Da hohe Verfügbarkeit in der heutigen Geschäftsrealität von größter Bedeutung ist, besteht eines der häufigsten Szenarien für Benutzer darin, sicherzustellen, dass die Datenbank immer für die Anwendung verfügbar ist.
Jeder Dienstanbieter ist mit einem ererbten Risiko einer Dienstunterbrechung verbunden, daher besteht einer der Schritte, die unternommen werden können, darin, sich auf mehrere Anbieter zu verlassen, um das Risiko und zusätzliche Redundanz zu mindern.
Cloud-Dienstanbieter sind da nicht anders - sie können ausfallen und Sie sollten dies im Voraus planen. Welche Optionen sind für MariaDB-Cluster verfügbar? Werfen wir einen Blick darauf in diesem Blogbeitrag.
MariaDB-Datenbank-Clustering in Multi-Cloud-Umgebungen
Wenn das von einem Cloud-Dienstanbieter vorgeschlagene SLA nicht ausreicht, besteht immer die Möglichkeit, außerhalb dieses Anbieters eine Disaster-Recovery-Site zu erstellen. Dadurch können Sie immer dann, wenn einer der Cloud-Anbieter eine Serviceverschlechterung erfährt, jederzeit zu einem anderen Anbieter wechseln und Ihre Datenbank betriebsbereit und verfügbar halten.
Eines der typischen Probleme für Multi-Cloud-Setups ist die Netzwerklatenz, die unvermeidlich ist, wenn wir über größere Entfernungen oder im Allgemeinen mehrere geografisch getrennte Standorte sprechen. Die Lichtgeschwindigkeit ist ziemlich hoch, aber sie ist endlich, jeder Hop, jeder Router fügt auch etwas Latenz in die Netzwerkinfrastruktur ein.
MariaDB-Cluster funktioniert hervorragend in Netzwerken mit geringer Latenz. Es ist ein Quorum-basierter Cluster, bei dem eine schnelle Kommunikation zwischen allen Knoten erforderlich ist, um den Betrieb reibungslos zu halten. Eine Erhöhung der Netzwerklatenz wirkt sich auf den Clusterbetrieb aus, insbesondere auf die Leistung der Schreibvorgänge. Es gibt mehrere Möglichkeiten, wie dieses Problem angegangen werden kann.
Zunächst haben wir die Möglichkeit, separate Cluster zu verwenden, die über asynchrone Replikationslinks verbunden sind. Dadurch können wir die Latenz fast vergessen, da die asynchrone Replikation wesentlich besser für die Arbeit in Umgebungen mit hoher Latenz geeignet ist.
Eine andere Option ist, dass Sie angesichts von Netzwerken mit geringer Latenz zwischen Rechenzentren immer noch vollkommen in Ordnung sein könnten, einen MariaDB-Cluster zu betreiben, der sich über mehrere Rechenzentren erstreckt. Schließlich bedeuten mehrere Rechenzentren geografisch gesehen nicht immer große Entfernungen – Sie können auch mehrere Anbieter innerhalb derselben Metropolregion nutzen, die mit schnellen Netzwerken mit geringer Latenz verbunden sind. Dann sprechen wir über eine Erhöhung der Latenz auf höchstens zehn Millisekunden, definitiv nicht auf Hunderte. Es hängt alles von der Anwendung ab, aber eine solche Erhöhung kann akzeptabel sein.
Asynchrone Replikation zwischen MariaDB-Clustern
Werfen wir einen kurzen Blick auf den asynchronen Ansatz. Die Idee ist einfach – zwei Cluster, die durch asynchrone Replikation miteinander verbunden sind.
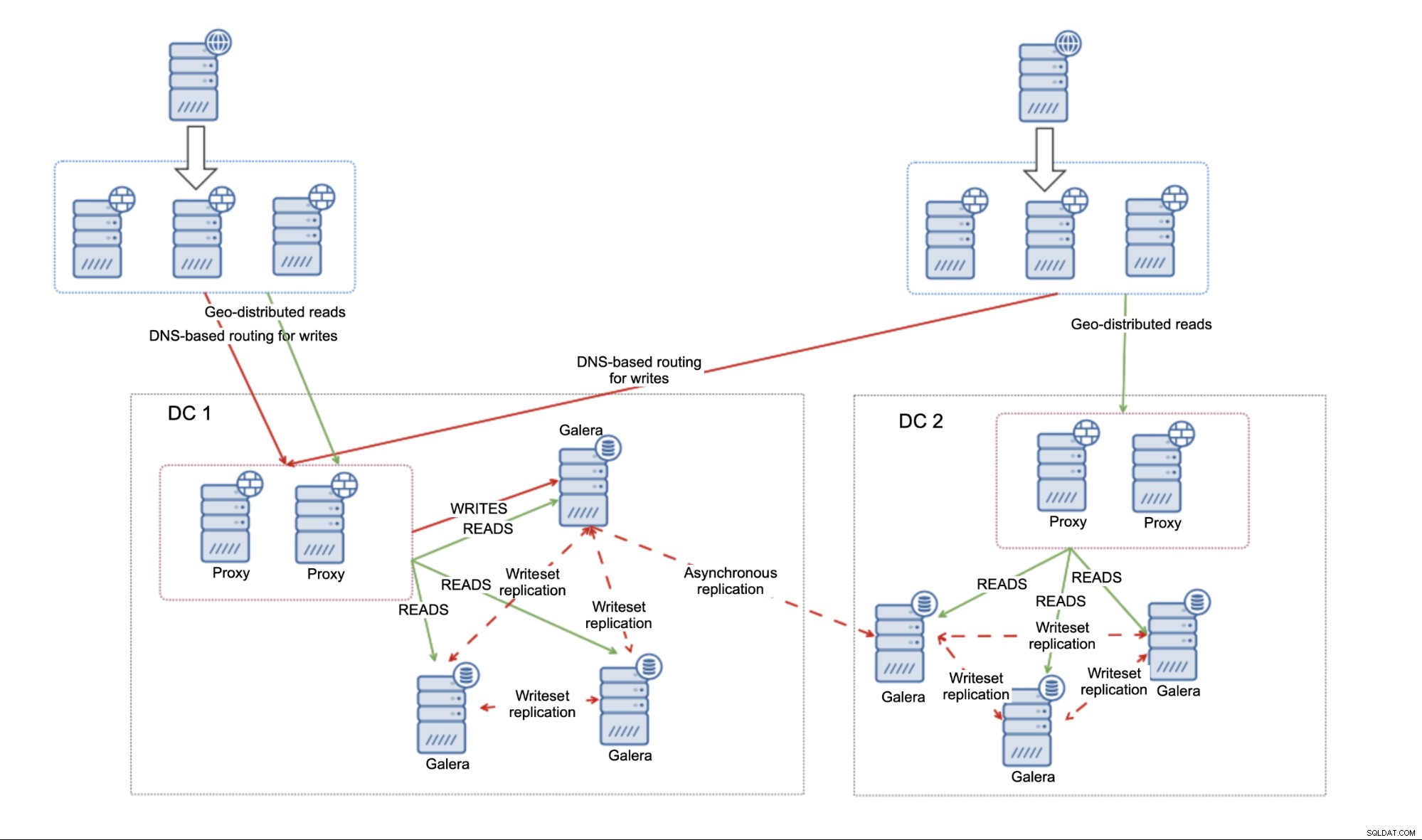
Dies ist mit mehreren Einschränkungen verbunden. Zunächst müssen Sie sich entscheiden, ob Sie Multi-Master verwenden oder den gesamten Datenverkehr nur an ein Rechenzentrum senden möchten. Wir empfehlen, davon abzusehen, in beide Rechenzentren zu schreiben und eine Master-Master-Replikation zu verwenden. Dies kann zu ernsthaften Problemen führen, wenn Sie nicht vorsichtig sind.
Wenn Sie sich entscheiden, das Aktiv-Passiv-Setup zu verwenden, möchten Sie wahrscheinlich eine Art DNS-basiertes Routing für Schreibvorgänge implementieren, um sicherzustellen, dass Ihre Anwendungsserver immer eine Verbindung zu einer Reihe von Proxys, die sich im aktiven Rechenzentrum befinden. Dies kann entweder buchstäblich durch einen DNS-Eintrag erreicht werden, der geändert wird, wenn ein Failover erforderlich ist, oder es kann durch eine Art Diensterkennungslösung wie Consul oder etcd erfolgen.
Der Hauptnachteil der Umgebung, die mit asynchroner Replikation erstellt wurde, ist die fehlende Fähigkeit, mit Netzwerkaufteilungen zwischen Rechenzentren umzugehen. Dies wird von der Replikation geerbt - egal, was Sie mit der Replikation verknüpfen möchten (einzelne Knoten, MariaDB-Cluster), es gibt keine Möglichkeit, die Tatsache zu umgehen, dass die Replikation nicht Quorum-fähig ist. Es gibt keinen Mechanismus, um den Zustand der Knoten zu verfolgen und das allgemeine Bild der gesamten Topologie zu verstehen. Wenn also die Verbindung zwischen zwei Rechenzentren unterbrochen wird, haben Sie am Ende zwei separate MariaDB-Cluster, die nicht verbunden sind und beide bereit sind, Datenverkehr zu akzeptieren. Es ist Sache des Benutzers zu definieren, was in einem solchen Fall zu tun ist. Es ist möglich, zusätzliche Tools zu implementieren, die den Zustand der Datenbanken von außen (d. h. vom dritten Rechenzentrum) überwachen und dann basierend auf diesen Informationen Maßnahmen ergreifen (oder keine Maßnahmen ergreifen). Es ist auch möglich, Tools zusammenzustellen, die die Infrastruktur mit Datenbanken teilen, aber Cluster-fähig sind und den Zustand der Konnektivität des Rechenzentrums verfolgen und als Quelle der Wahrheit für die Skripts verwendet werden können, die die Umgebung verwalten würden. Beispielsweise kann ClusterControl in einem Drei-Knoten-Cluster, Knoten pro Rechenzentrum, bereitgestellt werden, das das RAFT-Protokoll verwendet, um das Quorum sicherzustellen. Wenn ein Knoten die Konnektivität mit dem Rest des Clusters verliert, kann davon ausgegangen werden, dass das Rechenzentrum eine Netzwerkpartitionierung erfahren hat.
Multi-DC-MariaDB-Cluster
Alternative zur asynchronen Replikation könnte eine All-MariaDB-Cluster-Lösung sein, die sich über mehrere Rechenzentren erstreckt.
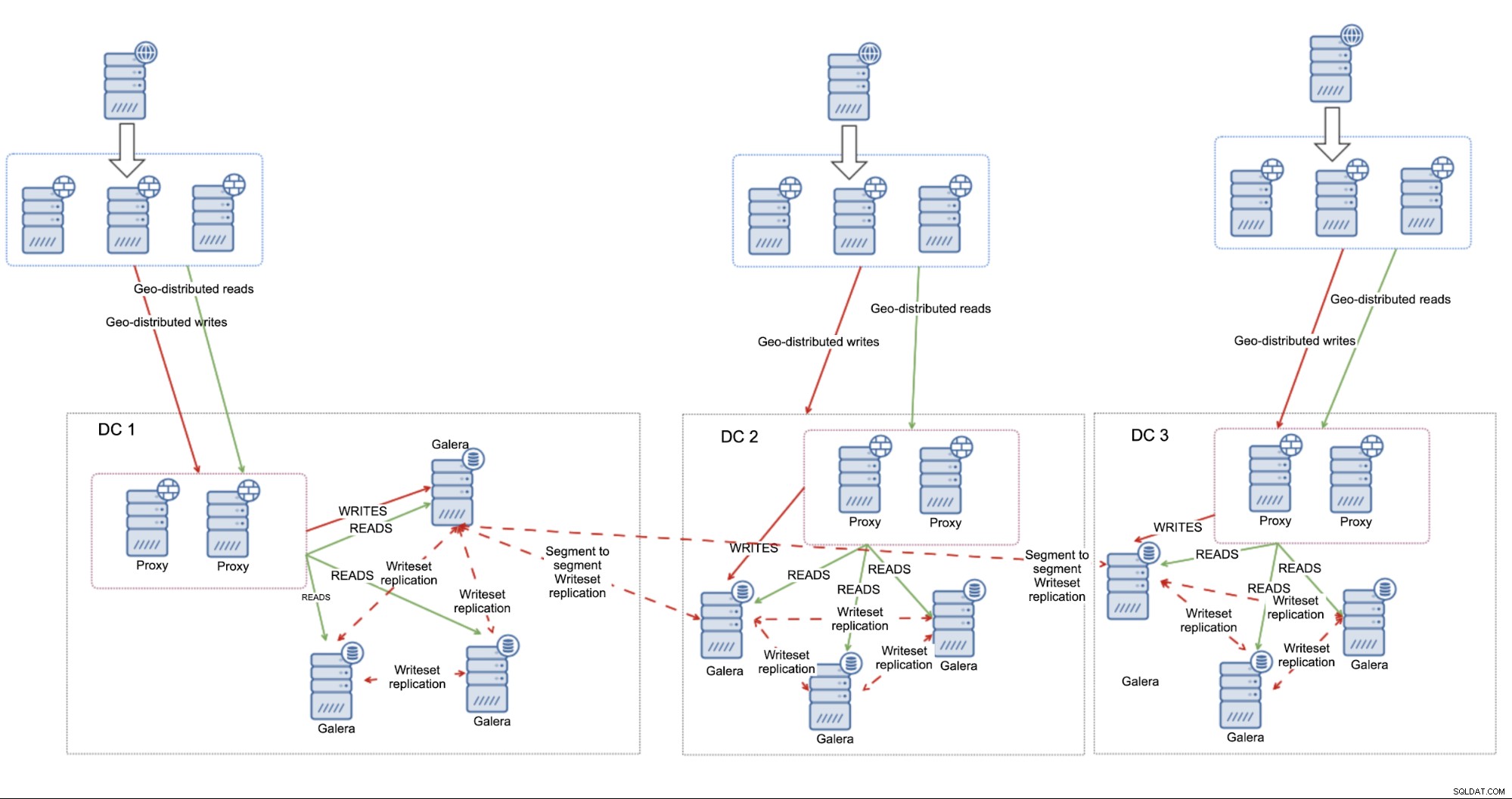
Wie am Anfang dieses Blogs erwähnt, MariaDB Cluster, genau wie jeder Galera-basierte Cluster, wird von der hohen Latenz betroffen sein. Allerdings ist es durchaus akzeptabel, es in Umgebungen mit „nicht so hoher“ Latenz auszuführen und zu erwarten, dass es sich ordnungsgemäß verhält und eine akzeptable Leistung liefert. Alles hängt vom Netzwerkdurchsatz und -design, der Entfernung zwischen den Rechenzentren und den Anwendungsanforderungen ab. Ein solcher Ansatz funktioniert hervorragend, insbesondere wenn wir Segmente verwenden, um separate Rechenzentren zu unterscheiden. Es ermöglicht MariaDB Cluster, seine Intra-Cluster-Konnektivität zu optimieren und den DC-übergreifenden Datenverkehr auf ein Minimum zu reduzieren.
Der Hauptvorteil dieses Setups besteht darin, dass es auf MariaDB-Cluster angewiesen ist, um Fehler zu behandeln. Wenn Sie drei Rechenzentren nutzen, sind Sie gegen die Split-Brain-Situation ziemlich abgesichert – solange es eine Mehrheit gibt, wird es weiter betrieben. Es ist nicht erforderlich, einen vollwertigen Knoten im dritten Rechenzentrum zu haben – Sie können auch Galera Arbitrator verwenden, einen Daemon, der als Teil des Clusters fungiert, aber keine Datenbankoperationen ausführen muss. Es verbindet sich mit den Knoten, nimmt an der Quorum-Berechnung teil und kann zur Weiterleitung des Datenverkehrs verwendet werden, falls die direkte Verbindung zwischen den beiden Rechenzentren nicht funktioniert.
In diesem Fall kann der gesamte Failover-Prozess wie folgt beschrieben werden:Definieren Sie alle Knoten in den Load Balancern (alle, wenn Rechenzentren nahe beieinander liegen, in anderen Fällen möchten Sie möglicherweise eine gewisse Priorität für die Knoten, die sich näher am Load Balancer befinden) und das war's auch schon. MariaDB-Cluster-Knoten, die die Mehrheit bilden, sind über jeden Proxy erreichbar.
Bereitstellen eines Multi-Cloud-MariaDB-Clusters mit ClusterControl
Werfen wir einen Blick auf zwei Optionen, die Sie verwenden können, um Multi-Cloud-MariaDB-Cluster mit ClusterControl bereitzustellen. Bitte beachten Sie, dass ClusterControl eine SSH-Konnektivität zu allen Knoten benötigt, die es verwaltet, sodass es an Ihnen liegt, die Netzwerkkonnektivität über mehrere Rechenzentren oder Cloud-Anbieter hinweg sicherzustellen. Solange die Konnektivität besteht, können wir mit zwei Methoden fortfahren.
Bereitstellen von MariaDB-Clustern mit asynchroner Replikation
ClusterControl kann Ihnen dabei helfen, zwei Cluster bereitzustellen, die über asynchrone Replikation verbunden sind. Wenn Sie einen einzelnen MariaDB-Cluster bereitgestellt haben, möchten Sie sicherstellen, dass auf einem der Knoten binäre Protokolle aktiviert sind. Dadurch können Sie diesen Knoten als Master für den zweiten Cluster verwenden, den wir in Kürze erstellen werden.
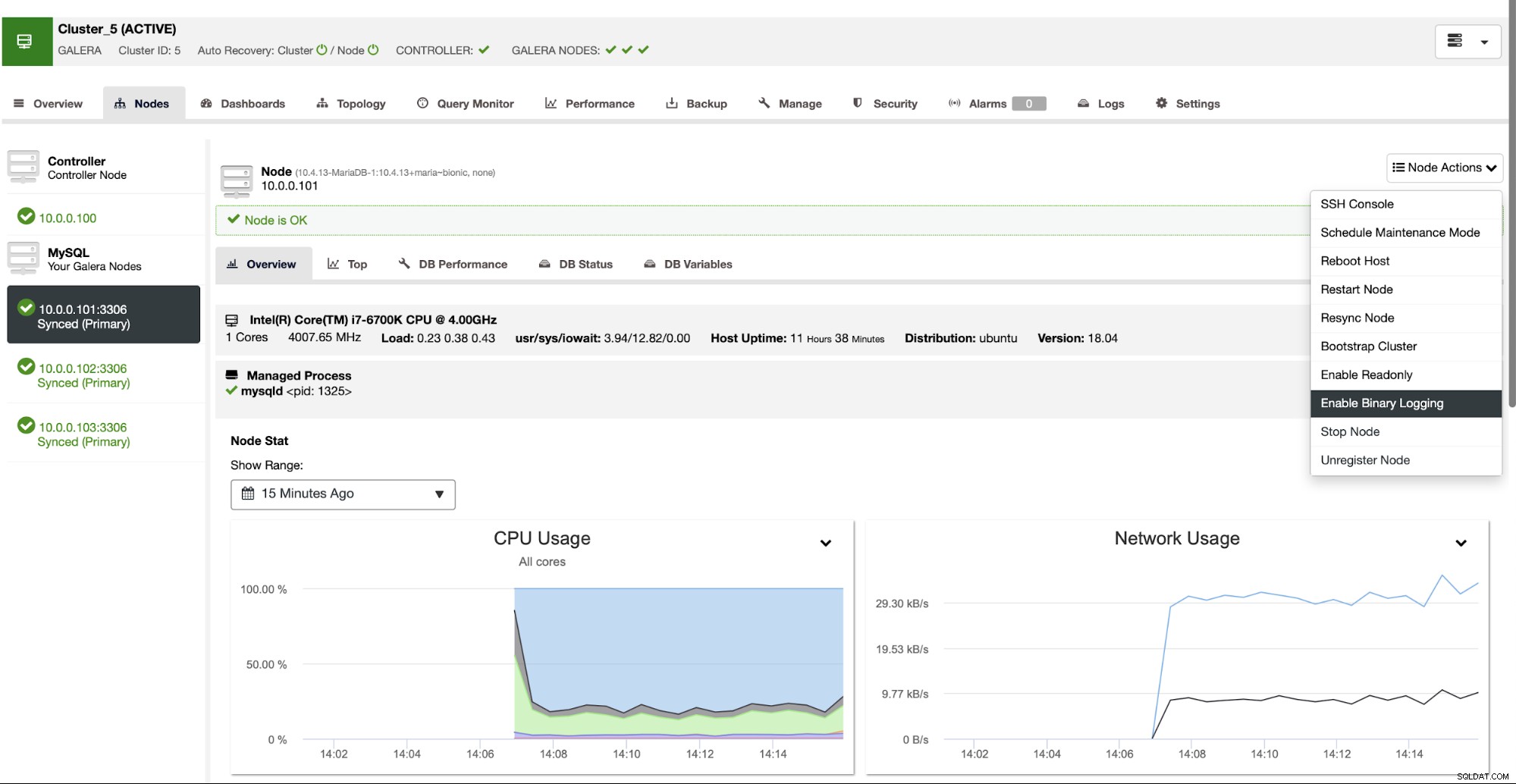
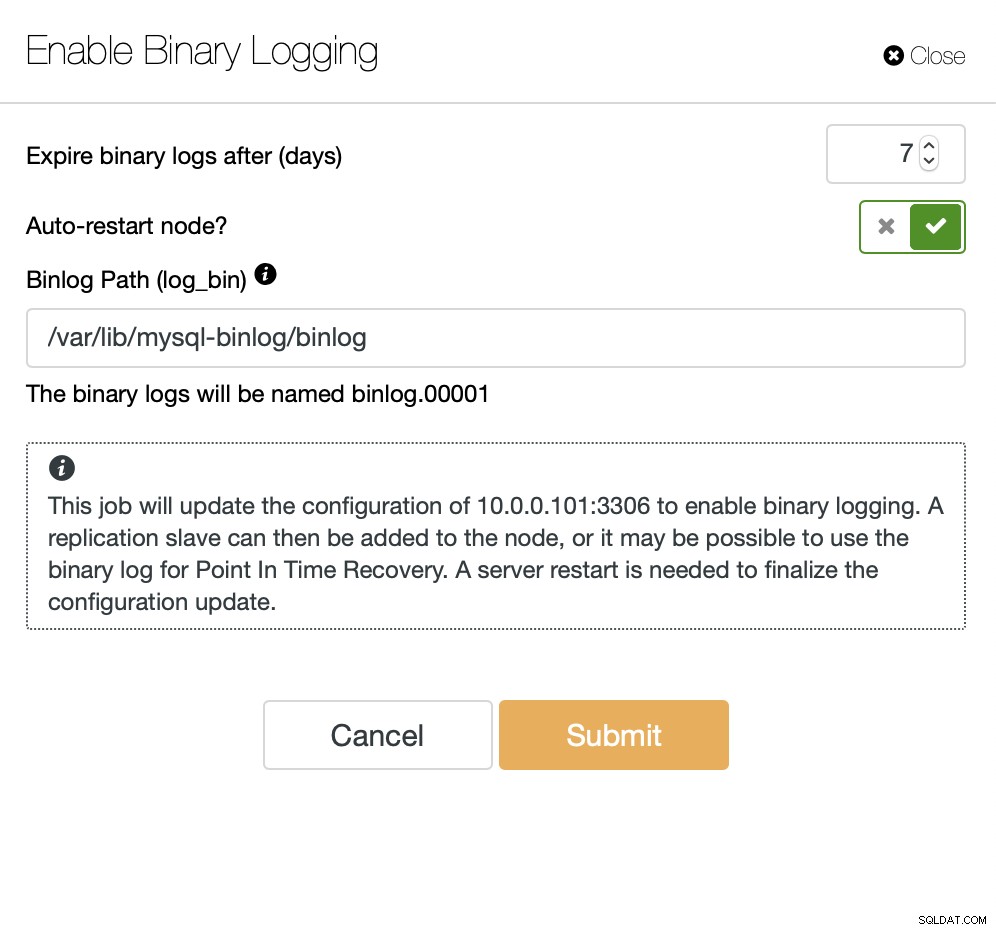
Sobald das Binärprotokoll aktiviert wurde, können wir den Job „Create Slave Cluster“ verwenden um den Einrichtungsassistenten zu starten.
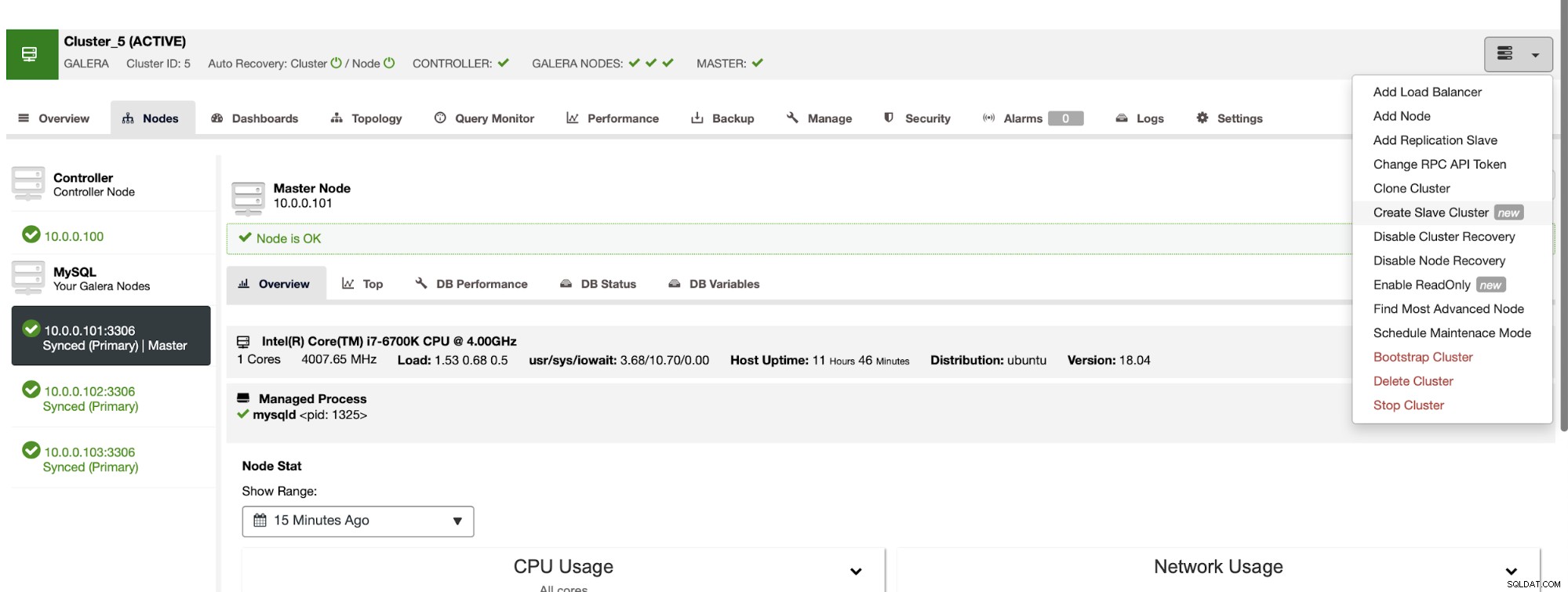
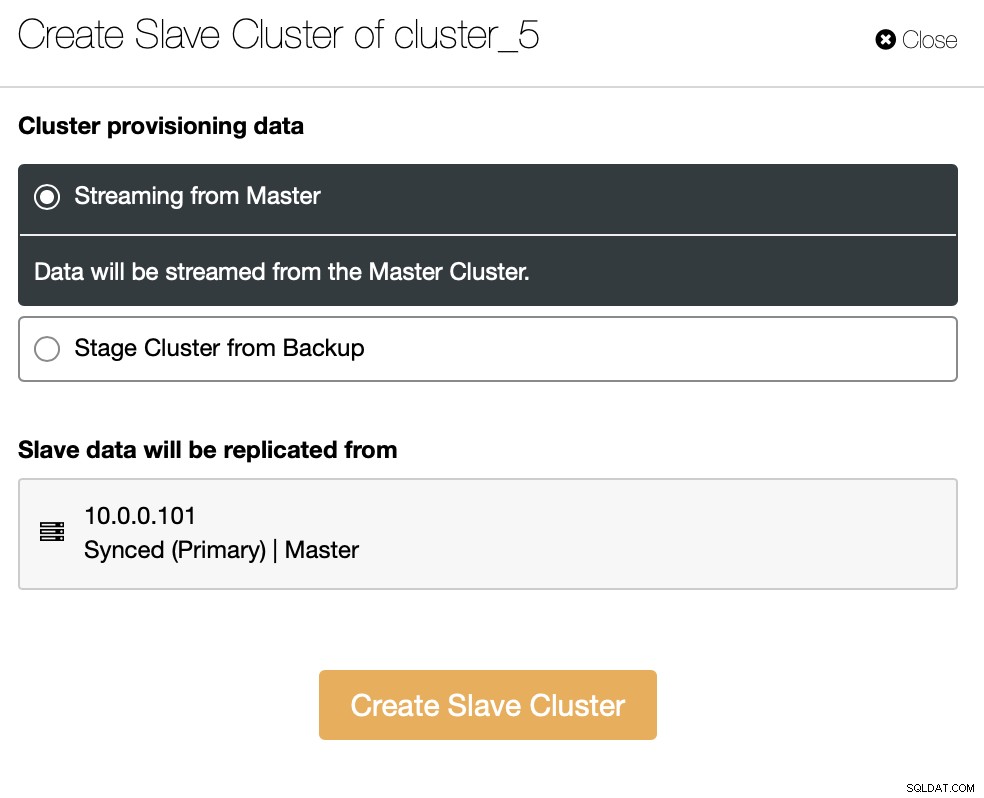
Wir können die Daten entweder direkt vom Master streamen oder Sie können einen verwenden der Backups zur Bereitstellung der Daten.
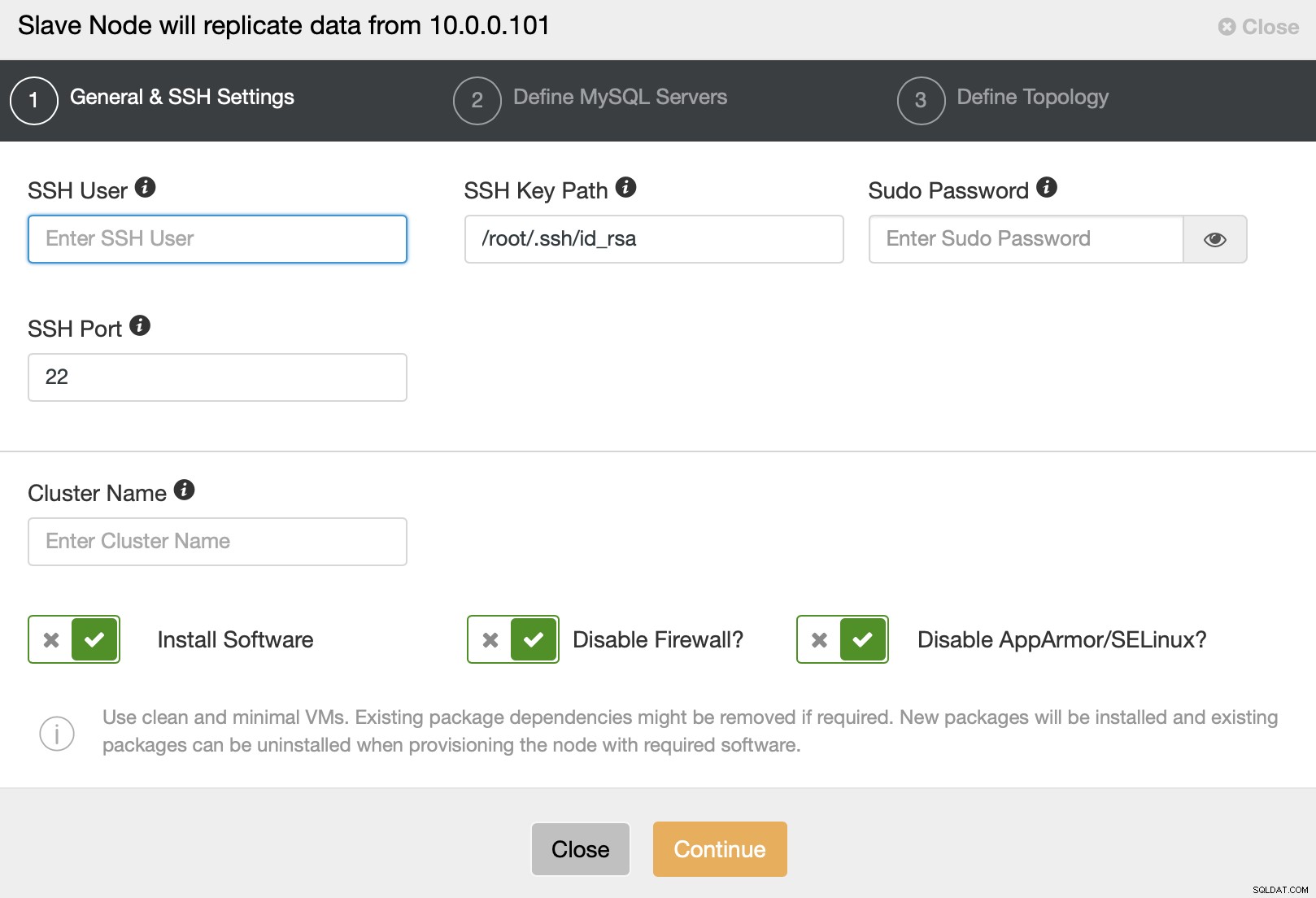
Dann wird Ihnen ein standardmäßiger Clusterbereitstellungsassistent angezeigt, den Sie bestehen müssen Details zur SSH-Verbindung.
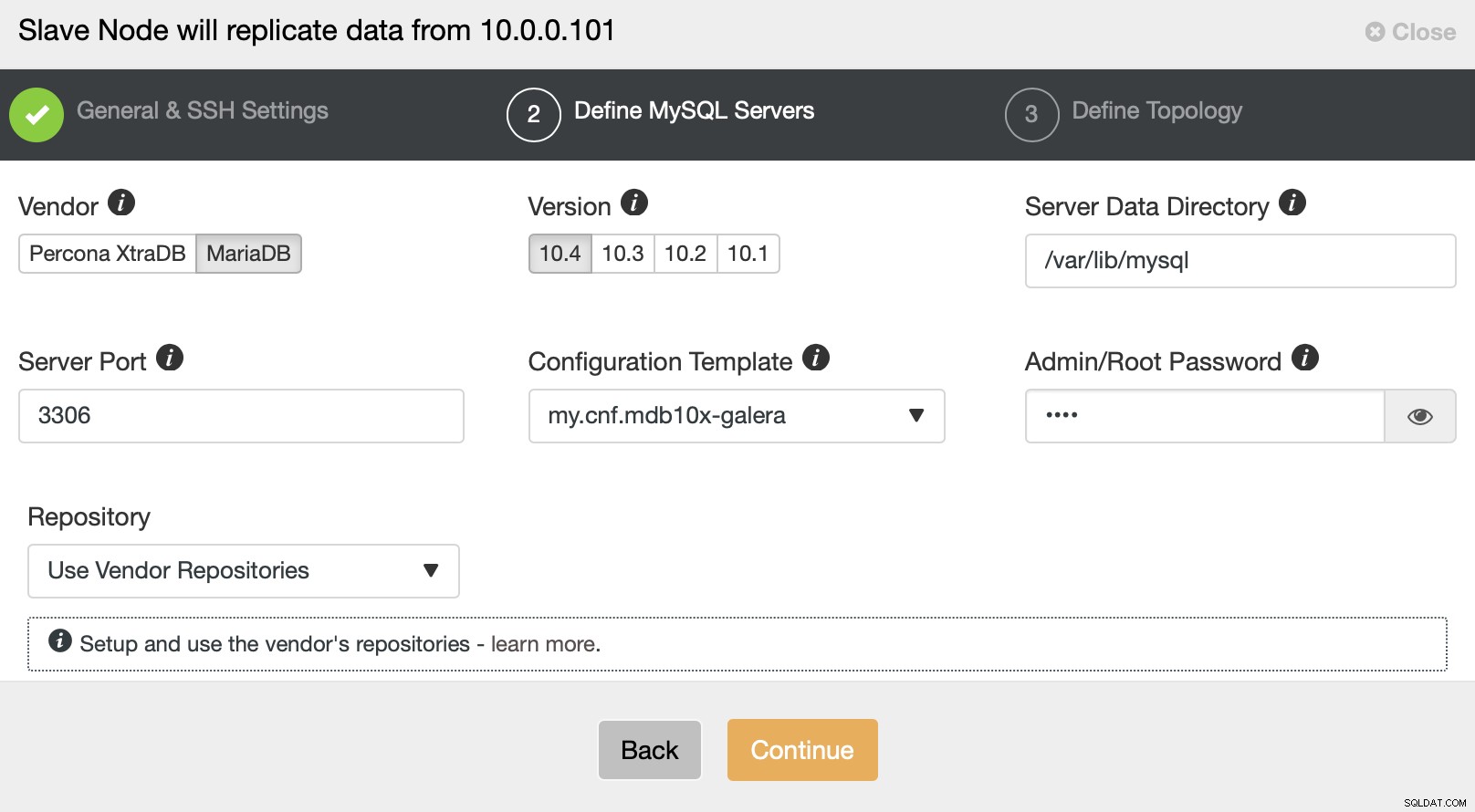
Sie werden auch aufgefordert, den Anbieter und die Version der Datenbanken auszuwählen wie nach dem Passwort für den Root-Benutzer gefragt.
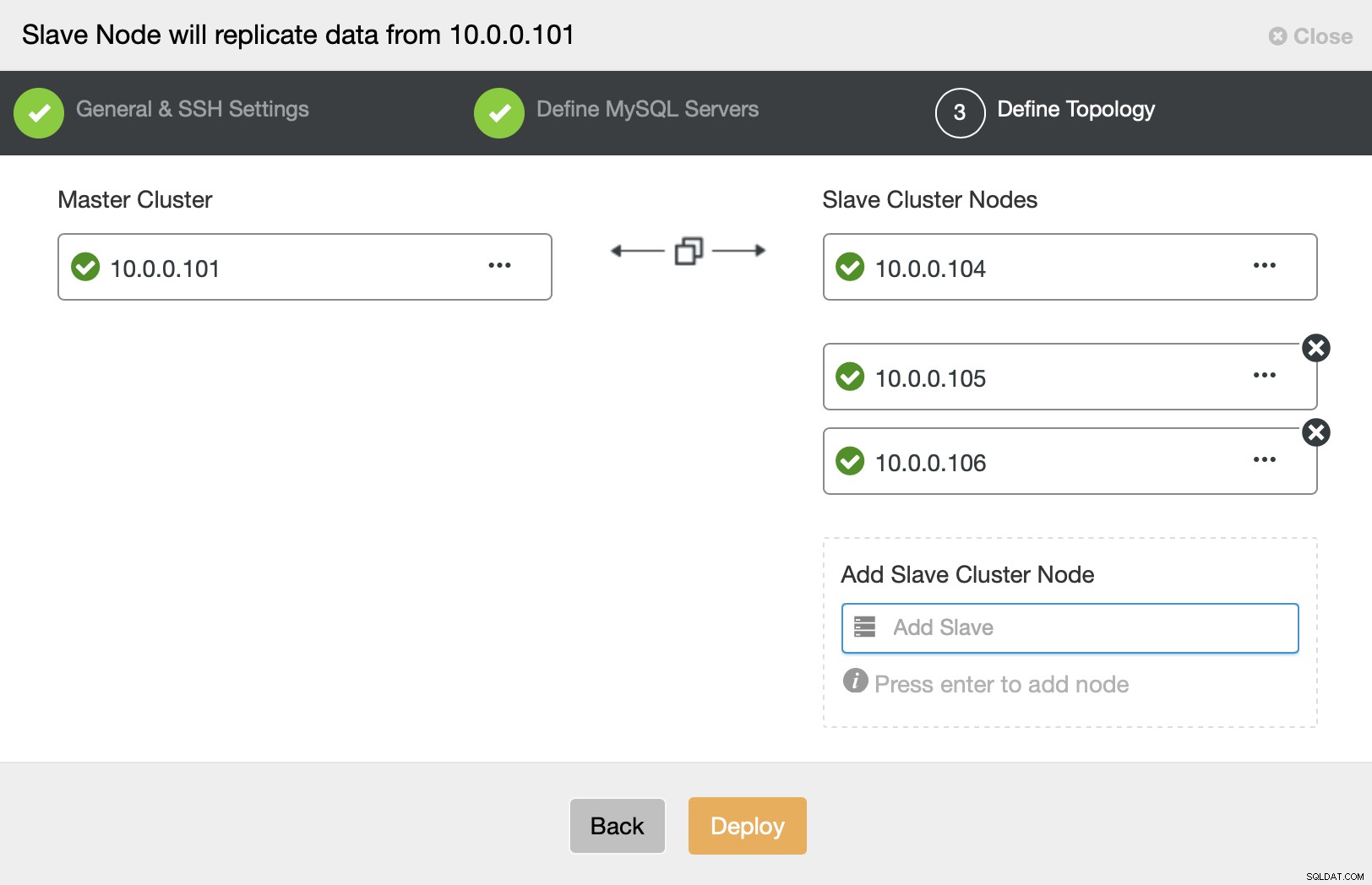
Schließlich werden Sie aufgefordert, Knoten zu definieren, die Sie hinzufügen möchten Cluster und Sie sind fertig.
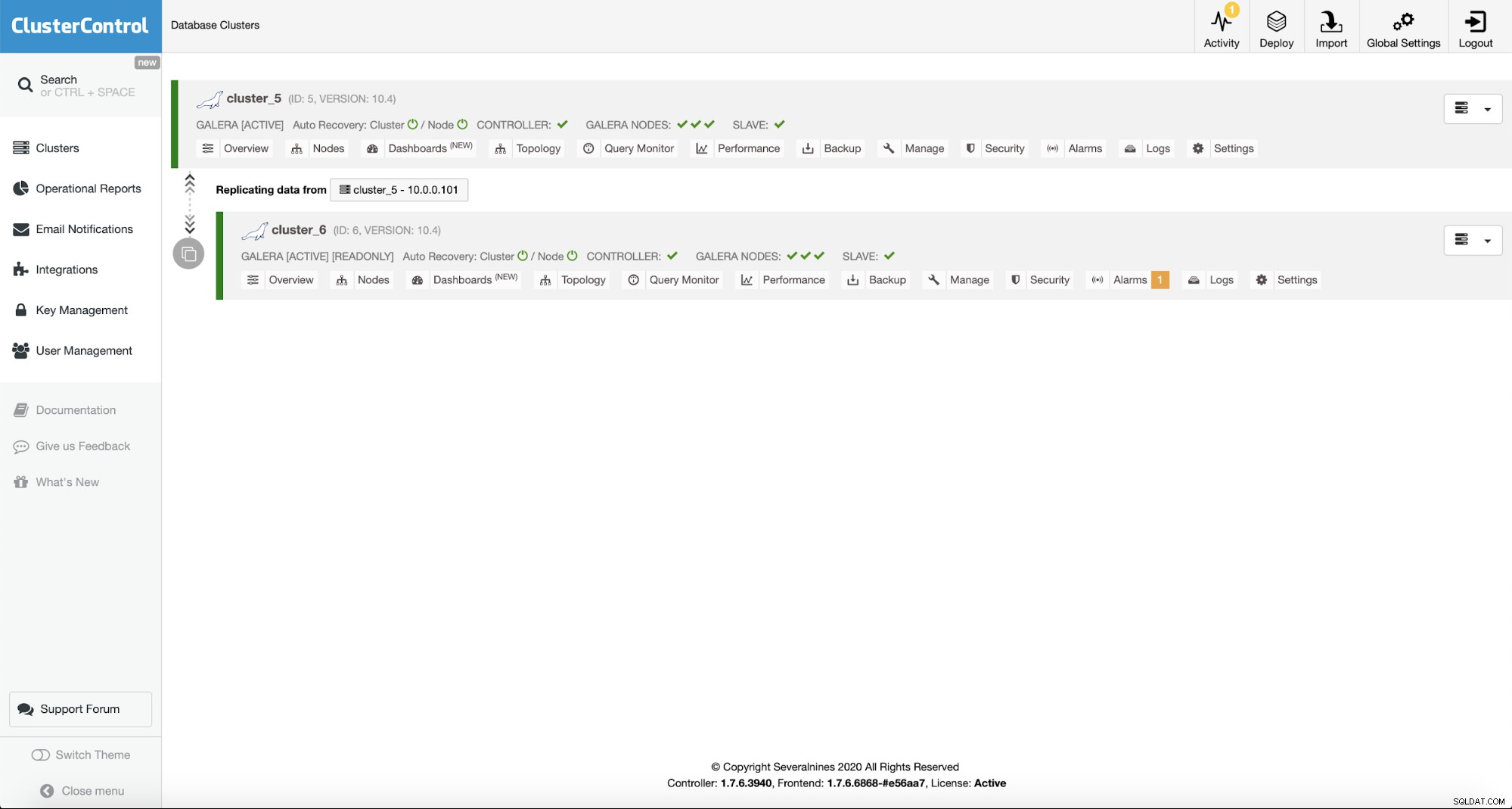
Nach der Bereitstellung sehen Sie es in der Liste der Cluster in der ClusterControl-Benutzeroberfläche.
Bereitstellen eines Multi-Cloud-MariaDB-Clusters
Wie bereits erwähnt, wäre eine weitere Option zur Bereitstellung von MariaDB-Clustern die Verwendung separater Segmente beim Hinzufügen von Knoten zum Cluster. In der ClusterControl-Benutzeroberfläche finden Sie eine Option zum „Add Node“ (Knoten hinzufügen):
Wenn Sie es verwenden, wird Ihnen folgender Bildschirm angezeigt:
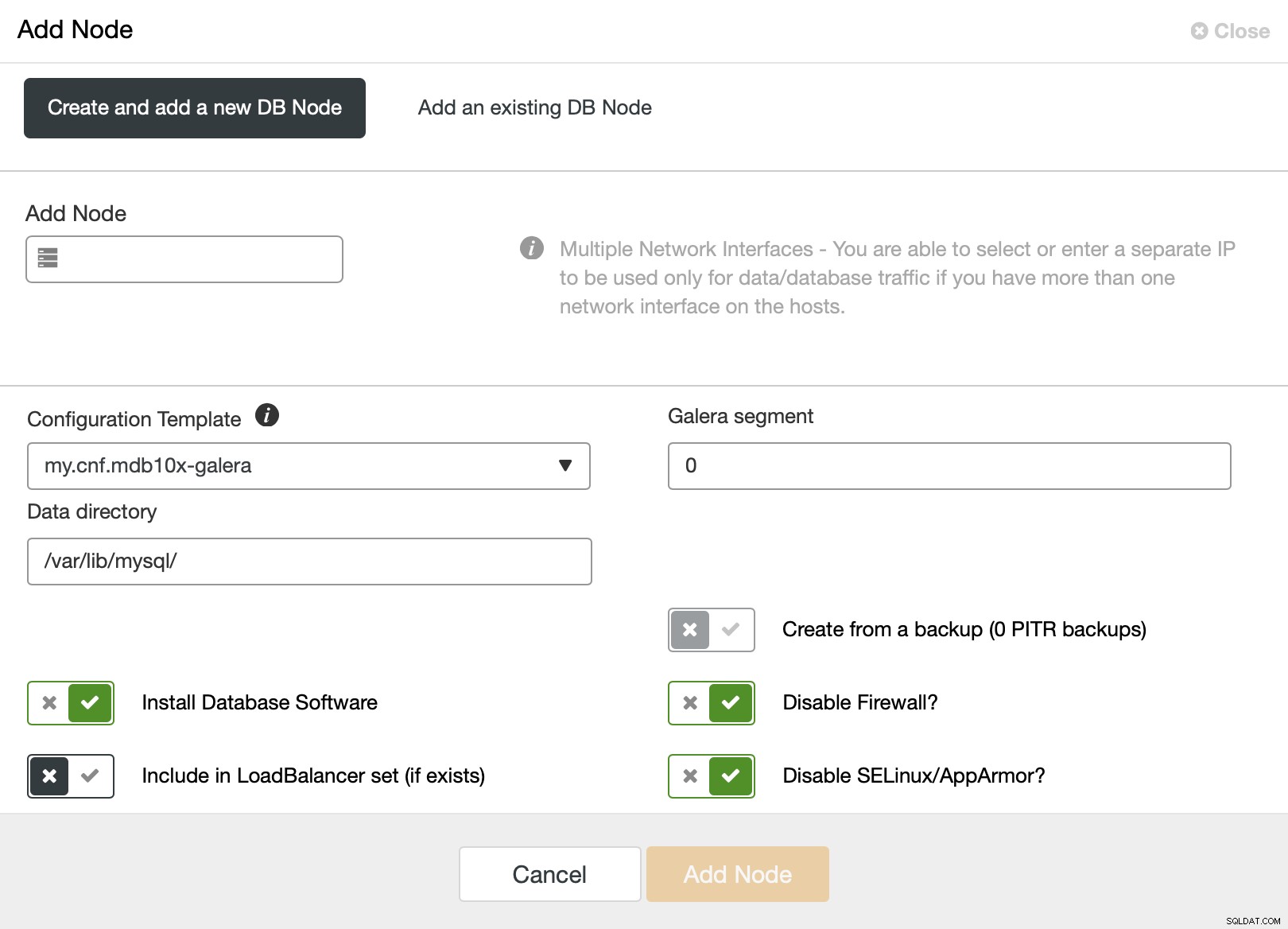
Das Standardsegment ist 0, also möchten Sie es in einen anderen Wert ändern .
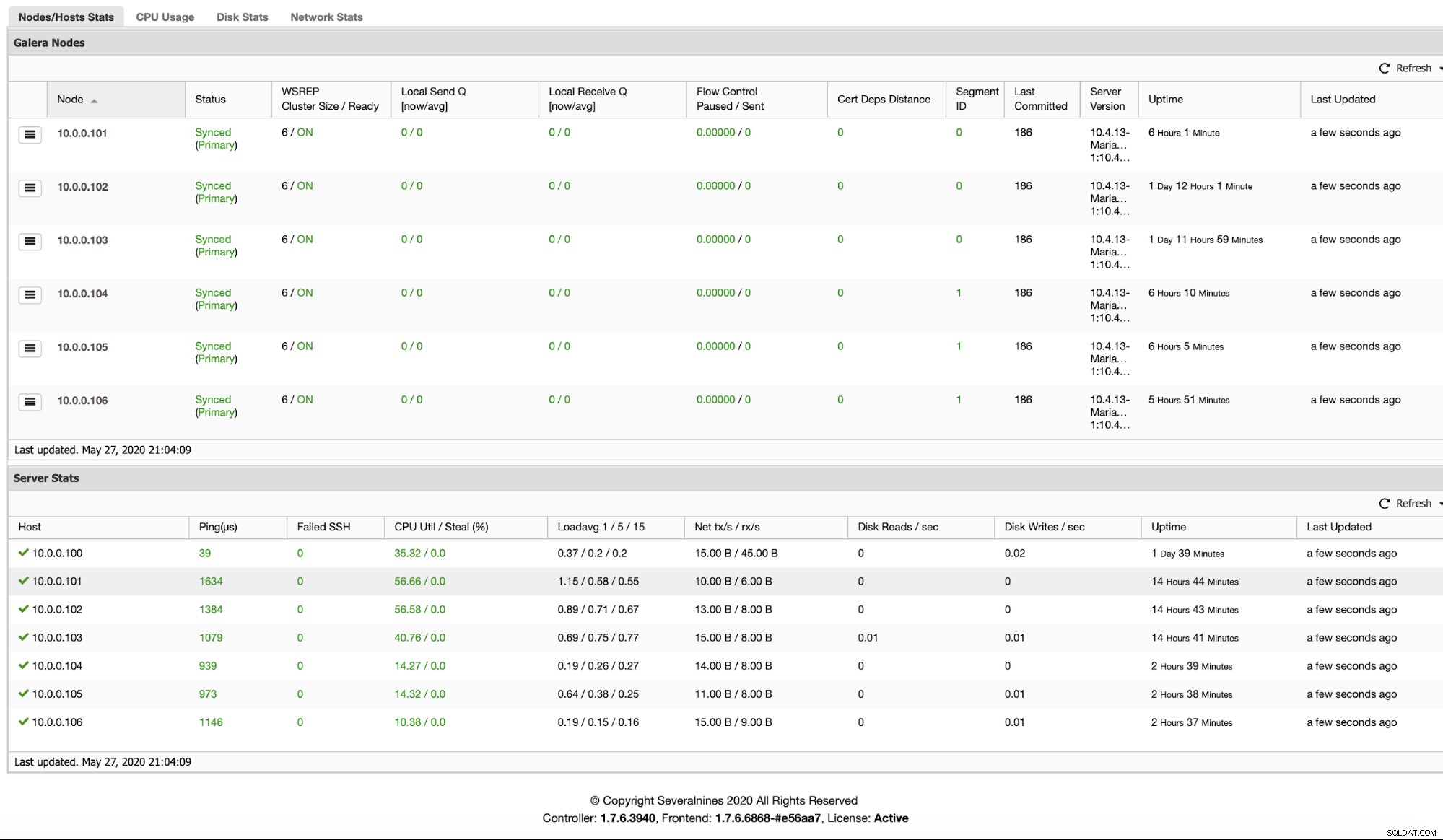
Nachdem Knoten hinzugefügt wurden, können Sie überprüfen, in welchem Segment sie sich befinden, indem Sie auf die Registerkarte Übersicht schauen:
Fazit
Wir hoffen, dass Ihnen dieser kurze Blog ein besseres Verständnis für die Optionen gegeben hat, die Sie für Multi-Cloud-MariaDB-Cluster-Bereitstellungen haben und wie sie verwendet werden können, um eine hohe Verfügbarkeit Ihrer Datenbankinfrastruktur sicherzustellen.