Hash-Indizes sind ein wesentlicher Bestandteil von Datenbanken. Wenn Sie jemals eine Datenbank verwendet haben, haben Sie sie wahrscheinlich in Aktion gesehen, ohne es überhaupt zu merken.
Hash-Indizes unterscheiden sich in ihrer Arbeit von anderen Arten von Indizes, da sie eher Werte als Zeiger auf Datensätze speichern, die sich auf einer Festplatte befinden. Dies gewährleistet ein schnelleres Suchen und Einfügen in den Index. Aus diesem Grund werden Hash-Indizes häufig als Primärschlüssel oder eindeutige Identifikatoren verwendet.
Hash-Indizes verstehen
Ein Hash-Index ist ein Indextyp, der am häufigsten in der Datenverwaltung verwendet wird. Es wird normalerweise für eine Spalte erstellt, die eindeutige Werte enthält, z. B. einen Primärschlüssel oder eine E-Mail-Adresse. Der Hauptvorteil der Verwendung von Hash-Indizes ist ihre schnelle Leistung.
Das Konzept hinter diesen Indizes kann für jemanden, der noch nie zuvor von ihnen gehört hat, kompliziert zu verstehen sein. Das Verständnis von Hash-Indizes ist jedoch wichtig, wenn Sie verstehen müssen, wie Datenbanken funktionieren. Es ist notwendig, um allgemeine Probleme im Zusammenhang mit Datenbanken und ihrer Geschwindigkeit zu lösen.
Die gute Nachricht ist, dass Sie mit ein wenig Geduld und ausgeschaltetem Mobiltelefon Hash-Indizes sicher meistern können! Schauen wir uns das also genauer an.
Schnell und einfach
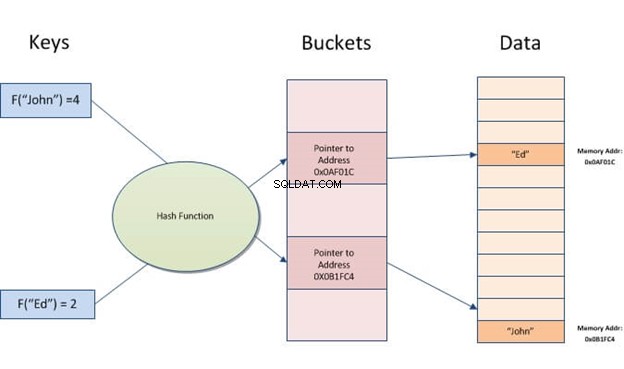
Ein Hash-Index ist eine Datenstruktur, die zur Beschleunigung von Datenbankabfragen verwendet werden kann. Es funktioniert durch Konvertieren von Eingabedatensätzen in ein Array von Buckets. Jeder Bucket hat dieselbe Anzahl an Datensätzen wie alle anderen Buckets in der Tabelle. Unabhängig davon, wie viele verschiedene Werte Sie für eine bestimmte Spalte haben, wird jede Zeile immer einem Bucket zugeordnet.
Hash-Indizes ermöglichen eine schnelle Suche nach Daten, die in Tabellen gespeichert sind. Sie arbeiten, indem sie aus dem Wert einen Indexschlüssel erstellen und ihn dann basierend auf dem resultierenden Hash lokalisieren. Es ist nützlich, wenn es viele Eingaben mit ähnlichen Werten oder Duplikaten gibt, da es nur Schlüssel vergleichen muss, anstatt alle Datensätze zu durchsuchen.
War das weder schnell noch einfach? Um zu verstehen, wie Hash-Indizes funktionieren und warum sie so leistungsfähig sind, müssen Sie verstehen, was mit Hashing gemeint ist.
Hashing nimmt eine Information (eine Zeichenkette) und wandelt sie in eine Adresse oder einen Zeiger für den späteren schnellen Zugriff um.
Die Idee beim Hashing ist, dass den Daten eine kleine Zahl zugewiesen wird. Wenn Sie die Daten nachschlagen, müssen Sie nicht wirklich Massen durchforsten. Schlagen Sie stattdessen einfach diese eine Zahl nach. Das einfachste Beispiel ist Strg+F-ing des gesuchten Wortes in einem Text, anstatt Dutzende von Seiten selbst zu lesen.
Wozu dienen Hash-Indizes?
Ein Hash-Index ist eine Möglichkeit, den Suchprozess zu beschleunigen. Bei herkömmlichen Indizes müssen Sie jede Zeile durchsuchen, um sicherzustellen, dass Ihre Abfrage erfolgreich ist. Aber bei Hash-Indizes ist das nicht der Fall!
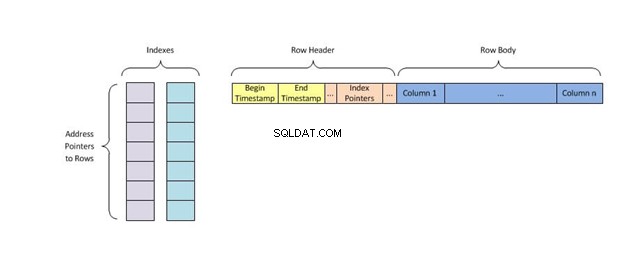
Jeder Schlüssel des Index enthält nur eine Zeile der Tabellendaten und verwendet den Indizierungsalgorithmus namens Hashing Dadurch wird ihnen ein eindeutiger Speicherort zugewiesen, wodurch alle anderen Schlüssel mit doppelten Werten eliminiert werden, bevor das Gesuchte gefunden wird.
Hash-Indizes sind eine von vielen Möglichkeiten, Daten in einer Datenbank zu organisieren. Sie arbeiten, indem sie Eingaben entgegennehmen und als Schlüssel zum Speichern auf einer Festplatte verwenden. Diese Schlüssel oder Hash-Werte , kann alles sein, von Zeichenfolgenlängen bis hin zu Zeichen in der Eingabe.
Hash-Indizes werden am häufigsten verwendet, wenn bestimmte Eingaben mit bestimmten Attributen abgefragt werden. Beispielsweise kann es alle A-Buchstaben finden, die höher als 10 cm sind. Sie können dies schnell tun, indem Sie eine Hash-Index-Funktion erstellen.
Hash-Indizes sind ein Teil des PostgreSQL-Datenbanksystems. Dieses System wurde entwickelt, um Geschwindigkeit und Leistung zu steigern. Hash-Indizes können in Verbindung mit anderen Indextypen wie B-Tree oder GiST verwendet werden.
Ein Hash-Index speichert Schlüssel, indem er sie in kleinere Blöcke unterteilt, die Buckets genannt werden, wobei jedem Bucket eine ganzzahlige ID-Nummer zugewiesen wird, um sie schnell abzurufen, wenn nach der Position eines Schlüssels in der Hash-Tabelle gesucht wird. Die Buckets werden sequentiell auf einem Datenträger gespeichert, sodass auf die darin enthaltenen Daten schnell zugegriffen werden kann.
Weitere technische Erläuterungen finden Sie auf dieser Seite (klicken Sie mit der rechten Maustaste und wählen Sie „Ins Englische übersetzen“).
Vorteile
Der Hauptvorteil der Verwendung von Hash-Indizes besteht darin, dass sie einen schnellen Zugriff ermöglichen, wenn der Datensatz anhand des Schlüsselwerts abgerufen wird. Es ist oft nützlich für Abfragen mit einer Gleichheitsbedingung. Außerdem erfordert die Verwendung von Hash-Benchmarks nicht viel Speicherplatz. Somit ist es ein effektives Werkzeug, aber nicht ohne Nachteile.
Nachteile
Hash-Indizes sind eine relativ neue Indizierungsstruktur mit dem Potenzial, erhebliche Leistungsvorteile zu bieten. Sie können sie sich als eine Erweiterung binärer Suchbäume (BSTs) vorstellen.
Hash-Indizes funktionieren, indem sie Daten basierend auf ihren Hash-Werten in Buckets speichern, was ein schnelles und effizientes Abrufen der Daten ermöglicht. Sie sind garantiert in Ordnung.
Es ist jedoch nicht möglich, doppelte Schlüssel in einem Bucket zu speichern. Daher wird es immer einen Overhead geben. Aber bisher überwiegen die Vorteile der Verwendung von Hash-Indizes die Nachteile.
Wie funktioniert das alles in etwas mehr Tiefe?
Nehmen wir eine Demo aviasales Datenbank, um ein tieferes Verständnis der Funktionsweise von Hash-Indizes zu erhalten.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Hier können Sie sehen, wie wir Hash-Indizes implementieren, indem wir Daten in Sets zusammenstellen.
Dies ist ein einfaches Beispiel, aber beachten Sie, dass Einschränkungen mit weniger Codeinfrastruktur einhergehen. Es kann einen Mangel an WAL-Log-Zugriff oder eine Unfähigkeit geben, Indizes (Indizes?) nach einem Absturz wiederherzustellen. Außerdem nehmen Indizes möglicherweise nicht an der Replikation teil, da PostgreSQL veraltet ist. Allerdings erhalten Sie, genau wie bei Python, Warnungen, mit denen Sie häufig Fehler vermeiden können.
Sie können einen tieferen Blick in diese Indizes werfen, wenn Sie ausreichend fasziniert sind. Dafür erstellen wir eine Seitenprüfung Erweiterungsinstanz.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Wenn Sie den Code vollständig überprüfen möchten, beginnen Sie mit README.
Zusammenfassung
Hash-Indizes sind eine Datenstruktur, die die Suche nach Informationen in großen Datenbanken beschleunigt. Sie arbeiten, indem sie die Daten in kleinere Stücke aufteilen und sie dann sortieren. Wenn Sie also nach etwas suchen, können Sie es viel schneller finden.
Wenn Sie mehr nachschlagen möchten, gibt es Ressourcen für DYOR. Halten Sie auch Ausschau nach unseren neuen Artikeln, die schneller herauskommen, als Sie das Wort „Hash“ auf dieser Seite mit Strg+F drücken können. Hoffe, das hilft!