Referenztabellen in Ihrer Datenbank zu haben, ist keine große Sache, oder? Sie müssen nur einen Code oder eine ID mit einer Beschreibung für jeden Referenztyp verknüpfen. Aber was, wenn Sie buchstäblich Dutzende von Referenztabellen haben? Gibt es eine Alternative zum One-Table-per-Type-Ansatz? Lesen Sie weiter, um ein generisches und erweiterbares zu entdecken Datenbankdesign zur Handhabung all Ihrer Referenzdaten.
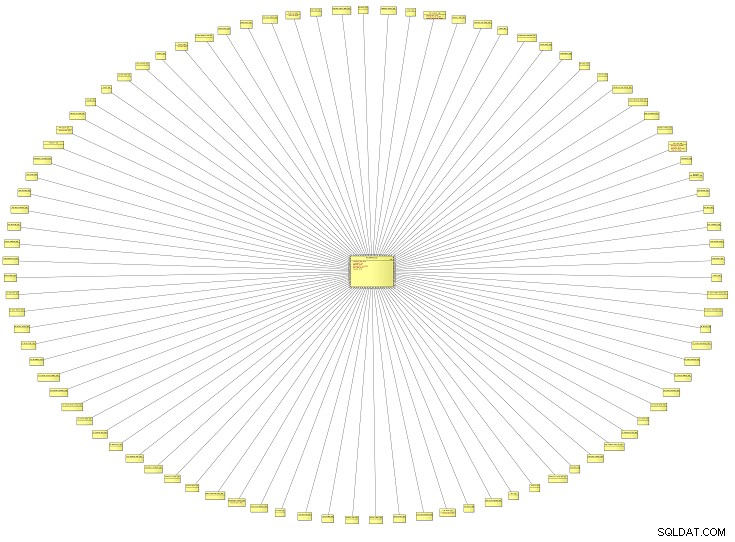
Dieses ungewöhnlich aussehende Diagramm ist eine Vogelperspektive eines logischen Datenmodells (LDM), das alle Referenztypen für ein Unternehmenssystem enthält. Es stammt von einer Bildungseinrichtung, könnte aber für das Datenmodell jeder Art von Organisation gelten. Je größer das Modell, desto mehr Referenztypen werden Sie wahrscheinlich entdecken.
Mit Referenztypen meine ich Referenzdaten oder Nachschlagewerte oder – wenn Sie auf der Hut sein wollen – Taxonomien . Normalerweise werden die hier definierten Werte in Dropdown-Listen in der Benutzeroberfläche Ihrer Anwendung verwendet. Sie können auch als Überschriften in einem Bericht erscheinen.
Dieses spezielle Datenmodell hatte ungefähr 100 Referenztypen. Lassen Sie uns hineinzoomen und nur zwei davon ansehen.
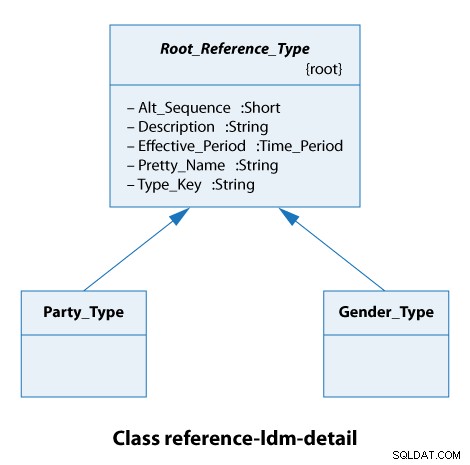
Aus diesem Klassendiagramm sehen wir, dass alle Referenztypen den Root_Reference_Type . In der Praxis bedeutet dies nur, dass alle unsere Referenztypen die gleichen Attribute von Alt_Sequence haben bis zu Type_Key einschließlich, wie unten gezeigt.
| Attribut | Beschreibung |
|---|---|
Alt_Sequence | Wird verwendet, um eine alternative Reihenfolge zu definieren, wenn eine nicht-alphabetische Reihenfolge erforderlich ist. |
Description | Die Beschreibung des Typs. |
Effective_Period | Legt effektiv fest, ob der Referenzeintrag aktiviert ist oder nicht. Sobald eine Referenz verwendet wurde, kann sie aufgrund von Referenzeinschränkungen nicht gelöscht werden; es kann nur deaktiviert werden. |
| Der hübsche Name für den Typ. Das sieht der Benutzer auf dem Bildschirm. |
Type_Key | Der eindeutige interne SCHLÜSSEL für den Typ. Dies ist dem Benutzer verborgen, aber Anwendungsentwickler können dies in ihrem SQL ausgiebig nutzen. |
Die Art der Partei ist hier entweder eine Organisation oder eine Person. Die Geschlechtstypen sind männlich und weiblich. Das sind also wirklich einfache Fälle.
Die traditionelle Referenztabellenlösung
Wie werden wir also das logische Modell in der physischen Welt einer tatsächlichen Datenbank implementieren?
Wir könnten davon ausgehen, dass jeder Referenztyp auf seine eigene Tabelle abgebildet wird. Sie könnten dies als das traditionellere eine Tabelle pro Klasse bezeichnen Lösung. Es ist einfach genug und würde in etwa so aussehen:
Die Kehrseite davon ist, dass es Dutzende und Aberdutzende dieser Tabellen geben könnte, die alle dieselben Spalten haben und alle ziemlich dasselbe tun.
Außerdem können wir viel mehr Entwicklungsarbeit leisten . Wenn Administratoren für die Pflege der Werte ein UI für jeden Typ benötigen, vervielfacht sich der Arbeitsaufwand schnell. Dafür gibt es keine festen Regeln – es hängt wirklich von Ihrer Entwicklungsumgebung ab – also müssen Sie mit Ihren Entwicklern sprechen um zu verstehen, welche Auswirkungen dies hat.
Aber angesichts der Tatsache, dass alle unsere Referenztypen die gleichen Attribute oder Spalten haben, gibt es eine allgemeinere Möglichkeit, unser logisches Datenmodell zu implementieren? Ja da ist! Und benötigt nur zwei Tabellen .
Die Zwei-Tisch-Lösung
Die erste Diskussion, die ich jemals über dieses Thema geführt habe, fand Mitte der 90er Jahre statt, als ich für eine Versicherungsgesellschaft auf dem Londoner Markt arbeitete. Damals gingen wir direkt zum physischen Design und verwendeten hauptsächlich natürliche/geschäftliche Schlüssel, keine IDs. Wo Referenzdaten vorhanden waren, entschieden wir uns, eine Tabelle pro Typ zu führen, die aus einem eindeutigen Code (dem VARCHAR PK) und einer Beschreibung bestand. Tatsächlich gab es damals viel weniger Nachschlagewerke. In den meisten Fällen wird in einer Spalte ein eingeschränkter Satz von Geschäftscodes verwendet, möglicherweise mit einer definierten Datenbankprüfungseinschränkung. es gäbe überhaupt keine Referenztabelle.
Aber das Spiel ist seitdem weitergegangen. Das ist was für eine Zwei-Tabellen-Lösung könnte so aussehen:
Wie Sie sehen können, ist dieses physische Datenmodell sehr einfach. Aber es ist ganz anders als das logische Modell, und nicht, weil irgendetwas in die Hose gegangen wäre. Das liegt daran, dass im Rahmen des physischen Designs einige Dinge getan wurden .
Der reference_type Tabelle repräsentiert jede einzelne Referenzklasse aus dem LDM. Wenn Sie also 20 Referenztypen in Ihrem LDM haben, haben Sie 20 Zeilen mit Metadaten in der Tabelle. Der reference_value Tabelle enthält die zulässigen Werte für alle die Referenztypen.
Zum Zeitpunkt dieses Projekts gab es einige recht lebhafte Diskussionen zwischen Entwicklern. Einige bevorzugten die Zwei-Tisch-Lösung und andere die Ein-Tisch-pro-Typ Methode.
Für jede Lösung gibt es Vor- und Nachteile. Wie Sie sich vorstellen können, waren die Entwickler hauptsächlich besorgt über den Arbeitsaufwand, den die Benutzeroberfläche erfordern würde. Einige dachten, dass es ziemlich schnell gehen würde, eine Admin-Benutzeroberfläche für jeden Tisch zusammenzustellen. Andere dachten, dass das Erstellen einer einzelnen Admin-Benutzeroberfläche komplexer wäre, sich aber letztendlich auszahlt.
Bei diesem speziellen Projekt wurde die Zwei-Tisch-Lösung bevorzugt. Sehen wir uns das genauer an.
Das erweiterbare und flexible Referenzdatenmuster
Da sich Ihr Datenmodell im Laufe der Zeit weiterentwickelt und neue Referenztypen erforderlich sind, müssen Sie nicht für jeden neuen Referenztyp Änderungen an Ihrer Datenbank vornehmen. Sie müssen lediglich neue Konfigurationsdaten definieren. Dazu fügen Sie dem reference_type Tabelle und fügen Sie ihre kontrollierte Liste zulässiger Werte zum reference_value Tabelle.
Ein wichtiges Konzept dieser Lösung ist die Definition effektiver Zeiträume für bestimmte Werte. Beispielsweise muss Ihre Organisation möglicherweise einen neuen reference_value eines „Ausweisnachweises“, der zu einem späteren Zeitpunkt akzeptabel sein wird. Es ist einfach, diesen neuen reference_value mit dem effective_period_from Datum richtig eingestellt. Dies kann im Voraus erfolgen. Bis zu diesem Datum erscheint der neue Eintrag nicht in der Dropdown-Liste der Werte, die Benutzer Ihrer Anwendung sehen. Dies liegt daran, dass Ihre Anwendung nur aktuelle oder aktivierte Werte anzeigt.
Andererseits müssen Sie Benutzer möglicherweise daran hindern, einen bestimmten reference_value . Aktualisieren Sie ihn in diesem Fall einfach mit dem effective_period_to Datum richtig eingestellt. Wenn dieser Tag vorüber ist, wird der Wert nicht mehr in der Dropdown-Liste angezeigt. Ab diesem Zeitpunkt wird es deaktiviert. Da es jedoch weiterhin physisch als Zeile in der Tabelle vorhanden ist, bleibt die referenzielle Integrität erhalten für die Tabellen, auf die bereits verwiesen wurde.
Jetzt, da wir an der Zwei-Tabellen-Lösung arbeiteten, wurde deutlich, dass einige zusätzliche Spalten für reference_type Tisch. Diese konzentrierten sich hauptsächlich auf UI-Bedenken.
Beispiel:pretty_name auf reference_type Tabelle wurde zur Verwendung in der Benutzeroberfläche hinzugefügt. Bei großen Taxonomien ist es hilfreich, ein Fenster mit Suchfunktion zu verwenden. Dann pretty_name könnte für den Titel des Fensters verwendet werden.
Wenn andererseits eine Dropdown-Liste mit Werten ausreicht, pretty_name könnte für die LOV-Eingabeaufforderung verwendet werden. Auf ähnliche Weise könnte die Beschreibung in der Benutzeroberfläche verwendet werden, um die Rollover-Hilfe zu füllen.
Ein Blick auf die Art der Konfigurations- oder Metadaten, die in diese Tabellen eingehen, wird helfen, die Dinge ein wenig zu klären.
Wie man all das verwaltet
Während das hier verwendete Beispiel sehr einfach ist, können die Richtwerte für ein großes Projekt schnell recht komplex werden. Daher kann es ratsam sein, all dies in einer Tabelle zu verwalten. Wenn dies der Fall ist, können Sie die Tabelle selbst verwenden, um die SQL mithilfe der Zeichenfolgenverkettung zu generieren. Diese wird in Skripts eingefügt, die für die Zieldatenbanken ausgeführt werden, die den Entwicklungslebenszyklus und die Produktionsdatenbank (Live) unterstützen. Dadurch wird die Datenbank mit allen notwendigen Referenzdaten gefüllt.
Hier sind die Konfigurationsdaten für die beiden LDM-Typen, Gender_Type und Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
Es gibt eine Zeile in reference_type für jeden LDM-Untertyp von Root_Reference_Type . Die Beschreibung in reference_type wird der LDM-Klassenbeschreibung entnommen. Für Gender_Type , würde dies lauten „Identifiziert das Geschlecht einer Person“. Die DML-Snippets zeigen die Unterschiede in den Beschreibungen zwischen Typ und Wert, die in der Benutzeroberfläche oder in Berichten verwendet werden können.
Sie werden diesen reference_type genannt Gender_Type wurde ein Bereich von 13000000 bis 13999999 für die zugehörigen reference_value.ids zugewiesen . In diesem Modell ist jeder reference_type wird ein eindeutiger, sich nicht überschneidender Bereich von IDs zugewiesen. Dies ist nicht unbedingt erforderlich, ermöglicht es uns jedoch, zusammengehörige Wert-IDs zu gruppieren. Es ahmt in gewisser Weise nach, was Sie erhalten würden, wenn Sie separate Tabellen hätten. Es ist schön zu haben, aber wenn Sie nicht glauben, dass dies einen Nutzen bringt, können Sie darauf verzichten.
Eine weitere Spalte, die dem PDM hinzugefügt wurde, ist admin_role . Hier ist der Grund.
Wer sind die Administratoren
Bei einigen Taxonomien können Werte mit geringen oder keinen Auswirkungen hinzugefügt oder entfernt werden. Dies tritt auf, wenn keine Programme die Werte in ihrer Logik verwenden oder wenn der Typ nicht mit anderen Systemen verbunden ist. In solchen Fällen ist es für Benutzeradministratoren sicher, diese auf dem neuesten Stand zu halten.
Aber in anderen Fällen muss viel mehr Sorgfalt walten. Ein neuer Referenzwert kann unbeabsichtigte Auswirkungen auf die Programmlogik oder auf nachgeschaltete Systeme haben.
Angenommen, wir fügen der Taxonomie des Geschlechtstyps Folgendes hinzu:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
Das wird schnell zum Problem, wenn wir irgendwo folgende Logik eingebaut haben:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Die Logik „Wenn du nicht männlich bist, musst du weiblich sein“ gilt eindeutig nicht mehr in der erweiterten Taxonomie.
Hier ist die admin_role Spalte kommt ins Spiel. Es entstand aus Diskussionen mit den Entwicklern über das physische Design und funktionierte in Verbindung mit ihrer UI-Lösung. Aber wenn die Lösung mit einer Tabelle pro Klasse gewählt wurde, dann reference_type hätte es nicht gegeben. Die darin enthaltenen Metadaten wären fest in die Anwendung Gender_Type Tabelle – , die weder flexibel noch erweiterbar ist.
Nur Benutzer mit der richtigen Berechtigung können die Taxonomie verwalten. Dies basiert wahrscheinlich auf fachlicher Expertise (KMU ). Andererseits müssen einige Taxonomien möglicherweise von der IT verwaltet werden, um eine Auswirkungsanalyse, gründliche Tests und eine harmonische Freigabe aller Codeänderungen rechtzeitig für die neue Konfiguration zu ermöglichen. (Ob dies durch Änderungsanforderungen oder auf andere Weise erfolgt, bleibt Ihrer Organisation überlassen.)
Sie haben vielleicht bemerkt, dass die Audit-Spalten created_by , created_date , updated_by , und updated_date werden im obigen Skript überhaupt nicht referenziert. Nochmals, wenn Sie an diesen nicht interessiert sind, müssen Sie sie nicht verwenden. Diese spezielle Organisation hatte einen Standard, der vorschrieb, Audit-Spalten in jeder Tabelle zu haben.
Auslöser:Einheitlichkeit bewahren
Trigger stellen sicher, dass diese Audit-Spalten konsistent aktualisiert werden, unabhängig von der Quelle der SQL (Skripts, Ihre Anwendung, geplante Batch-Updates, Ad-hoc-Updates usw.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Mein Hintergrund ist hauptsächlich Oracle und unglücklicherweise begrenzt Oracle Bezeichner auf 30 Bytes. Um dies nicht zu überschreiten, erhält jede Tabelle einen kurzen Alias von drei bis fünf Zeichen, und andere tabellenbezogene Artefakte verwenden diesen Alias in ihren Namen. Also reference_value Der Alias von ist reva – die ersten beiden Zeichen jedes Wortes. Vor Zeileneinfügung und vor Zeilenaktualisierung wird mit bri abgekürzt und bru bzw. Der Sequenzname reva_seq , und so weiter.
Das manuelle Codieren von Triggern wie diesem, Tabelle für Tabelle, erfordert viel demoralisierende Boilerplate-Arbeit für Entwickler. Glücklicherweise können diese Auslöser durch Codegenerierung erstellt werden , aber das ist das Thema eines anderen Artikels!
Die Bedeutung von Schlüsseln
Der ref_type_key und type_key Spalten sind beide auf 30 Byte begrenzt. Dadurch können sie in SQL-Abfragen vom PIVOT-Typ verwendet werden (in Oracle. Andere Datenbanken haben möglicherweise nicht die gleiche Längenbeschränkung für Bezeichner).
Da die Eindeutigkeit von Schlüsseln durch die Datenbank sichergestellt wird und der Trigger sicherstellt, dass sein Wert für alle Zeiten gleich bleibt, können – und sollten – diese Schlüssel in Abfragen und Code verwendet werden, um sie lesbarer zu machen . Was meine ich damit? Nun, statt:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Du schreibst:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
Grundsätzlich sagt der Schlüssel klar, was die Abfrage macht .
Von LDM zu PDM, mit Raum zum Wachsen
Der Weg von LDM zu PDM ist nicht unbedingt ein gerader Weg. Es ist auch keine direkte Transformation von einem zum anderen. Es ist ein separater Prozess, der seine eigenen Überlegungen und seine eigenen Bedenken einbringt.
Wie modellieren Sie die Referenzdaten in Ihrer Datenbank?