Seit der Veröffentlichung von ClusterControl 1.2.11 im Jahr 2015 wird MariaDB MaxScale als Datenbank-Load-Balancer unterstützt. Im Laufe der Jahre ist MaxScale gewachsen und gereift und hat mehrere reichhaltige Funktionen hinzugefügt. Kürzlich wurde MariaDB MaxScale 2.2 veröffentlicht und führt mehrere neue Funktionen ein, darunter die Failover-Verwaltung für Replikationscluster.
MariaDB MaxScale ermöglicht Master/Slave-Bereitstellungen mit hoher Verfügbarkeit, automatischem Failover, manuellem Switchover und automatischem Wiederbeitreten. Wenn der Master ausfällt, kann MariaDB MaxScale automatisch den aktuellsten Slave zum Master hochstufen. Wenn der ausgefallene Master wiederhergestellt wird, kann MariaDB MaxScale ihn automatisch als Slave für den neuen Master neu konfigurieren. Darüber hinaus können Administratoren eine manuelle Umschaltung durchführen, um den Master bei Bedarf zu ändern.
In unseren vorherigen Blogs haben wir die Bereitstellung von MaxScale mit ClusterControl sowie die Bereitstellung von MariaDB MaxScale auf Docker besprochen. Für diejenigen, die mit MariaDB MaxScale noch nicht vertraut sind, es ist ein erweiterter Plug-in-Datenbank-Proxy für MariaDB-Datenbankserver. Maxscale befindet sich zwischen Client-Anwendungen und den Datenbankservern und leitet Client-Anfragen und Server-Antworten weiter. Es überwacht auch die Server und bemerkt schnell alle Änderungen im Serverstatus oder in der Replikationstopologie.
Obwohl Maxscale einige der Eigenschaften anderer Load-Balancing-Technologien wie ProxySQL teilt, sticht diese neue Failover-Funktion (die Teil des Überwachungs- und automatischen Erkennungsmechanismus ist) hervor. In diesem Blog werden wir diese aufregende neue Funktion von Maxscale besprechen.
Überblick über den MariaDB MaxScale-Failover-Mechanismus
Meistererkennung
Es ist nun unwahrscheinlicher, dass der Monitor plötzlich den Master-Server wechselt, selbst wenn ein anderer Server mehr Slaves als der aktuelle Master hat. Der DBA kann eine Master-Neuauswahl erzwingen, indem er den aktuellen Master auf Nur-Lesen setzt oder indem er alle seine Slaves entfernt, wenn der Master ausgefallen ist.
Es kann immer nur ein Server das Master-Status-Flag haben, selbst in einem Multimaster-Setup. Andere Server in der Multimaster-Gruppe erhalten die Status-Flags Relay Master und Slave.
Wechsel auf die automatische Auswahl des neuen Masters
Der Switchover-Befehl kann jetzt nur noch mit dem Namen der Monitorinstanz als Parameter aufgerufen werden. In diesem Fall wählt der Monitor automatisch einen Server für die Heraufstufung aus.
Erkennung von Replikationsverzögerungen
Die Replikationsverzögerungsmessung liest jetzt einfach den Seconds_Behind_Master -Feld der Slave-Statusausgabe von Slaves. Der Slave berechnet diesen Wert, indem er den Zeitstempel im Binlog-Ereignis, das der Slave gerade verarbeitet, mit der eigenen Uhr des Slaves vergleicht. Wenn ein Slave mehrere Slave-Verbindungen hat, wird die kleinste Verzögerung verwendet.
Automatische Umschaltung nach Erkennung von geringem Speicherplatz
Mit den neueren Versionen von MariaDB Server kann der Monitor jetzt den Speicherplatz auf dem Backend überprüfen und feststellen, ob der Server knapp wird. In diesem Fall kann der Monitor so eingestellt werden, dass er automatisch von einem Master mit wenig Speicherplatz umschaltet. Slaves können auch in den Wartungsmodus versetzt werden. Der Speicherplatz ist auch ein Faktor, der bei der Auswahl des neuen Masters berücksichtigt wird, der hochgestuft werden soll.
Weitere Informationen finden Sie unter switchover_on_low_disk_space und maintenance_on_low_disk_space.
Funktion zum Zurücksetzen der Replikation
Die Reset-Replikation monitor löscht alle Slave-Verbindungen und Binärprotokolle und richtet dann die Replikation ein. Nützlich, wenn Daten synchronisiert sind, Gtids jedoch nicht.
Geplante Ereignisbehandlung bei Failover/Switchover/Rejoin
Vom Event-Scheduler-Thread gestartete Serverereignisse werden jetzt während Cluster-Änderungsvorgängen behandelt. Weitere Informationen finden Sie unter handle_server_events.
Externer Master-Support
Der Monitor kann erkennen, ob ein Server im Cluster von einem externen Master repliziert (einem Server, der nicht vom MaxScale-Monitor überwacht wird). Wenn der replizierende Server der Cluster-Master-Server ist, wird der Cluster selbst als externer Master betrachtet.
Wenn ein Failover/Switchover stattfindet, wird der neue Masterserver so eingestellt, dass er vom externen Masterserver des Clusters repliziert. Der Benutzername und das Passwort für die Replikation werden in replication_user und replication_password definiert. Die verwendete Adresse und der verwendete Port sind diejenigen, die von SHOW ALL SLAVES STATUS auf dem alten Cluster-Master-Server angezeigt werden. Im Falle einer Umschaltung stoppt auch der alte Master die Replikation vom externen Server, um die Topologie beizubehalten.
Nach dem Failover repliziert der neue Master vom externen Master. Wenn der ausgefallene alte Master wieder online geht, repliziert er ebenfalls vom externen Server. Um die Situation zu normalisieren, aktivieren Sie entweder auto_rejoin oder führen Sie manuell einen Rejoin durch. Dadurch wird der alte Master auf den aktuellen Cluster-Master umgeleitet.
Wie nützlich und anwendbar ist Failover?
Failover hilft Ihnen, Ausfallzeiten zu minimieren, tägliche Wartungsarbeiten durchzuführen oder katastrophale und unerwünschte Wartungsarbeiten zu bewältigen, die manchmal zu unglücklichen Zeiten auftreten können. Mit der Fähigkeit von MaxScale, Clientanwendungen von Back-End-Datenbankservern zu isolieren, werden wertvolle Funktionen hinzugefügt, die dazu beitragen, Ausfallzeiten zu minimieren.
Das MaxScale-Überwachungs-Plugin überwacht kontinuierlich den Status von Backend-Datenbankservern. Das Routing-Plugin von MaxScale verwendet dann diese Statusinformationen, um Abfragen immer an Backend-Datenbankserver weiterzuleiten, die in Betrieb sind. Es ist dann in der Lage, Abfragen an die Backend-Datenbank-Cluster zu senden, selbst wenn einige der Server eines Clusters gewartet werden oder ausfallen.
Die hohe Konfigurierbarkeit von MaxScale ermöglicht, dass Änderungen in der Clusterkonfiguration für Clientanwendungen transparent bleiben. Wenn beispielsweise ein neuer Server administrativ zu einem Master-Slave-Cluster hinzugefügt oder daraus entfernt werden muss, können Sie die MaxScale-Konfiguration einfach über die maxadmin-CLI-Konsole zur Serverliste der Monitor- und Router-Plug-ins hinzufügen. Die Client-Anwendung bemerkt diese Änderung überhaupt nicht und sendet weiterhin Datenbankabfragen an den Überwachungsport von MaxScale.
Das Einstellen eines Datenbankservers in die Wartung ist einfach und unkompliziert. Führen Sie einfach den folgenden Befehl mit maxctrl aus und MaxScale hört auf, Anfragen an diesen Server zu senden. Zum Beispiel
maxctrl: set server DB_785 maintenance
OKÜberprüfen Sie dann den Serverstatus wie folgt,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Im Wartungsmodus stoppt MaxScale die Weiterleitung neuer Anfragen an den Server. Bei aktuellen Anfragen beendet MaxScale diese Sitzungen nicht, sondern lässt zu, dass sie ihre Ausführung abschließen, und unterbricht im Wartungsmodus keine laufenden Abfragen. Beachten Sie auch, dass der Wartungsmodus nicht dauerhaft ist. Wenn MaxScale neu gestartet wird, während sich ein Knoten im Wartungsmodus befindet, wird eine neue Instanz von MariaDB MaxScale diesen Modus nicht berücksichtigen. Wenn mehrere MariaDB MaxScale-Instanzen für die Verwendung des Knotens konfiguriert sind, muss der Wartungsmodus in jeder MariaDB MaxScale-Instanz festgelegt werden. Wenn jedoch mehrere Dienste innerhalb einer MariaDB MaxScale-Instanz den Server verwenden, müssen Sie den Wartungsmodus nur einmal auf dem Server festlegen, damit alle Dienste die Modusänderung zur Kenntnis nehmen.
Wenn Sie mit Ihrer Wartung fertig sind, löschen Sie einfach den Server mit dem folgenden Befehl. Zum Beispiel
maxctrl: clear server DB_785 maintenance
OKUm zu überprüfen, ob es wieder normal ist, führen Sie einfach den Befehl Server auflisten aus .
Sie können auch bestimmte Verwaltungsaktionen über die ClusterControl-Benutzeroberfläche anwenden. Siehe Beispiel-Screenshot unten:
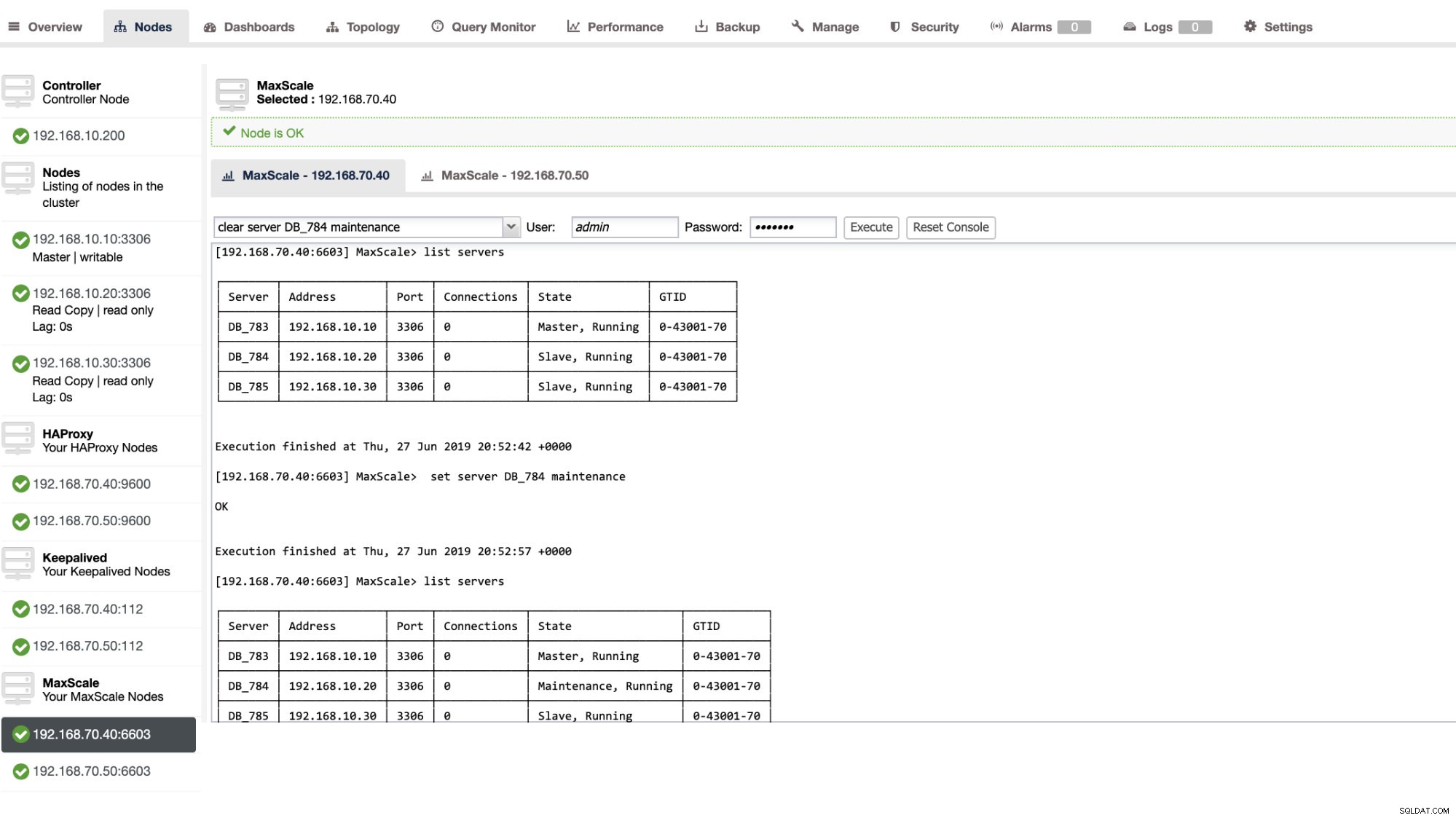
MaxScale-Failover aktiv
Das automatische Failover
Das MaxScale-Failover von MariaDB arbeitet sehr effizient und konfiguriert den Slave wie erwartet entsprechend neu. In diesem Test haben wir den folgenden Konfigurationsdateisatz, der von ClusterControl erstellt und verwaltet wurde. Siehe unten:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonBeachten Sie, dass nur auto_failover und auto_rejoin sind die Variablen, die ich hinzugefügt habe, da ClusterControl diese standardmäßig nicht hinzufügt, sobald Sie einen MaxScale-Load-Balancer eingerichtet haben (sehen Sie sich diesen Blog an, um zu erfahren, wie Sie MaxScale mit ClusterControl einrichten). Vergessen Sie nicht, dass Sie MariaDB MaxScale neu starten müssen, sobald Sie die Änderungen in Ihrer Konfigurationsdatei übernommen haben. Lauf einfach,
systemctl restart maxscaleund schon kann es losgehen.
Bevor wir mit dem Failover-Test fortfahren, prüfen wir zuerst den Zustand des Clusters:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Sieht toll aus!
Ich habe den Master einfach mit dem reinen Killerbefehl KILL -9 $(pidof mysqld) in meinem Master-Knoten beendet und sehe, dass der Monitor dies nicht überraschend schnell bemerkt hat und das Failover auslöst. Sehen Sie sich die Protokolle wie folgt an:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Sehen wir uns nun den Zustand des Clusters an,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Der Knoten 192.168.10.10, der zuvor der Master war, war ausgefallen. Ich habe versucht, neu zu starten und zu sehen, ob die automatische Wiederverbindung ausgelöst wird, und wie Sie im Protokoll um 2019-06-28 06:39:20.165, bemerkt haben Es war so schnell, den Zustand des Knotens zu erfassen und dann die Konfiguration automatisch einzurichten, ohne dass der DBA sie umständlich einschalten musste.
Jetzt, als ich endlich seinen Zustand überprüft habe, sieht es so aus, als würde es wie erwartet perfekt funktionieren. Siehe unten:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Mein Ex-Meister wurde repariert und wiederhergestellt und ich möchte umsteigen
Der Wechsel zu Ihrem vorherigen Master ist ebenfalls kein Problem. Sie können dies mit maxctrl (oder maxadmin in früheren Versionen von MaxScale) oder über die ClusterControl-Benutzeroberfläche (wie zuvor gezeigt) ausführen.
Lassen Sie uns einfach auf den vorherigen Zustand des Zustands des Replikationsclusters verweisen und wollten 192.168.10.10 (derzeit Slave) zurück in seinen Master-Zustand schalten. Bevor wir fortfahren, müssen Sie möglicherweise zuerst den Monitor identifizieren, den Sie verwenden werden. Sie können dies mit dem folgenden Befehl unten überprüfen:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘Sobald Sie es haben, können Sie den folgenden Befehl ausführen, um umzuschalten:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKÜberprüfen Sie dann erneut den Status des Clusters,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Sieht perfekt aus!
Protokolle zeigen Ihnen ausführlich, wie es gelaufen ist und welche Aktionsreihen während der Umstellung durchgeführt wurden. Siehe die Details unten:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]Im Falle einer falschen Umschaltung wird es nicht fortgesetzt und daher wird ein Fehler generiert, wie im obigen Protokoll gezeigt. So sind Sie auf der sicheren Seite und es gibt überhaupt keine gruseligen Überraschungen.
Machen Sie Ihre MaxScale hochverfügbar
Während es in Bezug auf Failover ein wenig vom Thema abweicht, wollte ich hier einige wertvolle Punkte in Bezug auf Hochverfügbarkeit und ihre Beziehung zu MariaDB MaxScale-Failover hinzufügen.
Ihre MaxScale hochverfügbar zu machen, ist ein wichtiger Teil für den Fall, dass Ihr System abstürzt, eine Beschädigung der Festplatte oder eine Beschädigung der virtuellen Maschine auftritt. Diese Situationen sind unvermeidlich und können den Status Ihrer automatisierten Failover-Einrichtung beeinträchtigen, wenn diese unerwarteten Wartungszyklen auftreten.
Für eine Umgebung vom Typ Replikations-Cluster ist dies sehr vorteilhaft und wird für ein bestimmtes MaxScale-Setup dringend empfohlen. Der Zweck davon ist, dass es immer nur einer MaxScale-Instanz erlaubt sein sollte, den Cluster zu einem bestimmten Zeitpunkt zu ändern. Wenn Sie mit Keepalived eingerichtet haben, befinden sich hier die Instanzen mit dem Status MASTER. MaxScale selbst kennt seinen Zustand nicht, aber mit maxctrl (oder maxadmin in früheren Versionen) kann eine MaxScale-Instanz in den passiven Modus versetzen. Ab Version 2.2.2 verhält sich ein passives MaxScale ähnlich wie ein aktives mit dem Unterschied, dass es kein Failover, Switchover oder Rejoin durchführt. Selbst manuelle Versionen dieser Befehle enden mit einem Fehler. Die Unterschiede im passiven/aktiven Modus können in Zukunft erweitert werden, bleiben Sie also auf dem Laufenden über solche Änderungen in MaxScale. Gehen Sie dazu einfach wie folgt vor:
maxctrl: alter maxscale passive true
OKSie können dies später überprüfen, indem Sie den folgenden Befehl ausführen:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Wenn Sie herausfinden möchten, wie Sie mit Keepalived eine hohe Verfügbarkeit einrichten, lesen Sie bitte diesen Beitrag von MariaDB.
VIP-Behandlung
Da MaxScale selbst keine VIP-Verwaltung integriert hat, können Sie Keepalived verwenden, um dies für Sie zu erledigen. Sie können einfach die virtual_ipaddress verwenden, die dem MASTER-Zustandsknoten zugewiesen ist. Dies wird wahrscheinlich mit virtuellem IP-Management erfolgen, genau wie MHA dies mit der master_failover_script-Variablen tut. Sehen Sie sich, wie bereits erwähnt, diesen Blogpost von MariaDB zum Setup von Keepalived mit MaxScale an.
Schlussfolgerung
MariaDB MaxScale ist reich an Funktionen und hat viele Fähigkeiten, die nicht nur darauf beschränkt sind, ein Proxy und Load Balancer zu sein, sondern es bietet auch den Failover-Mechanismus, nach dem große Organisationen suchen. Es ist fast eine Software für alle Fälle, hat aber natürlich Einschränkungen, die eine bestimmte Anwendung im Gegensatz zu anderen Load-Balancern wie ProxySQL benötigen könnte.
ClusterControl bietet auch einen automatischen Failover- und Master-Erkennungsmechanismus sowie Cluster- und Knotenwiederherstellung mit der Möglichkeit, Maxscale und andere Lastausgleichstechnologien einzusetzen.
Jedes dieser Tools hat seine unterschiedlichen Merkmale und Funktionen, aber MariaDB MaxScale wird innerhalb von ClusterControl gut unterstützt und kann problemlos zusammen mit Keepalived und HAProxy bereitgestellt werden, um Ihnen zu helfen, Ihre täglichen Routineaufgaben zu beschleunigen.