MariaDB-Replikation ist eine der beliebtesten Hochverfügbarkeitslösungen für MariaDB und wird häufig von Top-Unternehmen wie Booking.com und Google verwendet. Es ist sehr einfach einzurichten, mit einigen Kompromissen bei der laufenden Wartung wie Software-Upgrades, Schemaänderungen, Topologieänderungen, Failover und Wiederherstellung, die schon immer schwierig waren. Mit dem richtigen Toolset sollten Sie die Topologie jedoch problemlos handhaben können. In diesem Blogbeitrag werden wir uns einige Tipps zur effizienten Überwachung der MariaDB-Replikation mit ClusterControl ansehen.
Den Topologie-Viewer verwenden
Ein Replikations-Setup besteht aus einer Reihe von Rollen. Ein Knoten in einer Replikationskonfiguration könnte sein:
- Meister - Der primäre Autor/Leser.
- Backup-Master – Ein schreibgeschützter Slave mit halbsynchroner Replikation, ausschließlich für Master-Redundanz.
- Zwischenmaster - Replizieren von einem Master, während andere Slaves von diesem Knoten aus replizieren.
- Binlog-Server - Sammeln/speichern Sie nur Binlogs, ohne Daten zu liefern.
- Slave – Von einem Master replizieren und üblicherweise als schreibgeschützt eingestellt.
- Multisource-Slave – Replikation von mehreren Mastern.
Jede Rolle hat ihre eigene Verantwortung und Einschränkung, und man muss die richtige Topologie verstehen, wenn man mit den Datenbankknoten umgeht. Dies gilt auch für die Anwendung, bei der die Anwendung zu einem bestimmten Zeitpunkt nur auf den Master-Knoten schreiben muss. Daher ist es wichtig, einen Überblick darüber zu haben, welcher Knoten welche Rolle innehat, damit wir unsere Datenbank nicht vermasseln.
In ClusterControl kann Ihnen der Topology Viewer einen Überblick über die Replikationstopologie und ihren Status geben, wie im folgenden Screenshot gezeigt:
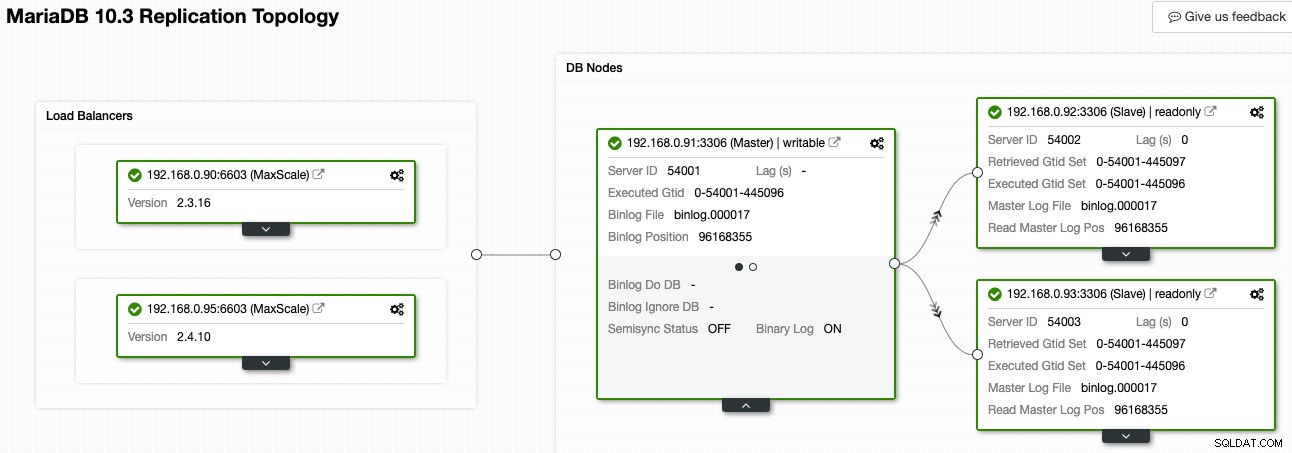
ClusterControl versteht die MariaDB-Replikation und ist in der Lage, die Topologie mit dem korrekten Replikationsdatenfluss zu visualisieren, wie durch die Pfeile dargestellt, die auf die Slave-Knoten zeigen. Wir können in unserem Replikations-Setup leicht unterscheiden, welcher Knoten Master, Slaves und Load Balancer (MaxScale) ist. Das grüne Kästchen zeigt an, dass alle wichtigen Dienste wie erwartet mit der zugewiesenen Rolle ausgeführt werden.
Betrachten Sie den folgenden Screenshot, in dem einige unserer Knoten Probleme haben:
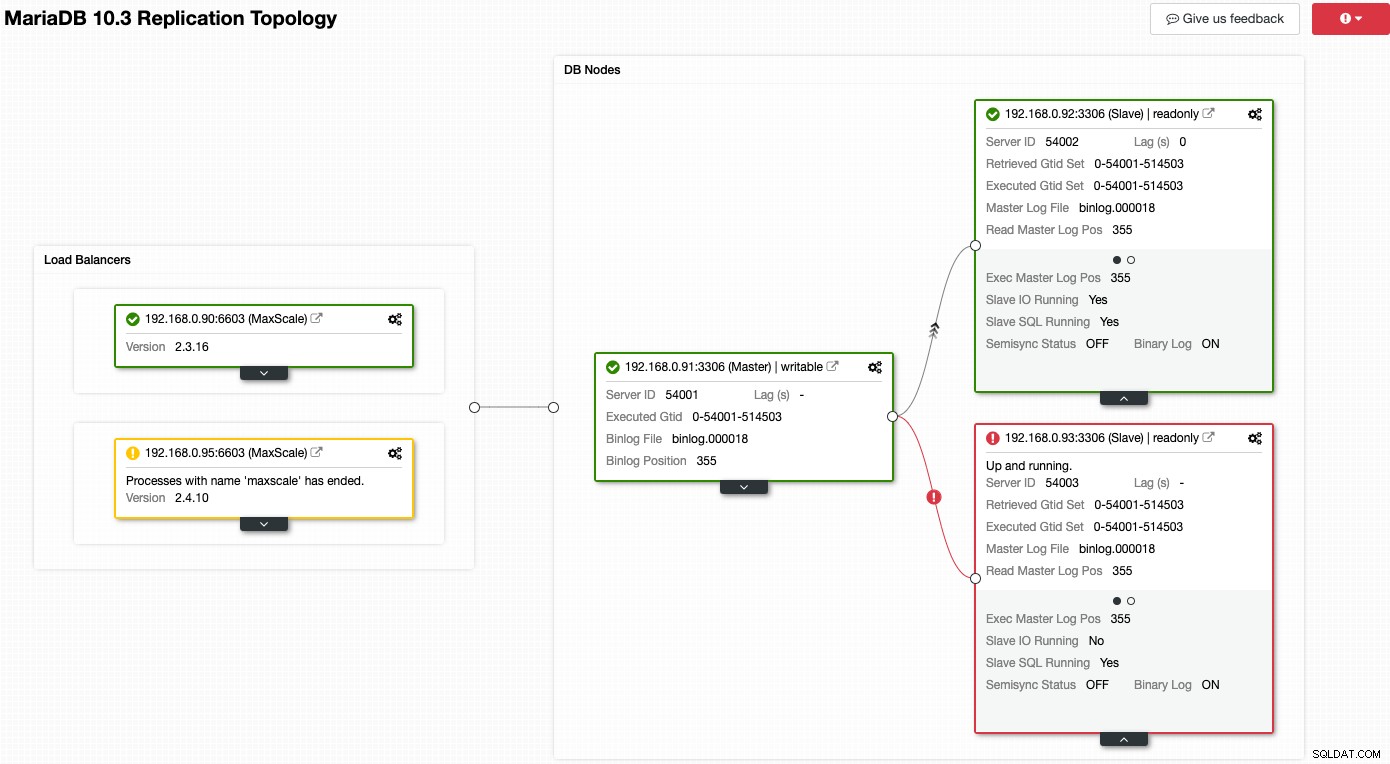
ClusterControl teilt Ihnen sofort mit, was mit der aktuellen Topologie nicht stimmt. Einer der Slaves (rotes Kästchen) zeigt „Slave IO Running“ als Nein an, um auf ein Verbindungsproblem hinzuweisen, das vom Master repliziert werden muss. Während das gelbe Kästchen anzeigt, dass unser MaxScale-Dienst nicht läuft. Wir können auch feststellen, dass die MaxScale-Versionen für beide Knoten nicht identisch sind. Sie können Verwaltungsaufgaben auch ausführen, indem Sie direkt auf das Zahnradsymbol (oben rechts in jedem Kästchen) klicken, wodurch das Risiko verringert wird, einen falschen Knoten auszuwählen.
Replikationsverzögerung
Dies ist das Wichtigste, wenn Sie sich auf die Konsistenz der Datenreplikation verlassen. Eine Replikationsverzögerung tritt auf, wenn die Slaves nicht mit den Aktualisierungen auf dem Master Schritt halten können. Nicht angewendete Änderungen sammeln sich in den Relaisprotokollen der Slaves an und die Version der Datenbank auf den Slaves weicht zunehmend von der des Masters ab.
In ClusterControl finden Sie das Replikationsverzögerungshistogramm unter Übersicht -> Replikationsverzögerung, wo ClusterControl ständig den Seconds_Behind_Master-Wert aus der Ausgabe von „SHOW SLAVE STATUS“ abtastet:
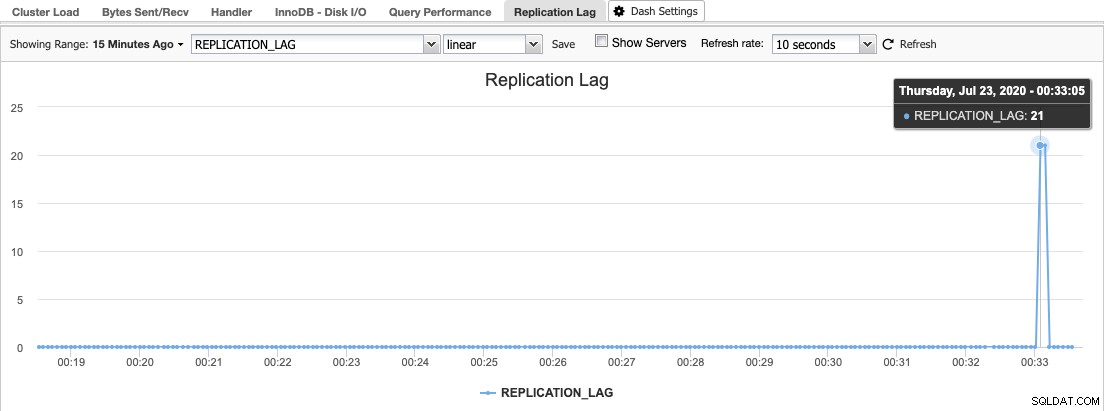
Eine Replikationsverzögerung tritt auf, wenn entweder der E/A-Thread oder der SQL-Thread die an ihn gestellten Anforderungen nicht bewältigen kann. Wenn der E/A-Thread leidet, bedeutet dies, dass die Netzwerkverbindung zwischen dem Master und seinen Slaves langsam ist oder Probleme hat. Sie sollten in Betracht ziehen, das slave_compressed_protocol zu aktivieren, um den Netzwerkverkehr zu komprimieren, oder Ihrem Netzwerkadministrator Bericht erstatten.
Wenn es sich um den SQL-Thread handelt, liegt das Problem wahrscheinlich an schlecht optimierten Abfragen, für deren Anwendung der Slave zu lange braucht. Möglicherweise gibt es Transaktionen mit langer Laufzeit oder zu viel E/A-Aktivität. Das Fehlen des Primärschlüssels in den Slave-Tabellen bei Verwendung des ROW- oder MIXED-Replikationsformats ist auch eine häufige Ursache für Verzögerungen in diesem Thread. Überprüfen Sie, ob die Master- und Slave-Versionen von Tabellen einen Primärschlüssel haben.
Einige weitere Tipps und Tricks finden Sie in diesem Blog-Beitrag, How to Reduce Replication Lag in Multi-Cloud Deployments.
Binär-/Relay-Protokollgröße
Es ist wichtig, die Festplattengröße der Binär- und Relaisprotokolle zu überwachen, da dies eine beträchtliche Menge an Speicherplatz auf jedem Knoten in einem Replikationscluster verbrauchen könnte. Üblicherweise würde man die Systemvariable "expire_logs_days" so setzen, dass binäre Protokolldateien nach einer bestimmten Anzahl von Tagen automatisch ablaufen, z. B. "expire_logs_days=7". Die Größe der Binärprotokolle hängt vollständig von der Anzahl der erstellten Binärereignisse (eingehende Schreibvorgänge) ab und wir wissen kaum, wie viel Speicherplatz es verbrauchen würde, bevor die Protokolle von MariaDB ablaufen. Denken Sie daran, wenn Sie log_slave_updates auf den Slaves aktivieren, wird die Größe der Protokolle fast verdoppelt, da sowohl Binär- als auch Relaisprotokolle auf demselben Server vorhanden sind.
Für ClusterControl können wir unter ClusterControl -> Einstellungen -> Schwellenwerte einen Schwellenwert für die Speicherplatznutzung festlegen, um eine Warnung und kritische Benachrichtigungen wie folgt zu erhalten:
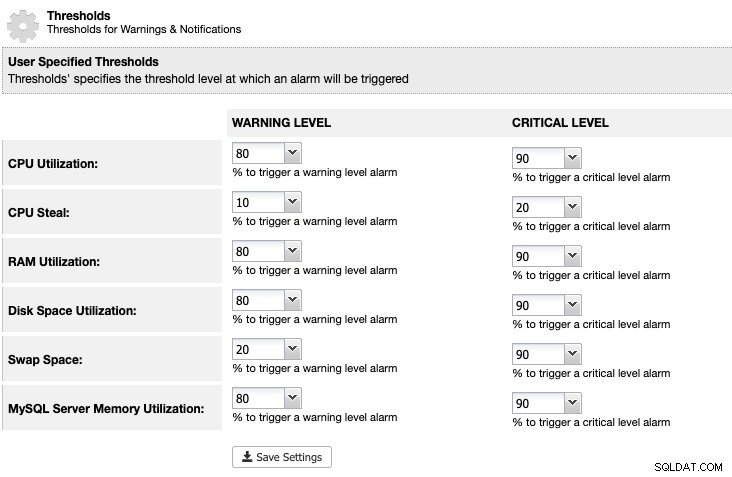
ClusterControl überwacht den gesamten Speicherplatz im Zusammenhang mit MariaDB-Diensten wie den Speicherort von MariaDB-Daten Verzeichnis, das Verzeichnis der Binärprotokolle und auch die Root-Partition. Wenn Sie den Schwellenwert erreicht haben, ziehen Sie in Betracht, die Binärprotokolle manuell zu löschen, indem Sie den Befehl PURGE BINARY LOGS verwenden, wie in diesem Artikel erklärt und besprochen.
Überwachungs-Dashboards aktivieren
ClusterControl bietet zwei Überwachungsoptionen zum Abtasten der Datenbankknoten – agentenlos oder agentenbasiert. Die Standardeinstellung ist agentenlos, wobei das Sampling über SSH in einem Nur-Pull-Mechanismus erfolgt. Für die agentenbasierte Überwachung muss ein Prometheus-Server ausgeführt werden und alle überwachten Knoten müssen mit mindestens drei Exportern konfiguriert sein:
- Prozessexporteur (Port 9011)
- Exporter für Knoten-/Systemmetriken (Port 9100)
- MySQL/MariaDB-Exporter (Port 9104)
Um das Dashboard für die agentenbasierte Überwachung zu aktivieren, muss man zu ClusterControl -> Dashboards -> Enable Agent Based Monitoring gehen. Nach der Aktivierung sehen Sie eine Reihe von Dashboards, die für unsere MariaDB-Replikation konfiguriert sind, was uns einen viel besseren Einblick in unser Replikations-Setup gibt. Der folgende Screenshot zeigt, was Sie für den Master-Knoten sehen würden:
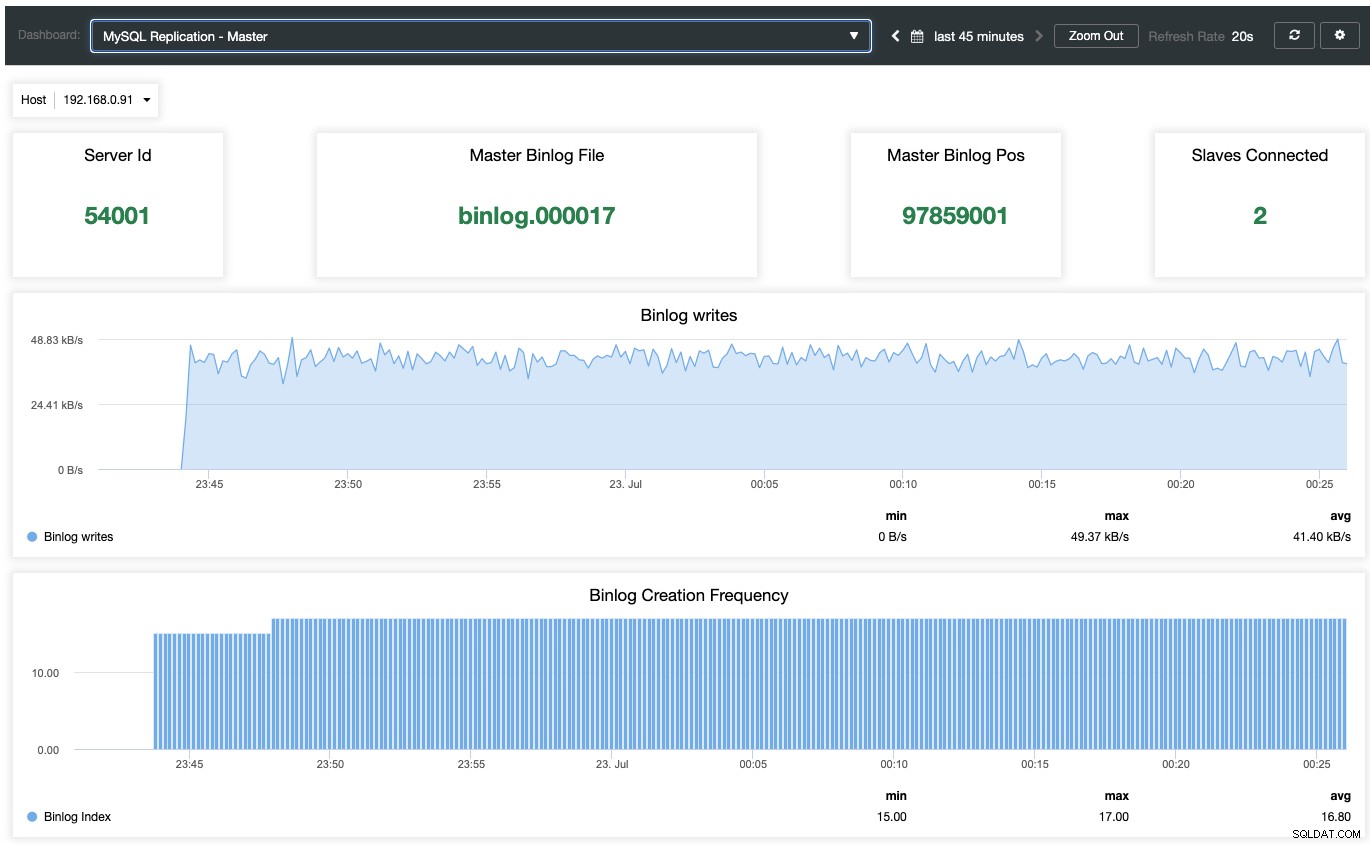
Abgesehen von MariaDB-Standardüberwachungs-Dashboards wie Allgemein, Caches und InnoDB-Metriken, Sie wird mit einem Replikations-Dashboard angezeigt. Für den Master-Knoten können wir viele nützliche Informationen über den Zustand des Masters, den Schreibdurchsatz und die Häufigkeit der Binlog-Erstellung erhalten.
Während für die Slaves alle wichtigen Zustände abgetastet und im folgenden Screenshot zusammengefasst werden. wenn alles grün ist, sind sie in guten händen:
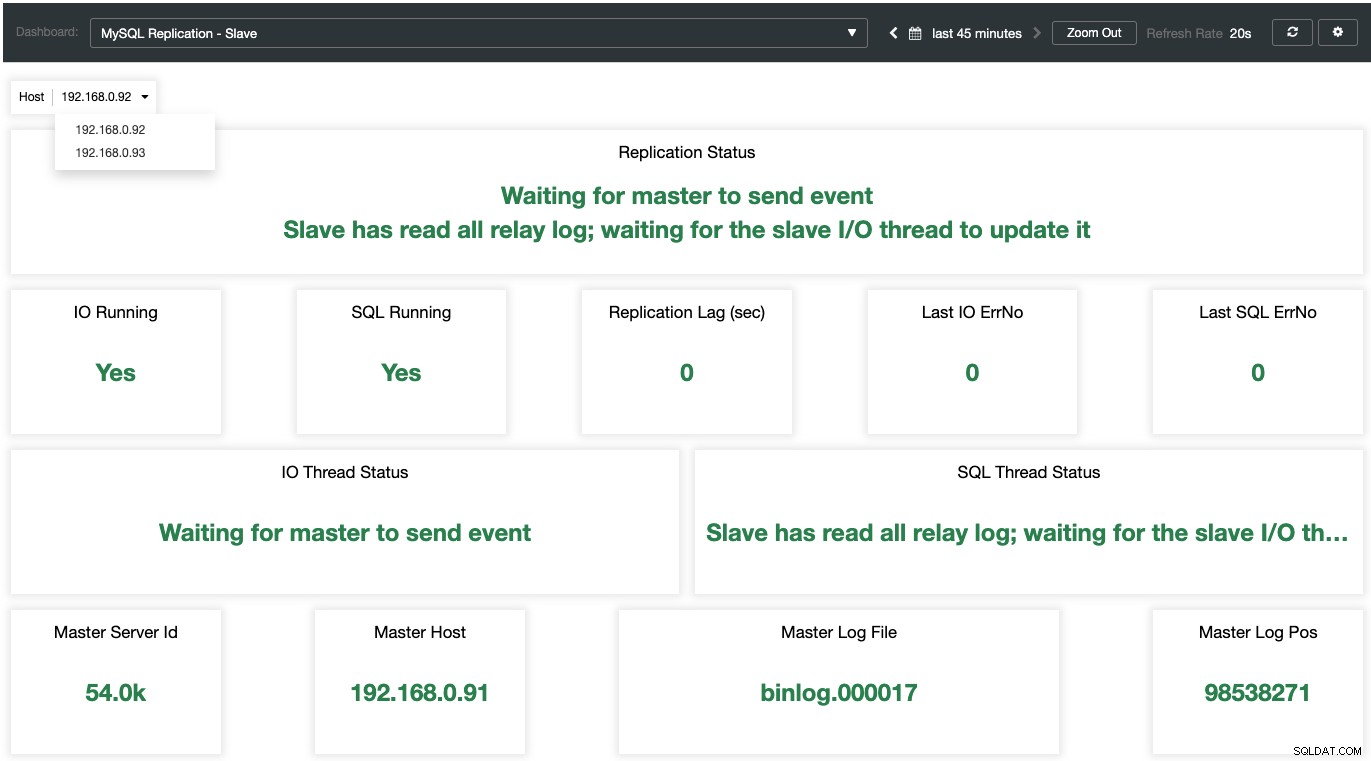
Das MariaDB-Fehlerprotokoll verstehen
MariaDB protokolliert seine wichtigen Ereignisse im Fehlerprotokoll, was nützlich ist, um zu verstehen, was mit dem Server vor sich ging, insbesondere vor, während und nach einer Topologieänderung. ClusterControl bietet eine zentralisierte Ansicht von Fehlerprotokollen unter ClusterControl -> Protokolle -> Systemprotokolle, indem es sie von jedem Datenbankknoten abruft. Sie klicken auf „Refresh Logs“, um einen Job auszulösen, um die neuesten Protokolle vom Server abzurufen.
Gesammelte Dateien werden in einer Navigationsbaumstruktur und einem Textbereich mit Syntaxhervorhebung zur besseren Lesbarkeit dargestellt:
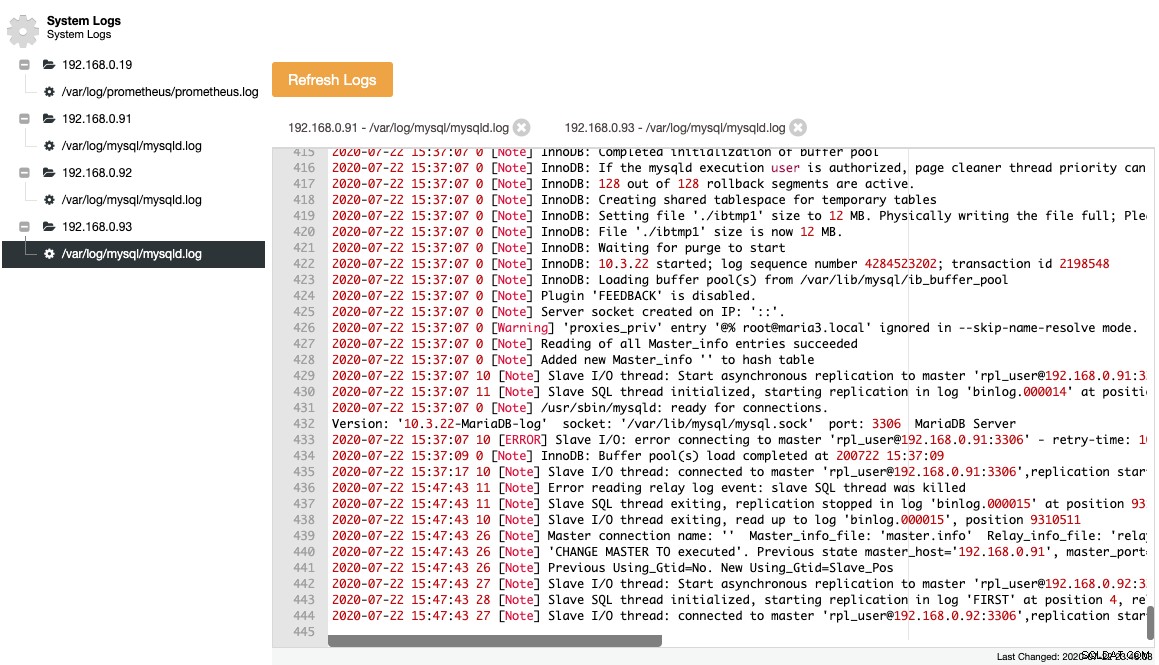
Aus dem obigen Screenshot können wir die Abfolge der Ereignisse verstehen und was mit diesem Knoten während eines Topologieänderungsereignisses passiert ist. Aus den letzten 12 Zeilen des obigen Fehlerprotokolls ging hervor, dass der Slave einen Fehler hatte, sobald er sich mit dem Master verbunden hatte, und die letzte binäre Protokolldatei und Position wurden im Protokoll aufgezeichnet, bevor er stoppte. Dann wurde ein neuerer CHANGE MASTER-Befehl mit GTID-Informationen ausgeführt, wie in der Zeile "Previous Using_Gtid=No. New Using_Gtid=Slave_Pos" gezeigt, und dann wird die Replikation wie gewünscht fortgesetzt.
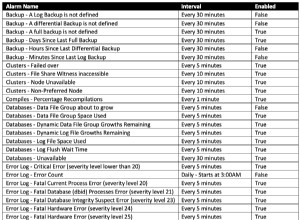
MariaDB-Alarm und Benachrichtigungen
Die Überwachung ist ohne Warnungen und Benachrichtigungen unvollständig. Alle von ClusterControl generierten Ereignisse und Alarme können an die E-Mail oder andere unterstützte Tools von Drittanbietern gesendet werden. Für E-Mail-Benachrichtigungen kann konfiguriert werden, ob die Art der Ereignisse sofort zugestellt, ignoriert oder verarbeitet wird (ein täglich zusammengefasster Bericht):

Für alle Ereignisse mit kritischem Schweregrad wird empfohlen, alles auf „Zustellen“ zu setzen, damit Sie die Benachrichtigungen so schnell wie möglich erhalten. Stellen Sie „Digest“ auf Warnereignisse ein, damit Sie sich über den Zustand und Zustand des Clusters im Klaren sind.
Sie können Ihre bevorzugten Kommunikations- und Messaging-Tools mit ClusterControl integrieren, indem Sie die Benachrichtigungsverwaltungsfunktion unter ClusterControl -> Integrationen -> Benachrichtigungen von Drittanbietern verwenden. ClusterControl kann Alarme und Ereignisse an PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow oder alle von Benutzern registrierten Webhooks senden.
Der folgende Screenshot zeigt, dass alle kritischen Ereignisse an den konfigurierten Telegrammkanal für unseren MariaDB 10.3-Replikationscluster gepusht werden:

ClusterControl unterstützt auch die Chatbot-Integration, bei der Sie mit dem Controller-Dienst über den s9s-Client direkt von Ihrem Messaging-Tool aus interagieren können, wie in diesem Blog-Beitrag gezeigt:Automate Your Database with CCBot:ClusterControl Hubot Integration.
Fazit
ClusterControl bietet ein komplettes Set proaktiver Überwachungstools für Ihre Datenbank-Cluster. Verwenden Sie ClusterControl, um Ihre MariaDB-Replikationseinrichtung zu überwachen, da die meisten Überwachungsfunktionen in der Community Edition kostenlos verfügbar sind. Verpassen Sie diese nicht!