Ein Datenbank-Load-Balancer oder Datenbank-Reverse-Proxy verteilt die eingehende Datenbank-Arbeitslast auf mehrere Datenbankserver, die dahinter laufen. Die Ziele von Datenbank-Load-Balancern bestehen darin, einen einzelnen Datenbankendpunkt für Anwendungen bereitzustellen, mit denen eine Verbindung hergestellt werden kann, den Abfragedurchsatz zu erhöhen, die Latenz zu minimieren und die Ressourcennutzung der Datenbankserver zu maximieren.
Es gibt zwei Arten der Topologie des Datenbank-Load-Balancers:
- Zentralisierte Topologie
- Verteilte Topologie
In diesem Blogbeitrag werden wir beide Topologien behandeln und einige Vor- und Nachteile jedes Setups verstehen. Wäre es auch möglich, beide Topologien miteinander zu mischen?
Zentralisierte Topologie
In einer zentralisierten Einrichtung befindet sich ein Reverse-Proxy zwischen der Daten- und der Präsentationsebene, wie im folgenden Diagramm dargestellt:
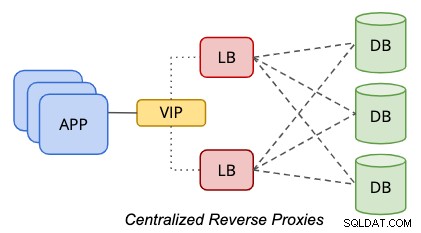
Um einen Single-Point-of-Failure zu eliminieren, muss man setzen zwei oder mehr Load-Balancer-Knoten für Redundanzzwecke einrichten. Wenn Ihre Anwendung mehrere Datenbankendpunkte verarbeiten kann, der Anwendungs- oder Datenbanktreiber beispielsweise Zustandsprüfungen durchführen kann, wenn der Load Balancer für die Abfrageverarbeitung fehlerfrei ist, können Sie wahrscheinlich den Teil der virtuellen IP-Adresse überspringen. Andernfalls sollten beide Load Balancer-Knoten mit einem gemeinsamen Hostnamen oder einer virtuellen IP-Adresse verbunden werden, um den Datenbankclients Transparenz zu bieten, wenn sie nur einen einzigen Datenbankendpunkt für den Zugriff auf die Datenebene verwenden müssen. Die Verwendung von DNS oder Host-Mapping ist auch möglich, wenn Sie die Verwendung virtueller IP-Adressen überspringen möchten.
Dieser Tier-basierte Ansatz ist aufgrund seiner unabhängigen statischen Hostplatzierung viel einfacher zu verwalten. Es ist sehr unwahrscheinlich, dass die Load-Balancer-Ebene horizontal skaliert wird (Hinzufügen weiterer Knoten), da sie eine solide Grundlage in Bezug auf Ausfallsicherheit, Redundanz und Transparenz für die Anwendungsebene bietet. Wahrscheinlich müssen Sie den Host hochskalieren (dem Host mehr Ressourcen hinzufügen), was in der Regel in langer Zukunft der Fall sein wird, nachdem die Workloads des Load Balancers mit dem Wachstum Ihres Unternehmens anspruchsvoller geworden sind.
Diese Topologie erfordert eine zusätzliche Ebene und Hosts, was in einer Bare-Metal-Infrastruktur mit physischen Servern kostspielig sein kann. Dieses Setup ist in einer Cloud- oder virtuellen Umgebung einfacher zu verwalten, wo Sie die Flexibilität haben, eine zusätzliche Ebene zwischen der Anwendungs- und der Datenbankebene hinzuzufügen, ohne dass Sie zu viele Kosten für die physische Infrastruktur wie Strom, Rack-Platz und Netzwerkkosten zahlen müssen.
Verteilte Topologie
In einem verteilten Topologie-Setup befinden sich die Load Balancer innerhalb der Präsentationsschicht (Anwendungs- oder Webserver), wie durch das folgende Diagramm vereinfacht:
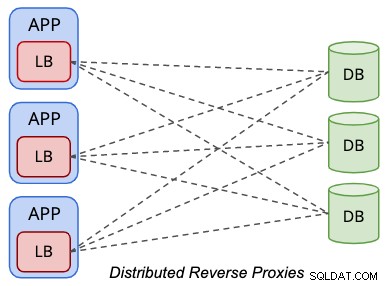
Anwendungen behandeln den Datenbanklastenausgleich ähnlich wie einen lokalen Datenbankserver, wobei die Load Balancer wird zur Darstellung der entfernten Datenbanken aus Sicht der Anwendung. Üblicherweise überwacht der Load Balancer die lokale Netzwerkschnittstelle wie 127.0.0.1 oder „localhost“, wodurch der Datenbank-Endpunkt-Datenbankhost für die Anwendungen optimiert wird.
Einer der Vorteile der Ausführung in dieser Topologie besteht darin, dass Sie keine zusätzlichen Hosts für Lastenausgleichszwecke benötigen. Durch die Kombination der Load-Balancer-Ebene innerhalb der Präsentationsebene konnten wir mindestens zwei Hosts einsparen. In einer Bare-Metal-Umgebung können Sie mit dieser Topologie im Laufe der Jahre möglicherweise viel Geld sparen. Im Allgemeinen ist die Workload des Lastenausgleichs im Vergleich zu Datenbank- oder Anwendungsworkloads weitaus weniger anspruchsvoll, wodurch es gerechtfertigt ist, dieselben Hardwareressourcen mit den Anwendungen zu teilen.
Wenn Sie sich zusammen mit dem Anwendungsserver befinden, bringen Sie den Reverse-Proxy näher an die Anwendung und eliminieren den Single-Point-of-Failure. Dies kann die Anwendungsleistung erheblich verbessern, wenn Sie eine geografische Trennung zwischen der Anwendung und der Datenebene haben, insbesondere für Datenbank-Load-Balancer, die das Zwischenspeichern von Ergebnismengen wie ProxySQL und MaxScale unterstützen. Andererseits entspricht die Anzahl der Datenbank-Load-Balancer im Allgemeinen der Anzahl der Anwendungsknoten, was bedeutet, dass bei einer Skalierung der Anwendungsebene die Anzahl der Datenbank-Load-Balancer zunimmt, was möglicherweise die Leistung für den Datenbankzustand beeinträchtigen kann Scheckdienst. Beachten Sie, dass die Zustandsprüfungen des Load Balancers etwas geschwätziger sind, da er dafür verantwortlich ist, mit dem korrekten Status der Datenbankknoten Schritt zu halten.
Mit Hilfe von IT-Infrastruktur-Automatisierungstools wie Chef, Puppet und Ansible zusammen mit den Container-Orchestrierungstools ist es keine unmögliche Aufgabe mehr, die Bereitstellung und Verwaltung mehrerer Load-Balancer-Instanzen für diese Topologie zu automatisieren. Es wird jedoch eine weitere Lernkurve für das Betriebsteam geben, um kampferprobte, produktionstaugliche Bereitstellungs- und Verwaltungsrichtlinien zu entwickeln, um die übermäßige Arbeit beim Umgang mit vielen Load Balancer-Knoten zu reduzieren. Verpassen Sie nicht alle wichtigen Verwaltungsaspekte für Datenbank-Load-Balancer wie Sicherung/Wiederherstellung, Upgrade/Downgrade, Konfigurationsverwaltung, Dienststeuerung, Fehlerverwaltung und so weiter.
Die verteilte Topologie kann für einige unterstützte Datenbank-Load-Balancer wie ProxySQL mit der zentralisierten Topologie gemischt werden, wie im folgenden Diagramm dargestellt:
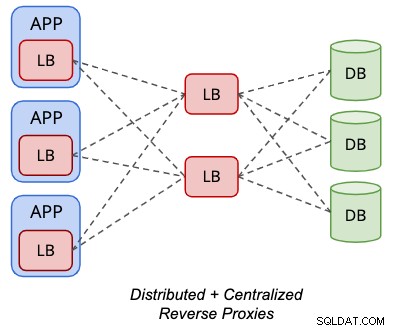
Die Backend-"Server" einer ProxySQL-Instanz können ein anderer Satz von ProxySQL sein Knoten statt. Bei dieser Konfiguration ist keine virtuelle IP-Adresse für den Einzelendpunktzugriff auf die Datenbankknoten erforderlich, da die lokale ProxySQL-Instanz, die lokal auf dem Anwendungsserver gehostet wird, vom Anwendungsstandpunkt aus der Einzelendpunktzugriff ist.
Dies erfordert jedoch zwei Versionen von Load-Balancer-Konfigurationen – eine, die sich auf der Anwendungsebene befindet, und eine andere, die sich auf den Load-Balancer-Ebenen befindet. Es erfordert auch mehr Hosts, abgesehen von der Notwendigkeit, etwas über virtuelle IP-Adresstechnologie, IP-Failover usw. zu lernen. In dieser Topologie verschmelzen die Vor- und Nachteile sowohl verteilter als auch zentralisierter Setups.
Fazit
Jede Topologie hat ihre eigenen Vor- und Nachteile und muss von Anfang an gut geplant werden. Diese frühe Entscheidung ist entscheidend und kann langfristig die Leistung, Skalierbarkeit, Zuverlässigkeit und Verfügbarkeit Ihrer Anwendung enorm beeinflussen.



