Beim Ausführen von verteilten Datenbankclustern ist es üblich, ihnen Load Balancer voranzustellen. Die Vorteile liegen auf der Hand – Lastausgleich, Verbindungs-Failover und Entkopplung der Anwendungsebene von den zugrunde liegenden Datenbanktopologien. Für einen intelligenteren Lastenausgleich wäre ein datenbankfähiger Proxy wie ProxySQL oder MaxScale der richtige Weg. In unserem vorherigen Blog haben wir Ihnen gezeigt, wie Sie ProxySQL als Hilfscontainer in Kubernetes ausführen. In diesem Blogbeitrag zeigen wir Ihnen, wie Sie ProxySQL als Kubernetes-Dienst bereitstellen. Wir verwenden Wordpress als Beispielanwendung und das Datenbank-Backend läuft auf einer Zwei-Knoten-MySQL-Replikation, die mit ClusterControl bereitgestellt wird. Das folgende Diagramm veranschaulicht unsere Infrastruktur:
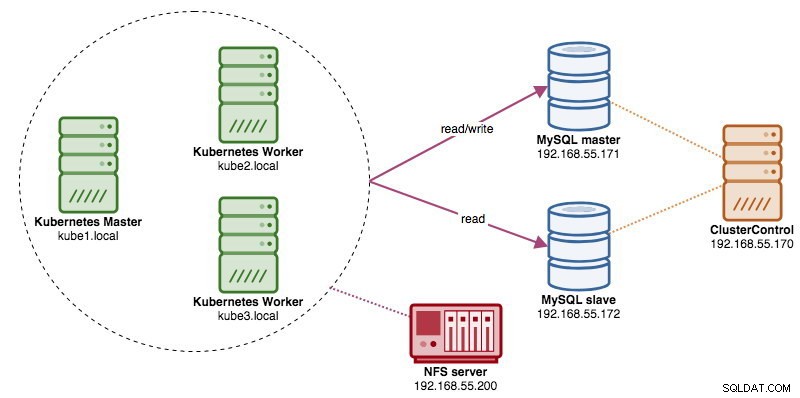
Da wir ein ähnliches Setup wie in diesem vorherigen Blog-Beitrag verwenden werden, erwarten Sie in einigen Teilen des Blog-Beitrags Duplikate, damit der Beitrag besser lesbar bleibt.
ProxySQL auf Kubernetes
Beginnen wir mit einer kleinen Zusammenfassung. Das Entwerfen einer ProxySQL-Architektur ist ein subjektives Thema und hängt stark von der Platzierung der Anwendung, den Datenbankcontainern sowie der Rolle von ProxySQL selbst ab. Im Idealfall können wir ProxySQL so konfigurieren, dass es von Kubernetes mit zwei Konfigurationen verwaltet wird:
- ProxySQL als Kubernetes-Dienst (zentralisierte Bereitstellung)
- ProxySQL als Hilfscontainer in einem Pod (verteilte Bereitstellung)
Beide Bereitstellungen können anhand des folgenden Diagramms leicht unterschieden werden:
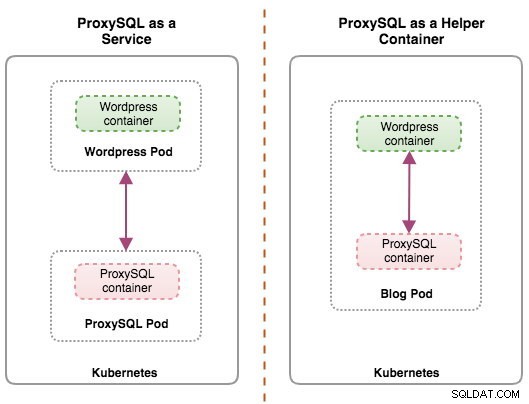
Dieser Blogbeitrag behandelt die erste Konfiguration – das Ausführen von ProxySQL als Kubernetes-Dienst. Die zweite Konfiguration wird hier bereits behandelt. Im Gegensatz zum Helper-Container-Ansatz macht das Ausführen als Dienst ProxySQL-Pods unabhängig von den Anwendungen aktiv und kann mit Hilfe von Kubernetes ConfigMap einfach skaliert und geclustert werden. Dies ist definitiv ein anderer Clustering-Ansatz als die native ProxySQL-Clustering-Unterstützung, die auf Konfigurationsprüfsummen über ProxySQL-Instanzen (auch bekannt als Proxysql_server) angewiesen ist. Sehen Sie sich diesen Blogbeitrag an, wenn Sie mehr über ProxySQL-Clustering erfahren möchten, das mit ClusterControl leicht gemacht wurde.
In Kubernetes ermöglicht das mehrschichtige Konfigurationssystem von ProxySQL Pod-Clustering mit ConfigMap. Es gibt jedoch eine Reihe von Mängeln und Problemumgehungen, damit es reibungslos funktioniert, wie es die native Clustering-Funktion von ProxySQL tut. Im Moment ist die Signalisierung eines Pods bei einem ConfigMap-Update ein Feature in Arbeit. Wir werden dieses Thema in einem kommenden Blog-Beitrag ausführlicher behandeln.
Grundsätzlich müssen wir ProxySQL-Pods erstellen und einen Kubernetes-Dienst anhängen, auf den von den anderen Pods innerhalb des Kubernetes-Netzwerks oder extern zugegriffen werden kann. Anwendungen verbinden sich dann über das TCP/IP-Netzwerk an den konfigurierten Ports mit dem ProxySQL-Dienst. Der Standardwert ist 6033 für MySQL-Verbindungen mit Lastenausgleich und 6032 für die ProxySQL-Verwaltungskonsole. Bei mehr als einem Replikat werden die Verbindungen zum Pod automatisch durch die Kubernetes-kube-proxy-Komponente ausgeglichen, die auf jedem Kubernetes-Knoten ausgeführt wird.
ProxySQL als Kubernetes-Dienst
In diesem Setup führen wir sowohl ProxySQL als auch Wordpress als Pods und Dienste aus. Das folgende Diagramm veranschaulicht unsere High-Level-Architektur:
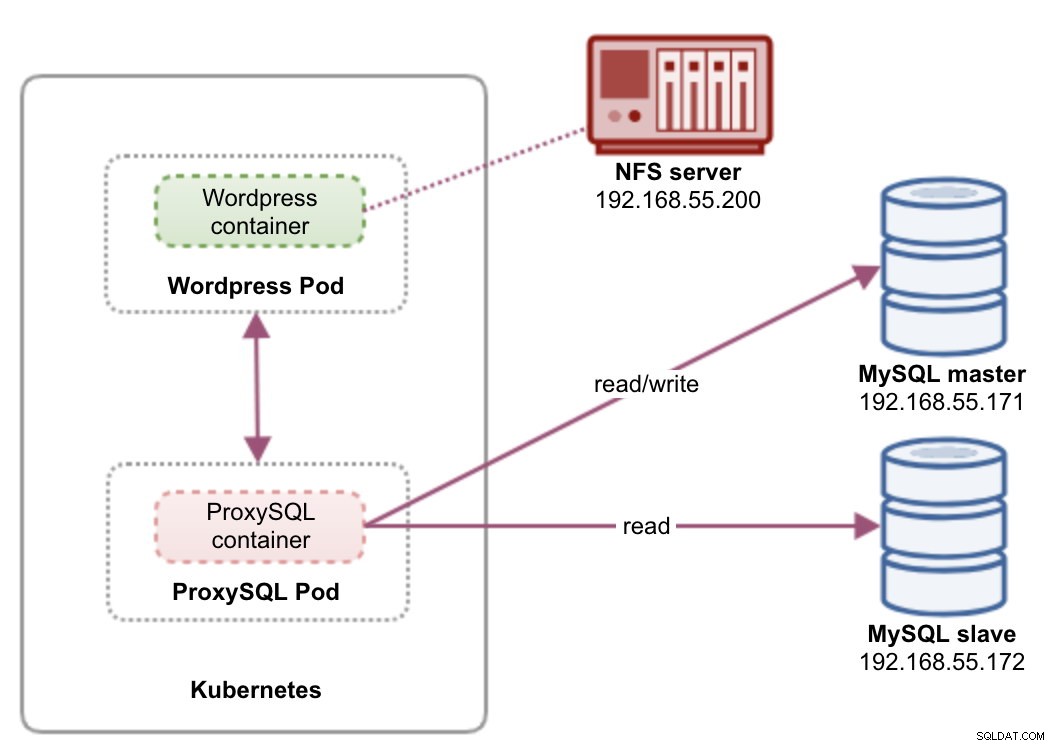
In diesem Setup werden wir zwei Pods und Dienste bereitstellen – „wordpress“ und „proxysql“. Wir werden Deployment und Service Declaration in einer YAML-Datei pro Anwendung zusammenführen und sie als eine Einheit verwalten. Um den Inhalt der Anwendungscontainer über mehrere Knoten hinweg persistent zu halten, müssen wir ein geclustertes oder entferntes Dateisystem verwenden, in diesem Fall NFS.
Das Bereitstellen von ProxySQL als Dienst bringt ein paar gute Dinge gegenüber dem Helfer-Container-Ansatz:
- Mithilfe des Kubernetes ConfigMap-Ansatzes kann ProxySQL mit unveränderlicher Konfiguration geclustert werden.
- Kubernetes übernimmt die ProxySQL-Wiederherstellung und gleicht die Verbindungen zu den Instanzen automatisch aus.
- Einzelner Endpunkt mit Implementierung der virtuellen IP-Adresse von Kubernetes namens ClusterIP.
- Zentralisierte Reverse-Proxy-Stufe mit Shared-Nothing-Architektur.
- Kann mit externen Anwendungen außerhalb von Kubernetes verwendet werden.
Wir beginnen mit der Bereitstellung als zwei Replikate für ProxySQL und drei für Wordpress, um die skalierbare Ausführung und die Lastausgleichsfunktionen zu demonstrieren, die Kubernetes bietet.
Datenbank vorbereiten
Erstellen Sie die WordPress-Datenbank und den Benutzer auf dem Master und weisen Sie sie mit der richtigen Berechtigung zu:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Erstellen Sie außerdem den ProxySQL-Überwachungsbenutzer:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Laden Sie dann die Grant-Tabelle neu:
mysql-master> FLUSH PRIVILEGES;ProxySQL-Pod und Dienstdefinition
Als nächstes bereiten wir unsere ProxySQL-Bereitstellung vor. Erstellen Sie eine Datei namens proxysql-rs-svc.yml und fügen Sie die folgenden Zeilen hinzu:
apiVersion: v1
kind: Deployment
metadata:
name: proxysql
labels:
app: proxysql
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: proxysql
tier: frontend
spec:
restartPolicy: Always
containers:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap
---
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendMal sehen, worum es bei diesen Definitionen geht. Die YAML besteht aus zwei Ressourcen, die in einer Datei kombiniert und durch das Trennzeichen „---“ getrennt sind. Die erste Ressource ist das Deployment, das wir mit der folgenden Spezifikation definieren:
spec:
replicas: 2
selector:
matchLabels:
app: proxysql
tier: frontend
strategy:
type: RollingUpdateDas Obige bedeutet, dass wir zwei ProxySQL-Pods als ReplicaSet bereitstellen möchten, das Containern entspricht, die mit „app=proxysql,tier=frontend“ gekennzeichnet sind. Die Bereitstellungsstrategie gibt die Strategie an, die verwendet wird, um alte Pods durch neue zu ersetzen. In dieser Bereitstellung haben wir RollingUpdate ausgewählt, was bedeutet, dass die Pods fortlaufend aktualisiert werden, ein Pod nach dem anderen.
Der nächste Teil ist die Vorlage des Containers:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
ports:
- containerPort: 6033
name: proxysql-mysql
- containerPort: 6032
name: proxysql-admin
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmapIn den spec.templates.spec.containers.* Abschnitt weisen wir Kubernetes an, ProxySQL mit severalnines/proxysql bereitzustellen Bildversion 1.4.12. Wir möchten auch, dass Kubernetes unsere benutzerdefinierte, vorkonfigurierte Konfigurationsdatei einbindet und sie /etc/proxysql.cnf im Container zuordnet. Die laufenden Pods veröffentlichen zwei Ports – 6033 und 6032. Wir definieren auch den Abschnitt „Volumes“, in dem wir Kubernetes anweisen, die ConfigMap als Volume innerhalb der ProxySQL-Pods bereitzustellen, die von volumeMounts bereitgestellt werden.
Die zweite Ressource ist der Service. Ein Kubernetes-Dienst ist eine Abstraktionsschicht, die den logischen Satz von Pods und eine Richtlinie für den Zugriff auf sie definiert. In diesem Abschnitt definieren wir Folgendes:
apiVersion: v1
kind: Service
metadata:
name: proxysql
labels:
app: proxysql
tier: frontend
spec:
type: NodePort
ports:
- nodePort: 30033
port: 6033
name: proxysql-mysql
- nodePort: 30032
port: 6032
name: proxysql-admin
selector:
app: proxysql
tier: frontendIn diesem Fall möchten wir, dass auf unser ProxySQL vom externen Netzwerk aus zugegriffen wird, daher ist der NodePort-Typ der ausgewählte Typ. Dadurch wird der nodePort auf allen Kubernetes-Knoten im Cluster veröffentlicht. Der Bereich gültiger Ports für die NodePort-Ressource ist 30000-32767. Wir haben Port 30033 für MySQL-Load-Balancing-Verbindungen gewählt, der Port 6033 der ProxySQL-Pods zugeordnet ist, und Port 30032 für den Port 6032 der ProxySQL-Verwaltung.
Daher müssen wir basierend auf unserer obigen YAML-Definition die folgende Kubernetes-Ressource vorbereiten, bevor wir mit der Bereitstellung des „proxysql“-Pods beginnen können:
- ConfigMap – Zum Speichern der ProxySQL-Konfigurationsdatei als Volume, damit sie auf mehreren Pods gemountet und erneut gemountet werden kann, wenn der Pod auf dem anderen Kubernetes-Knoten neu geplant wird.
KonfigMap für ProxySQL vorbereiten
Ähnlich wie im vorherigen Blogbeitrag werden wir den ConfigMap-Ansatz verwenden, um die Konfigurationsdatei vom Container zu entkoppeln und auch für Skalierbarkeitszwecke. Beachten Sie, dass wir in diesem Setup davon ausgehen, dass unsere ProxySQL-Konfiguration unveränderlich ist.
Erstellen Sie zunächst die ProxySQL-Konfigurationsdatei proxysql.cnf und fügen Sie die folgenden Zeilen hinzu:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="proxysql-admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)Achten Sie auf die admin_variables.admin_credentials Variable, bei der wir den nicht standardmäßigen Benutzer "proxysql-admin" verwendet haben. ProxySQL reserviert den Standardbenutzer „admin“ nur für die lokale Verbindung über localhost. Daher müssen wir andere Benutzer verwenden, um remote auf die ProxySQL-Instanz zuzugreifen. Andernfalls erhalten Sie die folgende Fehlermeldung:
ERROR 1040 (42000): User 'admin' can only connect locallyUnsere ProxySQL-Konfiguration basiert auf unseren beiden Datenbankservern, die in MySQL Replication ausgeführt werden, wie im folgenden Topologie-Screenshot von ClusterControl zusammengefasst:
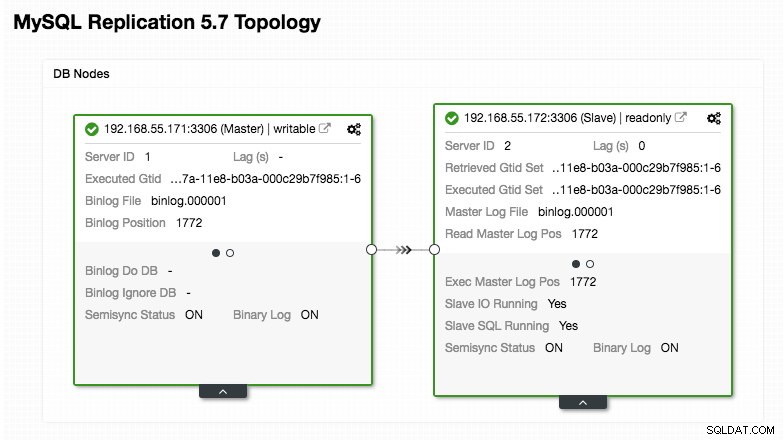
Alle Schreibvorgänge sollten an den Master-Knoten gehen, während Lesevorgänge an Hostgruppe 20 weitergeleitet werden, wie im Abschnitt „mysql_query_rules“ definiert. Das ist die Grundlage des Read/Write-Splittings und wir wollen sie komplett nutzen.
Importieren Sie dann die Konfigurationsdatei in ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdÜberprüfen Sie, ob die ConfigMap in Kubernetes geladen ist:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sWordpress-Pod und Dienstdefinition
Fügen Sie nun die folgenden Zeilen in eine Datei namens wordpress-rs-svc.yml ein auf dem Host, auf dem kubectl konfiguriert ist:
apiVersion: apps/v1
kind: Deployment
metadata:
name: wordpress
labels:
app: wordpress
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: wordpress
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033 # proxysql.default.svc.cluster.local:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_DATABASE
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
---
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendÄhnlich wie bei unserer ProxySQL-Definition besteht die YAML aus zwei Ressourcen, getrennt durch „---“-Trennzeichen, die in einer Datei zusammengefasst sind. Die erste ist die Deployment-Ressource, die als ReplicaSet bereitgestellt wird, wie im Abschnitt „spec.*“ gezeigt:
spec:
replicas: 3
selector:
matchLabels:
app: wordpress
tier: frontend
strategy:
type: RollingUpdateDieser Abschnitt enthält die Bereitstellungsspezifikation – 3 zu startende Pods, die mit dem Label „app=wordpress,tier=backend“ übereinstimmen. Die Bereitstellungsstrategie ist RollingUpdate, was bedeutet, dass Kubernetes den Pod ersetzen wird, indem Rolling Update Mode verwendet wird, genau wie bei unserer ProxySQL-Bereitstellung.
Der nächste Teil ist der Abschnitt "spec.template.spec.*":
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: proxysql:6033
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
In diesem Abschnitt weisen wir Kubernetes an, Wordpress 4.9 mithilfe des Apache-Webservers bereitzustellen, und wir haben dem Container den Namen "wordpress" gegeben. Der Container wird unabhängig vom Status jedes Mal neu gestartet, wenn er heruntergefahren ist. Wir möchten auch, dass Kubernetes eine Reihe von Umgebungsvariablen übergibt:
- WORDPRESS_DB_HOST - Der MySQL-Datenbankhost. Da wir ProxySQL als Dienst verwenden, ist der Dienstname der Wert von metadata.name das ist "proxysql". ProxySQL lauscht auf Port 6033 auf MySQL-Load-Balancing-Verbindungen, während die ProxySQL-Verwaltungskonsole auf 6032 läuft.
- WORDPRESS_DB_USER - Geben Sie den WordPress-Datenbankbenutzer an, der im Abschnitt "Vorbereitung der Datenbank" erstellt wurde.
- WORDPRESS_DB_PASSWORD - Das Passwort für WORDPRESS_DB_USER . Da wir das Passwort in dieser Datei nicht preisgeben möchten, können wir es mithilfe von Kubernetes Secrets verbergen. Hier weisen wir Kubernetes an, stattdessen die geheime Ressource „mysql-pass“ zu lesen. Secrets müssen vor der Pod-Bereitstellung erstellt werden, wie weiter unten erklärt.
Wir wollen auch Port 80 des Pods für den Endbenutzer veröffentlichen. Der in /var/www/html im Container gespeicherte Wordpress-Inhalt wird in unseren persistenten Speicher gemountet, der auf NFS läuft. Wir werden die PersistentVolume- und PersistentVolumeClaim-Ressourcen für diesen Zweck verwenden, wie im Abschnitt „Persistent Storage für Wordpress vorbereiten“ gezeigt.
Nach der Bruchzeile „---“ definieren wir eine weitere Ressource namens Service:
apiVersion: v1
kind: Service
metadata:
name: wordpress
labels:
app: wordpress
tier: frontend
spec:
type: NodePort
ports:
- name: wordpress
nodePort: 30088
port: 80
selector:
app: wordpress
tier: frontendIn dieser Konfiguration möchten wir, dass Kubernetes einen Dienst namens „wordpress“ erstellt, Port 30088 auf allen Knoten (alias NodePort) auf das externe Netzwerk abhört und ihn an Port 80 auf allen Pods weiterleitet, die mit „app=wordpress,tier=Frontend".
Daher müssen wir basierend auf unserer obigen YAML-Definition eine Reihe von Kubernetes-Ressourcen vorbereiten, bevor wir mit der Bereitstellung des „wordpress“-Pods und -Dienstes beginnen können:
- PersistentVolume und PersistentVolumeClaim - Um die Webinhalte unserer Wordpress-Anwendung zu speichern, damit wir die letzten Änderungen nicht verlieren, wenn der Pod auf einen anderen Worker-Knoten verschoben wird.
- Geheimnisse - Um das Benutzerpasswort der Wordpress-Datenbank in der YAML-Datei zu verbergen.
Persistenten Speicher für Wordpress vorbereiten
Ein guter persistenter Speicher für Kubernetes sollte für alle Kubernetes-Knoten im Cluster zugänglich sein. Für diesen Blogbeitrag haben wir NFS als PersistentVolume (PV)-Anbieter verwendet, weil es einfach ist und standardmäßig unterstützt wird. Der NFS-Server befindet sich irgendwo außerhalb unseres Kubernetes-Netzwerks (wie im ersten Architekturdiagramm gezeigt) und wir haben ihn so konfiguriert, dass er alle Kubernetes-Knoten mit der folgenden Zeile in /etc/exports zulässt:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Beachten Sie, dass das NFS-Clientpaket auf allen Kubernetes-Knoten installiert sein muss. Andernfalls wäre Kubernetes nicht in der Lage, das NFS korrekt zu mounten. Auf allen Knoten:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSStellen Sie außerdem sicher, dass auf dem NFS-Server das Zielverzeichnis existiert:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressErstellen Sie dann eine Datei namens wordpress-pv-pvc.yml und fügen Sie die folgenden Zeilen hinzu:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: wordpress
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: wordpress
tier: frontendIn der obigen Definition weisen wir Kubernetes an, 3 GB Volume-Speicherplatz auf dem NFS-Server für unseren Wordpress-Container zuzuweisen. Beachten Sie, dass NFS für die Produktionsnutzung mit automatischer Bereitstellung und Speicherklasse konfiguriert werden sollte.
Erstellen Sie die PV- und PVC-Ressourcen:
$ kubectl create -f wordpress-pv-pvc.ymlÜberprüfen Sie, ob diese Ressourcen erstellt wurden und der Status „Gebunden“ lauten muss:
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hSecrets für Wordpress vorbereiten
Erstellen Sie ein Geheimnis, das vom Wordpress-Container für WORDPRESS_DB_PASSWORD verwendet werden soll Umgebungsvariable. Der Grund liegt einfach darin, dass wir das Passwort nicht im Klartext in der YAML-Datei offenlegen möchten.
Erstellen Sie eine geheime Ressource namens mysql-pass und übergeben Sie das Passwort entsprechend:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdÜberprüfen Sie, ob unser Geheimnis erstellt wurde:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mBereitstellung von ProxySQL und Wordpress
Endlich können wir mit der Bereitstellung beginnen. Stellen Sie zuerst ProxySQL bereit, gefolgt von Wordpress:
$ kubectl create -f proxysql-rs-svc.yml
$ kubectl create -f wordpress-rs-svc.ymlWir können dann alle Pods und Dienste auflisten, die unter der Ebene „Frontend“ erstellt wurden:
$ kubectl get pods,services -l tier=frontend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
pod/proxysql-95b8d8446-qfbf2 1/1 Running 0 12m 10.36.0.2 kube2.local <none>
pod/proxysql-95b8d8446-vljlr 1/1 Running 0 12m 10.44.0.6 kube3.local <none>
pod/wordpress-59489d57b9-4dzvk 1/1 Running 0 37m 10.36.0.1 kube2.local <none>
pod/wordpress-59489d57b9-7d2jb 1/1 Running 0 30m 10.44.0.4 kube3.local <none>
pod/wordpress-59489d57b9-gw4p9 1/1 Running 0 30m 10.36.0.3 kube2.local <none>
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/proxysql NodePort 10.108.195.54 <none> 6033:30033/TCP,6032:30032/TCP 10m app=proxysql,tier=frontend
service/wordpress NodePort 10.109.144.234 <none> 80:30088/TCP 37m app=wordpress,tier=frontend
kube2.local <none>Die obige Ausgabe bestätigt unsere Bereitstellungsarchitektur, in der wir derzeit drei Wordpress-Pods haben, die öffentlich auf Port 30088 verfügbar gemacht werden, sowie unsere ProxySQL-Instanz, die extern auf Port 30033 und 30032 sowie intern auf Port 6033 und 6032 verfügbar gemacht wird.
An diesem Punkt sieht unsere Architektur in etwa so aus:
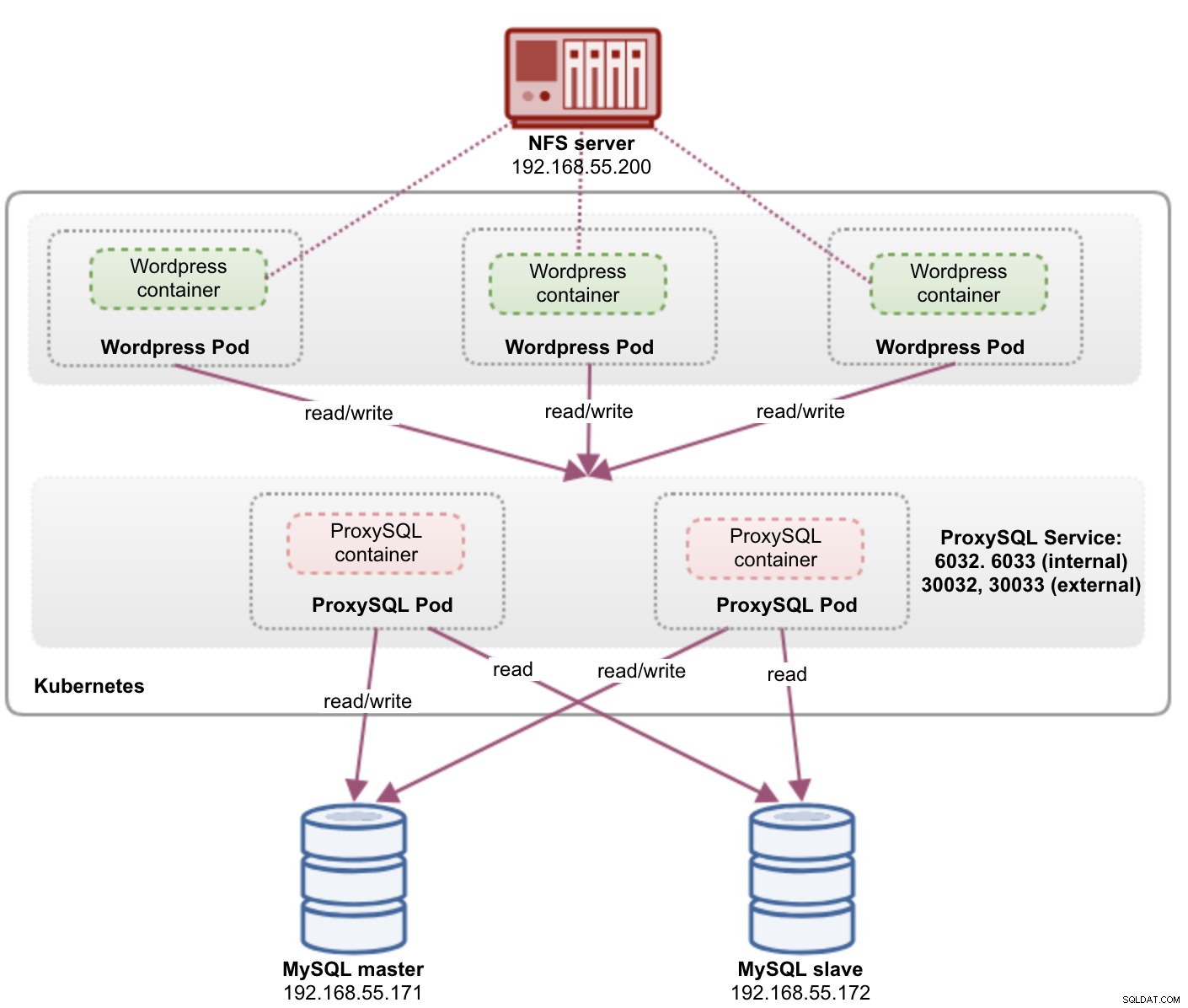
Der von den Wordpress-Pods veröffentlichte Port 80 wird jetzt über Port 30088 der Außenwelt zugeordnet. Wir können auf unseren Blog-Beitrag unter https://{any_kubernetes_host}:30088/ zugreifen und sollten auf die Wordpress-Installationsseite umgeleitet werden. Wenn wir mit der Installation fortfahren, wird der Teil der Datenbankverbindung übersprungen und direkt diese Seite angezeigt:
Es zeigt an, dass unsere MySQL- und ProxySQL-Konfiguration in der Datei wp-config.php korrekt konfiguriert ist. Andernfalls würden Sie zur Datenbankkonfigurationsseite weitergeleitet.
Unsere Bereitstellung ist jetzt abgeschlossen.
ProxySQL-Pods und Dienstverwaltung
Failover und Wiederherstellung werden voraussichtlich automatisch von Kubernetes gehandhabt. Wenn beispielsweise ein Kubernetes-Worker ausfällt, wird der Pod im nächsten verfügbaren Knoten nach --pod-eviction-timeout (standardmäßig 5 Minuten) neu erstellt. Wenn der Container abstürzt oder zerstört wird, ersetzt Kubernetes ihn fast sofort.
Einige gängige Verwaltungsaufgaben werden voraussichtlich anders sein, wenn sie in Kubernetes ausgeführt werden, wie in den nächsten Abschnitten gezeigt.
Verbinden mit ProxySQL
Während ProxySQL extern auf Port 30033 (MySQL) und 30032 (Admin) bereitgestellt wird, ist es auch intern über die veröffentlichten Ports 6033 bzw. 6032 zugänglich. Verwenden Sie daher für den Zugriff auf die ProxySQL-Instanzen im Kubernetes-Netzwerk die CLUSTER-IP oder den Dienstnamen „proxysql“ als Hostwert. Innerhalb des Wordpress-Pods können Sie beispielsweise mit dem folgenden Befehl auf die ProxySQL-Verwaltungskonsole zugreifen:
$ mysql -uproxysql-admin -p -hproxysql -P6032Wenn Sie eine externe Verbindung herstellen möchten, verwenden Sie den Port, der unter nodePort-Wert des Dienstes YAML definiert ist, und wählen Sie einen der Kubernetes-Knoten als Hostwert aus:
$ mysql -uproxysql-admin -p -hkube3.local -P30032Dasselbe gilt für die MySQL-Load-Balancing-Verbindung auf Port 30033 (extern) und 6033 (intern).
Hoch- und Runterskalieren
Das Hochskalieren ist mit Kubernetes einfach:
$ kubectl scale deployment proxysql --replicas=5
deployment.extensions/proxysql scaledÜberprüfen Sie den Rollout-Status:
$ kubectl rollout status deployment proxysql
deployment "proxysql" successfully rolled outAuch das Herunterskalieren ist ähnlich. Hier wollen wir von 5 auf 2 Replikate zurückgehen:
$ kubectl scale deployment proxysql --replicas=2
deployment.extensions/proxysql scaledWir können uns auch die Bereitstellungsereignisse für ProxySQL ansehen, um uns ein besseres Bild davon zu machen, was bei dieser Bereitstellung passiert ist, indem wir die Option „Beschreiben“ verwenden:
$ kubectl describe deployment proxysql
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 20m deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 20m deployment-controller Scaled down replica set proxysql-95b8d8446 to 0
Normal ScalingReplicaSet 7m10s deployment-controller Scaled up replica set proxysql-6c55f647cb to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled down replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 7m deployment-controller Scaled up replica set proxysql-6c55f647cb to 2
Normal ScalingReplicaSet 6m53s deployment-controller Scaled down replica set proxysql-769895fbf7 to 0
Normal ScalingReplicaSet 54s deployment-controller Scaled up replica set proxysql-6c55f647cb to 5
Normal ScalingReplicaSet 21s deployment-controller Scaled down replica set proxysql-6c55f647cb to 2Die Verbindungen zu den Pods werden automatisch von Kubernetes ausgeglichen.
Konfigurationsänderungen
Eine Möglichkeit, Konfigurationsänderungen an unseren ProxySQL-Pods vorzunehmen, besteht darin, unsere Konfiguration mit einem anderen ConfigMap-Namen zu versionieren. Ändern Sie zunächst unsere Konfigurationsdatei direkt über Ihren bevorzugten Texteditor:
$ vim /root/proxysql.cnfLaden Sie es dann mit einem anderen Namen in Kubernetes ConfigMap hoch. In diesem Beispiel hängen wir "-v2" an den Ressourcennamen an:
$ kubectl create configmap proxysql-configmap-v2 --from-file=proxysql.cnfÜberprüfen Sie, ob die ConfigMap korrekt geladen wurde:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 3d15h
proxysql-configmap-v2 1 19mÖffnen Sie die ProxySQL-Bereitstellungsdatei proxysql-rs-svc.yml und ändern Sie die folgende Zeile im Abschnitt configMap auf die neue Version:
volumes:
- name: proxysql-config
configMap:
name: proxysql-configmap-v2 #change this lineWenden Sie dann die Änderungen auf unsere ProxySQL-Bereitstellung an:
$ kubectl apply -f proxysql-rs-svc.yml
deployment.apps/proxysql configured
service/proxysql configuredÜberprüfen Sie die Einführung, indem Sie sich das ReplicaSet-Ereignis mit dem Flag „describe“ ansehen:
$ kubectl describe proxysql
...
Pod Template:
Labels: app=proxysql
tier=frontend
Containers:
proxysql:
Image: severalnines/proxysql:1.4.12
Ports: 6033/TCP, 6032/TCP
Host Ports: 0/TCP, 0/TCP
Environment: <none>
Mounts:
/etc/proxysql.cnf from proxysql-config (rw)
Volumes:
proxysql-config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: proxysql-configmap-v2
Optional: false
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
Progressing True NewReplicaSetAvailable
OldReplicaSets: <none>
NewReplicaSet: proxysql-769895fbf7 (2/2 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 53s deployment-controller Scaled up replica set proxysql-769895fbf7 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled down replica set proxysql-95b8d8446 to 1
Normal ScalingReplicaSet 46s deployment-controller Scaled up replica set proxysql-769895fbf7 to 2
Normal ScalingReplicaSet 41s deployment-controller Scaled down replica set proxysql-95b8d8446 to 0Achten Sie auf den Abschnitt „Volumes“ mit dem neuen ConfigMap-Namen. Sie können auch die Bereitstellungsereignisse unten in der Ausgabe sehen. An diesem Punkt wurde unsere neue Konfiguration in alle ProxySQL-Pods geladen, wo Kubernetes das ProxySQL-ReplicaSet auf 0 herunterskaliert hat (unter Einhaltung der RollingUpdate-Strategie) und sie wieder auf den gewünschten Zustand von 2 Replikaten bringt.
Abschließende Gedanken
Bis zu diesem Punkt haben wir mögliche Bereitstellungsansätze für ProxySQL in Kubernetes behandelt. Das Ausführen von ProxySQL mit Hilfe von Kubernetes ConfigMap eröffnet eine neue Möglichkeit des ProxySQL-Clustering, wobei es sich etwas von der in ProxySQL integrierten nativen Clustering-Unterstützung unterscheidet.
Im kommenden Blogbeitrag werden wir uns mit ProxySQL-Clustering mit Kubernetes ConfigMap und der richtigen Vorgehensweise befassen. Bleiben Sie dran!