Hohe Verfügbarkeit ist heutzutage ein Muss, da die meisten Unternehmen es sich nicht erlauben können, ihre Daten zu verlieren. Hochverfügbarkeit ist jedoch immer mit einem Preisschild verbunden (das stark variieren kann). Alle Setups, die nahezu sofortiges Handeln erfordern, würden normalerweise eine teure Umgebung erfordern, die genau das Produktions-Setup widerspiegelt. Aber es gibt andere Optionen, die weniger teuer sein können. Diese ermöglichen möglicherweise keinen sofortigen Wechsel zu einem Notfallwiederherstellungscluster, ermöglichen aber dennoch die Geschäftskontinuität (und belasten das Budget nicht).
Ein Beispiel für diese Art von Setup ist eine „Cold-Standby“-DR-Umgebung. Es ermöglicht Ihnen, Ihre Ausgaben zu reduzieren und gleichzeitig eine neue Umgebung an einem externen Standort einzurichten, falls die Katastrophe eintritt. In diesem Blogbeitrag zeigen wir, wie man ein solches Setup erstellt.
Die Ersteinrichtung
Nehmen wir an, wir haben eine ziemlich standardmäßige Master/Slave-MySQL-Replikationskonfiguration in unserem eigenen Rechenzentrum. Es ist ein hochverfügbares Setup mit ProxySQL und Keepalived für die Handhabung virtueller IPs. Das Hauptrisiko besteht darin, dass das Rechenzentrum nicht mehr verfügbar ist. Es ist ein kleines DC, vielleicht ist es nur ein ISP ohne BGP. Und in dieser Situation gehen wir davon aus, dass es in Ordnung ist, wenn es Stunden dauern würde, die Datenbank wiederherzustellen, solange es möglich ist, sie wiederherzustellen.
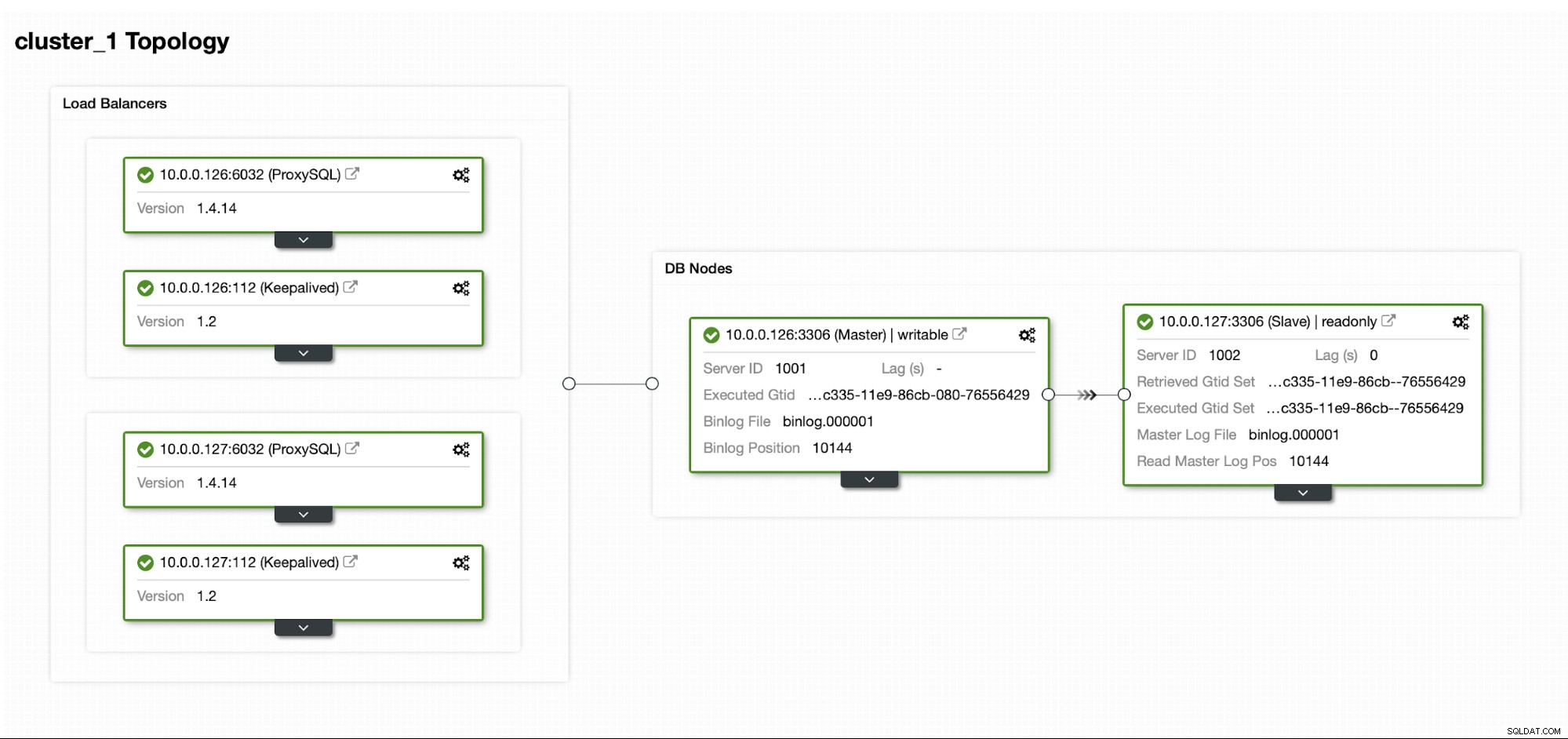
Um diesen Cluster bereitzustellen, haben wir ClusterControl verwendet, das Sie kostenlos herunterladen können. Für unsere DR-Umgebung verwenden wir EC2 (es könnte aber auch jeder andere Cloud-Anbieter sein.)
Die Herausforderung
Das Hauptproblem, mit dem wir uns befassen müssen, ist, wie können wir sicherstellen, dass wir über aktuelle Daten verfügen, um unsere Datenbank in der Notfallwiederherstellungsumgebung wiederherzustellen? Natürlich hätten wir idealerweise einen Replikations-Slave, der in EC2 läuft ... aber dann müssen wir dafür bezahlen. Wenn das Budget knapp ist, könnten wir versuchen, das mit Backups zu umgehen. Dies ist nicht die perfekte Lösung, da wir im schlimmsten Fall nie alle Daten wiederherstellen können.
Mit „Worst-Case-Szenario“ meinen wir eine Situation, in der wir keinen Zugriff auf die ursprünglichen Datenbankserver haben. Wenn wir sie erreichen könnten, wären keine Daten verloren gegangen.
Die Lösung
Wir werden ClusterControl verwenden, um einen Backup-Zeitplan einzurichten, um die Wahrscheinlichkeit zu verringern, dass die Daten verloren gehen. Wir werden auch die ClusterControl-Funktion verwenden, um Backups in die Cloud hochzuladen. Sollte das Rechenzentrum nicht verfügbar sein, können wir hoffen, dass der von uns gewählte Cloud-Anbieter erreichbar ist.
Einrichten des Backup-Zeitplans in ClusterControl
Zuerst müssen wir ClusterControl mit unseren Cloud-Anmeldeinformationen konfigurieren.
Wir können dies tun, indem wir „Integrationen“ aus dem Menü auf der linken Seite verwenden.
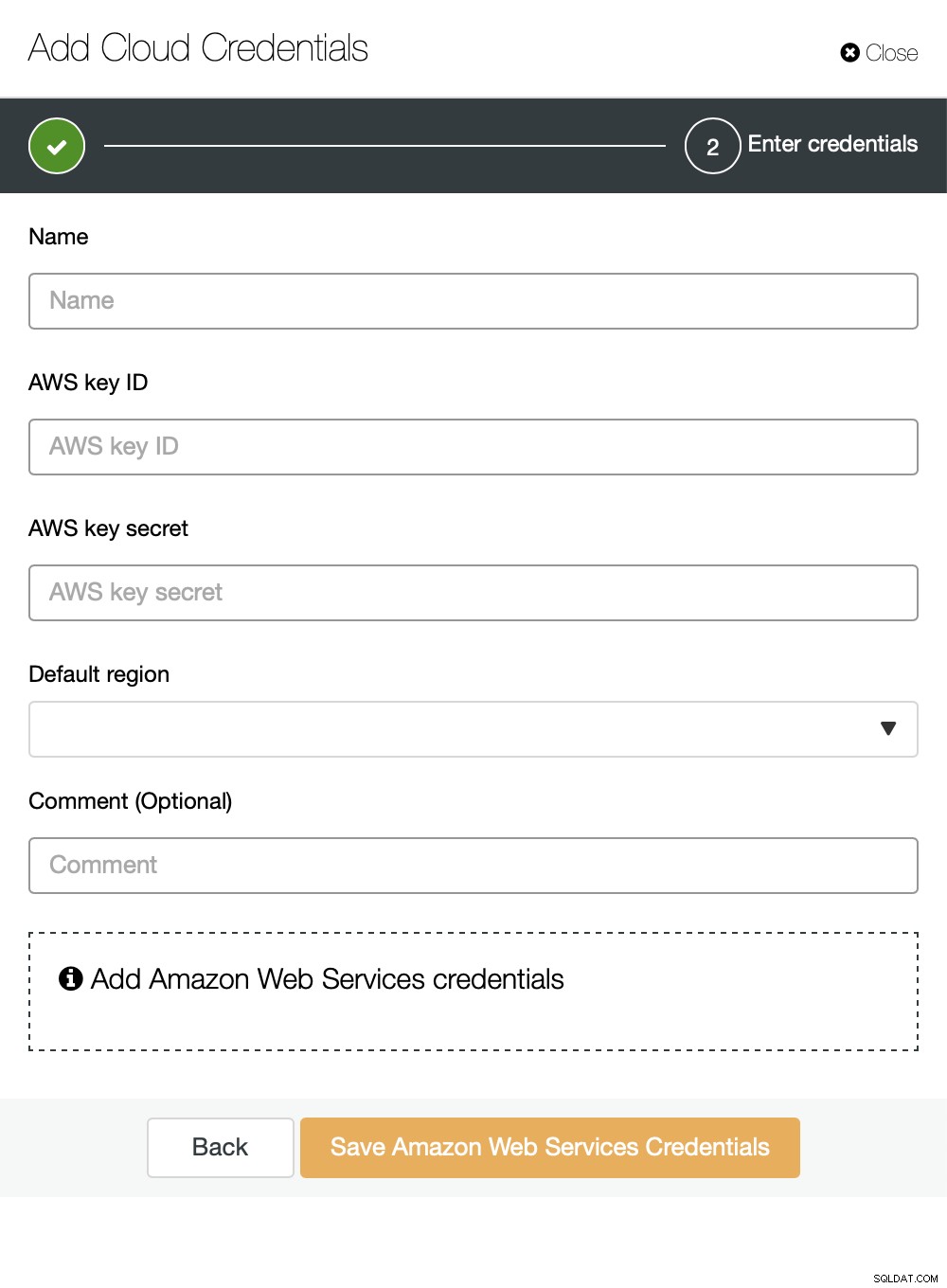
Sie können Amazon Web Services, Google Cloud oder Microsoft Azure als Cloud auswählen Sie möchten, dass ClusterControl Backups hochlädt. Wir werden mit AWS fortfahren, wo ClusterControl S3 zum Speichern von Backups verwenden wird.
Wir müssen dann die Schlüssel-ID und das Schlüsselgeheimnis übergeben und die Standardregion auswählen und wählen Sie einen Namen für diesen Satz von Anmeldeinformationen aus.
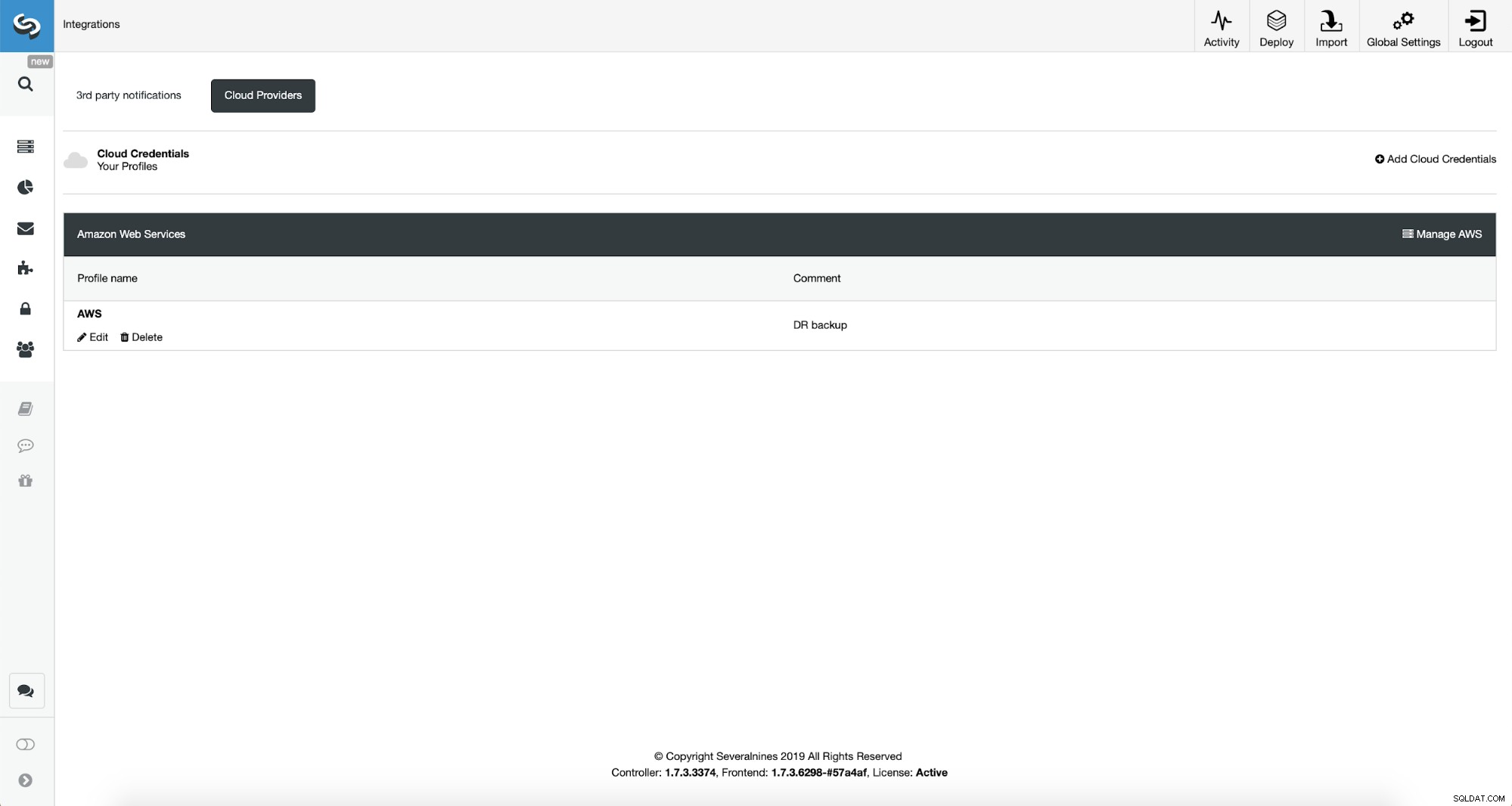
Sobald dies erledigt ist, können wir die soeben hinzugefügten Anmeldeinformationen sehen ClusterControl.
Nun fahren wir mit der Einrichtung des Backup-Zeitplans fort.
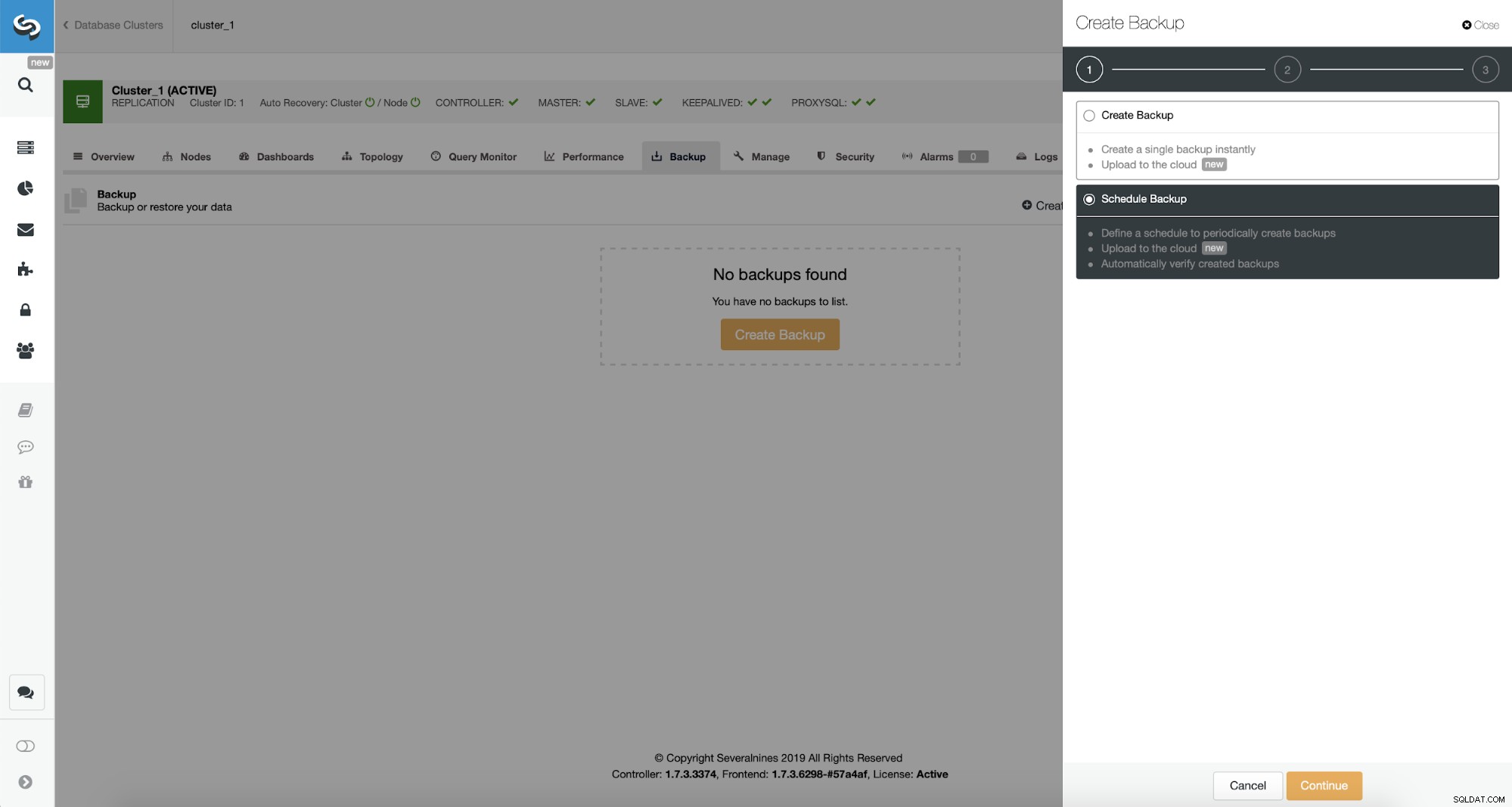
ClusterControl ermöglicht es Ihnen, eine Sicherung entweder sofort zu erstellen oder sie zu planen. Wir gehen mit der zweiten Option. Was wir wollen, ist den folgenden Zeitplan zu erstellen:
- Vollständige Sicherung einmal täglich erstellt
- Inkrementelle Backups werden alle 10 Minuten erstellt.
Die Idee hier ist wie folgt. Im schlimmsten Fall verlieren wir nur 10 Minuten des Verkehrs. Wenn das Rechenzentrum von außen nicht mehr verfügbar ist, aber intern funktionieren würde, könnten wir versuchen, Datenverluste zu vermeiden, indem wir 10 Minuten warten, das neueste inkrementelle Backup auf einen Laptop kopieren und es dann manuell an unsere DR-Datenbank senden, sogar per Telefon-Tethering und eine Mobilfunkverbindung, um einen ISP-Ausfall zu umgehen. Wenn wir die Daten für einige Zeit nicht aus dem alten Rechenzentrum abrufen können, soll dies die Anzahl der Transaktionen minimieren, die wir manuell in die DR-Datenbank zusammenführen müssen.
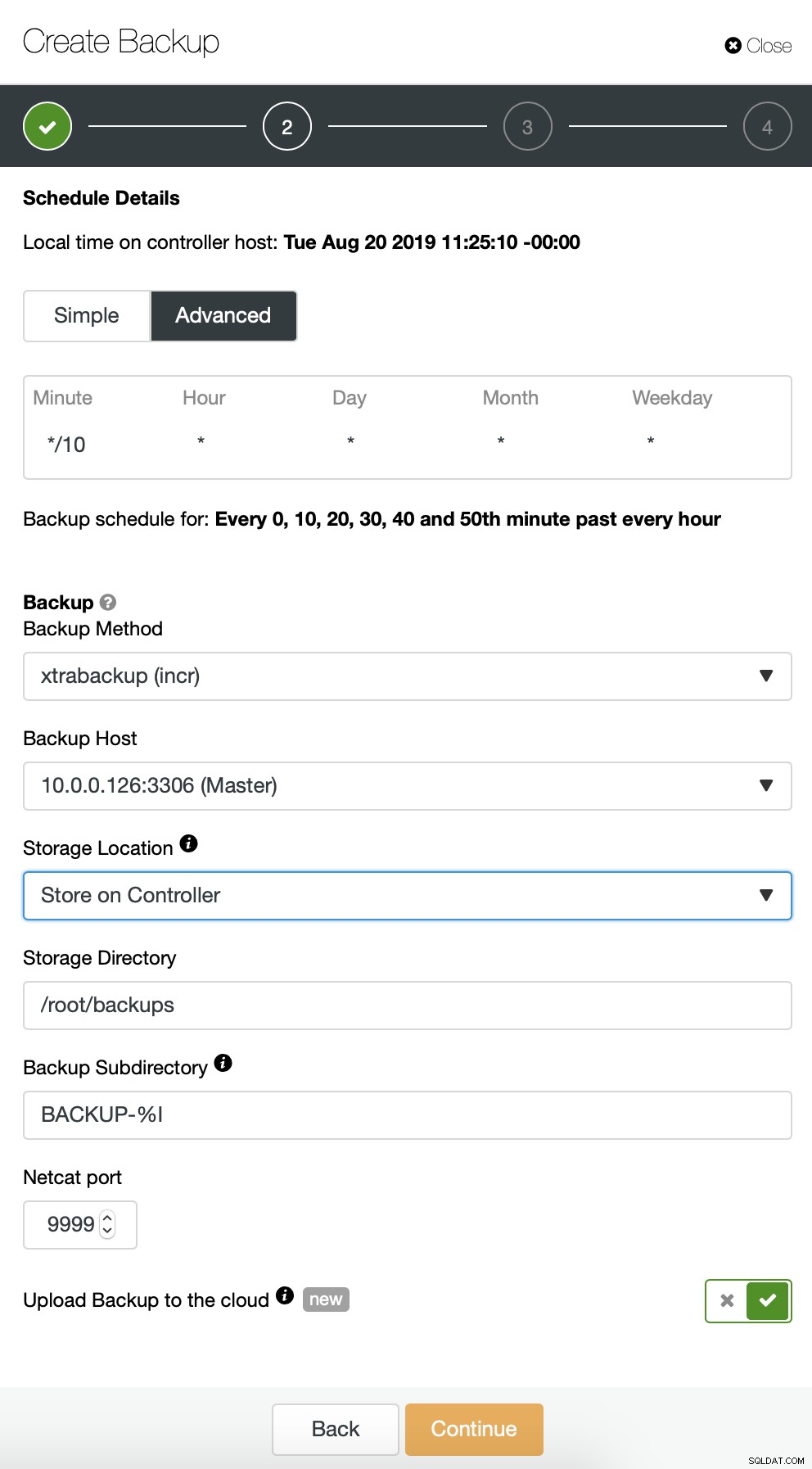
Wir beginnen mit einer vollständigen Sicherung, die täglich um 2:00 Uhr durchgeführt wird. Wir werden den Master verwenden, um das Backup zu erstellen, wir werden es auf dem Controller im Verzeichnis /root/backups/ speichern. Wir werden auch die Option „Backup in die Cloud hochladen“ aktivieren.
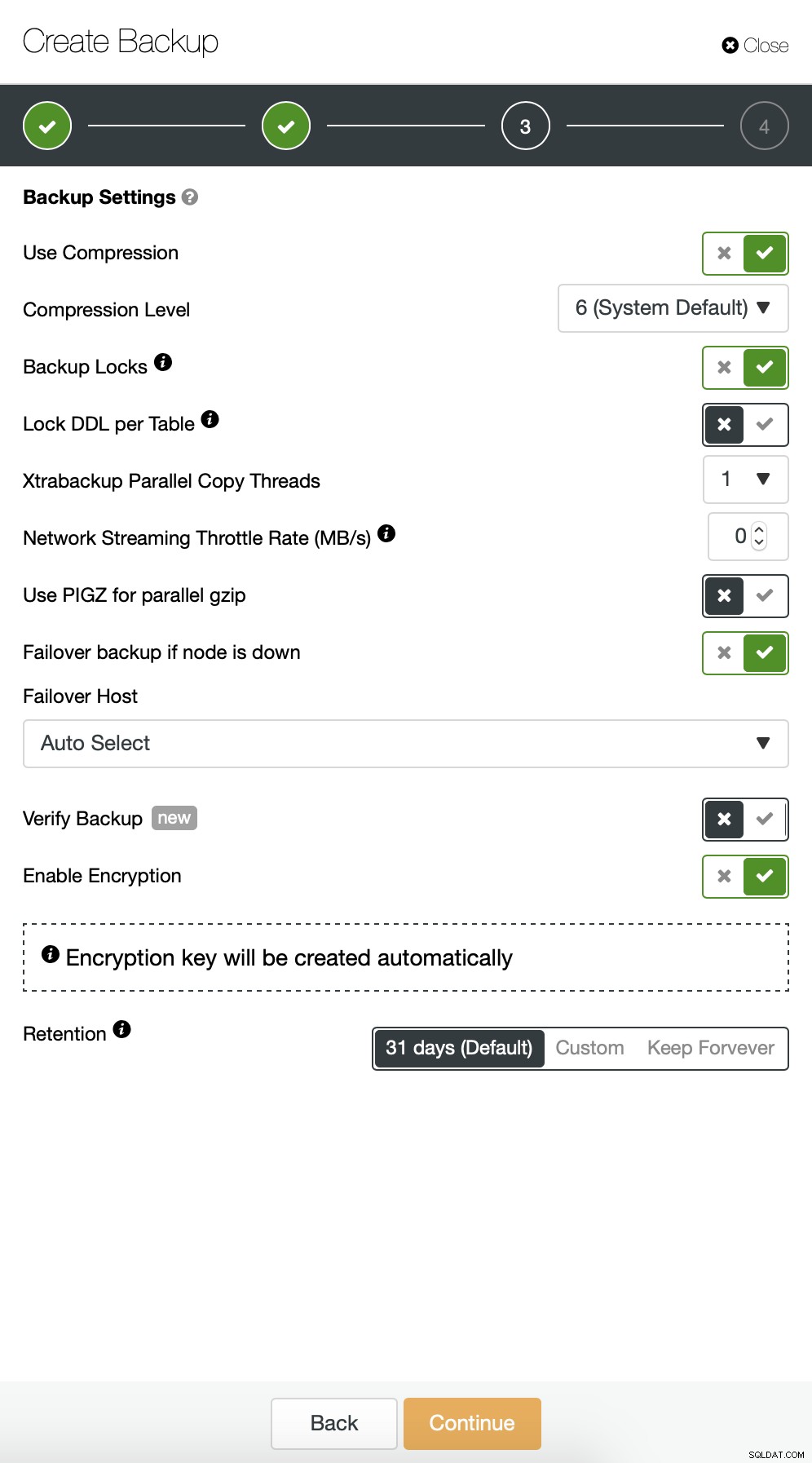
Als Nächstes möchten wir einige Änderungen an der Standardkonfiguration vornehmen. Wir haben uns für den automatisch ausgewählten Failover-Host entschieden (falls unser Master nicht verfügbar ist, verwendet ClusterControl einen anderen verfügbaren Knoten). Wir wollten auch die Verschlüsselung aktivieren, da wir unsere Backups über das Netzwerk senden werden.
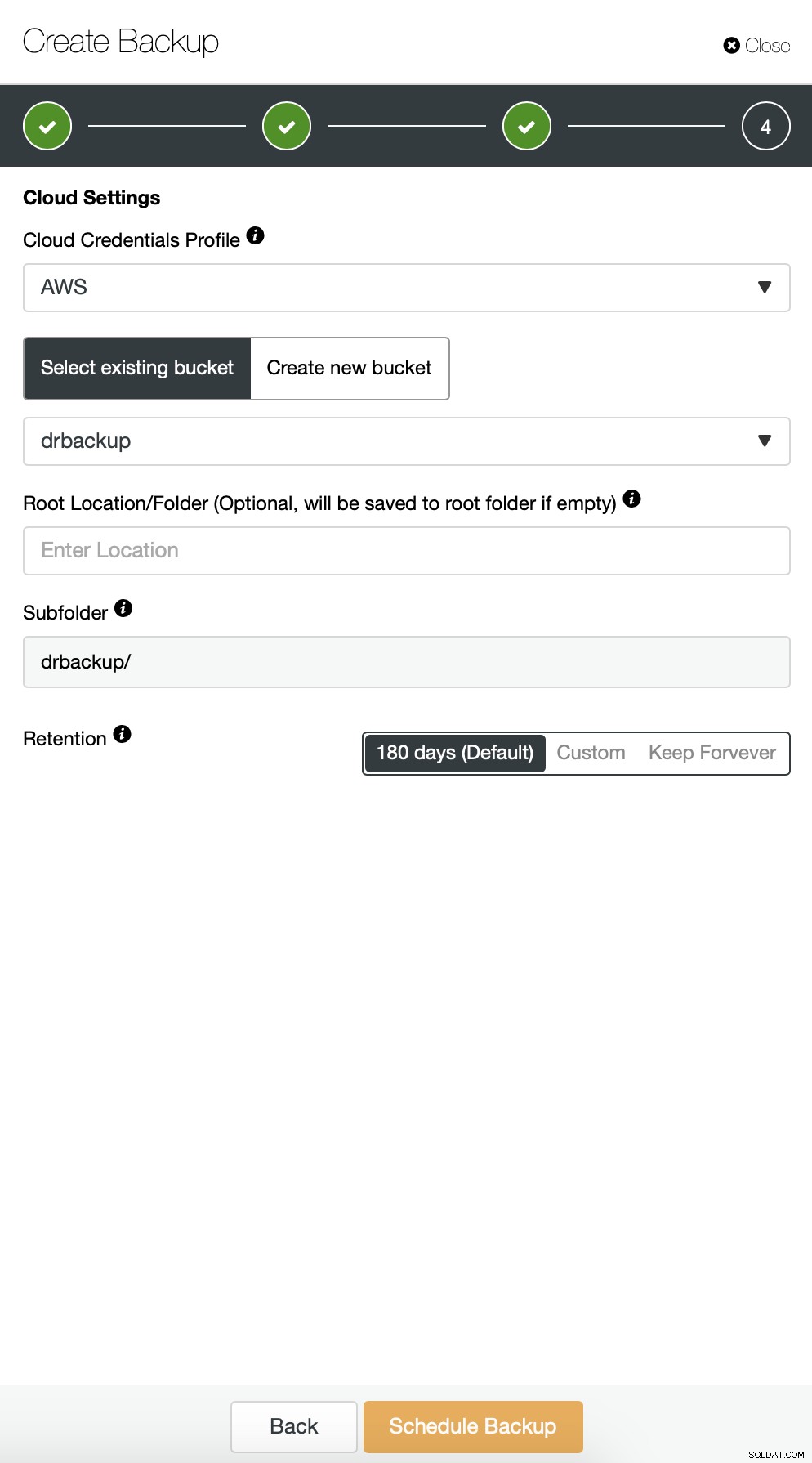
Dann müssen wir die Anmeldeinformationen auswählen, einen vorhandenen S3-Bucket auswählen oder einen erstellen bei Bedarf neu.
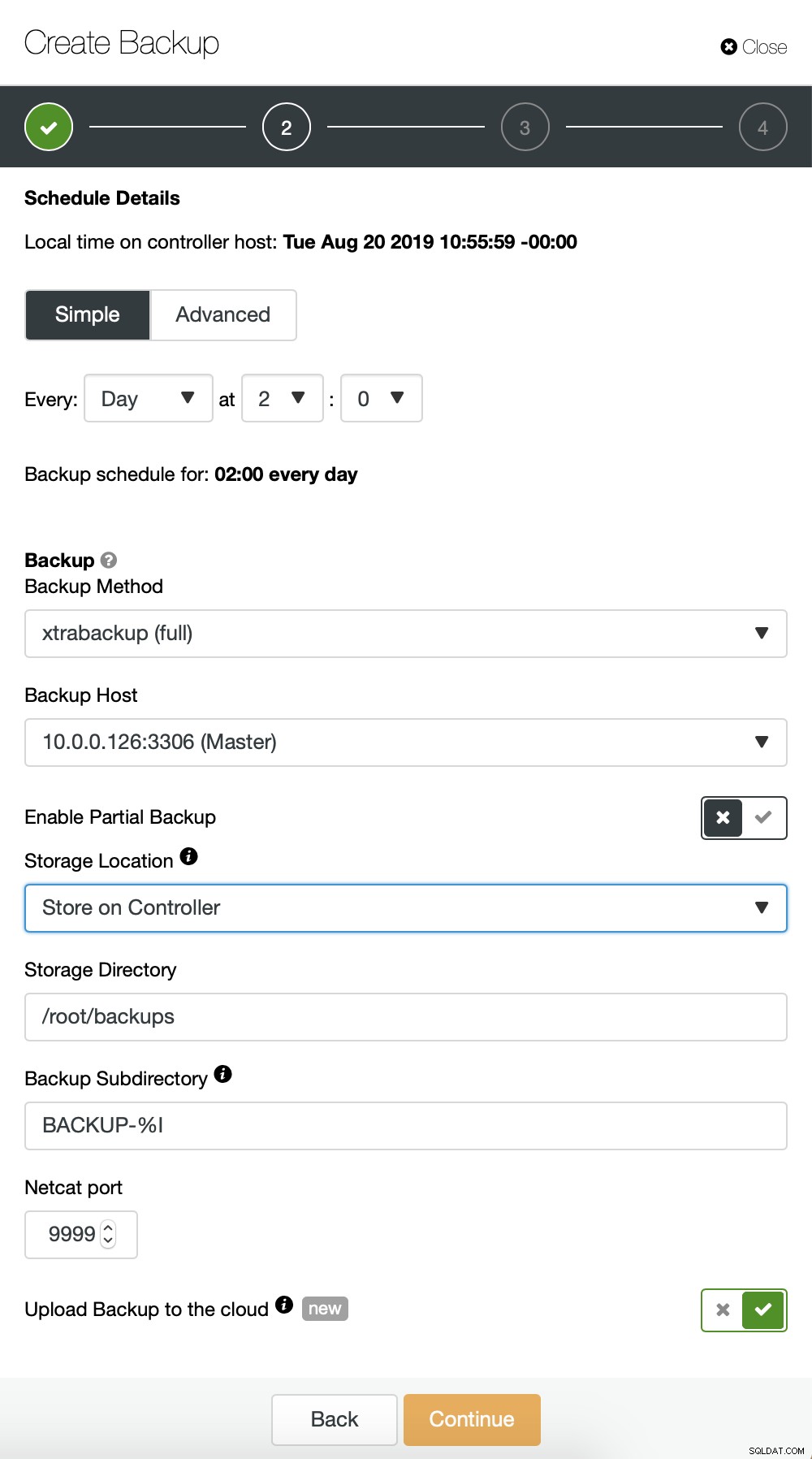
Wir wiederholen grundsätzlich den Prozess für die inkrementelle Sicherung, dieses Mal haben wir es verwendet den Dialog „Erweitert“, um die Sicherungen alle 10 Minuten auszuführen.
Der Rest der Einstellungen ist ähnlich, wir können auch den S3-Bucket wiederverwenden.
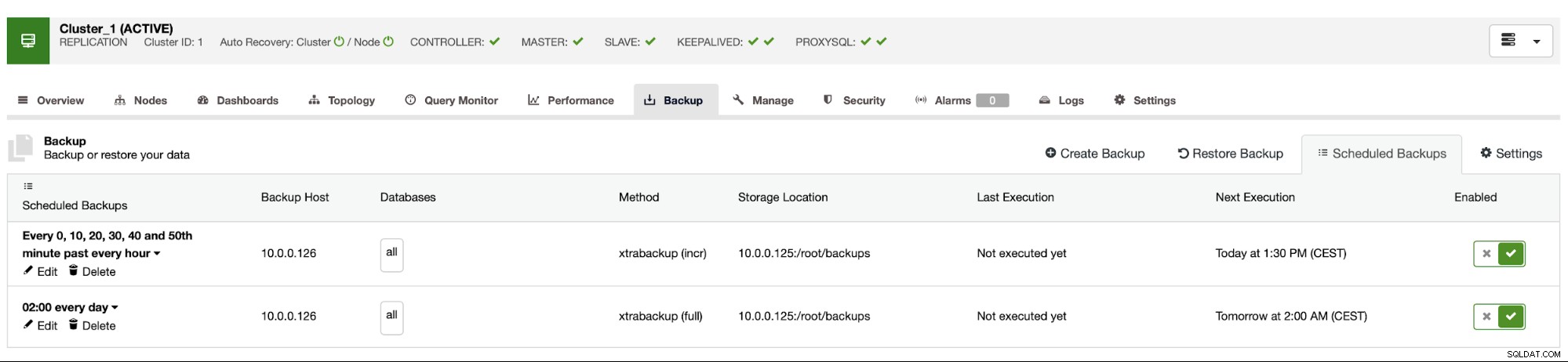
Der Backup-Zeitplan sieht wie oben aus. Wir müssen die vollständige Sicherung nicht manuell starten, ClusterControl führt die inkrementelle Sicherung wie geplant durch und wenn es feststellt, dass keine vollständige Sicherung verfügbar ist, führt es eine vollständige Sicherung anstelle der inkrementellen durch.
Mit einem solchen Setup können wir mit Sicherheit sagen, dass wir die Daten auf jedem externen System mit 10-Minuten-Granularität wiederherstellen können.
Manuelle Backup-Wiederherstellung
Falls Sie das Backup auf der Disaster-Recovery-Instanz wiederherstellen müssen, müssen Sie einige Schritte ausführen. Wir empfehlen dringend, diesen Prozess von Zeit zu Zeit zu testen, um sicherzustellen, dass er richtig funktioniert und Sie in der Lage sind, ihn auszuführen.
Zuerst müssen wir das AWS-Befehlszeilentool auf unserem Zielserver installieren:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userDann müssen wir es mit den richtigen Anmeldeinformationen konfigurieren:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonWir können jetzt testen, ob wir Zugriff auf die Daten in unserem S3-Bucket haben:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Jetzt müssen wir die Daten herunterladen. Wir werden ein Verzeichnis für die Backups erstellen – denken Sie daran, dass wir den gesamten Backup-Satz herunterladen müssen – beginnend mit einem vollständigen Backup bis zum letzten inkrementellen Backup, das wir anwenden möchten.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Nun gibt es zwei Möglichkeiten. Wir können Backups entweder einzeln herunterladen:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256Wir können auch, insbesondere wenn Sie einen engen Rotationsplan haben, alle Inhalte des Buckets mit dem synchronisieren, was wir lokal auf dem Server haben:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Wie Sie sich erinnern, sind die Backups verschlüsselt. Wir müssen einen Verschlüsselungsschlüssel haben, der in ClusterControl gespeichert ist. Stellen Sie sicher, dass Sie die Kopie an einem sicheren Ort außerhalb des Hauptrechenzentrums aufbewahren. Wenn Sie es nicht erreichen können, können Sie keine Sicherungen entschlüsseln. Den Schlüssel finden Sie in der ClusterControl-Konfiguration:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='Es ist mit base64 codiert, daher müssen wir es zuerst decodieren und in der Datei speichern, bevor wir mit der Entschlüsselung des Backups beginnen können:
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | openssl enc -base64 -d> pass
Jetzt können wir diese Datei wiederverwenden, um Backups zu entschlüsseln. Nehmen wir fürs Erste an, dass wir eine vollständige und zwei inkrementelle Sicherungen durchführen.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/Wir haben die Daten entschlüsselt, jetzt müssen wir mit der Einrichtung unseres MySQL-Servers fortfahren. Idealerweise sollte dies genau die gleiche Version sein wie auf den Produktivsystemen. Wir werden Percona Server für MySQL verwenden:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Nichts Komplexes, nur normale Installation. Sobald es hochgefahren und bereit ist, müssen wir es stoppen und den Inhalt seines Datenverzeichnisses entfernen.
service mysql stop
rm -rf /var/lib/mysql/*Um das Backup wiederherzustellen, benötigen wir Xtrabackup - ein Tool, das CC verwendet, um es zu erstellen (zumindest für Perona und Oracle MySQL verwendet MariaDB MariaBackup). Wichtig ist, dass dieses Tool in der gleichen Version wie auf den Produktionsservern installiert ist:
apt install percona-xtrabackup-24Das ist alles, was wir vorbereiten müssen. Jetzt können wir mit der Wiederherstellung des Backups beginnen. Bei inkrementellen Backups ist es wichtig zu bedenken, dass Sie diese vorbereiten und zusätzlich zum Basis-Backup anwenden müssen. Auch eine Basissicherung muss vorbereitet werden. Es ist wichtig, die Vorbereitung mit der Option „--apply-log-only“ auszuführen, um zu verhindern, dass xtrabackup die Rollback-Phase ausführt. Andernfalls können Sie die nächste inkrementelle Sicherung nicht anwenden.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/Im letzten Befehl haben wir xtrabackup erlaubt, das Rollback nicht abgeschlossener Transaktionen auszuführen - wir werden danach keine inkrementellen Backups mehr anwenden. Jetzt ist es an der Zeit, das Datenverzeichnis mit dem Backup zu füllen, MySQL zu starten und zu sehen, ob alles wie erwartet funktioniert:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Wie Sie sehen, ist alles gut. MySQL wurde korrekt gestartet und wir konnten darauf zugreifen (und die Daten sind da!). Wir haben es erfolgreich geschafft, unsere Datenbank an einem separaten Ort wieder zum Laufen zu bringen. Die benötigte Gesamtzeit hängt streng von der Größe der Daten ab - wir mussten Daten von S3 herunterladen, entschlüsseln und dekomprimieren und schließlich das Backup vorbereiten. Dennoch ist dies eine sehr kostengünstige Option (Sie müssen nur für S3-Daten bezahlen), die Ihnen eine Option für die Geschäftskontinuität bietet, falls eine Katastrophe eintritt.