Presto ist eine parallel verteilte Open-Source-SQL-Engine für die Big-Data-Verarbeitung. Es wurde von Grund auf von Facebook entwickelt. Die erste interne Veröffentlichung fand 2013 statt und war eine ziemlich revolutionäre Lösung für ihre Big-Data-Probleme.
Angesichts der Hunderte von geolokalisierten Servern und Petabytes an Daten begann Facebook, nach einer alternativen Plattform für seine Hadoop-Cluster zu suchen. Ihr Infrastrukturteam wollte die Zeit reduzieren, die zum Ausführen von Analyse-Batch-Jobs benötigt wird, und die Pipeline-Entwicklung vereinfachen, indem es eine in der Organisation weithin bekannte Programmiersprache – SQL – verwendete.
Laut der Presto-Stiftung „verwendet Facebook Presto für interaktive Abfragen gegen mehrere interne Datenspeicher, einschließlich ihres 300-PB-Data-Warehouse. Über 1.000 Facebook-Mitarbeiter verwenden Presto täglich, um mehr als 30.000 Abfragen auszuführen, die insgesamt mehr als ein Petabyte pro Tag scannen.“
Während Facebook über eine außergewöhnliche Data-Warehouse-Umgebung verfügt, gibt es die gleichen Herausforderungen in vielen Organisationen, die mit Big Data zu tun haben.
In diesem Blog werfen wir einen Blick darauf, wie Sie eine grundlegende Presto-Umgebung mit einem Docker-Server aus der tar-Datei einrichten. Als Datenquelle konzentrieren wir uns auf die MySQL-Datenquelle, aber es könnte auch jedes andere gängige RDBMS sein.
Ausführen von Presto in einer Big-Data-Umgebung
Bevor wir beginnen, werfen wir einen kurzen Blick auf die wichtigsten Architekturprinzipien. Presto ist eine Alternative zu Tools, die HDFS mithilfe von Pipelines von MapReduce-Jobs wie Hive abfragen. Im Gegensatz zu Hive verwendet Presto kein MapReduce. Presto wird mit einer speziellen Abfrageausführungs-Engine mit High-Level-Operatoren und In-Memory-Verarbeitung ausgeführt.
Im Gegensatz zu Hive kann Presto Daten durch alle Stufen auf einmal streamen, wobei Datenblöcke gleichzeitig ausgeführt werden. Es wurde entwickelt, um analytische Ad-hoc-Abfragen gegen einzelne oder verteilte heterogene Datenquellen auszuführen. Es kann von einer Hadoop-Plattform aus erreichen, um relationale Datenbanken oder andere Datenspeicher wie Flatfiles abzufragen.
Presto verwendet Standard-ANSI-SQL, einschließlich Aggregationen, Verknüpfungen oder Analysefensterfunktionen. SQL ist allgemein bekannt und viel einfacher zu verwenden als MapReduce, das in Java geschrieben wurde.
Bereitstellen von Presto in Docker
Die grundlegende Presto-Konfiguration kann mit einem vorkonfigurierten Docker-Image oder Presto-Server-Tarball bereitgestellt werden.
Der Docker-Server und die Presto-CLI-Container können einfach bereitgestellt werden mit:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliSie können zwischen zwei Versionen des Presto-Servers wählen. Community-Version und Enterprise-Version von Starburst. Da wir es in einer Nicht-Produktions-Sandbox-Umgebung ausführen werden, verwenden wir in diesem Artikel die Apache-Version.
Voraussetzungen
Presto ist vollständig in Java implementiert und erfordert die Installation von JVM auf Ihrem System. Es läuft sowohl auf OpenJDK als auch auf Oracle Java. Die Mindestversion ist Java 8u151 oder Java 11.
Um JAVA JDK herunterzuladen, besuchen Sie https://openjdk.java.net/ oder https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Sie können Ihre Java-Version mit
überprüfen$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Presto-Installation
Um Presto zu installieren, laden wir Server tar und Presto CLI jar ausführbar herunter.
Der Tarball enthält ein einzelnes Verzeichnis der obersten Ebene, presto-server-0.223, das wir das Installationsverzeichnis nennen werden.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoAußerdem benötigt Presto ein Datenverzeichnis zum Speichern von Protokollen usw.
Es wird empfohlen, ein Datenverzeichnis außerhalb des Installationsverzeichnisses zu erstellen.
$ mkdir -p ~/data/presto/An diesem Ort beginnen wir mit der Fehlerbehebung.
Konfigurieren von Presto
Bevor wir unsere erste Instanz starten, müssen wir eine Reihe von Konfigurationsdateien erstellen. Beginnen Sie mit der Erstellung eines etc/-Verzeichnisses innerhalb des Installationsverzeichnisses. Dieser Speicherort enthält die folgenden Konfigurationsdateien:
etc/
- Knoteneigenschaften - Umgebungskonfiguration des Knotens
- JVM-Konfiguration (jvm.config) - Java Virtual Machine-Konfiguration
- Config Properties(config.properties) -Konfiguration für den Presto-Server
- Katalogeigenschaften - Konfiguration für Konnektoren (Datenquellen)
- Protokolleigenschaften – Loggerkonfiguration
Nachfolgend finden Sie einige grundlegende Konfigurationen zum Ausführen der Presto-Sandbox. Weitere Einzelheiten finden Sie in der Dokumentation.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoDie grundlegende Struktur von etc/ kann wie folgt aussehen:

Der nächste Schritt besteht darin, den MySQL-Connector einzurichten.
Wir werden eine Verbindung zu einem der 3 Knoten des MariaDB-Clusters herstellen.
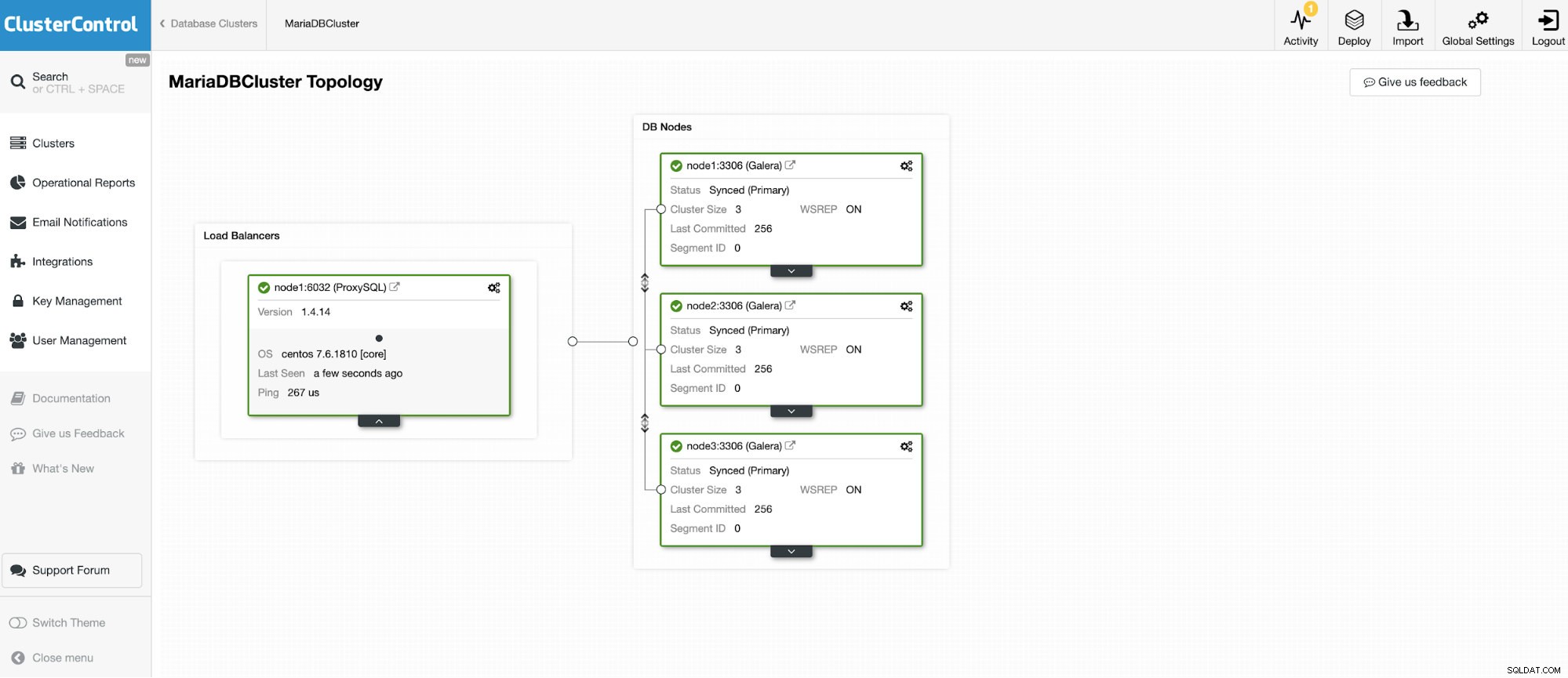
Und eine weitere eigenständige Instanz, auf der Oracle MySQL 5.7 ausgeführt wird.
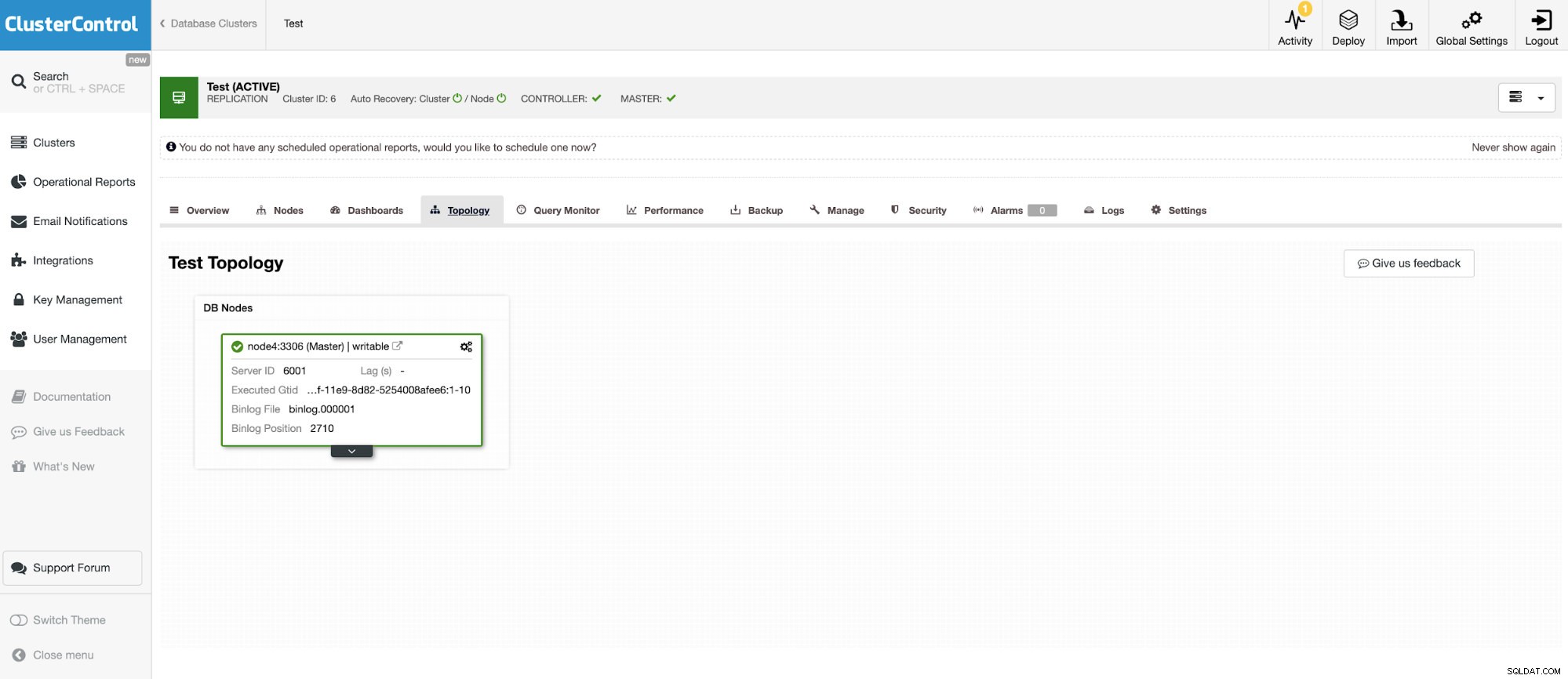
Der MySQL-Connector ermöglicht das Abfragen und Erstellen von Tabellen in einer externen MySQL-Datenbank. Dies kann verwendet werden, um Daten zwischen verschiedenen Systemen wie MariaDB und MySQL von Oracle zusammenzuführen.
Presto verwendet steckbare Anschlüsse und die Konfiguration ist sehr einfach. Um den MySQL-Connector zu konfigurieren, erstellen Sie eine Katalogeigenschaftendatei in etc/catalog mit dem Namen beispielsweise mysql.properties, um den MySQL-Connector als mysql-Katalog einzuhängen. Jede der Dateien stellt eine Verbindung zu einem anderen Server dar. In diesem Fall haben wir zwei Dateien:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretPresto ausführen
Wenn alles eingestellt ist, ist es an der Zeit, die Presto-Instanz zu starten. Um Presto zu starten, gehen Sie unter Preso-Installation in das bin-Verzeichnis und führen Sie Folgendes aus:
$ bin/launcher start
Started as 18363So stoppen Sie die Ausführung von Presto
$ bin/launcher stopWenn der Server jetzt läuft, können wir uns mit der CLI mit Presto verbinden und die MySQL-Datenbank abfragen.
So starten Sie die Presto-Konsolenausführung:
./presto --server localhost:8080 --catalog mysql --schema employeesJetzt können wir unsere Datenbanken per CLI abfragen.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Beide Datenbanken, MariaDB-Cluster und MySQL, wurden mit der Mitarbeiterdatenbank gefüttert.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlDer Status der Abfrage ist auch in der Presto-Webkonsole sichtbar:https://localhost:8080/ui/#
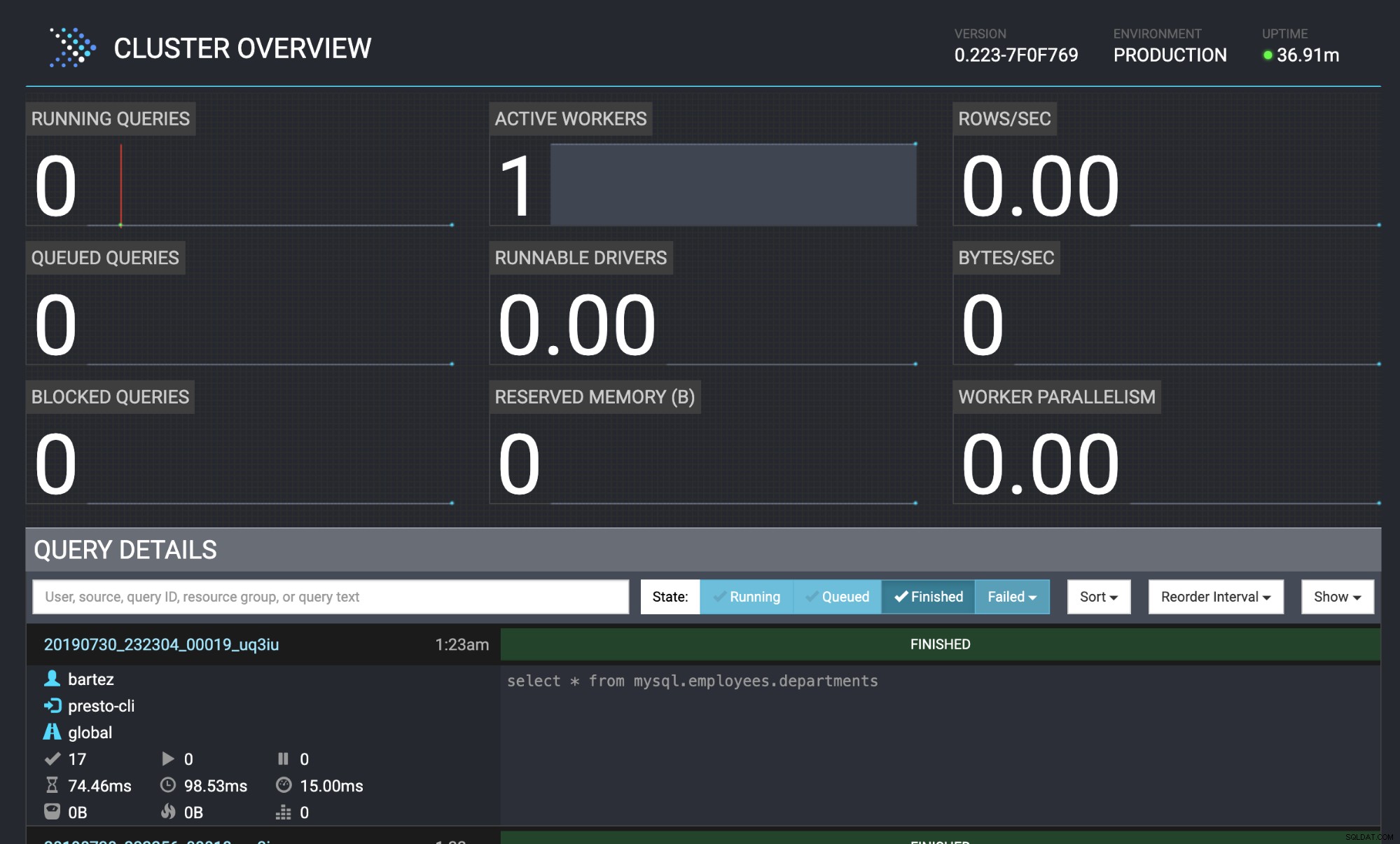 Presto-Cluster-Übersicht
Presto-Cluster-Übersicht Schlussfolgerung
Viele bekannte Unternehmen (wie Airbnb, Netflix, Twitter) setzen Presto für eine Leistung mit geringer Latenz ein. Es handelt sich zweifellos um eine sehr interessante Software, die die Ausführung umfangreicher ETL-Data-Warehouse-Prozesse überflüssig machen kann. In diesem Blog haben wir nur einen kurzen Blick auf den MySQL-Connector geworfen, aber Sie können ihn verwenden, um Daten aus HDFS, Objektspeichern, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB und vielen anderen zu analysieren.