In unserem vorherigen Blog über SCUMM-Dashboards haben wir uns das MySQL-Übersichts-Dashboard angesehen. Die neue Version von ClusterControl (Version 1.7) bietet eine Reihe von hochauflösenden Diagrammen mit nützlichen Metriken, und wir haben die Bedeutung jeder der Metriken durchgegangen und erklärt, wie sie Ihnen bei der Fehlerbehebung Ihrer Datenbank helfen. In diesem Blog werden wir uns das MySQL-Replikations-Dashboard ansehen. Lassen Sie uns mit den Details dieses Dashboards fortfahren, was zu bieten hat.
MySQL-Replikations-Dashboard
Das MySQL-Replikations-Dashboard bietet eine sehr einfache Reihe von Diagrammen, die es einfacher machen, Ihren MySQL-Master und Ihre Replik(en) zu überwachen. Beginnend von oben zeigt es die wichtigsten Variablen und Informationen, um den Zustand der Replik(en) oder sogar des Masters zu bestimmen. Dieses Dashboard bietet einen sehr nützlichen Teil bei der Überprüfung des Zustands der Slaves oder eines Masters im Master-Master-Setup. Auf diesem Dashboard kann man auch die Binärlog-Erstellung des Masters überprüfen und die Gesamtgröße in Bezug auf die generierte Größe zu einem bestimmten Zeitraum bestimmen.
Als Erstes präsentiert Ihnen dieses Dashboard die wichtigsten Informationen, die Sie möglicherweise zum Zustand Ihrer Replik benötigen. Siehe folgendes Diagramm:

Grundsätzlich zeigt es Ihnen den IO_Thread, den SQL_Thread, den Replikationsfehler des Slave-Threads und ob die Read_only-Variable aktiviert ist. Aus dem Beispiel-Screenshot oben zeigen alle Informationen, dass mein Slave 192.168.70.20 gesund ist und normal läuft.
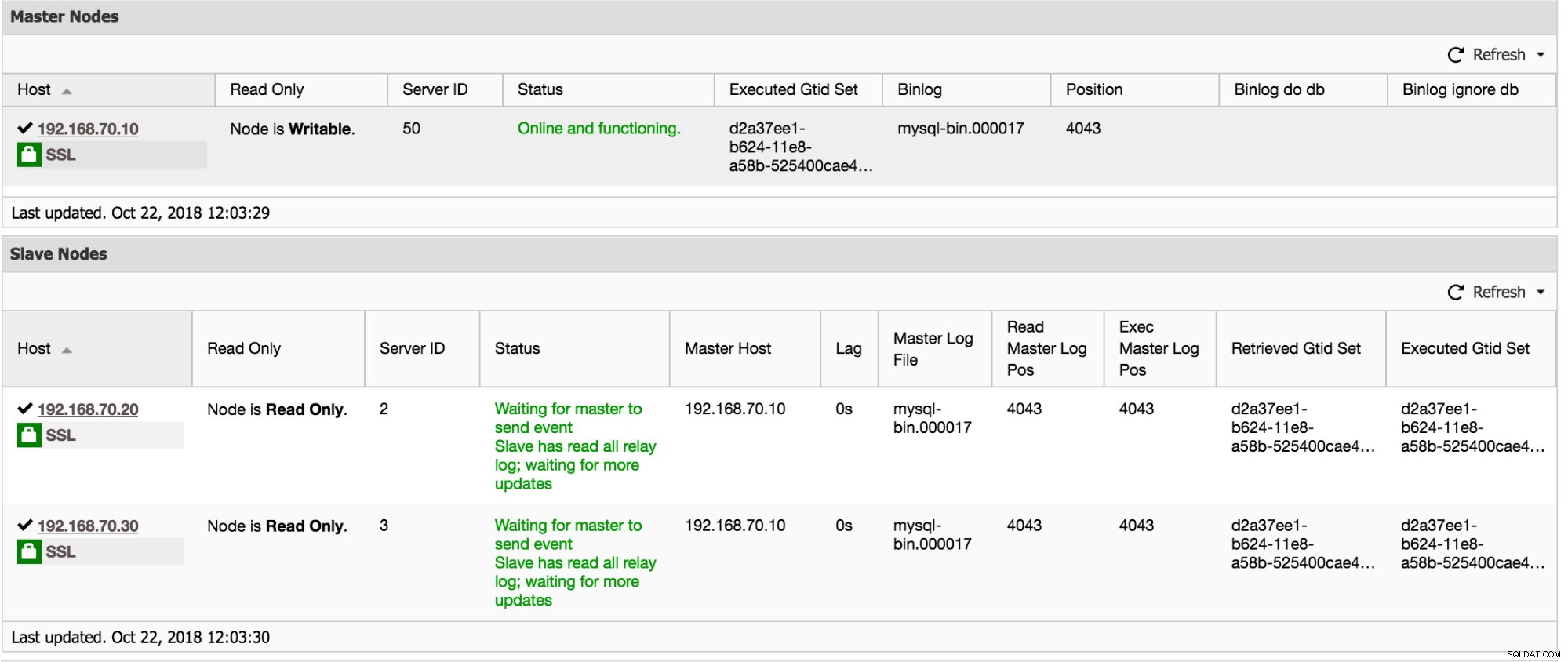
Darüber hinaus hat ClusterControl auch Informationen zu sammeln, wenn Sie zu Cluster -> Übersicht gehen. Scrollen Sie nach unten und Sie können die folgende Grafik sehen:
Ein weiterer Ort zum Anzeigen des Replikations-Setups ist die Topologieansicht des Replikations-Setups, auf die unter Cluster -> Topology zugegriffen werden kann. Es gibt auf einen schnellen Blick einen Überblick über die verschiedenen Knoten im Setup, ihre Rollen, Replikationsverzögerung, abgerufene GTID und mehr. Siehe folgendes Diagramm:
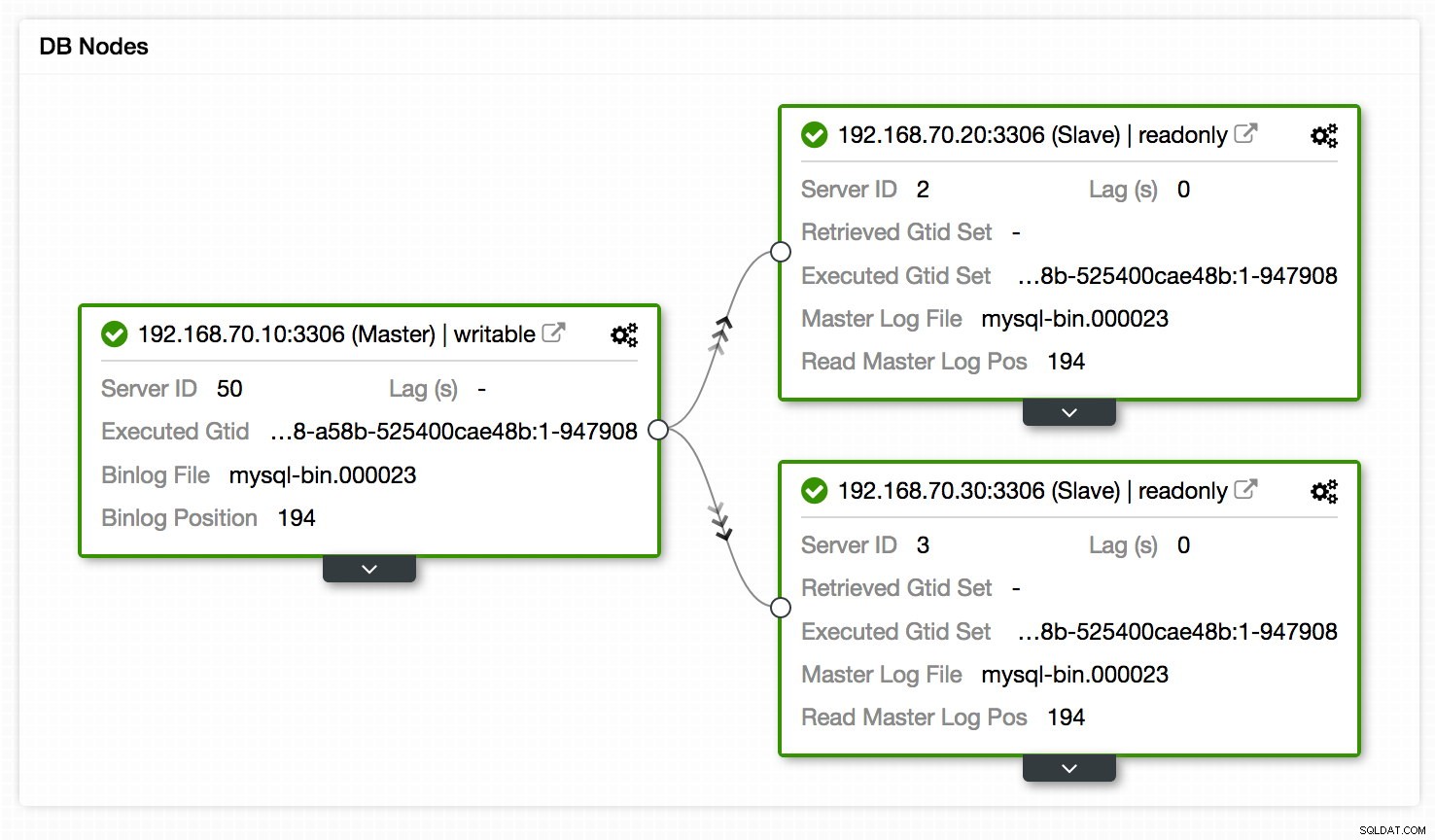
Darüber hinaus zeigt die Topologieansicht auch alle verschiedenen Knoten, die Teil Ihres Datenbank-Clusters sind, ob es sich um die Datenbankknoten, Load Balancer (ProxySQL/MaxScale/HaProxy) oder Arbitrators (garbd) handelt, sowie die Verbindungen zwischen ihnen. Die Knoten, Verbindungen und deren Status werden von ClusterControl ermittelt. Da ClusterControl die Knoten kontinuierlich überwacht und Zustandsinformationen speichert, werden alle Änderungen in der Topologie in der Weboberfläche widergespiegelt. Falls ein Ausfall von Knoten gemeldet wird, können Sie diese Ansicht zusammen mit den SCUMM-Dashboards verwenden und sehen, welche Auswirkungen dies möglicherweise verursacht hat.
Die Topologieansicht hat eine gewisse Ähnlichkeit mit Orchestrator, in dem Sie die Knoten verwalten, Master ändern können, indem Sie das Objekt per Drag &Drop auf den gewünschten Master ziehen, Knoten neu starten und Daten synchronisieren. Um mehr über unsere Topologieansicht zu erfahren, empfehlen wir Ihnen, unseren vorherigen Blog zu lesen – „Visualizing your Cluster Topology in ClusterControl“.
Fahren wir nun mit den Grafiken fort.
-
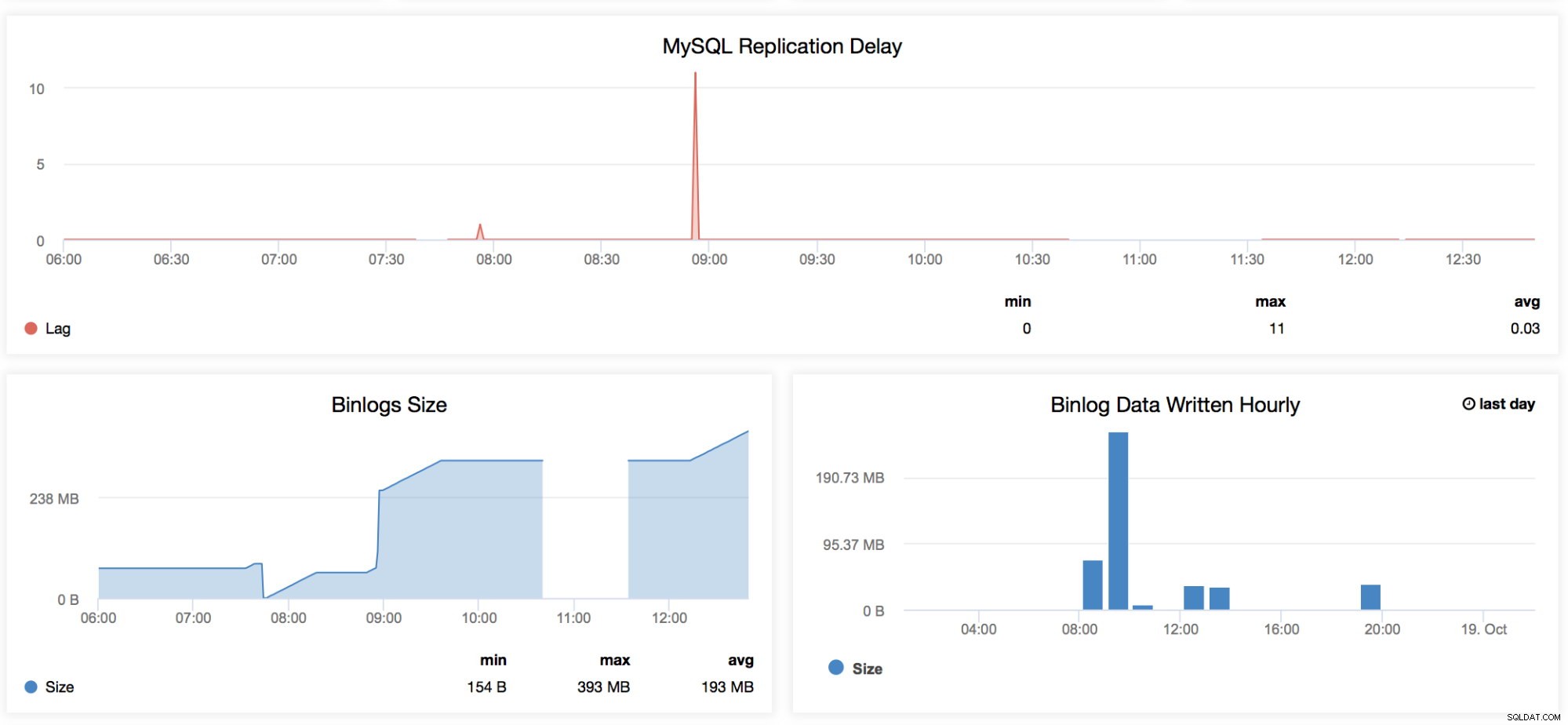
MySQL-Replikationsverzögerung
Dieses Diagramm ist jedem sehr vertraut, der MySQL verwaltet, insbesondere denjenigen, die täglich an ihrem Master-Slave-Setup arbeiten. Dieses Diagramm enthält die Trends für alle Verzögerungen, die für einen bestimmten Zeitbereich aufgezeichnet wurden, der in diesem Dashboard angegeben ist. Wann immer wir die periodische Abfallzeit überprüfen möchten, die unser Replikat hat, ist diese Grafik gut anzusehen. Es gibt bestimmte Fälle, in denen ein Replikat aus seltsamen Gründen verzögert werden kann, z. B. wenn Ihr RAID eine herabgesetzte BBU hat und ersetzt werden muss, eine Tabelle keinen eindeutigen Schlüssel hat, aber nicht auf dem Master, ein unerwünschter vollständiger Tabellenscan oder vollständiger Indexscan oder eine fehlerhafte Abfrage wurde von einem Entwickler ausgeführt. Dies ist auch ein guter Indikator, um festzustellen, ob Slave-Lag ein Schlüsselproblem ist, dann sollten Sie vielleicht die parallele Replikation nutzen. -
Binlog-Größe
Diese Diagramme sind miteinander verbunden. Das Diagramm „Binlog-Größe“ zeigt Ihnen, wie Ihr Knoten das Binärlog generiert, und hilft bei der Bestimmung seiner Größe basierend auf dem Zeitraum, in dem Sie scannen. -
Stündlich geschriebene Binlog-Daten
Die stündlich geschriebenen Binlog-Daten sind ein Diagramm, das auf dem aktuellen Tag und dem aufgezeichneten Vortag basiert. Dies kann nützlich sein, wenn Sie feststellen möchten, wie groß Ihr Knoten ist, der Schreibvorgänge akzeptiert, die Sie später für die Kapazitätsplanung verwenden können.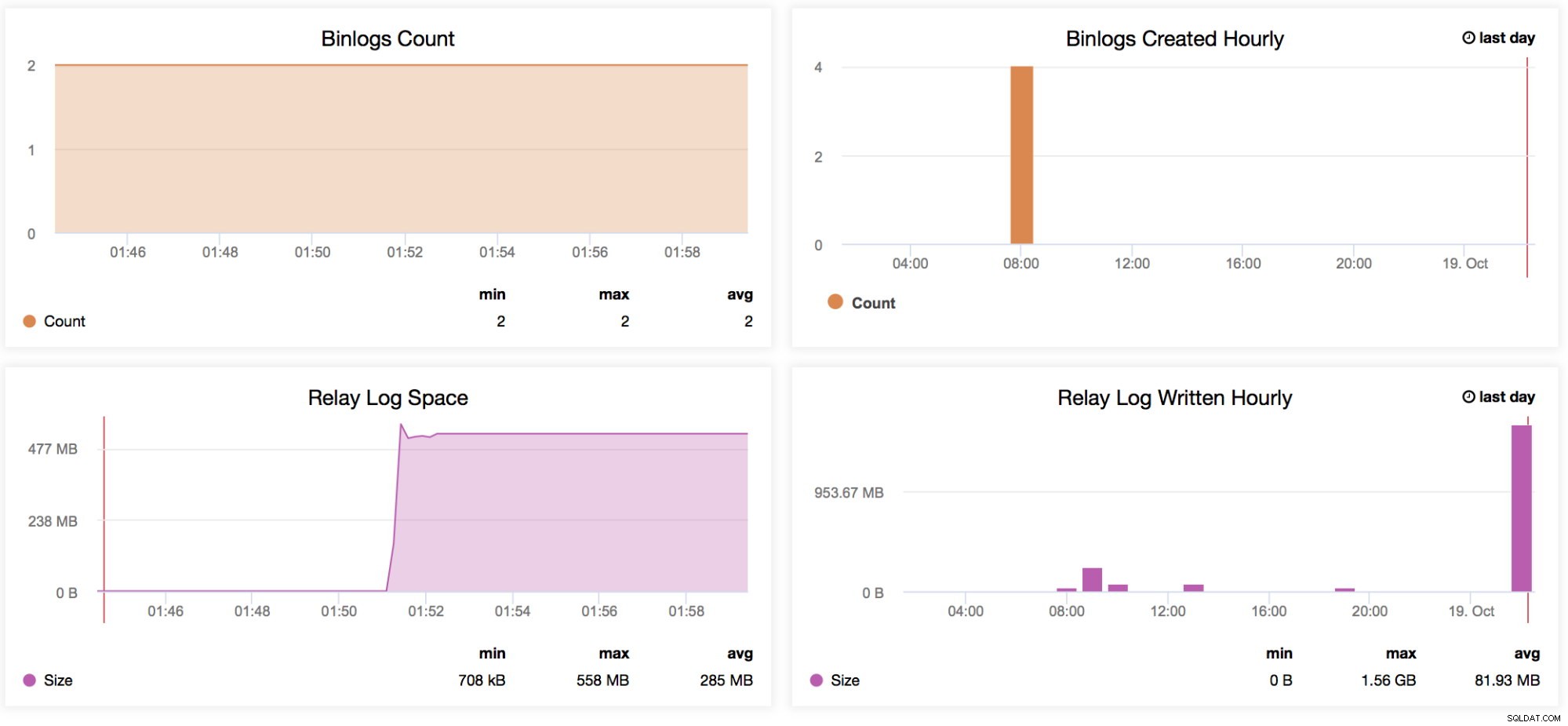
-
Anzahl der Binlogs
Angenommen, Sie erwarten für eine bestimmte Woche einen hohen Traffic. Sie möchten vergleichen, wie viele Schreibvorgänge Ihren Master und Ihre Slaves mit der Vorwoche durchlaufen haben. Dieses Diagramm ist für diese Art von Situation sehr nützlich - Um festzustellen, wie hoch die generierten Binärprotokolle auf dem Master selbst oder sogar auf den Slaves waren, wenn die Variable log_slave_updates aktiviert ist. Sie können diesen Indikator auch verwenden, um Ihre generierten Master vs. Slaves-Binärlogdaten zu bestimmen, insbesondere wenn Sie einige Tabellen oder Schemas (replicate_ignore_db, replicate_ignore_table, replicate_wild_do_table) auf Ihren Slaves filtern, die generiert wurden, während log_slave_updates aktiviert war. -
Stündlich erstellte Binlogs
Dieses Diagramm ist eine schnelle Übersicht, um Ihre Binlog-Erstellung stündlich von gestern und heute zu vergleichen. -
Speicherplatz für Relaisprotokolle
Dieses Diagramm dient als Grundlage für die generierten Relaisprotokolle Ihrer Replik. Wenn es zusammen mit dem Diagramm MySQL Replication Delay verwendet wird, hilft es zu bestimmen, wie groß die Anzahl der generierten Relay-Logs ist, was der Administrator im Hinblick auf die Festplattenverfügbarkeit der aktuellen Replik berücksichtigen muss. Es kann zu Problemen führen, wenn Ihr Slave rigoros verzögert und eine große Anzahl von Relaisprotokollen generiert. Dies kann Ihren Speicherplatz schnell verbrauchen. Es gibt bestimmte Situationen, in denen der Slave/das Replikat aufgrund einer hohen Anzahl von Schreibvorgängen vom Master enorm verzögert, sodass das Generieren einer großen Menge an Protokollen einige ernsthafte Probleme auf diesem Replikat verursachen kann. Dies kann dem Betriebsteam helfen, wenn es mit seinem Management über die Kapazitätsplanung spricht. -
Stündlich geschriebenes Relaisprotokoll
Dasselbe wie der Relaisprotokollbereich, fügt aber einen schnellen Überblick hinzu, um Ihre von gestern und heute geschriebenen Relaisprotokolle zu vergleichen.
Schlussfolgerung
Sie haben gelernt, dass die Verwendung von SCUMM zur Überwachung Ihrer MySQL-Replikation die Produktivität und Effizienz des Betriebsteams erhöht. Die Verwendung der Funktionen, die wir aus früheren Versionen haben, in Kombination mit den von SCUMM bereitgestellten Diagrammen, ist, als würden Sie ins Fitnessstudio gehen und massive Verbesserungen Ihrer Produktivität feststellen. Das kann SCUMM bieten:Überwachung auf Steroiden! (Nun, wir befürworten nicht, dass Sie Steroide nehmen sollten, wenn Sie ins Fitnessstudio gehen!)
In Teil 3 dieses Blogs werde ich die InnoDB-Metriken und MySQL-Leistungsschema-Dashboards diskutieren.



