168.55.172
iptables -I INPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I INPUT -m tcp -p tcp --dport 3306 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 4567 -j REJECT
iptables -I OUTPUT -m tcp -p tcp --dport 3306 -j REJECT
# print timestamp
dateDurch Ausführen des Skripts erhalten wir die folgende Ausgabe:
$ ./block_galera.sh
Wed Jul 4 16:46:02 UTC 2018Der gemeldete Zeitstempel kann als Beginn der Clusterpartitionierung betrachtet werden, bei der wir galera2 verlieren, während galera1 und galera3 noch online und zugänglich sind. An diesem Punkt sieht unsere Galera-Cluster-Architektur in etwa so aus:
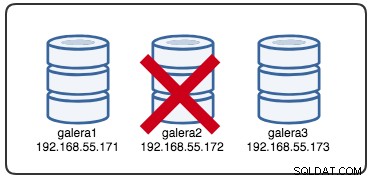
Aus der Perspektive partitionierter Knoten
Auf galera2 sehen Sie einige Ausdrucke im MySQL-Fehlerprotokoll. Teilen wir sie in mehrere Teile auf. Die Ausfallzeit begann um 16:46:02 UTC-Zeit und nach gmcast.peer_timeout=PT3S , erscheint Folgendes:
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 8b2041d6 with addr tcp://192.168.55.173:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:05 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.173:4567
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') connection to peer 737422d6 with addr tcp://192.168.55.171:4567 timed out, no messages seen in PT3S
2018-07-04 16:46:06 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 0Als es evs.suspect_timeout =PT5S passierte , werden beide Knoten galera1 und galera3 von galera2 als tot vermutet:
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 8b2041d6
2018-07-04 16:46:07 140454904243968 [Note] WSREP: evs::proto(62116b35, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactive
2018-07-04 16:46:07 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 0
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspecting node: 737422d6
2018-07-04 16:46:08 140454904243968 [Note] WSREP: evs::proto(62116b35, GATHER, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveDann überarbeitet Galera die aktuelle Clusteransicht und die Position dieses Knotens:
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,54) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})
2018-07-04 16:46:09 140454904243968 [Note] WSREP: view(view_id(NON_PRIM,62116b35,55) memb {
62116b35,0
} joined {
} left {
} partitioned {
737422d6,0
8b2041d6,0
})Mit der neuen Cluster-Ansicht führt Galera eine Quorum-Berechnung durch, um zu entscheiden, ob dieser Knoten Teil der primären Komponente ist. Wenn die neue Komponente „primary =no“ sieht, wird Galera den Status des lokalen Knotens von SYNCED auf OPEN herabstufen:
2018-07-04 16:46:09 140454288942848 [Note] WSREP: New COMPONENT: primary = no, bootstrap = no, my_idx = 0, memb_num = 1
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Flow-control interval: [16, 16]
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Trying to continue unpaused monitor
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Received NON-PRIMARY.
2018-07-04 16:46:09 140454288942848 [Note] WSREP: Shifting SYNCED -> OPEN (TO: 2753699)Mit der letzten Änderung der Clusteransicht und des Knotenstatus gibt Galera die Clusteransicht nach der Entfernung und den globalen Status wie folgt zurück:
2018-07-04 16:46:09 140454222194432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753699, view# -1: non-Primary, number of nodes: 1, my index: 0, protocol version 3
2018-07-04 16:46:09 140454222194432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.Sie können sehen, dass sich der folgende globale Status von galera2 in diesem Zeitraum geändert hat:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 1 |
| WSREP_CLUSTER_STATUS | non-Primary |
| WSREP_EVS_DELAYED | 737422d6-7db3-11e8-a2a2-bbe98913baf0:tcp://192.168.55.171:4567:1,8b2041d6-7f62-11e8-87d5-12a76678131f:tcp://192.168.55.173:4567:2 |
| WSREP_LOCAL_STATE_COMMENT | Initialized |
| WSREP_READY | OFF |
+---------------------------+-----------------------------------------------------------------------------------------------------------------------------------+Zu diesem Zeitpunkt ist der MySQL/MariaDB-Server auf galera2 noch zugänglich (die Datenbank lauscht auf 3306 und Galera auf 4567) und Sie können die MySQL-Systemtabellen abfragen und die Datenbanken und Tabellen auflisten. Wenn Sie jedoch in die Nicht-Systemtabellen springen und eine einfache Abfrage wie diese durchführen:
mysql> SELECT * FROM sbtest1;
ERROR 1047 (08S01): WSREP has not yet prepared node for application useSie erhalten sofort eine Fehlermeldung, die besagt, dass WSREP geladen, aber von diesem Knoten nicht einsatzbereit ist, wie von wsrep_ready gemeldet Status. Dies liegt daran, dass der Knoten seine Verbindung zur primären Komponente verliert und in den nicht betriebsbereiten Zustand übergeht (der Status des lokalen Knotens wurde von SYNCED in OPEN geändert). Datenlesevorgänge von Knoten in einem nicht betriebsbereiten Zustand gelten als veraltet, es sei denn, Sie setzen wsrep_dirty_reads=ON um Lesevorgänge zuzulassen, obwohl Galera weiterhin jeden Befehl ablehnt, der die Datenbank ändert oder aktualisiert.
Schließlich wird Galera im Hintergrund unendlich weiter zuhören und sich wieder mit anderen Mitgliedern verbinden:
2018-07-04 16:47:12 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 30
2018-07-04 16:47:13 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 30
2018-07-04 16:48:20 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 8b2041d6 (tcp://192.168.55.173:4567), attempt 60
2018-07-04 16:48:22 140454904243968 [Note] WSREP: (62116b35, 'tcp://0.0.0.0:4567') reconnecting to 737422d6 (tcp://192.168.55.171:4567), attempt 60Der Eviction-Prozessablauf durch die Galera-Gruppenkommunikation für den partitionierten Knoten während eines Netzwerkproblems kann wie folgt zusammengefasst werden:
- Trennt die Verbindung zum Cluster nach gmcast.peer_timeout .
- Vermutet andere Knoten nach evs.suspect_timeout .
- Ruft die neue Clusteransicht ab.
- Führt eine Quorum-Berechnung durch, um den Zustand des Knotens zu bestimmen.
- Stuft den Knoten von SYNCED auf OPEN herab.
- Versucht im Hintergrund, sich wieder mit der primären Komponente (anderen Galera-Knoten) zu verbinden.
Aus der Perspektive der primären Komponente
Auf galera1 bzw. galera3 nach gmcast.peer_timeout=PT3S , erscheint Folgendes im MySQL-Fehlerprotokoll:
2018-07-04 16:46:05 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting on, nonlive peers: tcp://192.168.55.172:4567
2018-07-04 16:46:06 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') reconnecting to 62116b35 (tcp://192.168.55.172:4567), attempt 0Nachdem es evs.suspect_timeout =PT5S passiert hat , galera2 wird von galera3 (und galera1) als tot verdächtigt:
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspecting node: 62116b35
2018-07-04 16:46:10 139955510687488 [Note] WSREP: evs::proto(8b2041d6, OPERATIONAL, view_id(REG,62116b35,54)) suspected node without join message, declaring inactiveGalera überprüft, ob die anderen Knoten auf die Gruppenkommunikation auf galera3 antworten, es stellt fest, dass sich galera1 im primären und stabilen Zustand befindet:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-04 16:46:11 139955510687488 [Note] WSREP: Node 737422d6 state primGalera überarbeitet die Clusteransicht dieses Knotens (galera3):
2018-07-04 16:46:11 139955510687488 [Note] WSREP: view(view_id(PRIM,737422d6,55) memb {
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
62116b35,0
})
2018-07-04 16:46:11 139955510687488 [Note] WSREP: save pc into diskGalera entfernt dann den partitionierten Knoten aus der primären Komponente:
2018-07-04 16:46:11 139955510687488 [Note] WSREP: forgetting 62116b35 (tcp://192.168.55.172:4567)Die neue primäre Komponente besteht nun aus zwei Knoten, galera1 und galera3:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 1, memb_num = 2Die primäre Komponente tauscht den Status untereinander aus, um sich auf die neue Clusteransicht und den globalen Status zu einigen:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-07-04 16:46:11 139955510687488 [Note] WSREP: (8b2041d6, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: sent state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 0 (192.168.55.171)
2018-07-04 16:46:11 139955502294784 [Note] WSREP: STATE EXCHANGE: got state msg: b3d38100-7f66-11e8-8e70-8e3bf680c993 from 1 (192.168.55.173)Galera berechnet und überprüft das Quorum des staatlichen Austauschs zwischen Online-Mitgliedern:
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 27,
members = 2/2 (joined/total),
act_id = 2753703,
last_appl. = 2753606,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Flow-control interval: [23, 23]
2018-07-04 16:46:11 139955502294784 [Note] WSREP: Trying to continue unpaused monitorGalera aktualisiert die neue Clusteransicht und den globalen Status nach der Entfernung von galera2:
2018-07-04 16:46:11 139955214169856 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2753703, view# 28: Primary, number of nodes: 2, my index: 1, protocol version 3
2018-07-04 16:46:11 139955214169856 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-04 16:46:11 139955214169856 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-04 16:46:11 139955214169856 [Note] WSREP: Assign initial position for certification: 2753703, protocol version: 3
2018-07-04 16:46:11 139956691814144 [Note] WSREP: Service thread queue flushed.
Clean up the partitioned node (galera2) from the active list:
2018-07-04 16:46:14 139955510687488 [Note] WSREP: cleaning up 62116b35 (tcp://192.168.55.172:4567)An diesem Punkt melden sowohl galera1 als auch galera3 einen ähnlichen globalen Status:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+------------------------------------------------------------------+
| WSREP_CLUSTER_SIZE | 2 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | 1491abd9-7f6d-11e8-8930-e269b03673d8:tcp://192.168.55.172:4567:1 |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+------------------------------------------------------------------+Sie listen das problematische Mitglied in wsrep_evs_delayed auf Status. Da der lokale Status "Synced" ist, sind diese Knoten betriebsbereit und Sie können die Client-Verbindungen von galera2 zu jedem von ihnen umleiten. Wenn dieser Schritt unbequem ist, ziehen Sie die Verwendung eines Lastenausgleichs in Betracht, der vor der Datenbank sitzt, um den Verbindungsendpunkt von den Clients zu vereinfachen.
Knotenwiederherstellung und Beitritt
Ein partitionierter Galera-Knoten wird unendlich weiter versuchen, eine Verbindung mit der primären Komponente herzustellen. Lassen Sie uns die iptables-Regeln auf galera2 leeren, damit es sich mit den verbleibenden Knoten verbinden kann:
# on galera2
$ iptables -FSobald der Knoten in der Lage ist, sich mit einem der Knoten zu verbinden, beginnt Galera automatisch mit der Wiederherstellung der Gruppenkommunikation:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 8b2041d6 tcp://192.168.55.173:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 737422d6 at tcp://192.168.55.171:4567 stable
2018-07-09 10:46:34 140075962705664 [Note] WSREP: declaring 8b2041d6 at tcp://192.168.55.173:4567 stableKnoten galera2 verbindet sich dann mit einer der primären Komponenten (in diesem Fall galera1, Knoten-ID 737422d6), um die aktuelle Clusteransicht und den aktuellen Knotenstatus abzurufen:
2018-07-09 10:46:34 140075962705664 [Note] WSREP: Node 737422d6 state prim
2018-07-09 10:46:34 140075962705664 [Note] WSREP: view(view_id(PRIM,1491abd9,142) memb {
1491abd9,0
737422d6,0
8b2041d6,0
} joined {
} left {
} partitioned {
})
2018-07-09 10:46:34 140075962705664 [Note] WSREP: save pc into diskGalera führt dann einen Zustandsaustausch mit den übrigen Mitgliedern durch, die die primäre Komponente bilden können:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 0, memb_num = 3
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE_EXCHANGE: sent state UUID: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: sent state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 0 (192.168.55.172)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 1 (192.168.55.171)
2018-07-09 10:46:34 140075954312960 [Note] WSREP: STATE EXCHANGE: got state msg: 4b23eaa0-8322-11e8-a87e-fe4e0fce2a5f from 2 (192.168.55.173)Der Zustandsaustausch erlaubt galera2, das Quorum zu berechnen und das folgende Ergebnis zu produzieren:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 71,
members = 2/3 (joined/total),
act_id = 2836958,
last_appl. = 0,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bcGalera stuft dann den Status des lokalen Knotens von OPEN auf PRIMARY herauf, um die Knotenverbindung zur Primärkomponente zu starten und herzustellen:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Trying to continue unpaused monitor
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting OPEN -> PRIMARY (TO: 2836958)Wie in der obigen Zeile angegeben, berechnet Galera die Lücke, wie weit der Knoten vom Cluster entfernt ist. Dieser Knoten erfordert eine Zustandsübertragung, um den Writeset mit der Nummer 2836958 von 2761994 einzuholen:
2018-07-09 10:46:34 140075929970432 [Note] WSREP: State transfer required:
Group state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
Local state: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994
2018-07-09 10:46:34 140075929970432 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958, view# 72: Primary, number of nodes:
3, my index: 0, protocol version 3
2018-07-09 10:46:34 140075929970432 [Warning] WSREP: Gap in state sequence. Need state transfer.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: wsrep_notify_cmd is not defined, skipping notification.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: REPL Protocols: 8 (3, 2)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Assign initial position for certification: 2836958, protocol version: 3Galera bereitet den IST-Listener auf Port 4568 auf diesem Knoten vor und bittet jeden synchronisierten Knoten im Cluster, Spender zu werden. In diesem Fall wählt Galera automatisch galera3 (192.168.55.173) aus, oder es könnte auch einen Spender aus der Liste unter wsrep_sst_donor auswählen (falls definiert) für den Synchronisierungsvorgang:
2018-07-09 10:46:34 140075996276480 [Note] WSREP: Service thread queue flushed.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: IST receiver addr using tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Prepared IST receiver, listening at: tcp://192.168.55.172:4568
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) requested state transfer from '*any*'. Selected 2.0 (192.168.55.173)(SYNCED) as donor.Es ändert dann den Status des lokalen Knotens von PRIMARY in JOINER. In diesem Stadium wird galera2 eine Zustandsübertragungsanforderung gewährt und beginnt, Schreibsätze zwischenzuspeichern:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Shifting PRIMARY -> JOINER (TO: 2836958)
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Requesting state transfer: success, donor: 2
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache history reset: 55238f52-41ee-11e8-852f-3316bdb654bc:2761994 -> 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:46:34 140075929970432 [Note] WSREP: GCache DEBUG: RingBuffer::seqno_reset(): full resetKnoten galera2 beginnt, die fehlenden Writesets aus dem gcache des ausgewählten Spenders (galera3) zu empfangen:
2018-07-09 10:46:34 140075954312960 [Note] WSREP: 2.0 (192.168.55.173): State transfer to 0.0 (192.168.55.172) complete.
2018-07-09 10:46:34 140075929970432 [Note] WSREP: Receiving IST: 74964 writesets, seqnos 2761994-2836958
2018-07-09 10:46:34 140075593627392 [Note] WSREP: Receiving IST... 0.0% ( 0/74964 events) complete.
2018-07-09 10:46:34 140075954312960 [Note] WSREP: Member 2.0 (192.168.55.173) synced with group.
2018-07-09 10:46:34 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') connection established to 737422d6 tcp://192.168.55.171:4567
2018-07-09 10:46:41 140075962705664 [Note] WSREP: (1491abd9, 'tcp://0.0.0.0:4567') turning message relay requesting off
2018-07-09 10:46:44 140075593627392 [Note] WSREP: Receiving IST... 36.0% (27008/74964 events) complete.
2018-07-09 10:46:54 140075593627392 [Note] WSREP: Receiving IST... 71.6% (53696/74964 events) complete.
2018-07-09 10:47:02 140075593627392 [Note] WSREP: Receiving IST...100.0% (74964/74964 events) complete.
2018-07-09 10:47:02 140075929970432 [Note] WSREP: IST received: 55238f52-41ee-11e8-852f-3316bdb654bc:2836958
2018-07-09 10:47:02 140075954312960 [Note] WSREP: 0.0 (192.168.55.172): State transfer from 2.0 (192.168.55.173) complete.Sobald alle fehlenden Writesets empfangen und angewendet wurden, wird Galera galera2 bis Seqno 2837012 als JOINED bewerben:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINER -> JOINED (TO: 2837012)
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Member 0.0 (192.168.55.172) synced with group.Der Knoten wendet alle zwischengespeicherten Writesets in seiner Slave-Warteschlange an und beendet das Aufholen mit dem Cluster. Seine Slave-Warteschlange ist jetzt leer. Galera befördert galera2 auf SYNCED, was anzeigt, dass der Knoten jetzt betriebsbereit und bereit ist, Clients zu bedienen:
2018-07-09 10:47:02 140075954312960 [Note] WSREP: Shifting JOINED -> SYNCED (TO: 2837012)
2018-07-09 10:47:02 140076605892352 [Note] WSREP: Synchronized with group, ready for connectionsZu diesem Zeitpunkt sind alle Knoten wieder betriebsbereit. Sie können dies überprüfen, indem Sie die folgenden Anweisungen auf galera2 verwenden:
mysql> SELECT * FROM information_schema.global_status WHERE variable_name IN ('WSREP_CLUSTER_STATUS','WSREP_LOCAL_STATE_COMMENT','WSREP_CLUSTER_SIZE','WSREP_EVS_DELAYED','WSREP_READY');
+---------------------------+----------------+
| VARIABLE_NAME | VARIABLE_VALUE |
+---------------------------+----------------+
| WSREP_CLUSTER_SIZE | 3 |
| WSREP_CLUSTER_STATUS | Primary |
| WSREP_EVS_DELAYED | |
| WSREP_LOCAL_STATE_COMMENT | Synced |
| WSREP_READY | ON |
+---------------------------+----------------+Die wsrep_cluster_size als 3 gemeldet und der Clusterstatus ist Primär, was darauf hinweist, dass galera2 Teil der Primärkomponente ist. Die wsrep_evs_delayed wurde ebenfalls gelöscht und der lokale Zustand ist jetzt Synchronisiert.
Der Ablauf des Wiederherstellungsprozesses für den partitionierten Knoten während eines Netzwerkproblems kann wie folgt zusammengefasst werden:
- Stellt die Gruppenkommunikation zu anderen Knoten wieder her.
- Ruft die Cluster-Ansicht von einer der primären Komponenten ab.
- Führt den Zustandsaustausch mit der primären Komponente durch und berechnet das Quorum.
- Ändert den Status des lokalen Knotens von OPEN zu PRIMARY.
- Berechnet die Lücke zwischen dem lokalen Knoten und dem Cluster.
- Ändert den Status des lokalen Knotens von PRIMARY in JOINER.
- Bereit IST Listener/Receiver auf Port 4568.
- Beantragt eine staatliche Übertragung über IST und wählt einen Spender aus.
- Beginnt mit dem Empfang und der Anwendung des fehlenden Writesets aus dem gcache des ausgewählten Spenders.
- Ändert den Status des lokalen Knotens von JOINER zu JOINED.
- Hängt mit dem Cluster auf, indem die zwischengespeicherten Writesets in der Slave-Warteschlange angewendet werden.
- Ändert den Status des lokalen Knotens von JOINED in SYNCED.
Clusterfehler
Ein Galera Cluster gilt als ausgefallen, wenn keine primäre Komponente (PC) vorhanden ist. Stellen Sie sich einen ähnlichen Galera-Cluster mit drei Knoten vor, wie im folgenden Diagramm dargestellt:
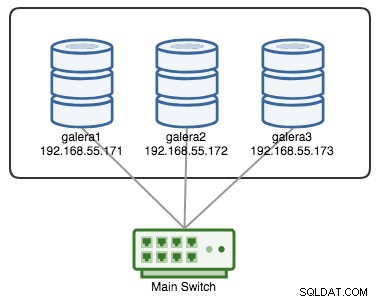
Ein Cluster gilt als betriebsbereit, wenn alle Knoten oder die Mehrheit der Knoten online sind. Online bedeutet, dass sie sich über den Replikationsdatenverkehr oder die Gruppenkommunikation von Galera sehen können. Wenn kein Datenverkehr vom Knoten ein- und ausgeht, sendet der Cluster ein Heartbeat-Beacon, damit der Knoten zeitnah antwortet. Andernfalls wird es in die Verzögerungs- oder Verdachtsliste aufgenommen, je nachdem, wie der Knoten antwortet.
Wenn ein Knoten ausfällt, sagen wir Knoten C, bleibt der Cluster betriebsbereit, da Knoten A und B immer noch mit 2 von 3 Stimmen im Quorum sind, um eine primäre Komponente zu bilden. Sie sollten den folgenden Clusterstatus auf A und B erhalten:
mysql> SHOW STATUS LIKE 'wsrep_cluster_status';
+----------------------+---------+
| Variable_name | Value |
+----------------------+---------+
| wsrep_cluster_status | Primary |
+----------------------+---------+Nehmen wir an, ein primärer Switch ist kaputt gegangen, wie im folgenden Diagramm dargestellt:
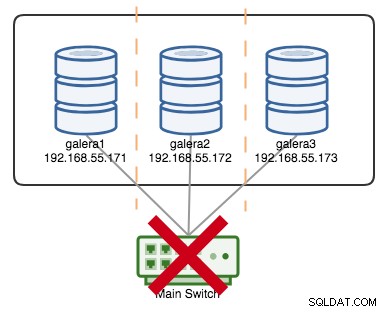
An diesem Punkt verliert jeder einzelne Knoten die Kommunikation untereinander, und der Clusterstatus wird auf allen Knoten als nicht primär gemeldet (wie es im vorherigen Fall mit galera2 passiert ist). Jeder Knoten würde das Quorum berechnen und feststellen, dass er die Minderheit ist (1 von 3 Stimmen), wodurch das Quorum verloren geht, was bedeutet, dass keine primäre Komponente gebildet wird und folglich alle Knoten sich weigern, irgendwelche Daten zu liefern. Dies wird als Clusterfehler betrachtet.
Sobald das Netzwerkproblem gelöst ist, stellt Galera automatisch die Kommunikation zwischen den Mitgliedern wieder her, tauscht die Zustände der Knoten aus und bestimmt die Möglichkeit, die primäre Komponente zu reformieren, indem es den Zustand der Knoten, UUIDs und Seqnos vergleicht. Wenn die Wahrscheinlichkeit besteht, führt Galera die Primärkomponenten wie in den folgenden Zeilen gezeigt zusammen:
2018-06-27 0:16:57 140203784476416 [Note] WSREP: New COMPONENT: primary = yes, bootstrap = no, my_idx = 2, memb_num = 3
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: Waiting for state UUID.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: sent state msg: 5885911b-795c-11e8-8683-931c85442c7e
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 0 (192.168.55.171)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 1 (192.168.55.172)
2018-06-27 0:16:57 140203784476416 [Note] WSREP: STATE EXCHANGE: got state msg: 5885911b-795c-11e8-8683-931c85442c7e from 2 (192.168.55.173)
2018-06-27 0:16:57 140203784476416 [Warning] WSREP: Quorum: No node with complete state:
Version : 4
Flags : 0x3
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.171'
Incoming addr: '192.168.55.171:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.172'
Incoming addr: '192.168.55.172:3306'
Version : 4
Flags : 0x2
Protocols : 0 / 8 / 3
State : NON-PRIMARY
Desync count : 0
Prim state : SYNCED
Prim UUID : 5224a024-791b-11e8-a0ac-8bc6118b0f96
Prim seqno : 5
First seqno : 112714
Last seqno : 112725
Prim JOINED : 3
State UUID : 5885911b-795c-11e8-8683-931c85442c7e
Group UUID : 55238f52-41ee-11e8-852f-3316bdb654bc
Name : '192.168.55.173'
Incoming addr: '192.168.55.173:3306'
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Full re-merge of primary 5224a024-791b-11e8-a0ac-8bc6118b0f96 found: 3 of 3.
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 5,
members = 3/3 (joined/total),
act_id = 112725,
last_appl. = 112722,
protocols = 0/8/3 (gcs/repl/appl),
group UUID = 55238f52-41ee-11e8-852f-3316bdb654bc
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Flow-control interval: [28, 28]
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Trying to continue unpaused monitor
2018-06-27 0:16:57 140203784476416 [Note] WSREP: Restored state OPEN -> SYNCED (112725)
2018-06-27 0:16:57 140202564110080 [Note] WSREP: New cluster view: global state: 55238f52-41ee-11e8-852f-3316bdb654bc:112725, view# 6: Primary, number of nodes: 3, my index: 2, protocol version 3A good indicator to know if the re-bootstrapping process is OK is by looking at the following line in the error log:
[Note] WSREP: Synchronized with group, ready for connectionsClusterControl Auto Recovery
ClusterControl comes with node and cluster automatic recovery features, because it oversees and understands the state of all nodes in the cluster. Automatic recovery is by default enabled if the cluster is deployed using ClusterControl. To enable or disable the cluster, simply clicking on the power icon in the summary bar as shown below:

Green icon means automatic recovery is turned on, while red is the opposite. You can monitor the recovery progress from the Activity -> Jobs dialog, like in this case, galera2 was totally inaccessible due to firewall blocking, thus forcing ClusterControl to report the following:
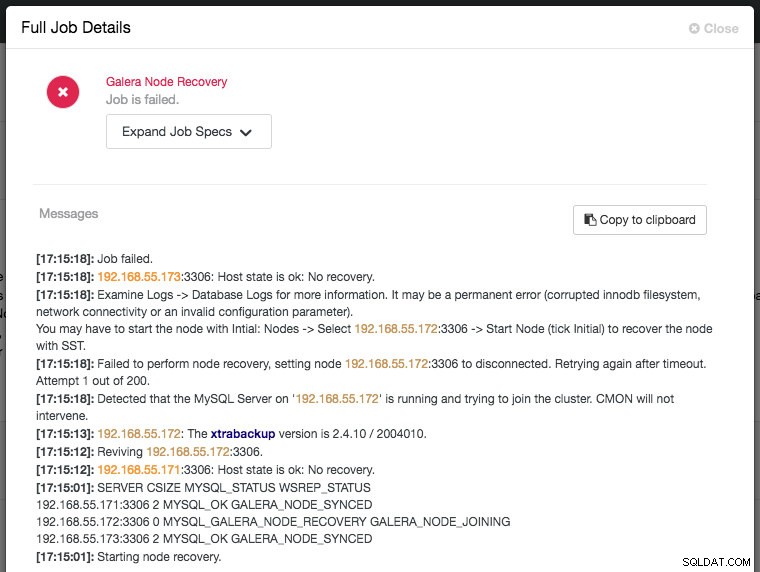
The recovery process will only be commencing after a graceful timeout (30 seconds) to give Galera node a chance to recover itself beforehand. If ClusterControl fails to recover a node or cluster, it will first pull all MySQL error logs from all accessible nodes and will raise the necessary alarms to notify the user via email or by pushing critical events to the third-party integration modules like PagerDuty, VictorOps or Slack. Manual intervention is then required. For Galera Cluster, ClusterControl will keep on trying to recover the failure until you mark the node as under maintenance, or disable the automatic recovery feature.
ClusterControl's automatic recovery is one of most favorite features as voted by our users. It helps you to take the necessary actions quickly, with a complete report on what has been attempted and recommendation steps to troubleshoot further on the issue. For users with support subscriptions, you can look for extra hands by escalating this issue to our technical support team for assistance.
Schlussfolgerung
Galera automatic node recovery and membership control are neat features to simplify the cluster management, improve the database reliability and reduce the risk of human error, as commonly haunting other open-source database replication technology like MySQL Replication, Group Replication and PostgreSQL Streaming/Logical Replication.