Die Bereitstellung eines Datenbank-Clusters ist kein Hexenwerk – es gibt viele Anleitungen dazu. Aber woher wissen Sie, dass das, was Sie gerade bereitgestellt haben, produktionsbereit ist? Manuelle Bereitstellungen können auch mühsam und sich wiederholend sein. Je nach Anzahl der Knoten im Cluster können die Bereitstellungsschritte zeitaufwändig und fehleranfällig sein. Konfigurationsmanagement-Tools wie Puppet, Chef und Ansible sind bei der Bereitstellung von Infrastruktur beliebt, aber für zustandsbehaftete Datenbank-Cluster müssen Sie umfangreiche Skripterstellung durchführen, um die Bereitstellung des gesamten Datenbank-HA-Stacks zu handhaben. Darüber hinaus muss das gewählte Template/Modul/Kochbuch/Rolle sorgfältig getestet werden, bevor Sie ihm als Teil Ihrer Infrastrukturautomatisierung vertrauen können. Versionsänderungen erfordern, dass die Skripte aktualisiert und erneut getestet werden.
Die gute Nachricht ist, dass ClusterControl die Bereitstellung des gesamten Stacks automatisiert – und das sogar kostenlos! Wir haben Tausende von Produktionsclustern bereitgestellt und eine Reihe von Vorkehrungen getroffen, um sicherzustellen, dass sie produktionsbereit sind. Es werden verschiedene Topologien unterstützt, von der Master-Slave-Replikation bis hin zu Galera-, NDB- und InnoDB-Clustern, mit verschiedenen Datenbank-Proxys an der Spitze.
Ein Hochverfügbarkeitsstapel, der über ClusterControl bereitgestellt wird, besteht aus drei Schichten:
- Datenbankebene (z. B. Galera Cluster)
- Reverse-Proxy-Schicht (z. B. HAProxy oder ProxySQL)
- Keepalived-Schicht, die bei Verwendung von Virtual IP eine hohe Verfügbarkeit der Proxy-Schicht sicherstellt
In diesem Blog zeigen wir Ihnen, wie Sie einen produktionstauglichen Galera-Cluster komplett mit Load Balancern für die Hochverfügbarkeitskonfiguration bereitstellen. Das komplette Setup besteht aus 6 Hosts:
- 1 Host – ClusterControl (Bereitstellung, Überwachung, Verwaltungsserver)
- 3 Hosts – MySQL Galera-Cluster
- 2 Hosts – Reverse Proxys fungieren als Load Balancer vor dem Cluster.
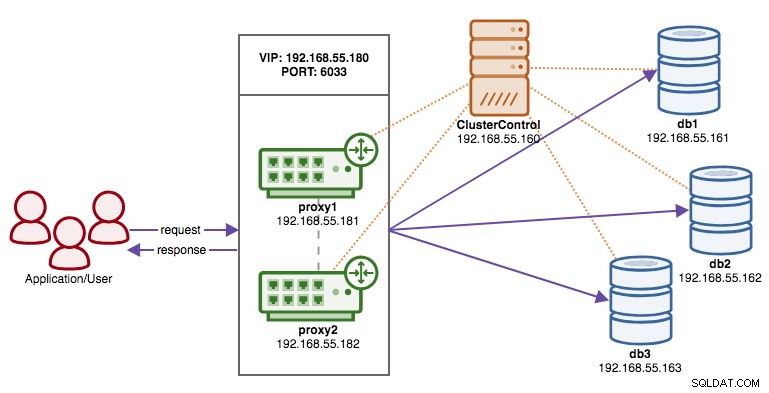
Das folgende Diagramm veranschaulicht unser Endergebnis nach Abschluss der Bereitstellung:
Voraussetzungen
ClusterControl muss sich auf einem unabhängigen Knoten befinden, der nicht Teil des Clusters ist. Laden Sie ClusterControl herunter, und die Seite generiert eine für Sie einzigartige Lizenz und zeigt die Schritte zur Installation von ClusterControl:
$ wget -O install-cc https://severalnines.com/scripts/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userBefolgen Sie die Anweisungen, in denen Sie durch die Einrichtung des MySQL-Servers, des MySQL-Root-Passworts auf dem ClusterControl-Knoten, des cmon-Passworts für die Verwendung von ClusterControl usw. geführt werden. Nach Abschluss der Installation sollten Sie die folgende Zeile erhalten:
Determining network interfaces. This may take a couple of minutes. Do NOT press any key.
Public/external IP => https://{public_IP}/clustercontrol
Installation successful. If you want to uninstall ClusterControl then run install-cc --uninstall.Generieren Sie dann auf dem ClusterControl-Server einen SSH-Schlüssel, mit dem wir später das passwortlose SSH einrichten. Sie können jeden Benutzer im System verwenden, aber er muss Superuser-Operationen (sudoer) ausführen können. In diesem Beispiel haben wir den Root-Benutzer ausgewählt:
$ whoami
root
$ ssh-keygen -t rsaRichten Sie passwortloses SSH zu allen Knoten ein, die Sie über ClusterControl überwachen/verwalten möchten. In diesem Fall richten wir dies auf allen Knoten im Stapel ein (einschließlich des ClusterControl-Knotens selbst). Führen Sie auf dem ClusterControl-Knoten die folgenden Befehle aus und geben Sie das Root-Passwort an, wenn Sie dazu aufgefordert werden:
$ ssh-copy-id example@sqldat.com # clustercontrol
$ ssh-copy-id example@sqldat.com # galera1
$ ssh-copy-id example@sqldat.com # galera2
$ ssh-copy-id example@sqldat.com # galera3
$ ssh-copy-id example@sqldat.com # proxy1
$ ssh-copy-id example@sqldat.com # proxy2Sie können dann überprüfen, ob es funktioniert, indem Sie den folgenden Befehl auf dem ClusterControl-Knoten ausführen:
$ ssh example@sqldat.com "ls /root"Stellen Sie sicher, dass Sie das Ergebnis des obigen Befehls sehen können, ohne das Passwort eingeben zu müssen.
Bereitstellen des Clusters
ClusterControl unterstützt alle Anbieter für Galera Cluster (Codership, Percona und MariaDB). Es gibt einige geringfügige Unterschiede, die Ihre Entscheidung für die Auswahl des Anbieters beeinflussen können. Wenn Sie mehr über die Unterschiede zwischen ihnen erfahren möchten, lesen Sie unseren vorherigen Blog-Beitrag – Galera-Cluster-Vergleich – Codership vs. Percona vs. MariaDB.
Für die Produktionsbereitstellung ist ein Galera-Cluster mit drei Knoten das Minimum, das Sie haben sollten. Sie können es später jederzeit nach der Bereitstellung des Clusters manuell oder über ClusterControl skalieren. Wir öffnen unsere ClusterControl-Benutzeroberfläche unter https://192.168.55.160/clustercontrol und erstellen den ersten Administratorbenutzer. Gehen Sie dann zum oberen Menü und klicken Sie auf Bereitstellen -> MySQL Galera und Ihnen wird folgender Dialog angezeigt:
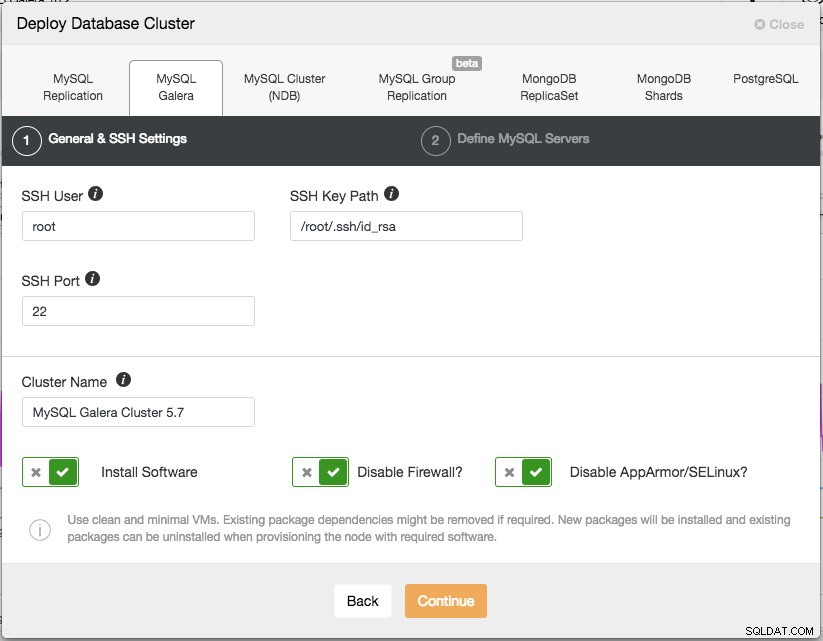
Es gibt zwei Schritte, der erste sind die "Allgemeinen &SSH-Einstellungen". Hier müssen wir den SSH-Benutzer konfigurieren, den ClusterControl verwenden soll, um sich mit den Datenbankknoten zu verbinden, zusammen mit dem Pfad zum SSH-Schlüssel (wie im Abschnitt „Voraussetzungen“ generiert) sowie dem SSH-Port der Datenbankknoten. ClusterControl geht davon aus, dass alle Datenbankknoten mit demselben SSH-Benutzer, -Schlüssel und -Port konfiguriert sind. Als nächstes geben Sie dem Cluster einen Namen, in diesem Fall verwenden wir "MySQL Galera Cluster 5.7". Dieser Wert kann später geändert werden. Wählen Sie dann die Optionen aus, um ClusterControl anzuweisen, die erforderliche Software zu installieren, die Firewall zu deaktivieren und auch das Sicherheitserweiterungsmodul auf der jeweiligen Linux-Distribution zu deaktivieren. Es wird empfohlen, alle diese einzuschalten, um das Potenzial einer erfolgreichen Bereitstellung zu maximieren.
Klicken Sie auf „Fortfahren“ und Ihnen wird das folgende Dialogfeld angezeigt:
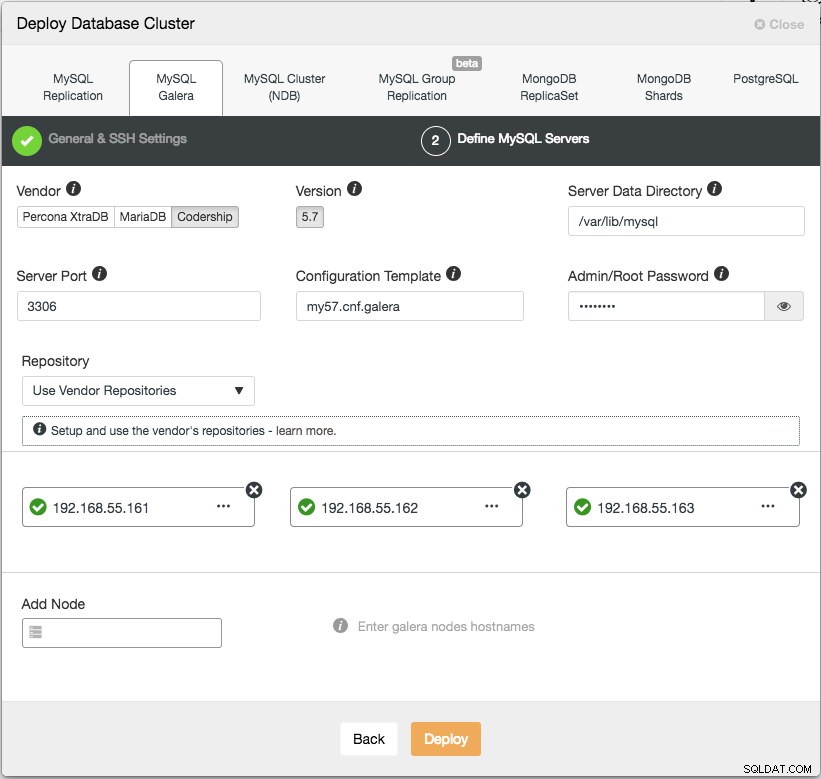
Im nächsten Schritt müssen wir die Datenbankserver konfigurieren – Hersteller, Version, Datadir, Port usw. – die ziemlich selbsterklärend sind. „Configuration Template“ ist der Vorlagendateiname unter /usr/share/cmon/templates des ClusterControl-Knotens. "Repository" ist, wie ClusterControl das Repository auf dem Datenbankknoten konfigurieren sollte. Standardmäßig wird das Anbieter-Repository verwendet und die neueste Version installiert, die vom Repository bereitgestellt wird. In einigen Fällen hat der Benutzer jedoch aufgrund von Sicherheitsrichtlinieneinschränkungen möglicherweise ein bereits vorhandenes Repository, das vom ursprünglichen Repository gespiegelt wurde. Dennoch unterstützt ClusterControl die meisten davon, wie im Benutzerhandbuch unter Repository beschrieben.
Fügen Sie zuletzt die IP-Adresse oder den Hostnamen (muss ein gültiger FQDN sein) der Datenbankknoten hinzu. Auf der linken Seite des Knotens sehen Sie ein grünes Häkchen-Symbol, das anzeigt, dass ClusterControl sich über passwortloses SSH mit dem Knoten verbinden konnte. Sie können jetzt loslegen. Klicken Sie auf Bereitstellen, um die Bereitstellung zu starten. Dies kann 15 bis 20 Minuten dauern. Sie können den Bereitstellungsfortschritt unter Aktivität (oberes Menü) -> Jobs -> Cluster erstellen überwachen :
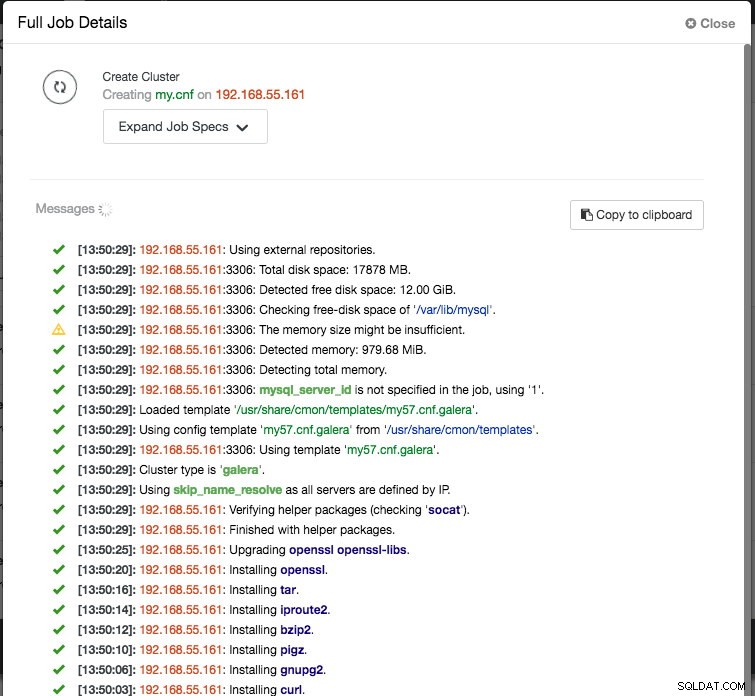
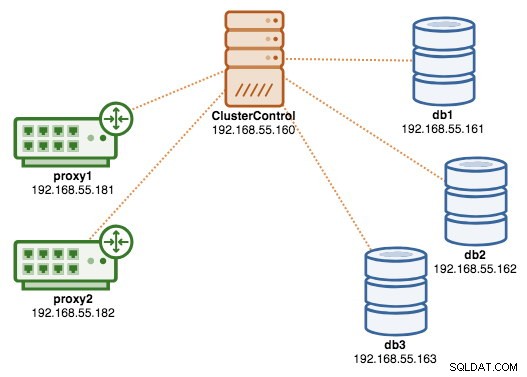
Sobald die Bereitstellung abgeschlossen ist, kann unsere Architektur an dieser Stelle wie folgt dargestellt werden:
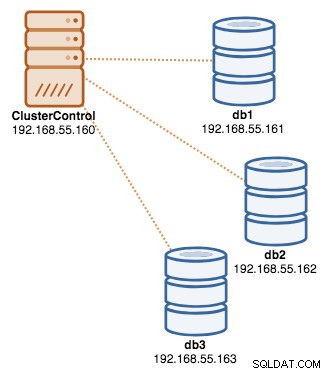
Bereitstellen der Load Balancer
In Galera Cluster sind alle Knoten gleich – jeder Knoten hat die gleiche Rolle und den gleichen Datensatz. Daher gibt es innerhalb des Clusters kein Failover, wenn ein Knoten ausfällt. Nur die Anwendungsseite erfordert ein Failover, um die nicht betriebsbereiten Knoten zu überspringen, während der Cluster partitioniert wird. Daher wird dringend empfohlen, Load Balancer auf einem Galera-Cluster zu platzieren, um:
- Vereinheitlichen Sie die mehreren Datenbank-Endpunkte zu einem einzigen Endpunkt (Load-Balancer-Host oder virtuelle IP-Adresse als Endpunkt).
- Gleichen Sie die Datenbankverbindungen zwischen den Back-End-Datenbankservern aus.
- Führen Sie Zustandsprüfungen durch und leiten Sie die Datenbankverbindungen nur an gesunde Knoten weiter.
- Anstößige (schlecht geschriebene) Abfragen umleiten/umschreiben/blockieren, bevor sie die Datenbankserver erreichen.
Es gibt drei Hauptauswahlen von Reverse-Proxys für Galera Cluster – HAProxy, MariaDB MaxScale oder ProxySQL – alle können automatisch von ClusterControl installiert und konfiguriert werden. In dieser Bereitstellung haben wir ProxySQL ausgewählt, da es alle oben genannten Punkte überprüft und das MySQL-Protokoll der Backend-Server versteht.
In dieser Architektur möchten wir zwei ProxySQL-Server verwenden, um Single-Point-of-Failure (SPOF) auf der Datenbankebene zu eliminieren, die über eine virtuelle Floating-IP-Adresse miteinander verbunden werden. Wir erklären dies im nächsten Abschnitt. Ein Knoten fungiert als aktiver Proxy und der andere als Hot-Standby. Der Knoten, der zu einem bestimmten Zeitpunkt die virtuelle IP-Adresse enthält, ist der aktive Knoten.
Um den ersten ProxySQL-Server bereitzustellen, gehen Sie einfach zum Cluster-Aktionsmenü (rechts neben der Zusammenfassungsleiste) und klicken Sie auf Load Balancer hinzufügen -> ProxySQL -> ProxySQL bereitstellen und Sie werden Folgendes sehen:
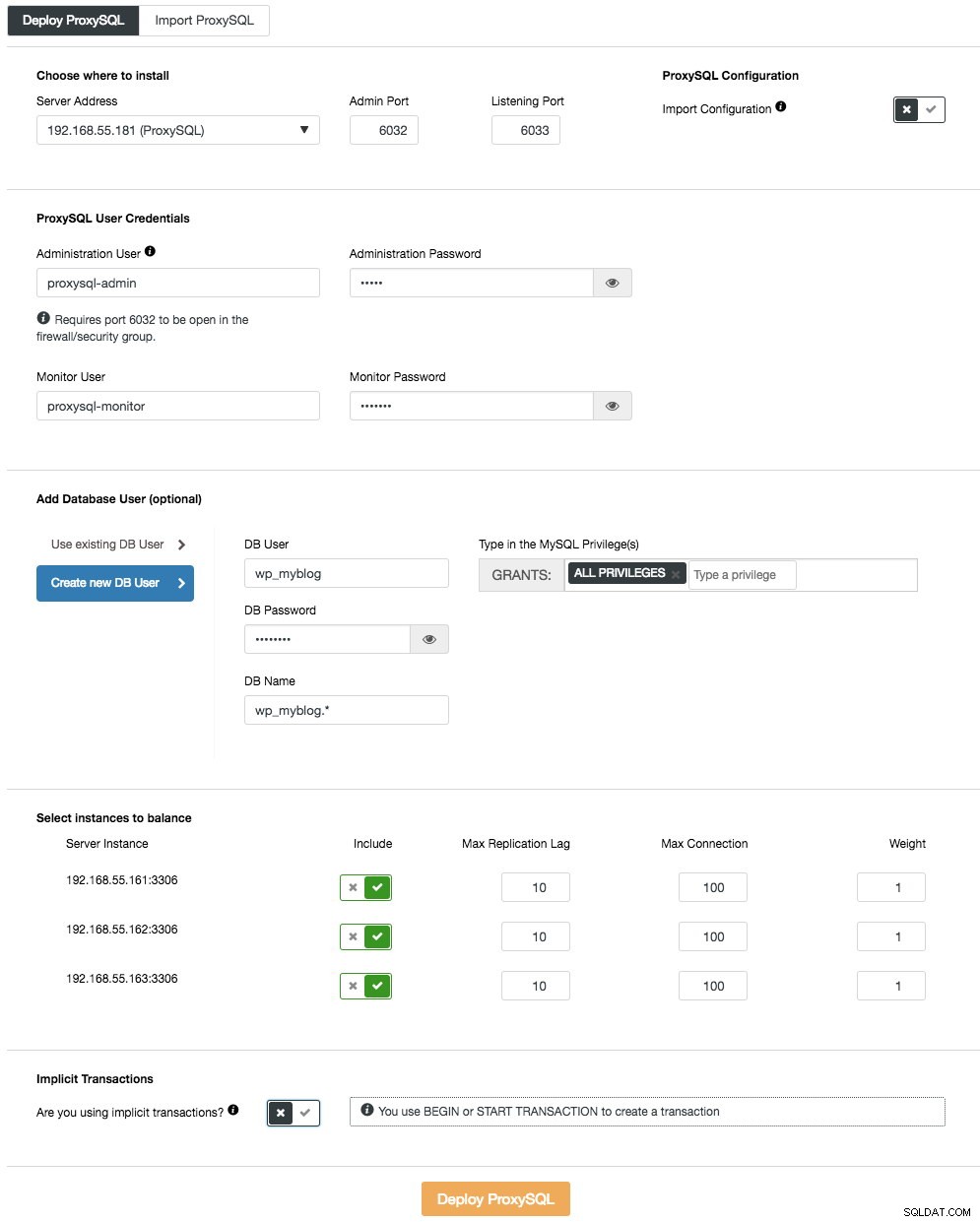
Auch hier sind die meisten Felder selbsterklärend. Im Abschnitt „Datenbankbenutzer“ fungiert ProxySQL als Gateway, über das Ihre Anwendung eine Verbindung zur Datenbank herstellt. Die Anwendung authentifiziert sich bei ProxySQL, daher müssen Sie alle Benutzer von allen Backend-MySQL-Knoten zusammen mit ihren Passwörtern zu ProxySQL hinzufügen. Von ClusterControl aus können Sie entweder einen neuen Benutzer erstellen, der von der Anwendung verwendet werden soll – Sie können über seinen Namen, sein Passwort, den Zugriff auf die Datenbanken und die MySQL-Berechtigungen dieses Benutzers entscheiden. Dieser Benutzer wird sowohl auf MySQL- als auch auf ProxySQL-Seite erstellt. Die zweite Option, die besser für bestehende Infrastrukturen geeignet ist, besteht darin, die vorhandenen Datenbankbenutzer zu verwenden. Sie müssen Benutzername und Passwort übergeben, und ein solcher Benutzer wird nur auf ProxySQL erstellt.
Im letzten Abschnitt, „Implizite Transaktion“, konfiguriert ClusterControl ProxySQL so, dass der gesamte Datenverkehr an den Master gesendet wird, wenn wir die Transaktion mit SET autocommit=0 gestartet haben. Andernfalls, wenn Sie BEGIN oder START TRANSACTION verwenden, um eine Transaktion zu erstellen, konfiguriert ClusterControl die Lese-/Schreibaufteilung in den Abfrageregeln. Damit soll sichergestellt werden, dass ProxySQL Transaktionen korrekt verarbeitet. Wenn Sie nicht wissen, wie Ihre Anwendung dies tut, können Sie letzteres auswählen.
Wiederholen Sie dieselbe Konfiguration für den zweiten ProxySQL-Knoten, mit Ausnahme des Werts „Serveradresse“, der 192.168.55.182 lautet. Sobald dies erledigt ist, werden beide Knoten unter der Registerkarte "Knoten" -> ProxySQL aufgelistet, wo Sie sie direkt von der Benutzeroberfläche aus überwachen und verwalten können:
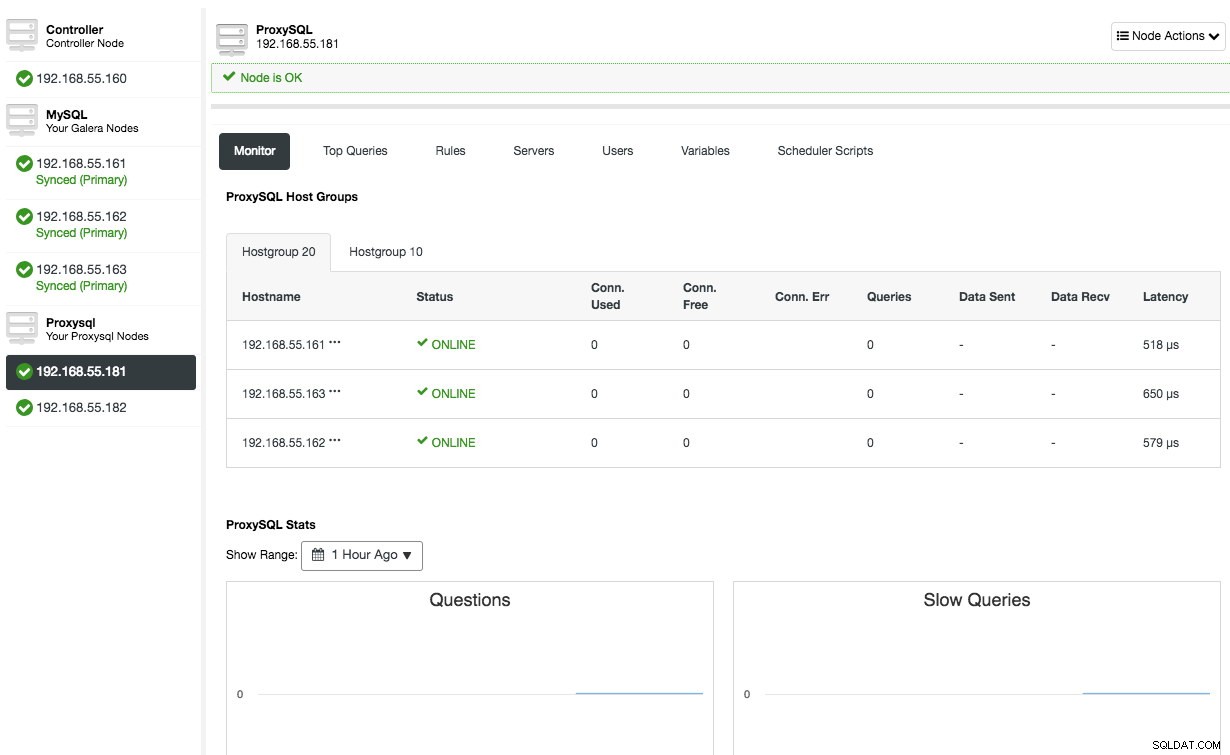
An diesem Punkt sieht unsere Architektur nun so aus:
Wenn Sie mehr über ProxySQL erfahren möchten, sehen Sie sich dieses Tutorial an – Database Load Balancing for MySQL and MariaDB with ProxySQL – Tutorial.
Bereitstellen der virtuellen IP-Adresse
Der letzte Teil ist die virtuelle IP-Adresse. Ohne sie wären unsere Load Balancer (Reverse Proxys) das schwache Glied, da sie ein Single Point of Failure wären – es sei denn, die Anwendung hat die Fähigkeit, fehlgeschlagene Datenbankverbindungen automatisch an einen anderen Load Balancer umzuleiten. Nichtsdestotrotz empfiehlt es sich, beide unter Verwendung einer virtuellen IP-Adresse zu vereinheitlichen und den Verbindungsendpunkt zur Datenbankebene zu vereinfachen.
Von ClusterControl UI -> Load Balancer hinzufügen -> Keepalived -> Keepalived bereitstellen und wählen Sie die beiden bereitgestellten ProxySQL-Hosts aus:
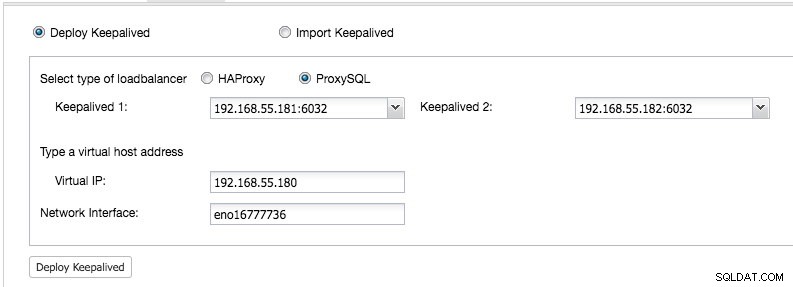
Geben Sie außerdem die virtuelle IP-Adresse und die Netzwerkschnittstelle an, um die IP-Adresse zu binden. Die Netzwerkschnittstelle muss auf beiden ProxySQL-Knoten vorhanden sein. Nach der Bereitstellung sollten Sie die folgenden grünen Häkchen in der Zusammenfassungsleiste des Clusters sehen:

An dieser Stelle kann unsere Architektur wie folgt dargestellt werden:
Unser Datenbank-Cluster ist jetzt bereit für den Produktionseinsatz. Sie können Ihre vorhandene Datenbank darin importieren oder eine neue neue Datenbank erstellen. Sie können die Schema- und Benutzerverwaltungsfunktion verwenden, wenn die Testlizenz noch nicht abgelaufen ist.
Um zu verstehen, wie ClusterControl Keepalived konfiguriert, lesen Sie diesen Blog-Beitrag, How ClusterControl Configures Virtual IP and What to Expect While Failover.
Verbindung zum Datenbank-Cluster herstellen
Aus Sicht der Anwendung und des Clients müssen sie eine Verbindung zu 192.168.55.180 an Port 6033 herstellen, bei der es sich um die virtuelle IP-Adresse handelt, die über den Load Balancern schwebt. Die Konfiguration der Wordpress-Datenbank sieht beispielsweise so aus:
/** The name of the database for WordPress */
define( 'DB_NAME', 'wp_myblog' );
/** MySQL database username */
define( 'DB_USER', 'wp_myblog' );
/** MySQL database password */
define( 'DB_PASSWORD', 'mysecr3t' );
/** MySQL hostname - virtual IP address with ProxySQL load-balanced port*/
define( 'DB_HOST', '192.168.55.180:6033' );Wenn Sie direkt auf den Datenbank-Cluster zugreifen möchten und den Load Balancer umgehen, können Sie sich einfach mit Port 3306 der Datenbank-Hosts verbinden. Dies wird in der Regel von den DBA-Mitarbeitern für Verwaltung, Management und Fehlerbehebung benötigt. Mit ClusterControl können die meisten dieser Operationen direkt von der Benutzeroberfläche aus durchgeführt werden.
Abschließende Gedanken
Wie oben gezeigt, ist die Bereitstellung eines Datenbankclusters keine schwierige Aufgabe mehr. Nach der Bereitstellung gibt es eine vollständige Suite kostenloser Überwachungsfunktionen sowie kommerzielle Funktionen für Backup-Management, Failover/Wiederherstellung und andere. Die schnelle Bereitstellung verschiedener Arten von Cluster-/Replikationstopologien kann bei der Bewertung von Hochverfügbarkeits-Datenbanklösungen und ihrer Anpassung an Ihre spezielle Umgebung hilfreich sein.