ProxySQL befindet sich normalerweise zwischen der Anwendungs- und der Datenbankebene, in der sogenannten Reverse-Proxy-Ebene. Wenn Ihre Anwendungscontainer von Kubernetes orchestriert und verwaltet werden, möchten Sie möglicherweise ProxySQL vor Ihren Datenbankservern verwenden.
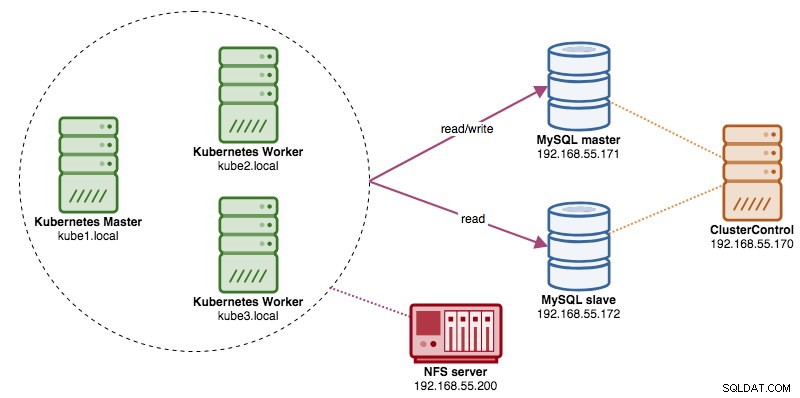
In diesem Beitrag zeigen wir Ihnen, wie Sie ProxySQL auf Kubernetes als Hilfscontainer in einem Pod ausführen. Wir werden Wordpress als Beispielanwendung verwenden. Der Datendienst wird von unserer Zwei-Knoten-MySQL-Replikation bereitgestellt, die mithilfe von ClusterControl bereitgestellt wird und sich außerhalb des Kubernetes-Netzwerks auf einer Bare-Metal-Infrastruktur befindet, wie im folgenden Diagramm dargestellt:
ProxySQL-Docker-Image
In diesem Beispiel verwenden wir das von Multiplenines verwaltete ProxySQL-Docker-Image, ein allgemeines öffentliches Image, das für die Mehrzwecknutzung entwickelt wurde. Das Image enthält kein Einstiegsskript und unterstützt Galera Cluster (zusätzlich zur integrierten Unterstützung für die MySQL-Replikation), wo ein zusätzliches Skript für Zustandsprüfungszwecke erforderlich ist.
Um einen ProxySQL-Container auszuführen, führen Sie einfach den folgenden Befehl aus:
$ docker run -d -v /path/to/proxysql.cnf:/etc/proxysql.cnf severalnines/proxysqlDieses Bild empfiehlt Ihnen, eine ProxySQL-Konfigurationsdatei an den Bereitstellungspunkt /etc/proxysql.cnf zu binden, obwohl Sie dies überspringen und später mithilfe der ProxySQL-Verwaltungskonsole konfigurieren können. Beispielkonfigurationen werden auf der Docker-Hub-Seite oder der Github-Seite bereitgestellt.
ProxySQL auf Kubernetes
Das Entwerfen der ProxySQL-Architektur ist ein subjektives Thema und hängt stark von der Platzierung der Anwendungs- und Datenbankcontainer sowie der Rolle von ProxySQL selbst ab. ProxySQL leitet nicht nur Abfragen weiter, sondern kann auch zum Umschreiben und Zwischenspeichern von Abfragen verwendet werden. Effiziente Cache-Treffer erfordern möglicherweise eine benutzerdefinierte Konfiguration, die speziell auf die Arbeitslast der Anwendungsdatenbank zugeschnitten ist.
Im Idealfall können wir ProxySQL so konfigurieren, dass es von Kubernetes mit zwei Konfigurationen verwaltet wird:
- ProxySQL als Kubernetes-Dienst (zentralisierte Bereitstellung).
- ProxySQL als Hilfscontainer in einem Pod (verteilte Bereitstellung).
Die erste Option ist ziemlich einfach, bei der wir einen ProxySQL-Pod erstellen und einen Kubernetes-Dienst daran anhängen. Anwendungen stellen dann über das Netzwerk an den konfigurierten Ports eine Verbindung zum ProxySQL-Dienst her. Der Standardwert ist 6033 für MySQL-Load-Balancing-Port und 6032 für ProxySQL-Administrationsport. Diese Bereitstellung wird im nächsten Blogbeitrag behandelt.
Die zweite Option ist etwas anders. Kubernetes hat ein Konzept namens „Pod“. Sie können einen oder mehrere Container pro Pod haben, diese sind relativ eng gekoppelt. Die Inhalte eines Pods werden immer gemeinsam lokalisiert und gemeinsam geplant und in einem gemeinsamen Kontext ausgeführt. Ein Pod ist die kleinste verwaltbare Containereinheit in Kubernetes.
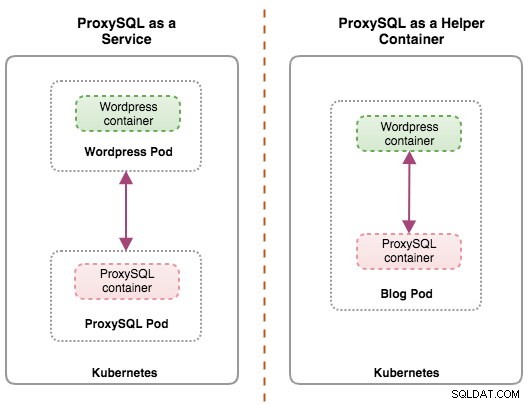
Beide Bereitstellungen können anhand des folgenden Diagramms leicht unterschieden werden:
Der Hauptgrund dafür, dass Pods mehrere Container haben können, ist die Unterstützung von Hilfsanwendungen, die eine primäre Anwendung unterstützen. Typische Beispiele für Hilfsanwendungen sind Daten-Puller, Daten-Pusher und Proxys. Hilfs- und primäre Anwendungen müssen häufig miteinander kommunizieren. Normalerweise geschieht dies über ein gemeinsam genutztes Dateisystem, wie in dieser Übung gezeigt, oder über die Loopback-Netzwerkschnittstelle localhost. Ein Beispiel für dieses Muster ist ein Webserver zusammen mit einem Hilfsprogramm, das ein Git-Repository nach neuen Updates abfragt.
Dieser Blogbeitrag behandelt die zweite Konfiguration – das Ausführen von ProxySQL als Hilfscontainer in einem Pod.
ProxySQL als Helfer in einem Pod
In diesem Setup führen wir ProxySQL als Hilfscontainer für unseren Wordpress-Container aus. Das folgende Diagramm veranschaulicht unsere High-Level-Architektur:
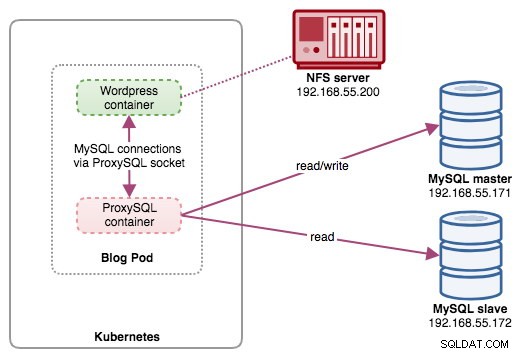
In diesem Setup ist der ProxySQL-Container eng mit dem Wordpress-Container gekoppelt, und wir haben ihn als „Blog“-Pod bezeichnet. Wenn eine Neuplanung stattfindet, z. B. wenn der Kubernetes-Worker-Knoten ausfällt, werden diese beiden Container immer zusammen als eine logische Einheit auf dem nächsten verfügbaren Host neu geplant. Um den Inhalt der Anwendungscontainer über mehrere Knoten hinweg persistent zu halten, müssen wir ein geclustertes oder entferntes Dateisystem verwenden, in diesem Fall NFS.
Die ProxySQL-Rolle besteht darin, dem Anwendungscontainer eine Datenbankabstraktionsschicht bereitzustellen. Da wir eine Zwei-Knoten-MySQL-Replikation als Backend-Datenbankdienst ausführen, ist die Lese-Schreib-Aufteilung von entscheidender Bedeutung, um den Ressourcenverbrauch auf beiden MySQL-Servern zu maximieren. ProxySQL zeichnet sich darin aus und erfordert nur minimale bis keine Änderungen an der Anwendung.
Es gibt eine Reihe weiterer Vorteile, wenn ProxySQL in diesem Setup ausgeführt wird:
- Bringen Sie die Caching-Funktion für Abfragen der in Kubernetes ausgeführten Anwendungsschicht am nächsten.
- Sichere Implementierung durch Verbindung über ProxySQL-UNIX-Socket-Datei. Es ist wie eine Pipe, die der Server und die Clients verwenden können, um sich zu verbinden und Anfragen und Daten auszutauschen.
- Verteilte Reverse-Proxy-Stufe mit Shared-Nothing-Architektur.
- Weniger Netzwerk-Overhead aufgrund der "Skip-Networking"-Implementierung.
- Zustandsloser Bereitstellungsansatz durch Verwendung von Kubernetes ConfigMaps.
Datenbank vorbereiten
Erstellen Sie die WordPress-Datenbank und den Benutzer auf dem Master und weisen Sie sie mit der richtigen Berechtigung zu:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Erstellen Sie außerdem den ProxySQL-Überwachungsbenutzer:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Laden Sie dann die Grant-Tabelle neu:
mysql-master> FLUSH PRIVILEGES;Pod vorbereiten
Kopieren Sie nun die folgenden Zeilen in eine Datei mit dem Namen blog-deployment.yml auf dem Host, auf dem kubectl konfiguriert ist:
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog
labels:
app: blog
spec:
replicas: 1
selector:
matchLabels:
app: blog
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: blog
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmp
- image: severalnines/proxysql
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Die YAML-Datei hat viele Zeilen und schauen wir uns nur den interessanten Teil an. Der erste Abschnitt:
apiVersion: apps/v1
kind: DeploymentDie erste Zeile ist die apiVersion. Unser Kubernetes-Cluster läuft auf v1.12, daher sollten wir auf die Kubernetes v1.12-API-Dokumentation verweisen und der Ressourcendeklaration gemäß dieser API folgen. Die nächste ist die Art, die angibt, welche Art von Ressource wir bereitstellen möchten. Bereitstellung, Service, ReplicaSet, DaemonSet, PersistentVolume sind einige der Beispiele.
Der nächste wichtige Abschnitt ist der Abschnitt "Container". Hier definieren wir alle Container, die wir gemeinsam in diesem Pod betreiben möchten. Der erste Teil ist der Wordpress-Container:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmpIn diesem Abschnitt weisen wir Kubernetes an, Wordpress 4.9 mithilfe des Apache-Webservers bereitzustellen, und wir haben dem Container den Namen „wordpress“ gegeben. Wir möchten auch, dass Kubernetes eine Reihe von Umgebungsvariablen übergibt:
- WORDPRESS_DB_HOST - Der Datenbankhost. Da sich unser ProxySQL-Container im selben Pod wie der Wordpress-Container befindet, ist es sicherer, stattdessen eine ProxySQL-Socket-Datei zu verwenden. Das Format zur Verwendung der Socket-Datei in Wordpress ist „localhost:{path to the socket file}“. Standardmäßig befindet es sich im Verzeichnis /tmp des ProxySQL-Containers. Dieser /tmp-Pfad wird zwischen Wordpress- und ProxySQL-Containern geteilt, indem „shared-data“-VolumeMounts verwendet werden, wie weiter unten gezeigt. Beide Container müssen dieses Volume mounten, um denselben Inhalt im /tmp-Verzeichnis zu teilen.
- WORDPRESS_DB_USER - Geben Sie den Benutzer der WordPress-Datenbank an.
- WORDPRESS_DB_PASSWORD - Das Passwort für WORDPRESS_DB_USER . Da wir das Passwort in dieser Datei nicht preisgeben möchten, können wir es mithilfe von Kubernetes Secrets verbergen. Hier weisen wir Kubernetes an, stattdessen die geheime Ressource „mysql-pass“ zu lesen. Secrets müssen vor der Pod-Bereitstellung erstellt werden, wie weiter unten erklärt.
Wir wollen auch Port 80 des Containers für den Endbenutzer veröffentlichen. Der in /var/www/html im Container gespeicherte Wordpress-Inhalt wird in unseren dauerhaften Speicher gemountet, der auf NFS läuft.
Als nächstes definieren wir den ProxySQL-Container:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
ports:
- containerPort: 6033
name: proxysqlIm obigen Abschnitt weisen wir Kubernetes an, ein ProxySQL mit severalnines/proxysql bereitzustellen Bildversion 1.4.12. Wir möchten auch, dass Kubernetes unsere benutzerdefinierte, vorkonfigurierte Konfigurationsdatei einbindet und sie /etc/proxysql.cnf im Container zuordnet. Es wird ein Volume namens „shared-data“ geben, das dem /tmp-Verzeichnis zugeordnet wird, um es mit dem Wordpress-Image zu teilen – ein temporäres Verzeichnis, das die Lebensdauer eines Pods teilt. Dadurch kann die ProxySQL-Socket-Datei (/tmp/proxysql.sock) vom Wordpress-Container verwendet werden, wenn eine Verbindung zur Datenbank hergestellt wird, wobei das TCP/IP-Netzwerk umgangen wird.
Der letzte Teil ist der Abschnitt "Volumes":
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Kubernetes muss drei Volumes für diesen Pod erstellen:
- wordpress-persistent-storage – Verwenden Sie den PersistentVolumeClaim Ressource, um den NFS-Export dem Container für die dauerhafte Datenspeicherung von Wordpress-Inhalten zuzuordnen.
- proxysql-config - Verwenden Sie die ConfigMap Ressource zum Zuordnen der ProxySQL-Konfigurationsdatei.
- shared-data – Verwenden Sie das emptyDir Ressource zum Mounten eines freigegebenen Verzeichnisses für unsere Container innerhalb des Pods. leeres Verzeichnis resource ist ein temporäres Verzeichnis, das die Lebensdauer eines Pods teilt.
Daher müssen wir basierend auf unserer obigen YAML-Definition eine Reihe von Kubernetes-Ressourcen vorbereiten, bevor wir mit der Bereitstellung des „Blog“-Pods beginnen können:
- PersistentVolume und PersistentVolumeClaim - Um die Webinhalte unserer Wordpress-Anwendung zu speichern, damit wir die letzten Änderungen nicht verlieren, wenn der Pod auf einen anderen Worker-Knoten verschoben wird.
- Geheimnisse - Um das Benutzerpasswort der Wordpress-Datenbank in der YAML-Datei zu verbergen.
- ConfigMap - Um die Konfigurationsdatei dem ProxySQL-Container zuzuordnen, damit Kubernetes sie automatisch erneut bereitstellen kann, wenn sie auf einen anderen Knoten verschoben wird.
PersistentVolume und PersistentVolumeClaim
Ein guter persistenter Speicher für Kubernetes sollte für alle Kubernetes-Knoten im Cluster zugänglich sein. Für diesen Blogbeitrag haben wir NFS als PersistentVolume (PV)-Anbieter verwendet, weil es einfach ist und standardmäßig unterstützt wird. Der NFS-Server befindet sich irgendwo außerhalb unseres Kubernetes-Netzwerks und wir haben ihn so konfiguriert, dass alle Kubernetes-Knoten mit der folgenden Zeile in /etc/exports:
zugelassen werden/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Beachten Sie, dass das NFS-Clientpaket auf allen Kubernetes-Knoten installiert sein muss. Andernfalls wäre Kubernetes nicht in der Lage, das NFS korrekt zu mounten. Auf allen Knoten:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSStellen Sie außerdem sicher, dass auf dem NFS-Server das Zielverzeichnis existiert:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressErstellen Sie dann eine Datei namens wordpress-pv-pvc.yml und fügen Sie die folgenden Zeilen hinzu:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: blog
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: blog
tier: frontendIn der obigen Definition möchten wir, dass Kubernetes 3 GB Volume-Speicherplatz auf dem NFS-Server für unseren Wordpress-Container zuweist. Beachten Sie, dass NFS für die Produktionsnutzung mit automatischer Bereitstellung und Speicherklasse konfiguriert werden sollte.
Erstellen Sie die PV- und PVC-Ressourcen:
$ kubectl create -f wordpress-pv-pvc.ymlÜberprüfen Sie, ob diese Ressourcen erstellt wurden und der Status „Gebunden“ lauten muss:
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hGeheimnisse
Die erste besteht darin, ein Geheimnis zu erstellen, das vom Wordpress-Container für WORDPRESS_DB_PASSWORD verwendet wird Umgebungsvariable. Der Grund liegt einfach darin, dass wir das Passwort nicht im Klartext in der YAML-Datei offenlegen möchten.
Erstellen Sie eine geheime Ressource namens mysql-pass und übergeben Sie das Passwort entsprechend:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdÜberprüfen Sie, ob unser Geheimnis erstellt wurde:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mConfigMap
Wir müssen auch eine ConfigMap-Ressource für unseren ProxySQL-Container erstellen. Eine Kubernetes-ConfigMap-Datei enthält Schlüssel-Wert-Paare von Konfigurationsdaten, die in Pods verwendet oder zum Speichern von Konfigurationsdaten verwendet werden können. Mit ConfigMaps können Sie Konfigurationsartefakte von Bildinhalten entkoppeln, um containerisierte Anwendungen portabel zu halten.
Da unser Datenbankserver bereits auf Bare-Metal-Servern mit einem statischen Hostnamen und einer statischen IP-Adresse sowie einem statischen Überwachungsbenutzernamen und -kennwort ausgeführt wird, speichert die ConfigMap-Datei in diesem Anwendungsfall vorkonfigurierte Konfigurationsinformationen über den ProxySQL-Dienst, den wir verwenden möchten.
Erstellen Sie zuerst eine Textdatei namens proxysql.cnf und fügen Sie die folgenden Zeilen hinzu:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)Achten Sie besonders auf die Abschnitte „mysql_servers“ und „mysql_users“, wo Sie die Werte möglicherweise ändern müssen, damit sie zu Ihrem Datenbank-Cluster-Setup passen. In diesem Fall haben wir zwei Datenbankserver, die in MySQL Replication ausgeführt werden, wie im folgenden Topologie-Screenshot von ClusterControl zusammengefasst:
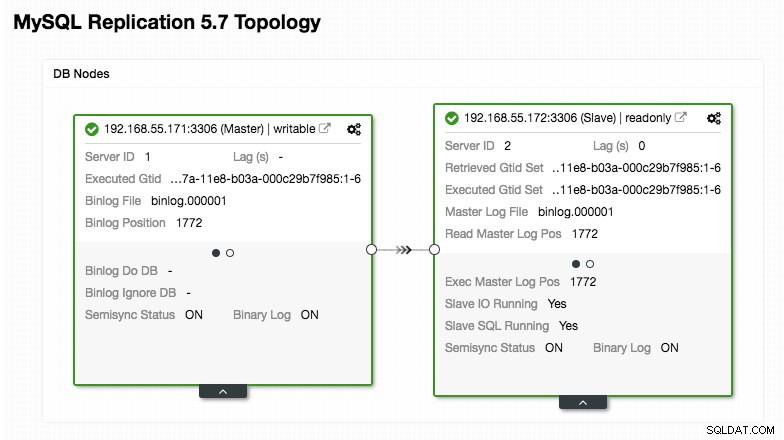
Alle Schreibvorgänge sollten an den Master-Knoten gehen, während Lesevorgänge an Hostgruppe 20 weitergeleitet werden, wie im Abschnitt „mysql_query_rules“ definiert. Das ist die Grundlage des Read/Write-Splittings und wir wollen sie komplett nutzen.
Importieren Sie dann die Konfigurationsdatei in ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdÜberprüfen Sie, ob die ConfigMap in Kubernetes geladen ist:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sBereitstellen des Pods
Jetzt sollten wir in der Lage sein, den Blog-Pod bereitzustellen. Senden Sie den Bereitstellungsjob an Kubernetes:
$ kubectl create -f blog-deployment.ymlÜberprüfen Sie den Pod-Status:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-t4cb7 2/2 Running 0 100sEs muss 2/2 unter der Spalte READY anzeigen, was darauf hinweist, dass zwei Container im Pod ausgeführt werden. Verwenden Sie das Optionsflag -c, um die Wordpress- und ProxySQL-Container im Blog-Pod zu überprüfen:
$ kubectl logs blog-54755cbcb5-t4cb7 -c wordpress
$ kubectl logs blog-54755cbcb5-t4cb7 -c proxysqlAus dem Protokoll des ProxySQL-Containers sollten Sie die folgenden Zeilen sehen:
2018-10-20 08:57:14 [INFO] Dumping current MySQL Servers structures for hostgroup ALL
HID: 10 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 10 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: OFFLINE_HARD , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:HID 10 (Writer-Hostgruppe) darf nur einen ONLINE-Knoten haben (der einen einzelnen Master anzeigt) und der andere Host muss sich mindestens im Status OFFLINE_HARD befinden. Für HID 20 wird erwartet, dass es für alle Knoten ONLINE ist (was auf mehrere Lesereplikate hinweist).
Um eine Zusammenfassung der Bereitstellung zu erhalten, verwenden Sie das Beschreibungs-Flag:
$ kubectl describe deployments blogUnser Blog wird jetzt ausgeführt, wir können jedoch nicht von außerhalb des Kubernetes-Netzwerks darauf zugreifen, ohne den Dienst zu konfigurieren, wie im nächsten Abschnitt erläutert.
Blogdienst erstellen
Der letzte Schritt besteht darin, einen Dienst an unseren Pod anzuhängen. Dies soll sicherstellen, dass unser Wordpress-Blog-Pod von der Außenwelt aus zugänglich ist. Erstellen Sie eine Datei namens blog-svc.yml und fügen Sie die folgende Zeile ein:
apiVersion: v1
kind: Service
metadata:
name: blog
labels:
app: blog
tier: frontend
spec:
type: NodePort
ports:
- name: blog
nodePort: 30080
port: 80
selector:
app: blog
tier: frontendErstellen Sie den Dienst:
$ kubectl create -f blog-svc.ymlÜberprüfen Sie, ob der Dienst korrekt erstellt wurde:
example@sqldat.com:~/proxysql-blog# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blog NodePort 10.96.140.37 <none> 80:30080/TCP 26s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 43hDer vom Blog-Pod veröffentlichte Port 80 wird jetzt über Port 30080 der Außenwelt zugeordnet. Wir können auf unseren Blog-Beitrag unter https://{any_kubernetes_host}:30080/ zugreifen und sollten auf die Installationsseite von Wordpress weitergeleitet werden. Wenn wir mit der Installation fortfahren, wird der Teil der Datenbankverbindung übersprungen und direkt diese Seite angezeigt:
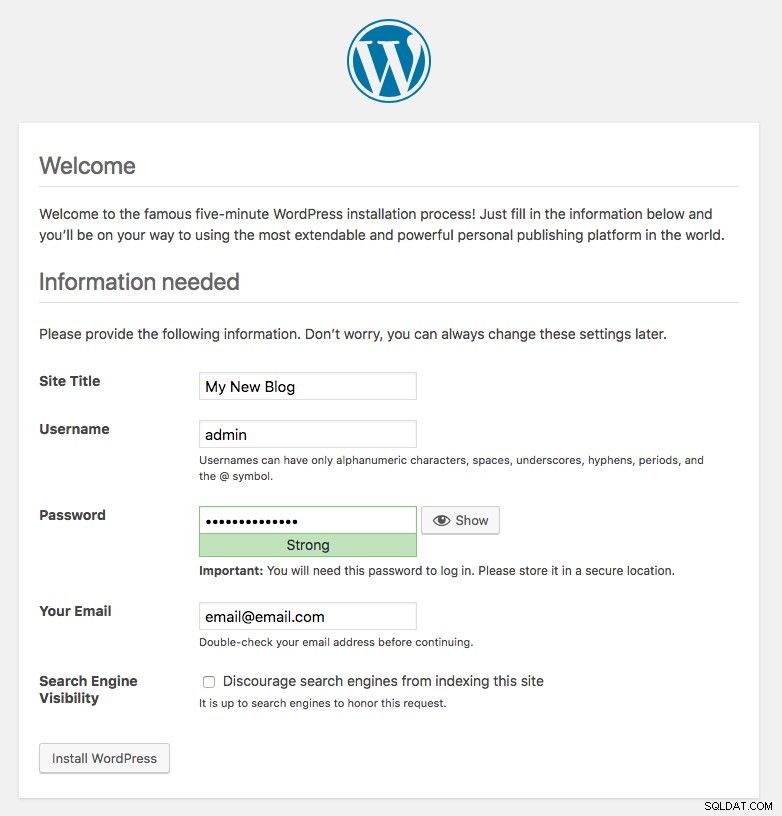
Es zeigt an, dass unsere MySQL- und ProxySQL-Konfiguration in der Datei wp-config.php korrekt konfiguriert ist. Andernfalls würden Sie zur Datenbankkonfigurationsseite weitergeleitet.
Unsere Bereitstellung ist jetzt abgeschlossen.
ProxySQL-Container in einem Pod verwalten
Failover und Wiederherstellung werden voraussichtlich automatisch von Kubernetes gehandhabt. Wenn beispielsweise der Kubernetes-Worker ausfällt, wird der Pod im nächsten verfügbaren Knoten nach --pod-eviction-timeout (standardmäßig 5 Minuten) neu erstellt. Wenn der Container abstürzt oder zerstört wird, ersetzt Kubernetes ihn fast sofort.
Einige gängige Verwaltungsaufgaben werden voraussichtlich anders sein, wenn sie in Kubernetes ausgeführt werden, wie in den nächsten Abschnitten gezeigt.
Hoch- und Runterskalieren
In der obigen Konfiguration haben wir ein Replikat in unserer Bereitstellung bereitgestellt. Ändern Sie zum Hochskalieren einfach die spec.replicas Wert entsprechend mit dem kubectl-Bearbeitungsbefehl:
$ kubectl edit deployment blogEs öffnet die Deployment-Definition in einer Standard-Textdatei und ändert einfach die spec.replicas Wert auf etwas Höheres, zum Beispiel "replicas:3". Speichern Sie dann die Datei und überprüfen Sie sofort den Rollout-Status mit dem folgenden Befehl:
$ kubectl rollout status deployment blog
Waiting for deployment "blog" rollout to finish: 1 of 3 updated replicas are available...
Waiting for deployment "blog" rollout to finish: 2 of 3 updated replicas are available...
deployment "blog" successfully rolled outAn diesem Punkt laufen drei Blog-Pods (Wordpress + ProxySQL) gleichzeitig in Kubernetes:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 11m
blog-54755cbcb5-cwpdj 2/2 Running 0 11m
blog-54755cbcb5-jxtvc 2/2 Running 0 22mAn diesem Punkt sieht unsere Architektur in etwa so aus:
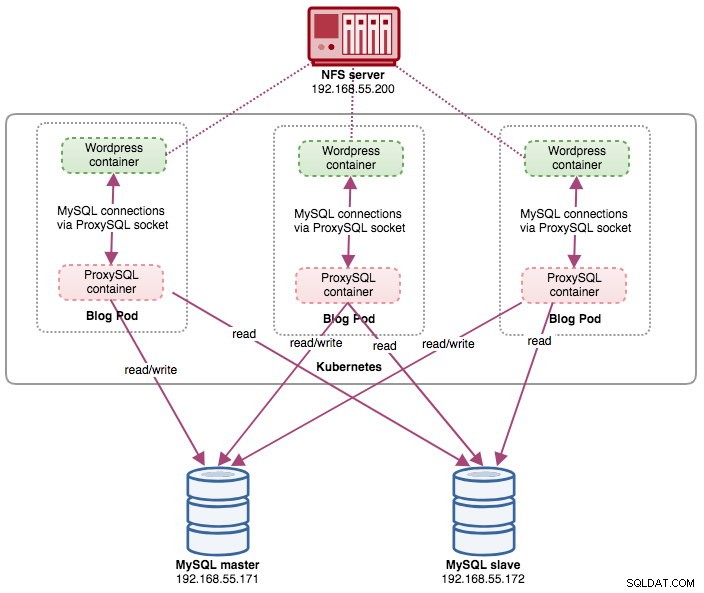
Beachten Sie, dass möglicherweise mehr Anpassungen als bei unserer aktuellen Konfiguration erforderlich sind, um Wordpress in einer horizontal skalierten Produktionsumgebung reibungslos auszuführen (denken Sie an statische Inhalte, Sitzungsverwaltung und andere). Diese würden eigentlich den Rahmen dieses Blogposts sprengen.
Das Herunterskalieren ist ähnlich.
Konfigurationsverwaltung
Das Konfigurationsmanagement ist in ProxySQL wichtig. Hier passiert die Magie, wenn Sie Ihren eigenen Satz von Abfrageregeln definieren können, um Abfragen zwischenzuspeichern, Firewalls zu erstellen und umzuschreiben. Im Gegensatz zur üblichen Praxis, wo ProxySQL über die Admin-Konsole konfiguriert und mit „SAVE .. TO DISK“ in die Persistenz verschoben wird, bleiben wir nur bei Konfigurationsdateien, um die Dinge in Kubernetes portabler zu machen. Aus diesem Grund verwenden wir ConfigMaps.
Da wir uns auf unsere zentralisierte Konfiguration verlassen, die von Kubernetes ConfigMaps gespeichert wird, gibt es eine Reihe von Möglichkeiten, Konfigurationsänderungen vorzunehmen. Erstens, indem Sie den kubectl-Bearbeitungsbefehl verwenden:
$ kubectl edit configmap proxysql-configmapEs öffnet die Konfiguration in einem Standard-Texteditor und Sie können direkt Änderungen daran vornehmen und die Textdatei speichern, sobald Sie fertig sind. Andernfalls sollten Sie die Configmaps auch neu erstellen:
$ vi proxysql.cnf # edit the configuration first
$ kubectl delete configmap proxysql-configmap
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnfNachdem die Konfiguration per Push in ConfigMap übertragen wurde, starten Sie den Pod oder Container neu, wie im Abschnitt „Dienststeuerung“ gezeigt. Die Konfiguration des Containers über die ProxySQL-Verwaltungsschnittstelle (Port 6032) macht ihn nach der Neuplanung des Pods durch Kubernetes nicht dauerhaft.
Dienststeuerung
Da die beiden Container in einem Pod eng miteinander verbunden sind, besteht die beste Methode zum Anwenden der ProxySQL-Konfigurationsänderungen darin, Kubernetes zum Ersetzen des Pods zu zwingen. Bedenken Sie, dass wir nach der Skalierung jetzt drei Blog-Pods haben:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-jxtvc 2/2 Running 1 22mVerwenden Sie den folgenden Befehl, um jeweils einen Pod zu ersetzen:
$ kubectl get pod blog-54755cbcb5-6fnqn -n default -o yaml | kubectl replace --force -f -
pod "blog-54755cbcb5-6fnqn" deleted
pod/blog-54755cbcb5-6fnqnÜberprüfen Sie dann mit Folgendem:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-qs6jm 2/2 Running 1 2m26sSie werden feststellen, dass der letzte Pod neu gestartet wurde, indem Sie sich die Spalten AGE und RESTART ansehen, es wurde ein anderer Pod-Name angezeigt. Wiederholen Sie die gleichen Schritte für die restlichen Pods. Andernfalls können Sie auch den Befehl „docker kill“ verwenden, um den ProxySQL-Container manuell innerhalb des Kubernetes-Worker-Knotens zu beenden. Zum Beispiel:
(kube-worker)$ docker kill $(docker ps | grep -i proxysql_blog | awk {'print $1'})Kubernetes ersetzt dann den abgebrochenen ProxySQL-Container durch einen neuen.
Überwachung
Verwenden Sie den Befehl kubectl exec, um eine SQL-Anweisung über den MySQL-Client auszuführen. Zum Beispiel, um die Abfrageverarbeitung zu überwachen:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032
mysql> SELECT * FROM stats_mysql_query_digest;Oder mit einem Einzeiler:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032 -e 'SELECT * FROM stats_mysql_query_digest'Durch Ändern der SQL-Anweisung können Sie andere ProxySQL-Komponenten überwachen oder beliebige Verwaltungsaufgaben über diese Admin-Konsole ausführen. Auch hier bleibt es nur während der Lebensdauer des ProxySQL-Containers bestehen und wird nicht beibehalten, wenn der Pod neu geplant wird.
Abschließende Gedanken
ProxySQL spielt eine Schlüsselrolle, wenn Sie Ihre Anwendungscontainer skalieren und auf intelligente Weise auf ein verteiltes Datenbank-Backend zugreifen möchten. Es gibt eine Reihe von Möglichkeiten, ProxySQL auf Kubernetes bereitzustellen, um unser Anwendungswachstum bei der Ausführung in großem Maßstab zu unterstützen. Dieser Blogpost behandelt nur einen davon.
In einem kommenden Blogbeitrag werden wir uns ansehen, wie ProxySQL in einem zentralisierten Ansatz ausgeführt wird, indem es als Kubernetes-Dienst verwendet wird.