Jemand hat versehentlich einen Teil der Datenbank gelöscht. Jemand hat vergessen, eine WHERE-Klausel in eine DELETE-Abfrage aufzunehmen, oder er hat die falsche Tabelle gelöscht. So etwas kann und wird passieren, es ist unvermeidlich und menschlich. Aber die Auswirkungen können verheerend sein. Was können Sie tun, um sich vor solchen Situationen zu schützen, und wie können Sie Ihre Daten wiederherstellen? In diesem Blogbeitrag behandeln wir einige der typischsten Fälle von Datenverlust und wie Sie sich darauf vorbereiten können, sich davon zu erholen.
Vorbereitungen
Es gibt Dinge, die Sie tun sollten, um eine reibungslose Genesung zu gewährleisten. Gehen wir sie durch. Bitte denken Sie daran, dass es sich nicht um eine Situation handelt, in der Sie sich nur eine aussuchen können. Idealerweise implementieren Sie alle Maßnahmen, die wir im Folgenden besprechen werden.
Sicherung
Sie müssen ein Backup haben, daran führt kein Weg vorbei. Sie sollten Ihre Backup-Dateien testen lassen – wenn Sie Ihre Backups nicht testen, können Sie nicht sicher sein, ob sie gut sind und ob Sie sie jemals wiederherstellen können. Für die Notfallwiederherstellung sollten Sie eine Kopie Ihres Backups irgendwo außerhalb Ihres Rechenzentrums aufbewahren – nur für den Fall, dass das gesamte Rechenzentrum nicht verfügbar ist. Um die Wiederherstellung zu beschleunigen, ist es sehr nützlich, eine Kopie des Backups auch auf den Datenbankknoten aufzubewahren. Wenn Ihr Dataset groß ist, kann das Kopieren über das Netzwerk von einem Sicherungsserver auf den Datenbankknoten, den Sie wiederherstellen möchten, viel Zeit in Anspruch nehmen. Die neueste Sicherung lokal aufzubewahren kann die Wiederherstellungszeiten erheblich verkürzen.
Logische Sicherung
Ihr erstes Backup wird höchstwahrscheinlich ein physisches Backup sein. Für MySQL oder MariaDB wird es entweder so etwas wie xtrabackup oder eine Art Dateisystem-Snapshot sein. Solche Sicherungen eignen sich hervorragend zum Wiederherstellen eines ganzen Datensatzes oder zum Bereitstellen neuer Knoten. Im Falle des Löschens einer Teilmenge von Daten leiden sie jedoch unter einem erheblichen Overhead. Zunächst einmal können Sie nicht alle Daten wiederherstellen, da Sie sonst alle Änderungen überschreiben, die nach der Erstellung der Sicherung vorgenommen wurden. Was Sie suchen, ist die Möglichkeit, nur eine Teilmenge von Daten wiederherzustellen, nur die Zeilen, die versehentlich entfernt wurden. Um dies mit einem physischen Backup zu tun, müssten Sie es auf einem separaten Host wiederherstellen, entfernte Zeilen lokalisieren, sie sichern und sie dann auf dem Produktionscluster wiederherstellen. Das Kopieren und Wiederherstellen von Hunderten von Gigabyte an Daten, nur um eine Handvoll Zeilen wiederherzustellen, ist definitiv ein erheblicher Overhead. Um dies zu vermeiden, können Sie logische Backups verwenden - anstatt physische Daten zu speichern, speichern solche Backups Daten in einem Textformat. Dies erleichtert das Auffinden der genauen entfernten Daten, die dann direkt auf dem Produktionscluster wiederhergestellt werden können. Um es noch einfacher zu machen, können Sie eine solche logische Sicherung auch in Teile aufteilen und jede einzelne Tabelle in eine separate Datei sichern. Wenn Ihr Datensatz groß ist, ist es sinnvoll, eine riesige Textdatei so weit wie möglich aufzuteilen. Dadurch wird die Sicherung inkonsistent, aber in den meisten Fällen ist dies kein Problem - wenn Sie den gesamten Datensatz in einen konsistenten Zustand zurückversetzen müssen, verwenden Sie eine physische Sicherung, die in dieser Hinsicht viel schneller ist. Wenn Sie nur eine Teilmenge von Daten wiederherstellen müssen, sind die Konsistenzanforderungen weniger streng.
Point-in-Time-Wiederherstellung
Die Sicherung ist nur ein Anfang – Sie können Ihre Daten bis zu dem Zeitpunkt wiederherstellen, an dem die Sicherung erstellt wurde, aber höchstwahrscheinlich wurden die Daten nach diesem Zeitpunkt entfernt. Nur durch das Wiederherstellen fehlender Daten aus der letzten Sicherung können Sie alle Daten verlieren, die nach der Sicherung geändert wurden. Um dies zu vermeiden, sollten Sie Point-In-Time Recovery implementieren. Für MySQL bedeutet dies im Grunde, dass Sie Binärprotokolle verwenden müssen, um alle Änderungen wiederzugeben, die zwischen dem Moment der Sicherung und dem Datenverlustereignis aufgetreten sind. Der folgende Screenshot zeigt, wie ClusterControl dabei helfen kann.
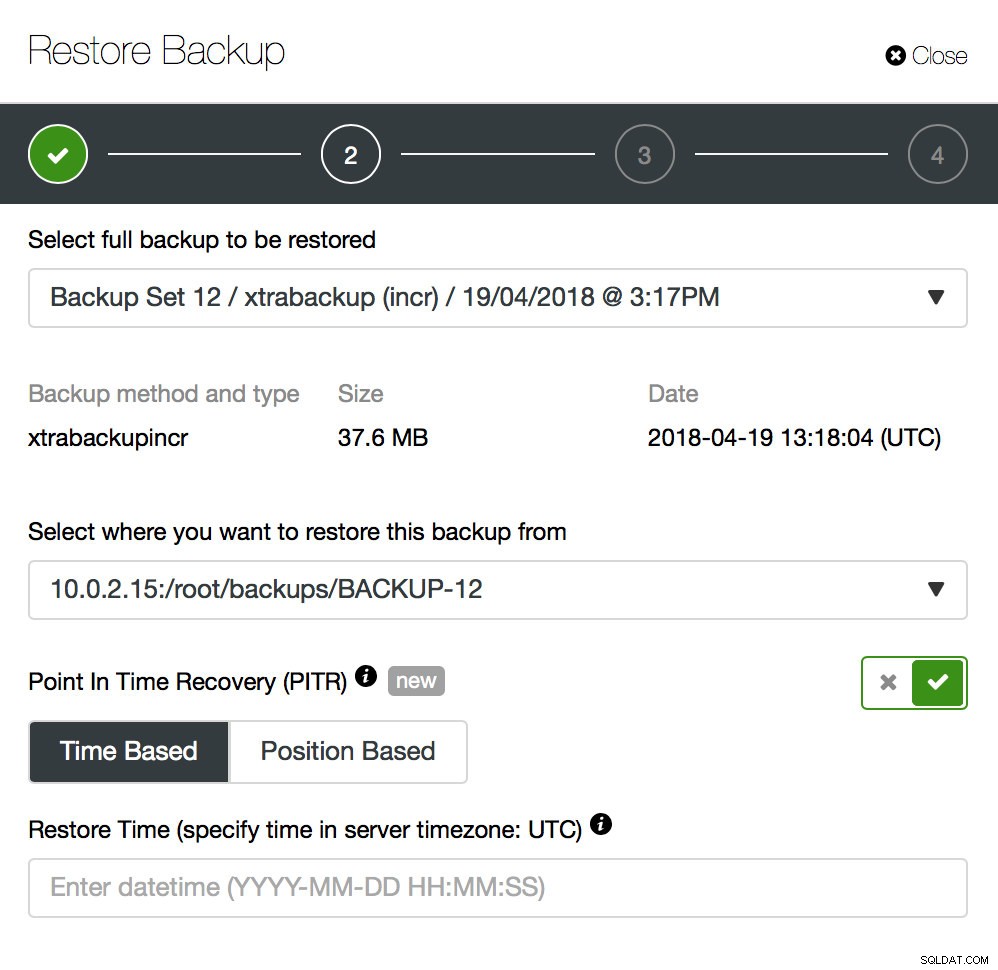
Was Sie tun müssen, ist, diese Sicherung bis zum Zeitpunkt kurz vor dem Datenverlust wiederherzustellen. Sie müssen es auf einem separaten Host wiederherstellen, um keine Änderungen am Produktionscluster vorzunehmen. Sobald Sie die Sicherung wiederhergestellt haben, können Sie sich bei diesem Host anmelden, die fehlenden Daten finden, sie sichern und auf dem Produktionscluster wiederherstellen.
Verzögerter Sklave
Alle oben besprochenen Methoden haben einen gemeinsamen Schmerzpunkt – es braucht Zeit, um die Daten wiederherzustellen. Es kann länger dauern, wenn Sie alle Daten wiederherstellen und dann versuchen, nur den interessanten Teil zu sichern. Es kann weniger Zeit in Anspruch nehmen, wenn Sie über ein logisches Backup verfügen und Sie können schnell zu den Daten gelangen, die Sie wiederherstellen möchten, aber es ist keineswegs eine schnelle Aufgabe. Sie müssen noch ein paar Zeilen in einer großen Textdatei finden. Je größer es ist, desto komplizierter wird die Aufgabe – manchmal verlangsamt die schiere Größe der Datei alle Aktionen. Eine Methode, um diese Probleme zu vermeiden, besteht darin, einen verzögerten Slave zu haben. Slaves versuchen normalerweise, mit dem Master auf dem Laufenden zu bleiben, aber es ist auch möglich, sie so zu konfigurieren, dass sie Abstand zu ihrem Master halten. Im folgenden Screenshot sehen Sie, wie Sie ClusterControl verwenden, um einen solchen Slave bereitzustellen:
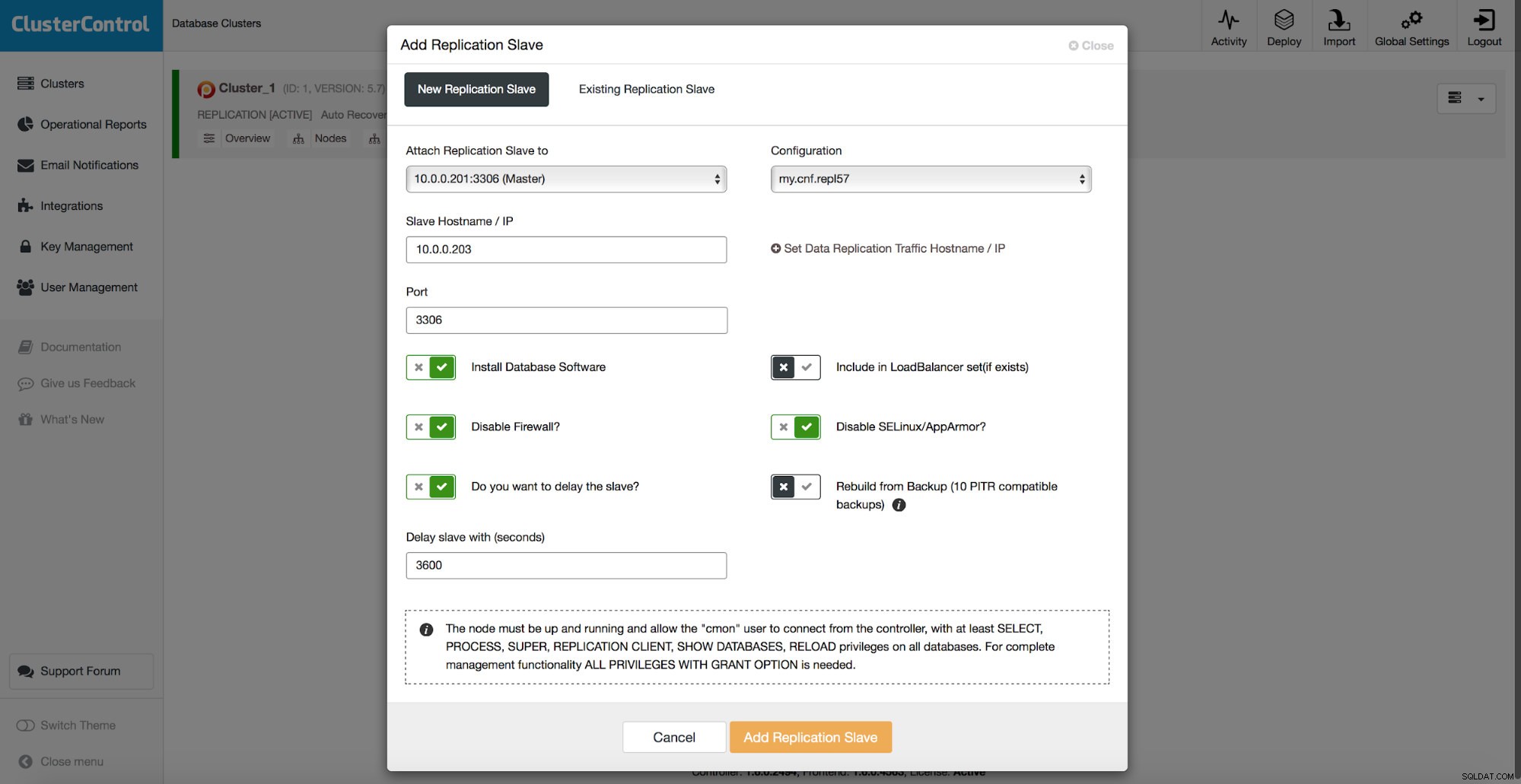
Kurz gesagt, wir haben hier die Möglichkeit, einen Replikations-Slave zum Datenbank-Setup hinzuzufügen und ihn so zu konfigurieren, dass er verzögert wird. Im obigen Screenshot wird der Slave um 3600 Sekunden verzögert, was einer Stunde entspricht. Auf diese Weise können Sie diesen Slave verwenden, um die entfernten Daten bis zu einer Stunde nach der Datenlöschung wiederherzustellen. Sie müssen kein Backup wiederherstellen, es reicht aus, mysqldump oder SELECT ... INTO OUTFILE für die fehlenden Daten auszuführen, und Sie erhalten die Daten, die Sie auf Ihrem Produktionscluster wiederherstellen können.
Daten wiederherstellen
In diesem Abschnitt gehen wir einige Beispiele für versehentliches Löschen von Daten durch und wie Sie sie wiederherstellen können. Wir werden durch die Wiederherstellung nach einem vollständigen Datenverlust gehen, wir werden auch zeigen, wie man sich nach einem teilweisen Datenverlust wiederherstellt, wenn man physische und logische Sicherungen verwendet. Wir zeigen Ihnen schließlich, wie Sie versehentlich gelöschte Zeilen wiederherstellen können, wenn Sie einen verzögerten Slave in Ihrem Setup haben.
Vollständiger Datenverlust
Versehentliches „rm -rf“ oder „DROP SCHEMA myonlyschema;“ wurde ausgeführt und Sie hatten am Ende überhaupt keine Daten. Wenn Sie zufällig auch andere Dateien als aus dem MySQL-Datenverzeichnis entfernt haben, müssen Sie den Host möglicherweise neu bereitstellen. Der Einfachheit halber gehen wir davon aus, dass nur MySQL betroffen ist. Betrachten wir zwei Fälle, mit einem verzögerten Slave und ohne einen.
Kein verzögerter Slave
In diesem Fall können wir nur das letzte physische Backup wiederherstellen. Da alle unsere Daten entfernt wurden, müssen wir uns keine Sorgen über Aktivitäten machen, die nach dem Datenverlust aufgetreten sind, denn ohne Daten gibt es keine Aktivität. Wir sollten uns Sorgen über die Aktivitäten machen, die nach der Sicherung stattfanden. Das bedeutet, dass wir eine Point-in-Time-Wiederherstellung durchführen müssen. Natürlich dauert es länger, als nur Daten aus dem Backup wiederherzustellen. Wenn es wichtiger ist, Ihre Datenbank schnell hochzufahren, als alle Daten wiederherzustellen, können Sie auch einfach ein Backup wiederherstellen und damit fertig sein.
Zunächst einmal, wenn Sie noch Zugriff auf Binärprotokolle auf dem Server haben, den Sie wiederherstellen möchten, können Sie diese für PITR verwenden. Zunächst wollen wir den relevanten Teil der Binärlogs zur weiteren Untersuchung in eine Textdatei umwandeln. Wir wissen, dass der Datenverlust nach 13:00:00 Uhr aufgetreten ist. Lassen Sie uns zuerst prüfen, welche Binlog-Datei wir untersuchen sollten:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Wie man sieht, interessiert uns die letzte Binlog-Datei.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outWenn Sie fertig sind, werfen wir einen Blick auf den Inhalt dieser Datei. Wir werden in vim nach „drop schema“ suchen. Hier ist ein relevanter Teil der Datei:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Wie wir sehen, wollen wir bis Position 320358785 wiederherstellen. Wir können diese Daten an die ClusterControl-UI übergeben:
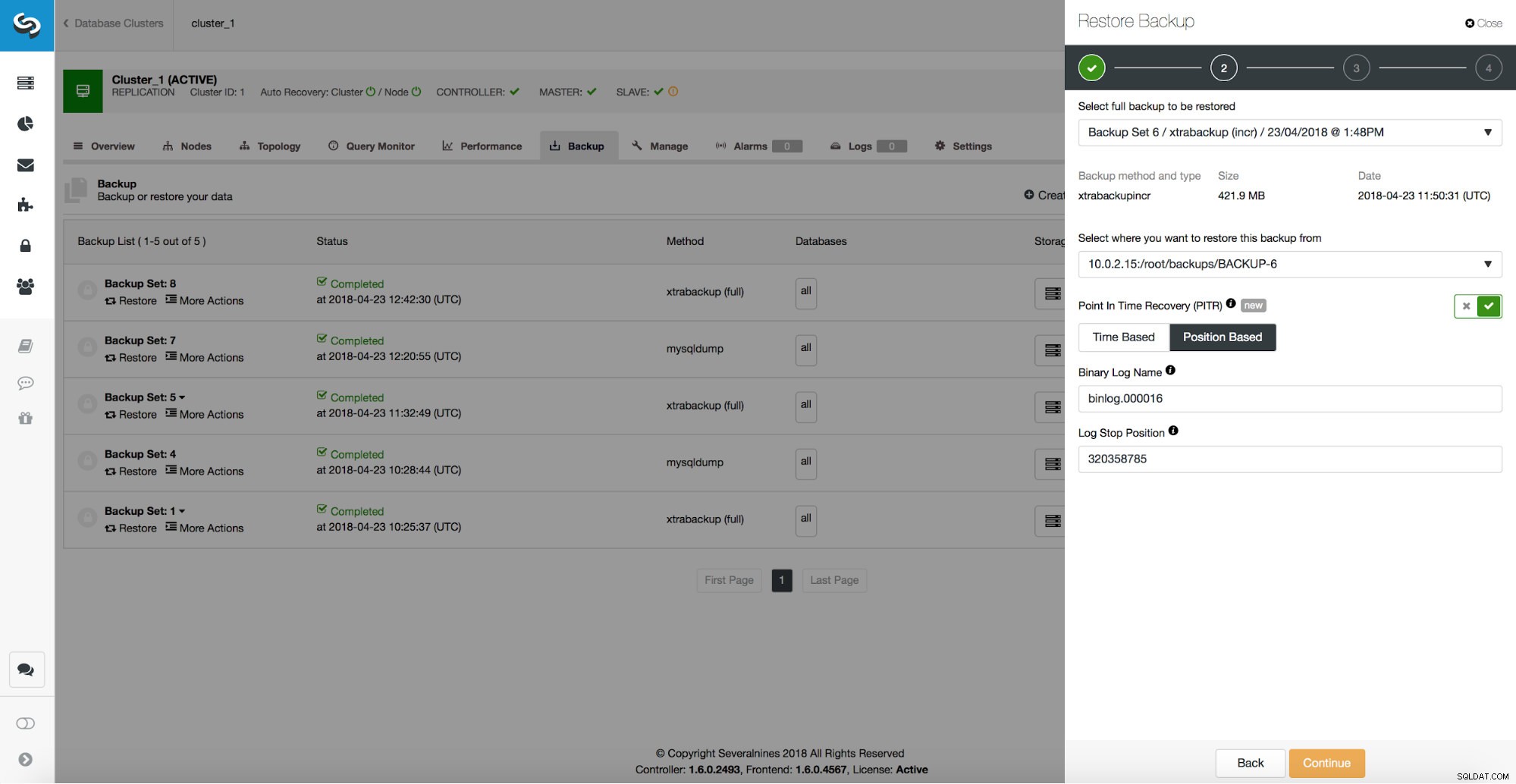
Verzögerter Sklave
Wenn wir einen verzögerten Slave haben und dieser Host ausreicht, um den gesamten Datenverkehr zu bewältigen, können wir ihn verwenden und zum Master machen. Zunächst müssen wir aber dafür sorgen, dass der alte Master bis zum Datenverlust eingeholt wird. Wir werden hier eine CLI verwenden, um dies zu erreichen. Zuerst müssen wir herausfinden, an welcher Stelle der Datenverlust aufgetreten ist. Dann stoppen wir den Slave und lassen ihn bis zum Datenverlustereignis laufen. Wir haben im vorherigen Abschnitt gezeigt, wie man die richtige Position erhält - durch Untersuchung von Binärlogs. Wir können entweder diese Position verwenden (binlog.000016, Position 320358785) oder, wenn wir einen Multithread-Slave verwenden, sollten wir die GTID des Datenverlustereignisses verwenden (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) und Abfragen bis zu wiederholen diese GTID.
Lassen Sie uns zuerst den Slave stoppen und die Verzögerung deaktivieren:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Dann können wir es bis zu einer bestimmten Binärlog-Position starten.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Wenn wir GTID verwenden möchten, sieht der Befehl anders aus:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)Sobald die Replikation gestoppt wurde (was bedeutet, dass alle von uns angeforderten Ereignisse ausgeführt wurden), sollten wir überprüfen, ob der Host die fehlenden Daten enthält. Wenn dies der Fall ist, können Sie ihn zum Master hochstufen und dann andere Hosts neu erstellen, indem Sie den neuen Master als Datenquelle verwenden.
Dies ist nicht immer die beste Option. Alles hängt davon ab, wie verspätet Ihr Slave ist - wenn er um ein paar Stunden verspätet ist, macht es möglicherweise keinen Sinn, darauf zu warten, dass er aufholt, insbesondere wenn der Schreibverkehr in Ihrer Umgebung stark ist. In einem solchen Fall ist es höchstwahrscheinlich schneller, Hosts mithilfe eines physischen Backups neu aufzubauen. Wenn Sie andererseits ein eher geringes Verkehrsaufkommen haben, könnte dies eine gute Möglichkeit sein, das Problem tatsächlich schnell zu beheben, einen neuen Master zu fördern und mit dem Bereitstellen des Verkehrs fortzufahren, während der Rest der Knoten im Hintergrund neu erstellt wird .
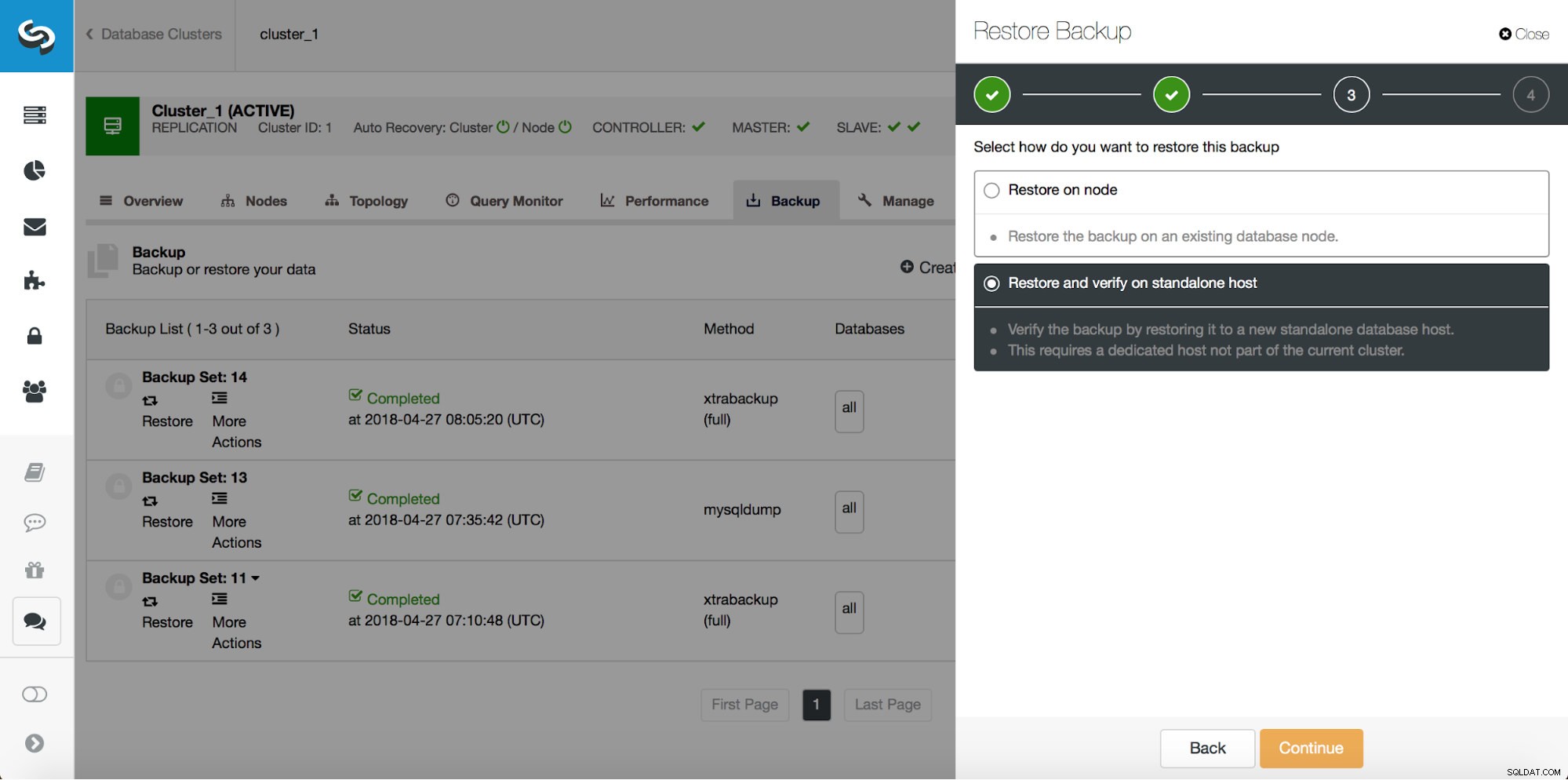
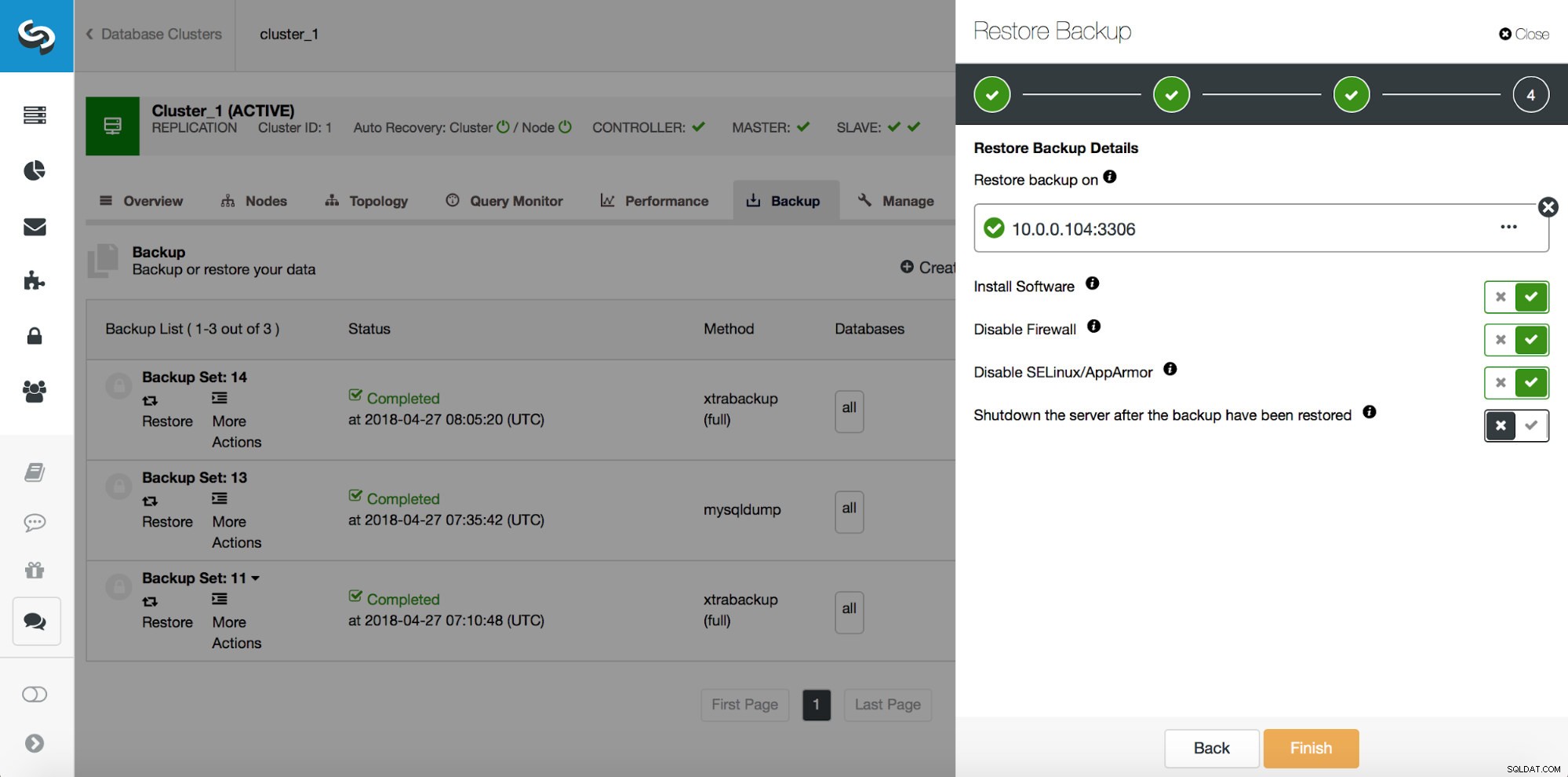
Teilweiser Datenverlust – Physische Sicherung
Im Falle eines teilweisen Datenverlusts können physische Sicherungen ineffizient sein, aber da dies die häufigste Art einer Sicherung ist, ist es sehr wichtig zu wissen, wie man sie für eine teilweise Wiederherstellung verwendet. Der erste Schritt besteht immer darin, ein Backup bis zu einem Zeitpunkt vor dem Datenverlustereignis wiederherzustellen. Es ist auch sehr wichtig, es auf einem separaten Host wiederherzustellen. ClusterControl verwendet xtrabackup für physische Backups, daher werden wir zeigen, wie es verwendet wird. Nehmen wir an, wir haben die folgende falsche Abfrage ausgeführt:
DELETE FROM sbtest1 WHERE id < 23146;
Wir wollten nur eine einzelne Zeile löschen (‘=’ in der WHERE-Klausel), stattdessen haben wir eine Reihe davon gelöscht (
Schauen wir uns nun die Ausgabedatei an und sehen, was wir dort finden können. Wir verwenden die zeilenbasierte Replikation, daher sehen wir nicht das genaue SQL, das ausgeführt wurde. Stattdessen (solange wir das Flag --verbose für mysqlbinlog verwenden) sehen wir Ereignisse wie unten:
Wie zu sehen ist, identifiziert MySQL zu löschende Zeilen mit einer sehr präzisen WHERE-Bedingung. Mysteriöse Zeichen im menschenlesbaren Kommentar „@1“, „@2“ bedeuten „erste Spalte“, „zweite Spalte“. Wir wissen, dass die erste Spalte „id“ ist, was uns interessiert. Wir müssen ein großes DELETE-Ereignis in einer „sbtest1“-Tabelle finden. Kommentare, die folgen, sollten die ID von 1, dann die ID von „2“, dann „3“ und so weiter erwähnen – alles bis zur ID von „23145“. Alle sollten in einer einzigen Transaktion ausgeführt werden (einzelnes Ereignis in einem Binärprotokoll). Nachdem wir die Ausgabe mit „weniger“ analysiert hatten, fanden wir:
Das Ereignis, an das diese Kommentare angehängt sind, begann bei:
Also wollen wir das Backup bis zum vorherigen Commit an Position 29600687 wiederherstellen. Lassen Sie uns das jetzt tun. Dafür verwenden wir einen externen Server. Wir werden die Sicherung bis zu dieser Position wiederherstellen und den Wiederherstellungsserver am Laufen halten, damit wir später die fehlenden Daten extrahieren können.
Stellen Sie nach Abschluss der Wiederherstellung sicher, dass unsere Daten wiederhergestellt wurden:
Sieht gut aus. Jetzt können wir diese Daten in eine Datei extrahieren, die wir wieder auf den Master laden.
Irgendetwas stimmt nicht - das liegt daran, dass der Server so konfiguriert ist, dass er Dateien nur an einem bestimmten Ort schreiben kann - es geht nur um Sicherheit, wir möchten Benutzern nicht erlauben, Inhalte an einem beliebigen Ort zu speichern. Lassen Sie uns prüfen, wo wir unsere Datei speichern können:
Ok, versuchen wir es noch einmal:
Jetzt sieht es viel besser aus. Kopieren wir die Daten auf den Master:
Jetzt ist es an der Zeit, die fehlenden Zeilen auf den Master zu laden und zu testen, ob es erfolgreich war:
Das ist alles, wir haben unsere fehlenden Daten wiederhergestellt.
Im vorherigen Abschnitt haben wir verlorene Daten mithilfe eines physischen Backups und eines externen Servers wiederhergestellt. Was wäre, wenn wir ein logisches Backup erstellt hätten? Lass uns mal sehen. Lassen Sie uns zunächst überprüfen, ob wir ein logisches Backup haben:
Ja, es ist da. Jetzt ist es an der Zeit, es zu dekomprimieren.
Wenn Sie es sich ansehen, werden Sie sehen, dass die Daten im mehrwertigen INSERT-Format gespeichert sind. Zum Beispiel:
Jetzt müssen wir nur noch lokalisieren, wo sich unsere Tabelle befindet und wo dann die für uns interessanten Zeilen gespeichert sind. Nachdem wir mysqldump-Muster kennen (Tabelle löschen, neue erstellen, Indizes deaktivieren, Daten einfügen), wollen wir zunächst herausfinden, welche Zeile die CREATE TABLE-Anweisung für die Tabelle „sbtest1“ enthält:
Jetzt müssen wir mithilfe einer Trial-and-Error-Methode herausfinden, wo wir nach unseren Zeilen suchen müssen. Wir zeigen Ihnen den letzten Befehl, den wir uns ausgedacht haben. Der ganze Trick besteht darin, mit sed verschiedene Zeilenbereiche zu drucken und dann zu prüfen, ob die letzte Zeile Zeilen in der Nähe, aber später als das, was wir suchen, enthält. Im folgenden Befehl suchen wir nach Zeilen zwischen 971 (CREATE TABLE) und 993. Außerdem bitten wir sed, sich zu beenden, sobald es Zeile 994 erreicht, da der Rest der Datei für uns nicht von Interesse ist:
Die Ausgabe sieht wie folgt aus:
Dies bedeutet, dass unser Zeilenbereich (bis zur Zeile mit der ID 23145) nah ist. Als nächstes geht es um die manuelle Bereinigung der Datei. Wir möchten, dass es mit der ersten Zeile beginnt, die wir wiederherstellen müssen:
Und enden Sie mit der letzten wiederherzustellenden Zeile:
Wir mussten einige der nicht benötigten Daten kürzen (es handelt sich um eine mehrzeilige Einfügung), aber nach all dem haben wir eine Datei, die wir wieder auf den Master laden können.
Abschließend letzte Prüfung:
Alles ist gut, Daten wurden wiederhergestellt.
In diesem Fall werden wir nicht den gesamten Prozess durchlaufen. Wir haben bereits beschrieben, wie Sie die Position eines Datenverlustereignisses in den Binärprotokollen identifizieren können. Wir haben auch beschrieben, wie Sie einen verzögerten Slave stoppen und die Replikation bis zu einem Punkt vor dem Datenverlustereignis erneut starten können. Wir haben auch erklärt, wie man SELECT INTO OUTFILE und LOAD DATA INFILE verwendet, um Daten von einem externen Server zu exportieren und auf den Master zu laden. Das ist alles, was Sie brauchen. Solange die Daten noch auf dem verzögerten Slave sind, müssen Sie ihn stoppen. Dann müssen Sie die Position vor dem Datenverlust lokalisieren, den Slave bis zu diesem Punkt starten und anschließend den verzögerten Slave verwenden, um gelöschte Daten zu extrahieren, die Datei auf den Master zu kopieren und sie zu laden, um die Daten wiederherzustellen .
Das Wiederherstellen verlorener Daten macht keinen Spaß, aber wenn Sie die Schritte befolgen, die wir in diesem Blog beschrieben haben, haben Sie gute Chancen, verlorene Daten wiederherzustellen.mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826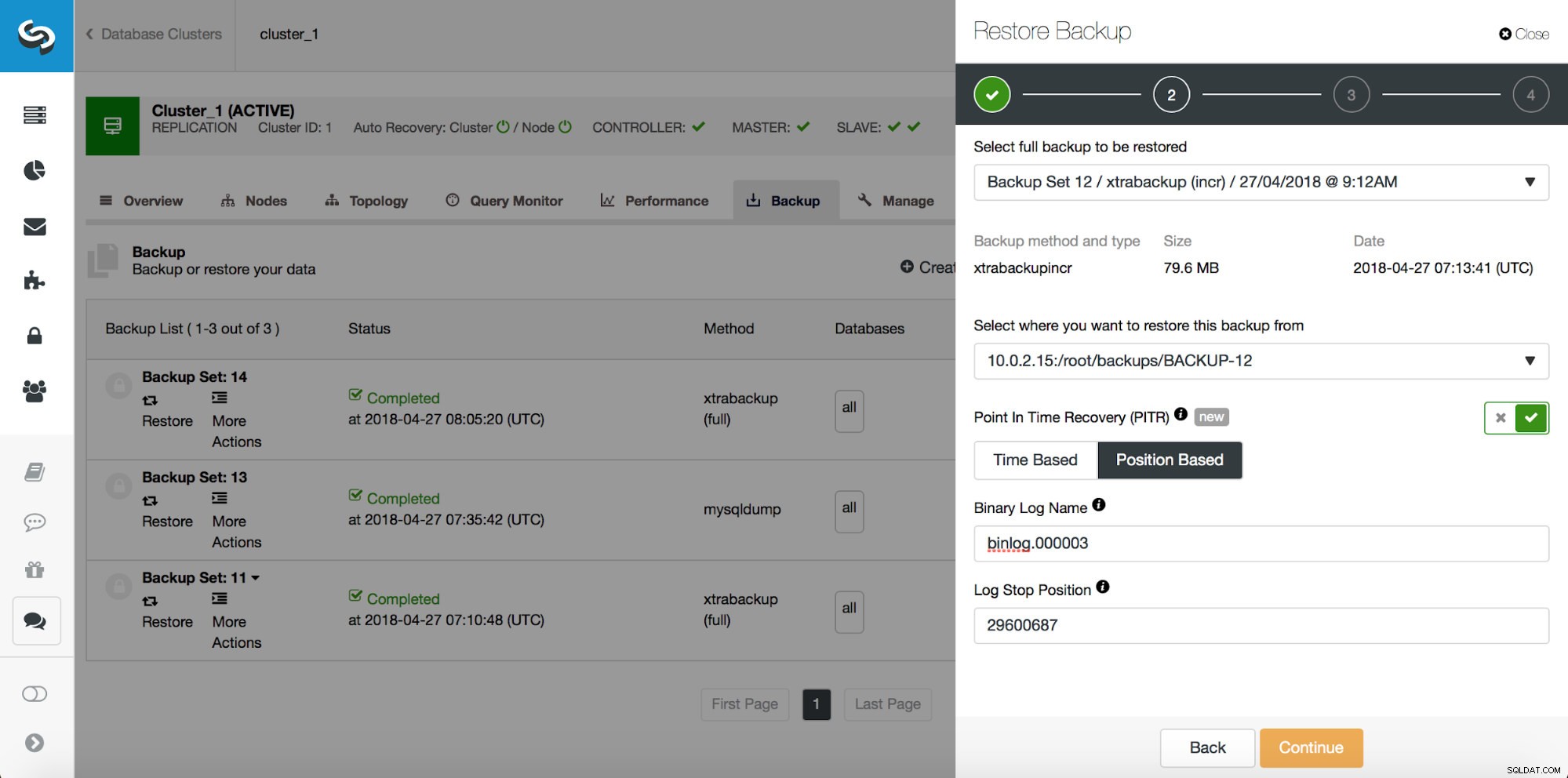
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Teilweiser Datenverlust – Logische Sicherung
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzexample@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlINSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessINSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Teilweiser Datenverlust, verzögerter Slave
Schlussfolgerung



