Galera Cluster mit seiner (nahezu) synchronen Replikation wird häufig in vielen verschiedenen Arten von Umgebungen verwendet. Es zu skalieren, indem neue Knoten hinzugefügt werden, ist nicht schwer (oder genauso einfach ein paar Klicks, wenn Sie ClusterControl verwenden).
Das Hauptproblem bei der synchronen Replikation ist der synchrone Teil, der oft dazu führt, dass der gesamte Cluster nur so schnell ist wie sein langsamster Knoten. Jeder auf einem Cluster ausgeführte Schreibvorgang muss auf alle Knoten repliziert und auf ihnen zertifiziert werden. Wenn sich dieser Prozess aus irgendeinem Grund verlangsamt, kann dies die Fähigkeit des Clusters, Schreibvorgänge zu verarbeiten, ernsthaft beeinträchtigen. Die Flusskontrolle wird dann eingreifen, um sicherzustellen, dass der langsamste Knoten immer noch mit der Last Schritt halten kann. Dies macht es für einige der üblichen Szenarien, die in einer realen Umgebung auftreten, ziemlich schwierig.
Lassen Sie uns zunächst die geografisch verteilte Notfallwiederherstellung besprechen. Natürlich können Sie Cluster über ein Wide Area Network ausführen, aber die erhöhte Latenz wirkt sich erheblich auf die Leistung des Clusters aus. Dies schränkt die Möglichkeit der Verwendung eines solchen Setups ernsthaft ein, insbesondere über längere Entfernungen, wenn die Latenz höher ist.
Ein weiterer recht häufiger Anwendungsfall – eine Testumgebung für das Upgrade einer Hauptversion. Es ist keine gute Idee, verschiedene Versionen von MariaDB Galera Cluster-Knoten im selben Cluster zu mischen, auch wenn dies möglich ist. Andererseits erfordert die Migration auf die neuere Version ausführliche Tests. Idealerweise wären sowohl Lese- als auch Schreibvorgänge getestet worden. Eine Möglichkeit, dies zu erreichen, besteht darin, einen separaten Galera-Cluster zu erstellen und die Tests auszuführen, aber Sie möchten Tests in einer Umgebung ausführen, die so nah wie möglich an der Produktion liegt. Nach der Bereitstellung kann ein Cluster für Tests mit realen Abfragen verwendet werden, aber es wäre schwierig, eine Arbeitslast zu generieren, die der Produktionslast nahe kommt. Sie können einen Teil des Produktionsdatenverkehrs nicht auf ein solches Testsystem verschieben, da die Daten nicht aktuell sind.
Schließlich die Migration selbst. Nochmals, was wir bereits gesagt haben, selbst wenn es möglich ist, alte und neue Versionen von Galera-Knoten im selben Cluster zu mischen, ist dies nicht der sicherste Weg, dies zu tun.
Glücklicherweise wäre die einfachste Lösung für all diese drei Probleme, separate Galera-Cluster mit einer asynchronen Replikation zu verbinden. Was macht es zu einer so guten Lösung? Nun, es ist asynchron, wodurch es die Galera-Replikation nicht beeinflusst. Da es keine Flusskontrolle gibt, wird die Leistung des „Master“-Clusters nicht durch die Leistung des „Slave“-Clusters beeinflusst. Wie bei jeder asynchronen Replikation kann eine Verzögerung auftreten, aber solange sie innerhalb akzeptabler Grenzen bleibt, kann sie einwandfrei funktionieren. Sie müssen auch bedenken, dass die asynchrone Replikation heutzutage parallelisiert werden kann (mehrere Threads können zusammenarbeiten, um die Bandbreite zu erhöhen) und die Replikationsverzögerung noch weiter reduzieren kann.
In diesem Blogbeitrag werden wir die Schritte zur Bereitstellung asynchroner Replikation zwischen MariaDB Galera-Clustern erörtern.
Wie konfiguriere ich die asynchrone Replikation zwischen MariaDB Galera-Clustern?
Zunächst müssen wir einen Cluster bereitstellen. Für unsere Zwecke richten wir einen Drei-Knoten-Cluster ein. Wir werden die Einrichtung auf ein Minimum beschränken, daher werden wir nicht auf die Komplexität der Anwendungs- und Proxy-Schicht eingehen. Die Proxy-Schicht kann sehr nützlich sein, um Aufgaben zu bewältigen, für die Sie eine asynchrone Replikation bereitstellen möchten – das Umleiten einer Teilmenge des schreibgeschützten Datenverkehrs zum Testcluster, das Helfen in der Notfallwiederherstellungssituation, wenn der „Haupt“-Cluster nicht verfügbar ist, indem die Datenverkehr zum DR-Cluster. Es gibt zahlreiche Proxys, die Sie je nach Ihren Vorlieben ausprobieren können – HAProxy, MaxScale oder ProxySQL – alle können in solchen Setups verwendet werden, und je nach Fall können einige von ihnen Ihnen dabei helfen, Ihren Datenverkehr zu verwalten.
Konfigurieren des Quellclusters
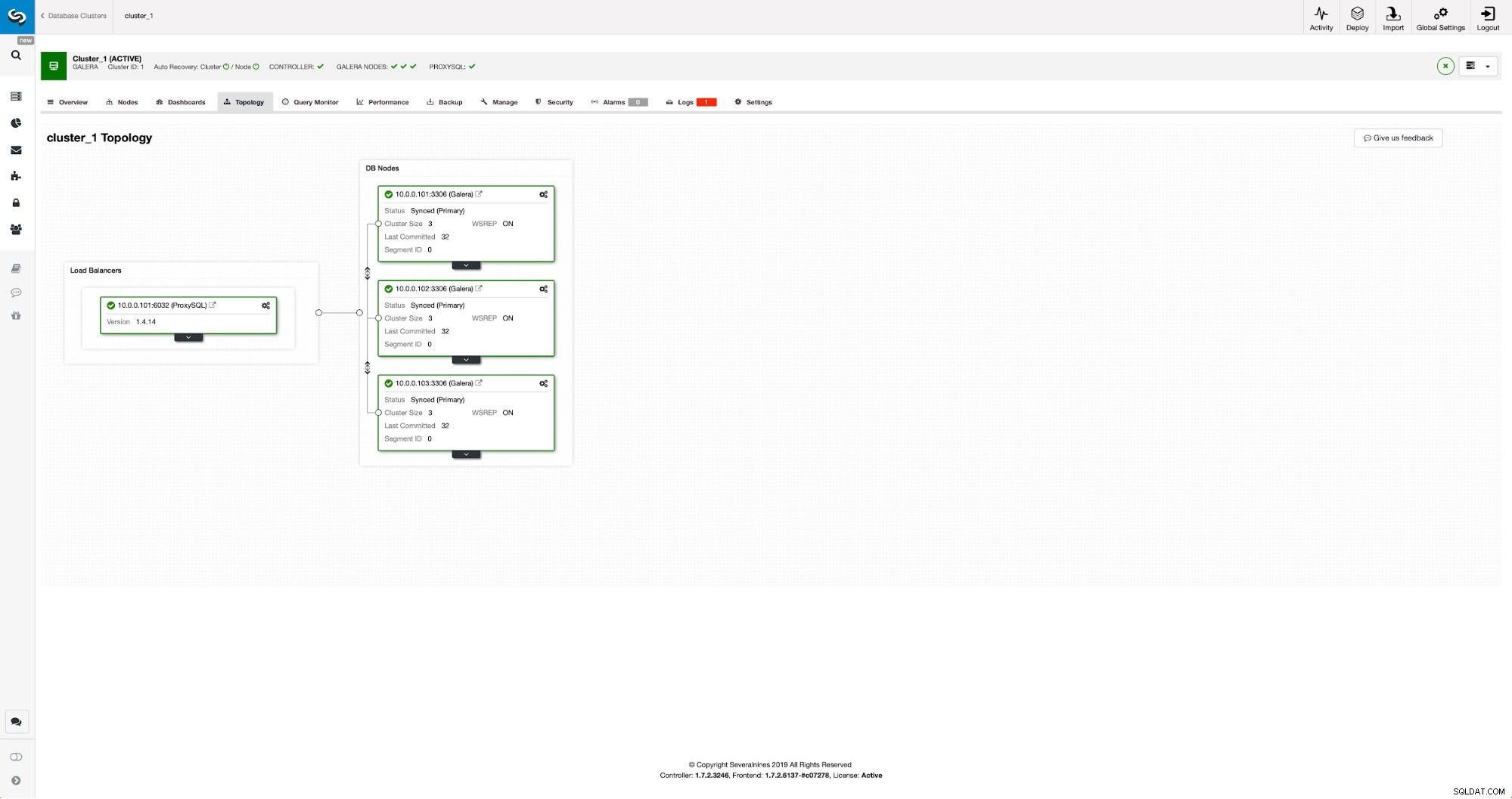
Unser Cluster besteht aus drei MariaDB 10.3-Knoten, wir haben auch ProxySQL bereitgestellt, um die Lese-Schreib-Aufteilung vorzunehmen und den Datenverkehr auf alle Knoten im Cluster zu verteilen. Dies ist keine Bereitstellung auf Produktionsniveau, dafür müssten wir mehr ProxySQL-Knoten und ein Keepalived darüber bereitstellen. Für unsere Zwecke reicht es trotzdem. Um die asynchrone Replikation einzurichten, muss auf unserem Cluster ein Binärprotokoll aktiviert sein. Mindestens ein Knoten, aber es ist besser, ihn auf allen aktiviert zu lassen, falls der einzige Knoten mit aktiviertem Binlog ausfällt - dann möchten Sie einen anderen Knoten im Cluster haben, der aktiv ist und den Sie abarbeiten können.
Stellen Sie beim Aktivieren des Binärprotokolls sicher, dass Sie die Rotation des Binärprotokolls so konfigurieren, dass die alten Protokolle irgendwann entfernt werden. Sie verwenden das ROW-Binärprotokollformat. Sie sollten auch sicherstellen, dass Sie GTID konfiguriert und verwendet haben – es ist sehr praktisch, wenn Sie Ihren „Slave“-Cluster neu versklaven oder die Multithread-Replikation aktivieren müssten. Da es sich um einen Galera-Cluster handelt, möchten Sie „wsrep_gtid_domain_id“ konfiguriert und „wsrep_gtid_mode“ aktiviert haben. Diese Einstellungen stellen sicher, dass GTIDs für den Verkehr generiert werden, der vom Galera-Cluster kommt. Weitere Informationen finden Sie in der Dokumentation. Sobald dies alles erledigt ist, können Sie mit der Einrichtung des zweiten Clusters fortfahren.
Einrichten des Zielclusters
Da es derzeit keinen Zielcluster gibt, müssen wir mit der Bereitstellung beginnen. Wir werden diese Schritte nicht im Detail behandeln, Sie finden Anweisungen in der Dokumentation. Im Allgemeinen besteht der Prozess aus mehreren Schritten:
- MariaDB-Repositories konfigurieren
- MariaDB 10.3-Pakete installieren
- Konfigurieren Sie Knoten, um einen Cluster zu bilden
Am Anfang beginnen wir mit nur einem Knoten. Sie können alle so einrichten, dass sie einen Cluster bilden, aber dann sollten Sie sie stoppen und nur einen für den nächsten Schritt verwenden. Dieser eine Knoten wird ein Slave des ursprünglichen Clusters. Wir werden Mariabackup verwenden, um es bereitzustellen. Dann konfigurieren wir die Replikation.
Zuerst müssen wir ein Verzeichnis erstellen, in dem wir das Backup speichern:
mkdir /mnt/mariabackupDann führen wir das Backup aus und erstellen es in dem im obigen Schritt vorbereiteten Verzeichnis. Bitte stellen Sie sicher, dass Sie den richtigen Benutzer und das richtige Passwort verwenden, um sich mit der Datenbank zu verbinden:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Als nächstes müssen wir die Sicherungsdateien auf den ersten Knoten im zweiten Cluster kopieren. Wir haben dafür scp verwendet, Sie können verwenden, was Sie wollen - rsync, netcat, alles, was funktioniert.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Nachdem das Backup kopiert wurde, müssen wir es vorbereiten, indem wir die Log-Dateien anwenden:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!Im Falle eines Fehlers müssen Sie die Sicherung möglicherweise erneut ausführen. Wenn alles geklappt hat, können wir die alten Daten entfernen und durch die Sicherungsinformationen ersetzen
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Wir wollen auch den richtigen Eigentümer der Dateien festlegen:
chown -R mysql.mysql /var/lib/mysql/Wir verlassen uns auf GTID, um die Replikation konsistent zu halten, daher müssen wir sehen, was die zuletzt angewendete GTID in diesem Backup war. Diese Informationen finden Sie in der xtrabackup_info-Datei, die Teil des Backups ist:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Wir müssen auch sicherstellen, dass der Slave-Knoten Binärprotokolle zusammen mit „log_slave_updates“ aktiviert hat. Idealerweise wird dies auf allen Knoten im zweiten Cluster aktiviert – nur für den Fall, dass der „Slave“-Knoten ausfällt und Sie die Replikation mit einem anderen Knoten im Slave-Cluster einrichten müssten.
Das Letzte, was wir tun müssen, bevor wir die Replikation einrichten können, ist die Erstellung eines Benutzers, den wir verwenden werden, um die Replikation auszuführen:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)Das ist alles, was wir brauchen. Jetzt können wir den ersten Knoten im zweiten Cluster starten, unseren zukünftigen Slave:
galera_new_clusterSobald es gestartet ist, können wir MySQL CLI aufrufen und es so konfigurieren, dass es ein Slave wird, indem wir die GITD-Position verwenden, die wir ein paar Schritte zuvor gefunden haben:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)Sobald das erledigt ist, können wir endlich die Replikation einrichten und starten:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)An diesem Punkt haben wir einen Galera-Cluster, der aus einem Knoten besteht. Dieser Knoten ist auch ein Slave des ursprünglichen Clusters (insbesondere ist sein Master Knoten 10.0.0.101). Um anderen Knoten beizutreten, verwenden wir SST, aber damit es funktioniert, müssen wir zuerst sicherstellen, dass die SST-Konfiguration korrekt ist – bitte denken Sie daran, dass wir gerade alle Benutzer in unserem zweiten Cluster durch den Inhalt des Quellclusters ersetzt haben. Was Sie jetzt tun müssen, ist sicherzustellen, dass die ‚wsrep_sst_auth‘-Konfiguration des zweiten Clusters mit der des ersten Clusters übereinstimmt. Sobald dies erledigt ist, können Sie die verbleibenden Knoten nacheinander starten und sie sollten dem vorhandenen Knoten (10.0.0.104) beitreten, die Daten über SST abrufen und den Galera-Cluster bilden. Letztendlich sollten Sie am Ende zwei Cluster mit jeweils drei Knoten und einem asynchronen Replikationslink darüber haben (in unserem Beispiel von 10.0.0.101 bis 10.0.0.104). Sie können bestätigen, dass die Replikation funktioniert, indem Sie den Wert von:
überprüfenMariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Wie konfiguriere ich die asynchrone Replikation zwischen MariaDB Galera-Clustern mit ClusterControl?
Zum Zeitpunkt dieses Blogs verfügt ClusterControl nicht über die Funktionalität, asynchrone Replikation über mehrere Cluster hinweg zu konfigurieren, wir arbeiten daran, während ich dies schreibe. Nichtsdestotrotz kann ClusterControl bei diesem Prozess eine große Hilfe sein - wir zeigen Ihnen, wie Sie die mühsamen manuellen Schritte durch die Automatisierung von ClusterControl beschleunigen können.
Aus dem, was wir zuvor gezeigt haben, können wir schließen, dass dies die allgemeinen Schritte sind, die beim Einrichten der Replikation zwischen zwei Galera-Clustern zu unternehmen sind:
- Stellen Sie einen neuen Galera-Cluster bereit
- Neuen Cluster mit Daten aus dem alten bereitstellen
- Neuen Cluster konfigurieren (SST-Konfiguration, Binärlogs)
- Richten Sie die Replikation zwischen dem alten und dem neuen Cluster ein
Die ersten drei Punkte können Sie bereits jetzt mit ClusterControl problemlos ausführen. Wir zeigen Ihnen, wie das geht.
Bereitstellen und Bereitstellen eines neuen MariaDB Galera-Clusters mit ClusterControl
Die Ausgangssituation ist ähnlich – wir haben einen Cluster am Laufen. Wir müssen den zweiten einrichten. Eines der neueren Features von ClusterControl ist die Option, einen neuen Cluster bereitzustellen und ihn mit den Daten aus dem Backup bereitzustellen. Dies ist sehr nützlich, um Testumgebungen zu erstellen, es ist auch eine Option, die wir verwenden werden, um unseren neuen Cluster für die Replikationskonfiguration bereitzustellen. Daher ist der erste Schritt, den wir unternehmen werden, ein Backup mit mariabackup zu erstellen:
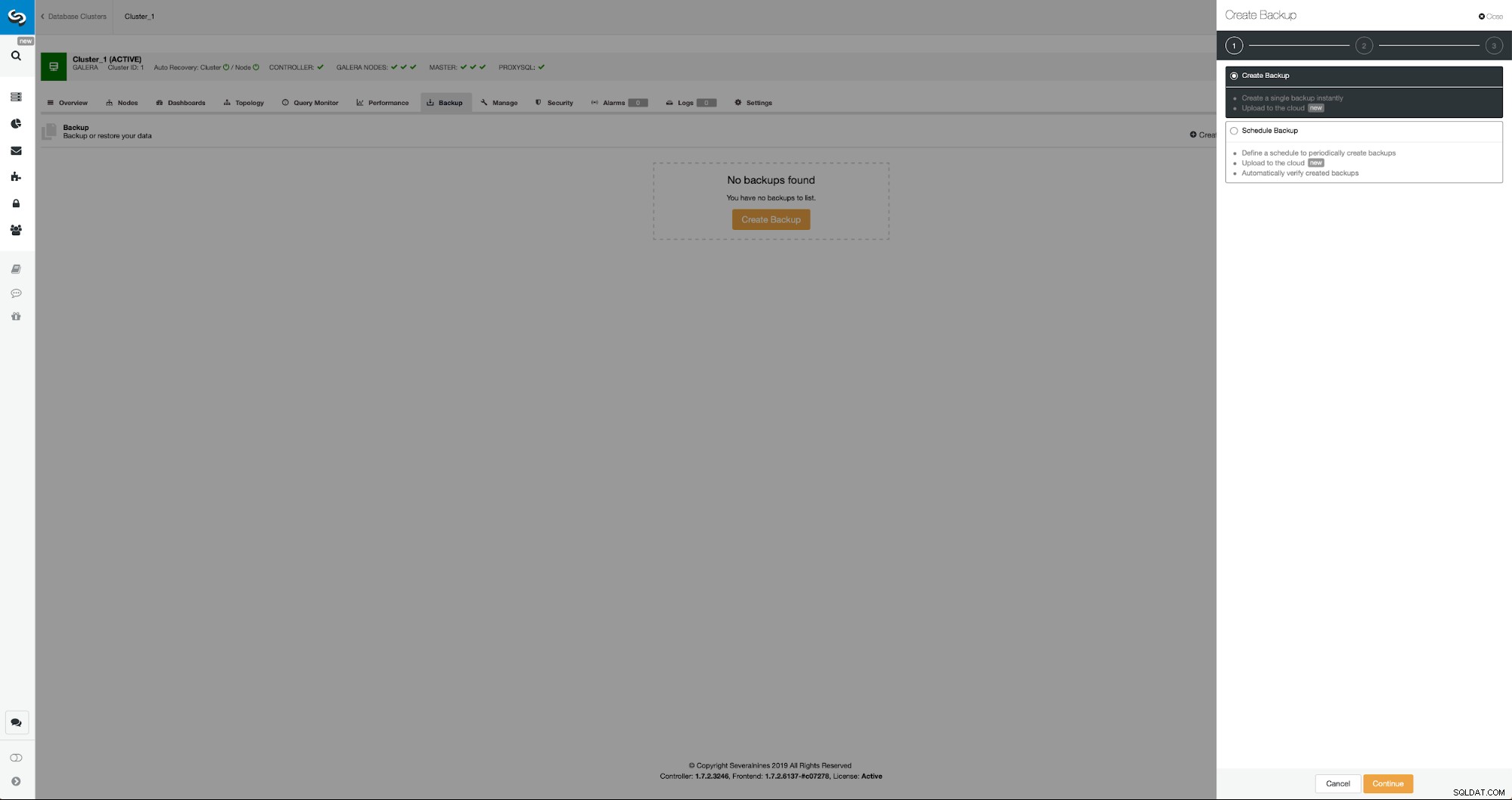
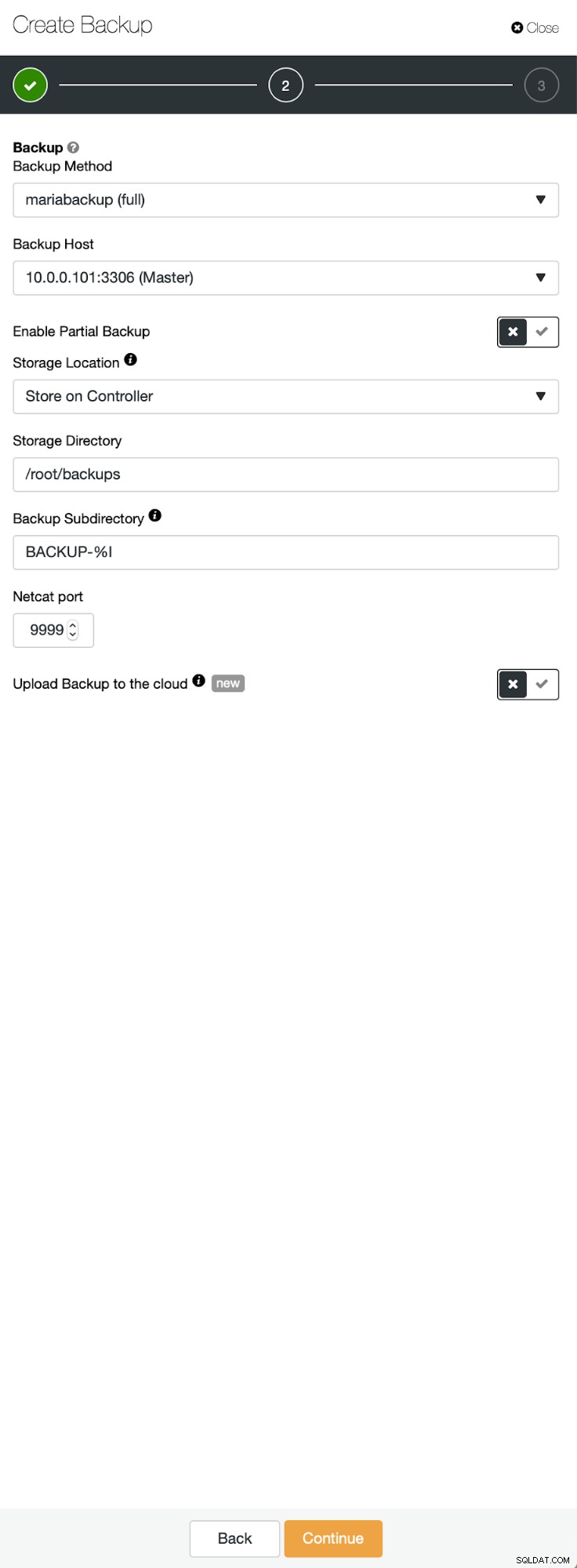
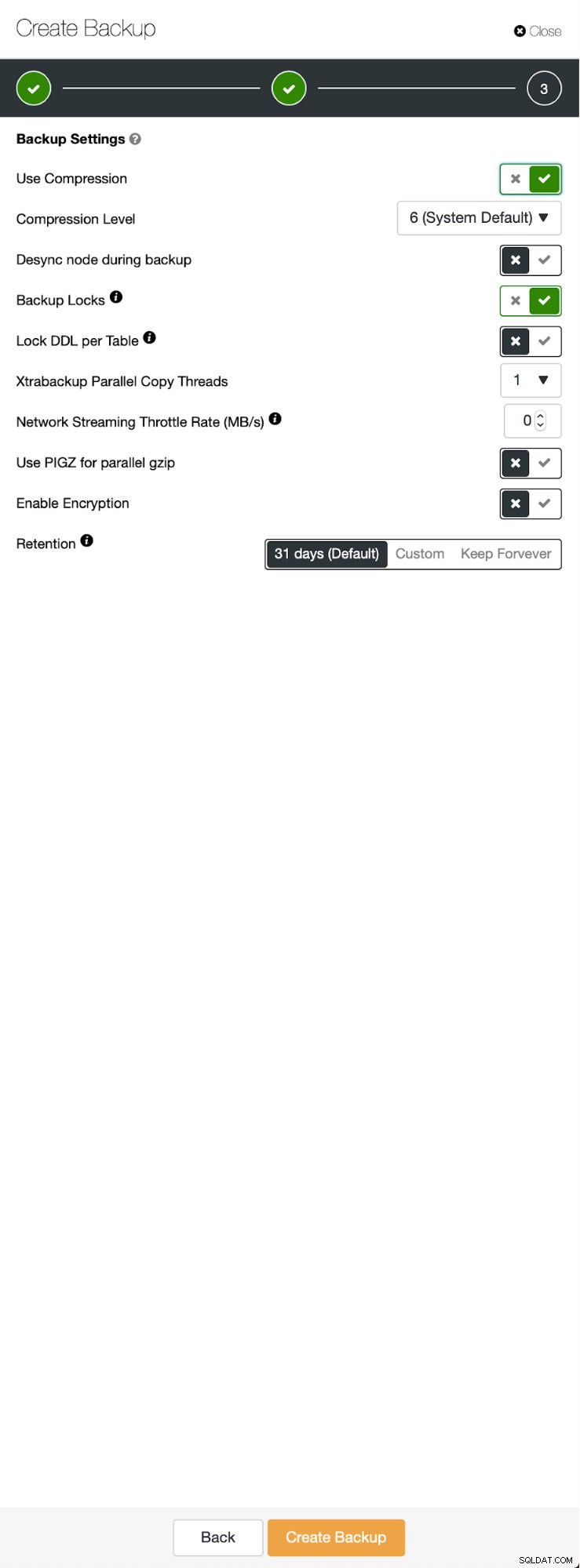
Drei Schritte, in denen wir den Knoten ausgewählt haben, um das Backup davon zu entfernen. Dieser Knoten (10.0.0.101) wird zum Master. Es müssen Binärprotokolle aktiviert sein. In unserem Fall haben alle Knoten binlog aktiviert, aber wenn nicht, ist es sehr einfach, es über ClusterControl zu aktivieren - wir zeigen die Schritte später, wenn wir es für den zweiten Cluster tun werden.
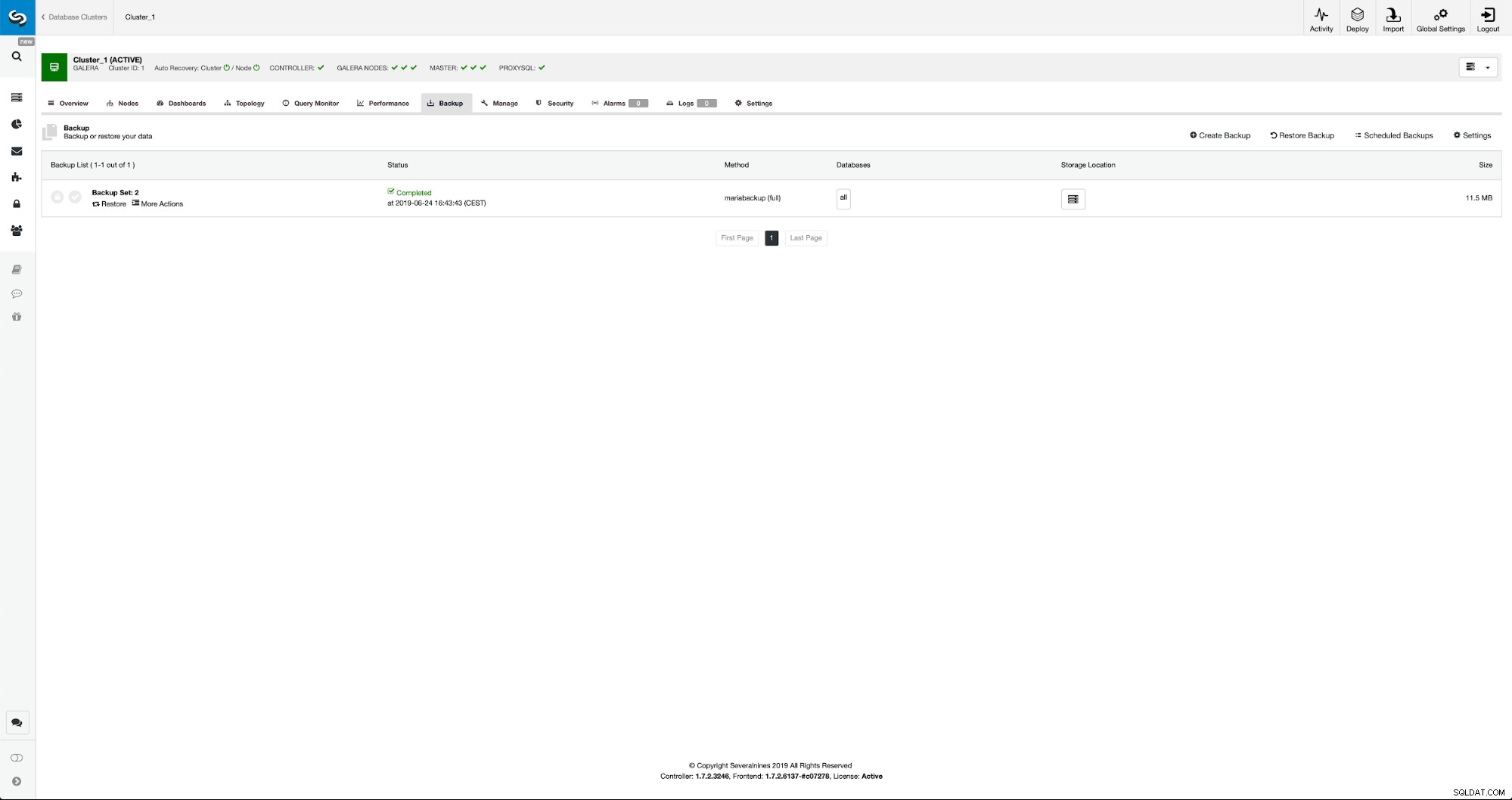
Sobald die Sicherung abgeschlossen ist, wird sie in der Liste sichtbar. Wir können dann fortfahren und es wiederherstellen:

Wenn wir das wollen, könnten wir sogar die Point-In-Time-Wiederherstellung durchführen, aber in unserem Fall spielt es keine Rolle:Sobald die Replikation konfiguriert ist, werden alle erforderlichen Transaktionen aus Binlogs auf den neuen Cluster angewendet.

Dann wählen wir die Option zum Erstellen eines Clusters aus dem Backup. Dies öffnet einen weiteren Dialog:
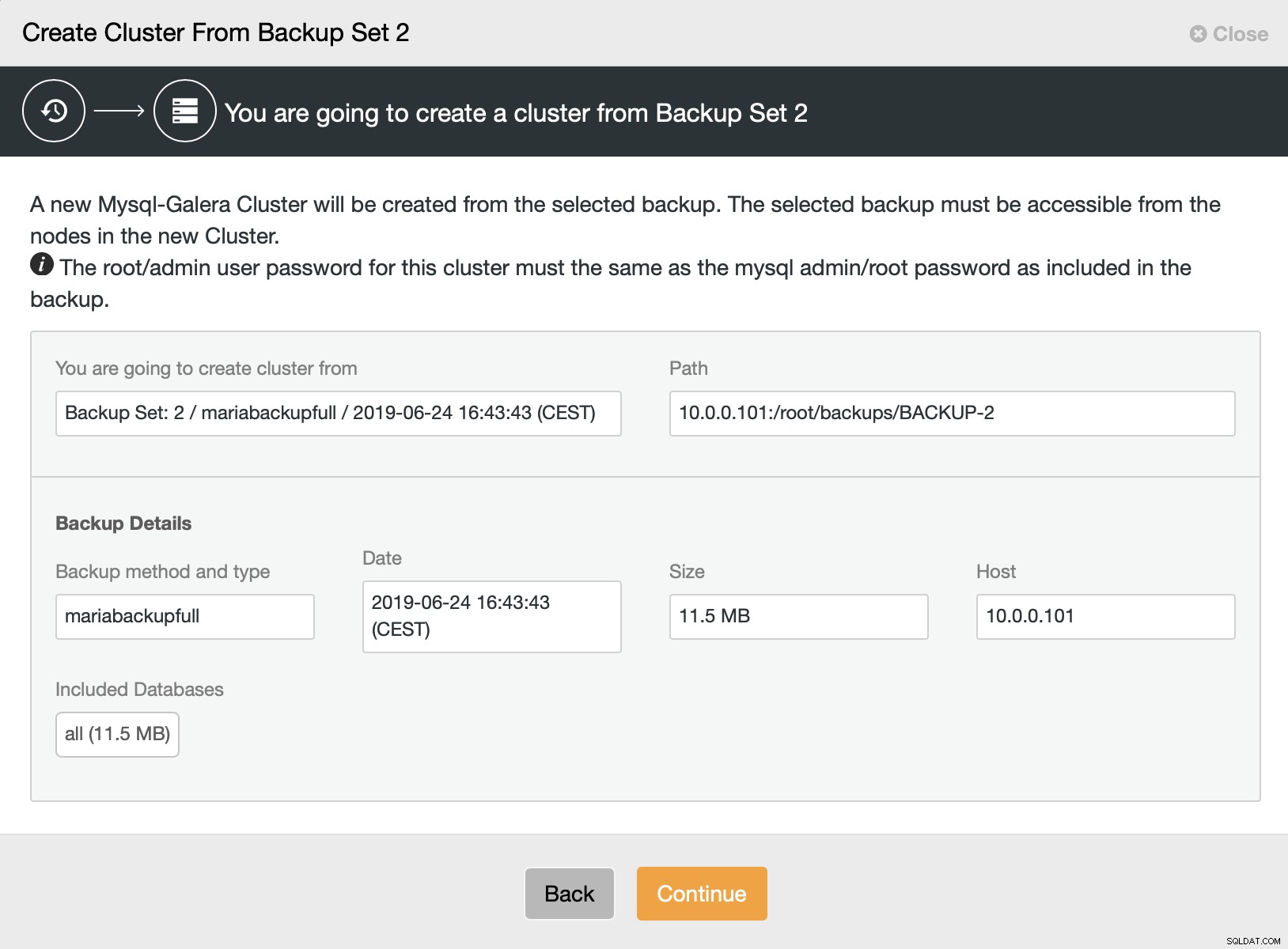
Es ist eine Bestätigung, welches Backup verwendet wird, von welchem Host das Backup stammt, welche Methode verwendet wurde, um es zu erstellen, und einige Metadaten, um zu überprüfen, ob das Backup solide aussieht.
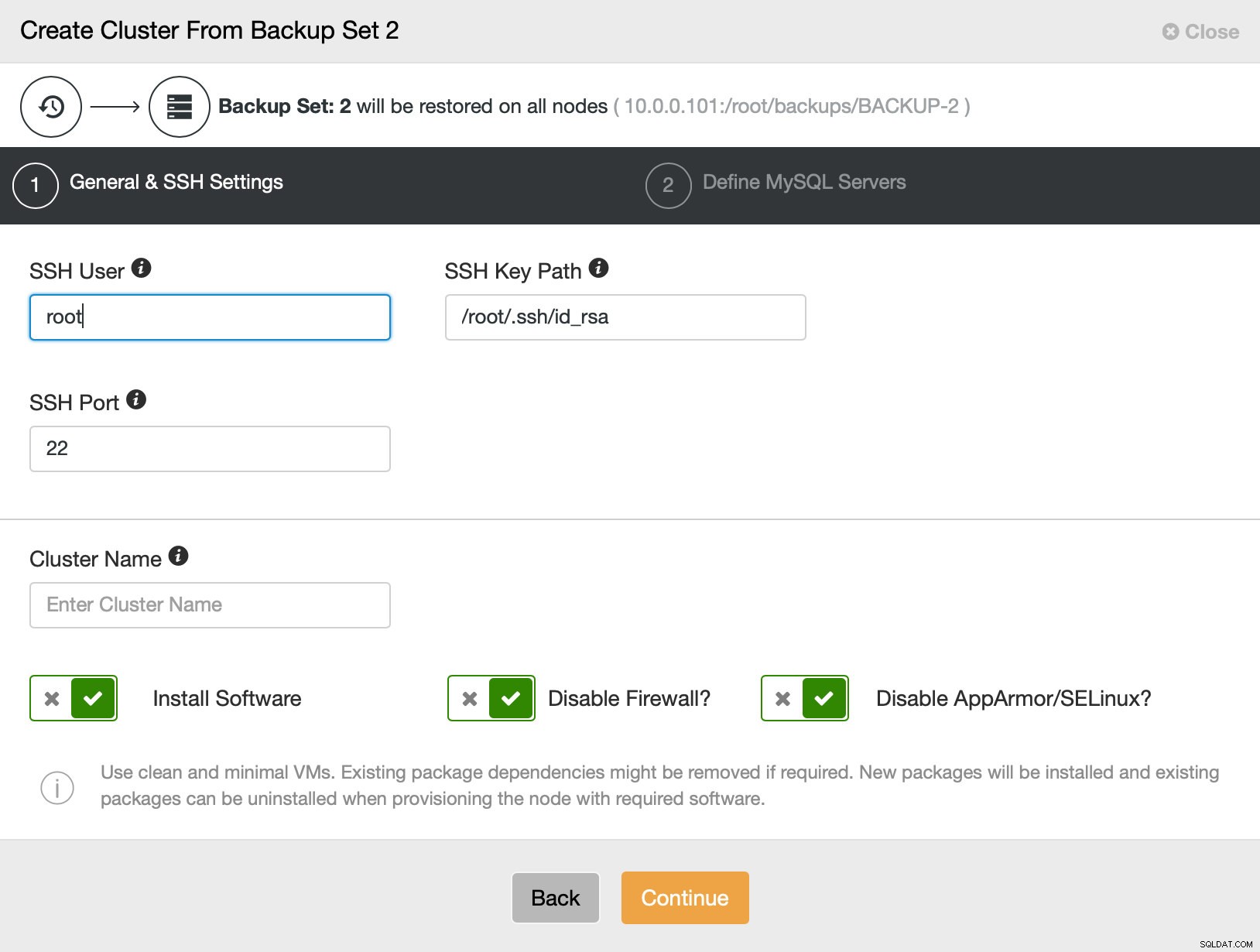
Dann gehen wir im Grunde zum regulären Bereitstellungsassistenten, in dem wir die SSH-Konnektivität zwischen dem ClusterControl-Host und den Knoten definieren müssen, auf denen der Cluster bereitgestellt werden soll (die Voraussetzung für ClusterControl) und im zweiten Schritt Anbieter, Version, Passwort und bereitzustellende Knoten auf:
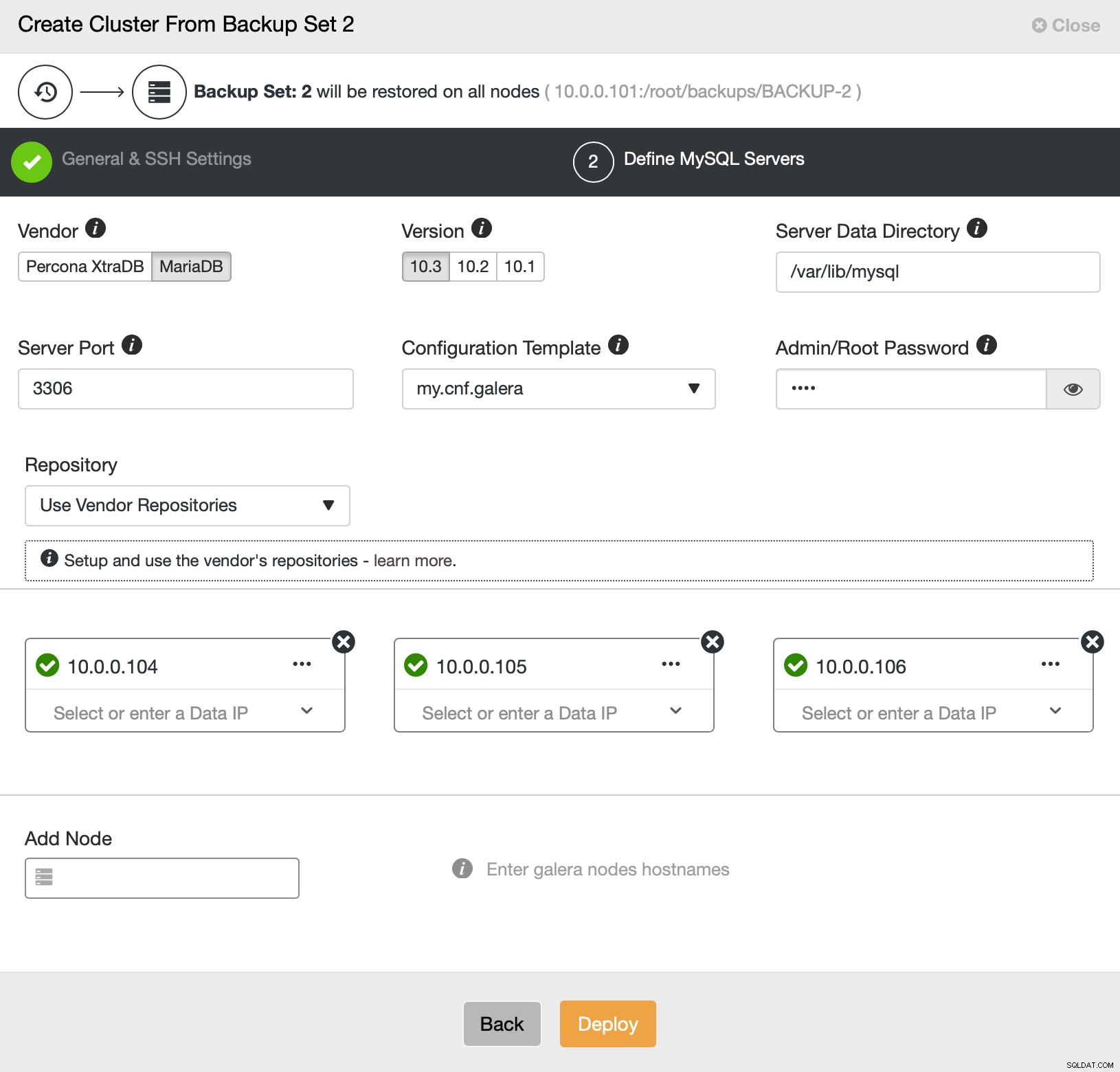
Das ist alles in Bezug auf Bereitstellung und Bereitstellung. ClusterControl richtet den neuen Cluster ein und stellt ihn mit den Daten des alten bereit.
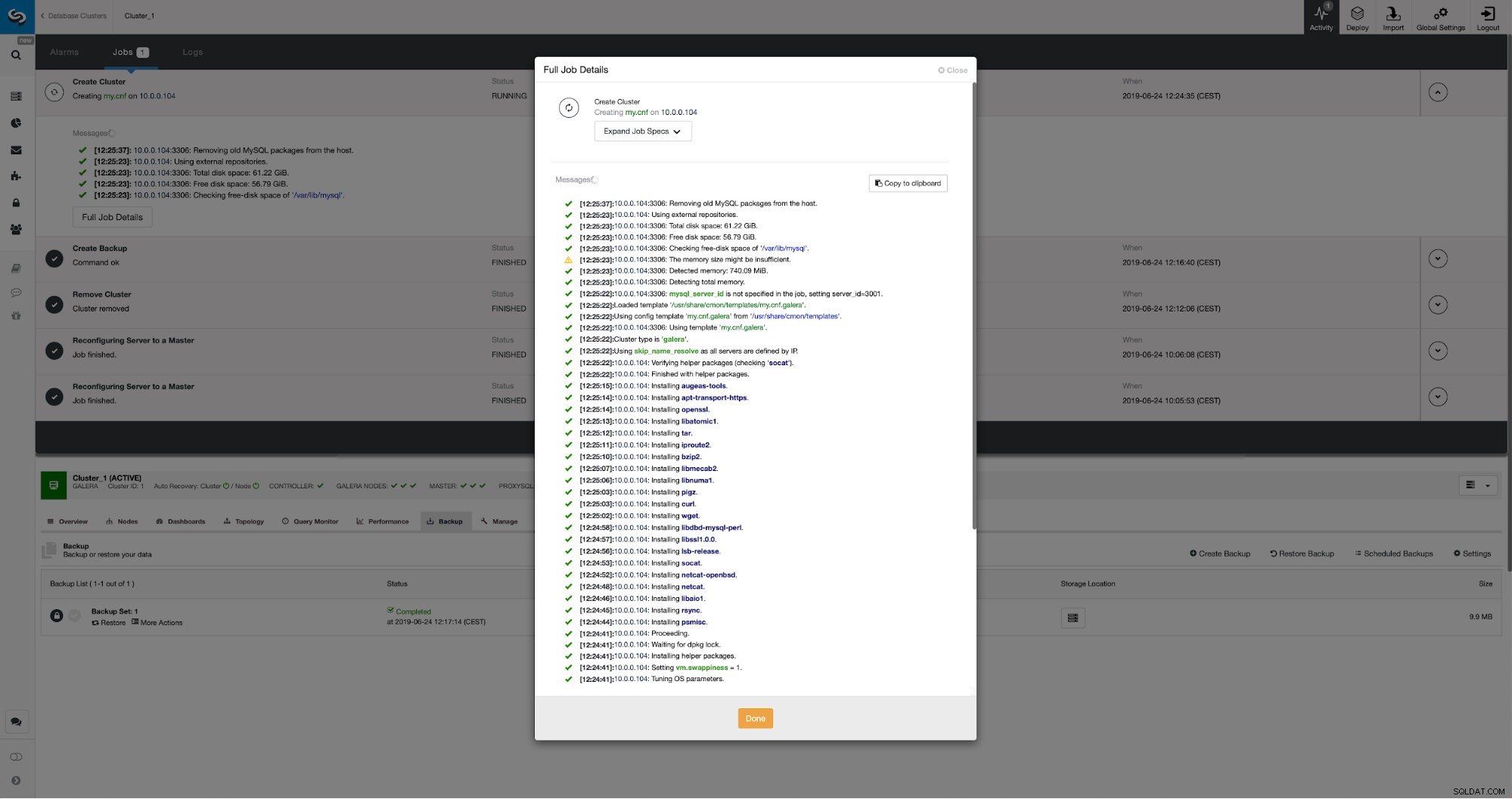
Wir können den Fortschritt auf der Registerkarte „Aktivität“ überwachen. Nach Abschluss wird der zweite Cluster in der Cluster-Liste in ClusterControl angezeigt.
Neukonfiguration des neuen Clusters mit ClusterControl
Jetzt müssen wir den Cluster neu konfigurieren – wir werden Binärprotokolle aktivieren. Im manuellen Prozess mussten wir Änderungen in der Konfiguration wsrep_sst_auth und auch Konfigurationseinträge in den Abschnitten [mysqldump] und [xtrabackup] der Konfiguration vornehmen. Diese Einstellungen finden Sie in der Datei secrets-backup.cnf. Dieses Mal wird es nicht benötigt, da ClusterControl neue Passwörter für den Cluster generiert und die Dateien korrekt konfiguriert hat. Beachten Sie jedoch Folgendes:Sollten Sie das Passwort des Benutzers „backupuser“@„127.0.0.1“ im ursprünglichen Cluster ändern, müssen Sie auch im zweiten Cluster Konfigurationsänderungen vornehmen, um dies als Änderungen widerzuspiegeln der erste Cluster wird auf den zweiten Cluster repliziert.
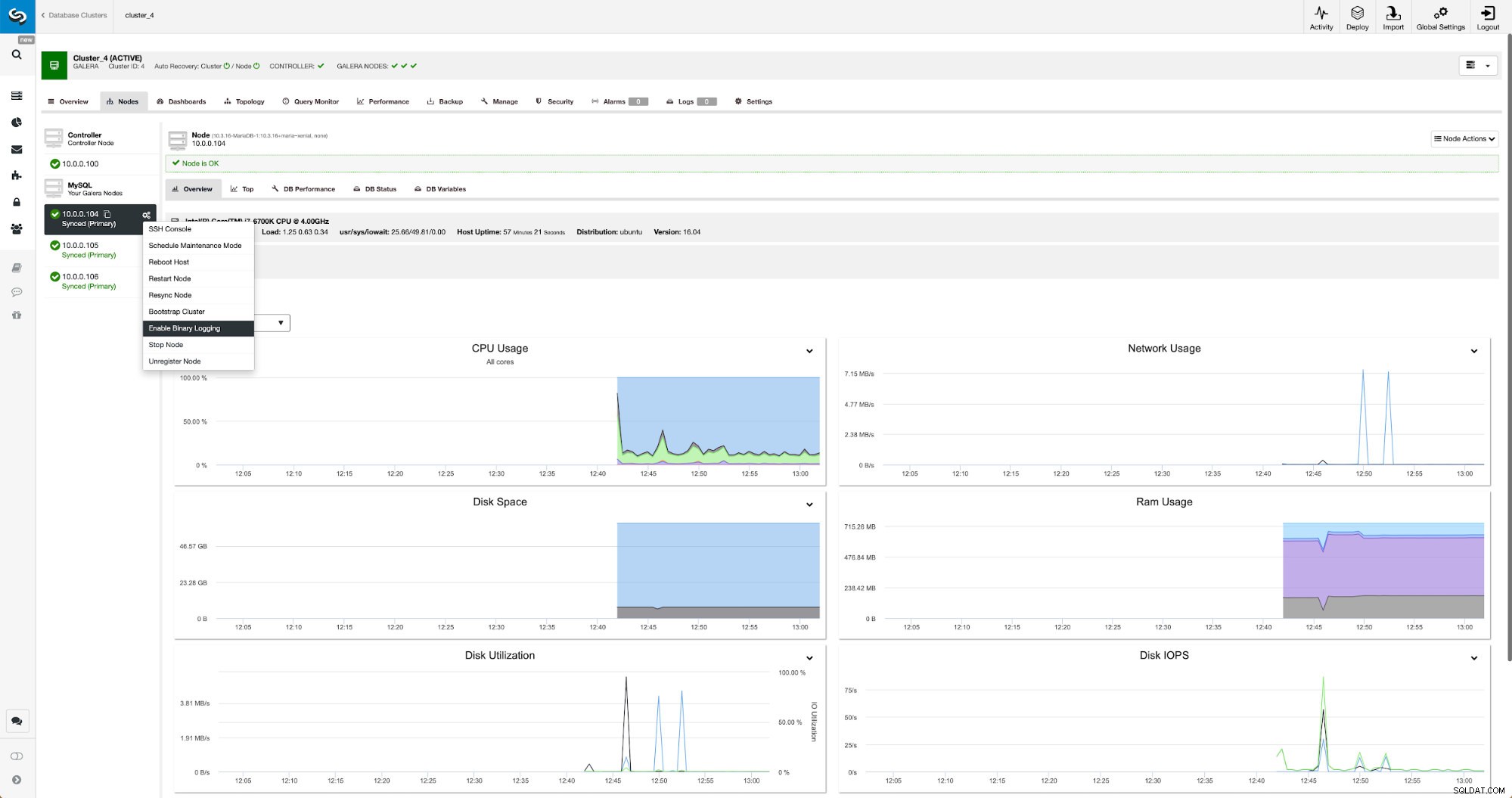
Binäre Protokolle können im Abschnitt Knoten aktiviert werden. Sie müssen Knoten für Knoten auswählen und den Job „Enable Binary Logging“ ausführen. Ihnen wird ein Dialog angezeigt:
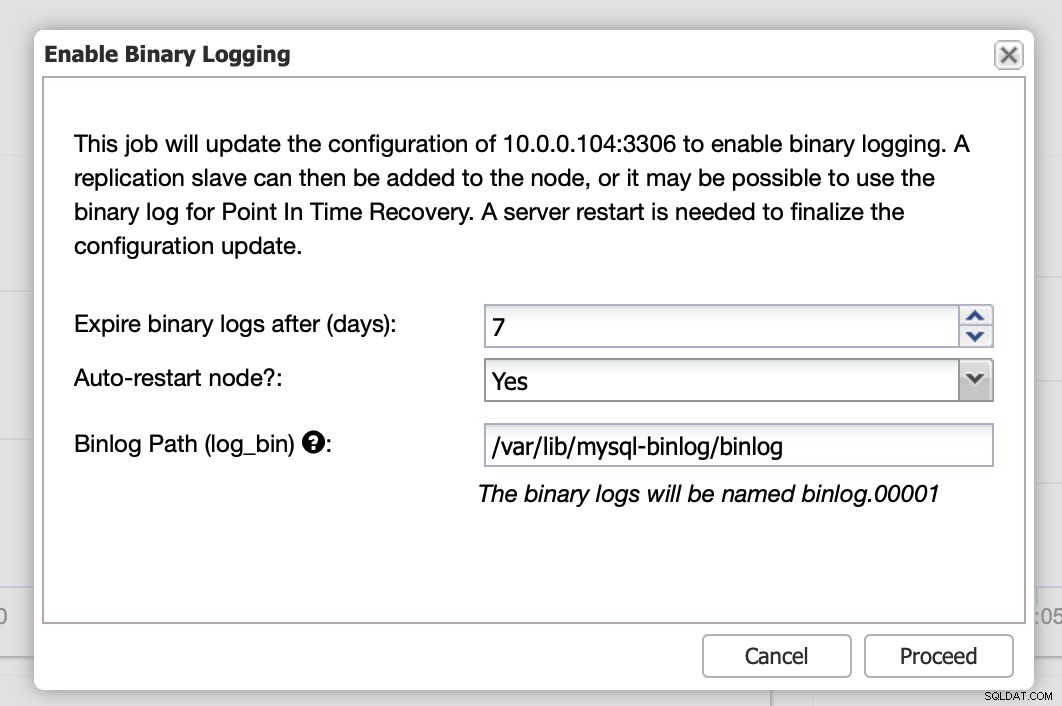
Hier können Sie festlegen, wie lange Sie die Protokolle aufbewahren möchten, wo sie gespeichert werden sollen und ob ClusterControl den Knoten neu starten soll, damit Sie Änderungen anwenden können - die binäre Protokollkonfiguration ist nicht dynamisch und MariaDB muss neu gestartet werden, um diese Änderungen zu übernehmen.
Wenn die Änderungen abgeschlossen sind, sehen Sie alle Knoten als „Master“ gekennzeichnet, was bedeutet, dass diese Knoten das Binärprotokoll aktiviert haben und als Master fungieren können.
Wenn wir noch keinen Replikationsbenutzer erstellt haben, müssen wir das tun. Im ersten Cluster müssen wir zu Manage -> Schemas and Users:
gehen
Auf der rechten Seite haben wir eine Option, um einen neuen Benutzer zu erstellen:
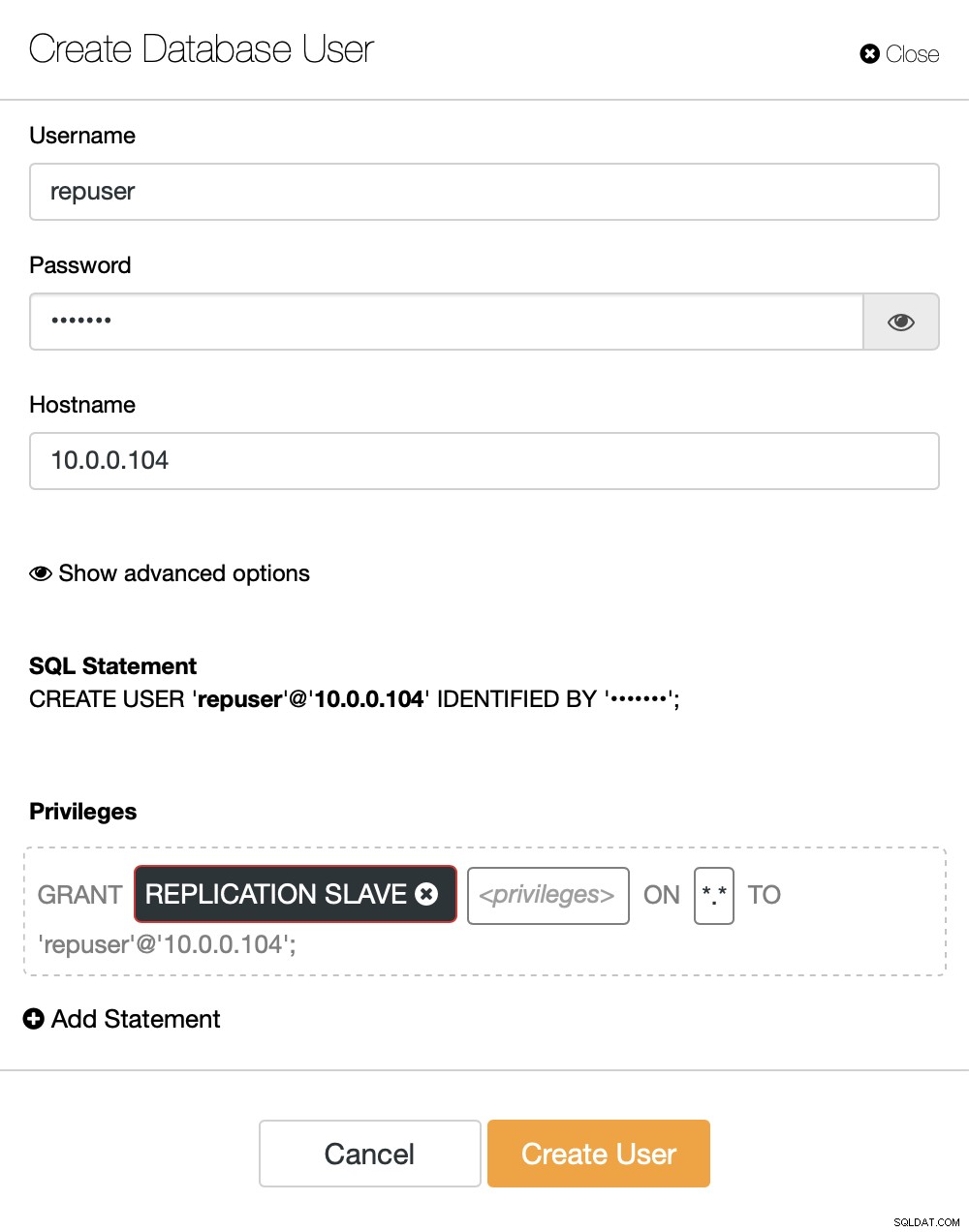
Damit ist die zum Einrichten der Replikation erforderliche Konfiguration abgeschlossen.
Replikation zwischen Clustern mit ClusterControl einrichten
Wie bereits erwähnt, arbeiten wir daran, diesen Teil zu automatisieren. Derzeit muss dies manuell erfolgen. Wie Sie sich vielleicht erinnern, benötigen wir die GITD-Position unseres Backups und führen dann einige Befehle mit der MySQL-CLI aus. GTID-Daten sind im Backup verfügbar. ClusterControl erstellt ein Backup mit xbstream/mbstream und komprimiert es anschließend. Unser Backup wird auf dem ClusterControl-Host gespeichert, auf dem wir keinen Zugriff auf die mbstream-Binärdatei haben. Sie können versuchen, es zu installieren, oder Sie können die Sicherungsdatei an den Ort kopieren, an dem diese Binärdatei verfügbar ist:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/Sobald das erledigt ist, wollen wir am 10.0.0.104 den Inhalt der xtrabackup_info-Datei überprüfen:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Abschließend konfigurieren wir die Replikation und starten sie:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Das ist es – wir haben gerade die asynchrone Replikation zwischen zwei MariaDB Galera-Clustern mit ClusterControl konfiguriert. Wie Sie sehen konnten, war ClusterControl in der Lage, die meisten Schritte zu automatisieren, die wir unternehmen mussten, um diese Umgebung einzurichten.