Es gibt so viel, was man über Geschichte und Bedeutung sagen kann. Geschichte eines Landes, einer Zivilisation, eines jeden von uns. Ich liebe Zitate und mag dieses von Teddy Roosevelt (cooler Typ):
Je mehr Sie über die Vergangenheit wissen, desto besser sind Sie für die Zukunft gerüstet.Warum werde ich in einem Blog über SQL Server poetisch (oder versuche es) über die Geschichte? Denn auch der Verlauf in SQL Server ist wichtig. Wenn ein Leistungsproblem in SQL Server besteht, ist es ideal, das Problem live zu beheben, aber in einigen Fällen können historische Informationen einen schlagenden Beweis oder zumindest einen Ausgangspunkt liefern. Eine großartige Quelle für historische Informationen in SQL Server ist das ERRORLOG. Ich habe in meinem ursprünglichen Beitrag Performance Issues:The First Encounter erwähnt, dass das ERRORLOG früher ein nachträglicher Einfall für mich war. Nicht mehr. Bei Client-Audits erfassen wir immer die ERRORLOGs, und obwohl wir über Warnungen mit hohem Schweregrad benachrichtigt werden (die in das Protokoll geschrieben werden), ist es nicht ungewöhnlich, andere interessante Informationen im Protokoll zu finden. Wir bereiten uns auf die Zukunft vor, indem wir die historischen Informationen in den Protokollen verwenden; Die Informationen können uns dabei helfen, ein Problem oder ein potenzielles Problem zu beheben, bevor es zu einer Katastrophe kommt.
Anzeigen des FEHLERLOGS
Zunächst werden wir einige Optionen zum Anzeigen des ERROLOG überprüfen. Wenn ich mit einer Instanz verbunden bin, navigiere ich normalerweise über SSMS zu ihr (Verwaltung | SQL Server-Protokolle, klicken Sie mit der rechten Maustaste auf ein Protokoll und wählen Sie SQL Server-Protokoll anzeigen). Von diesem Fenster aus kann ich einfach durch das Protokoll blättern oder die Filter- oder Suchoptionen verwenden, um die Ergebnismenge einzugrenzen. Ich kann auch mehrere Dateien anzeigen, indem ich sie im linken Bereich auswähle.
Wenn ich mir Daten ansehe, die bei einem unserer Gesundheitsaudits erfasst wurden, öffne ich einfach die Protokolldateien in einem Texteditor und überprüfe sie (ich habe die Möglichkeit, in den Viewer zu gehen und sie auch zu laden). Die Protokolldateien befinden sich im Protokollordner (Standardspeicherort:C:\Programme\Microsoft SQL Server\MSSQL12.SQL2014\MSSQL\Log), falls ich sie mir jemals auf dem Server ansehen wollte. Viele von Ihnen ziehen es vielleicht vor, das Protokoll mit der undokumentierten Prozedur sp_readerrorlog oder der erweiterten gespeicherten Prozedur xp_readerrorlog anzusehen und/oder zu durchsuchen.
Und schließlich, wenn Sie sich für PowerShell interessieren, ist dies auch eine Option, um das Protokoll auf diese Weise zu lesen (siehe diesen Beitrag:Use PowerShell to Parse SQL Server 2012 Error Logs). Die Methode liegt bei Ihnen – verwenden Sie, was Sie wissen und was für Sie funktioniert – es ist der Inhalt, der wirklich zählt. Und denken Sie daran, dass Sie manchmal einfach das Protokoll durchlesen müssen, um die Reihenfolge der Ereignisse zu verstehen, und manchmal müssen Sie nach einem bestimmten Fehler oder einer bestimmten Information suchen.
Was steht im ERRORLOG?
Welche Informationen können wir also außer Fehlern im ERRORLOG finden? Ich habe viele der Artikel, die ich am nützlichsten fand, unten aufgelistet. Beachten Sie, dass dies keine vollständige Liste ist (und ich bin sicher, dass viele von Ihnen Vorschläge haben werden, was hinzugefügt werden könnte – zögern Sie nicht, einen Kommentar zu posten, und ich kann dies aktualisieren!), Aber noch einmal, das ist, was ich bin suche zuerst wenn ich mir eine Instanz proaktiv anschaue.
- Ob der Server physisch oder virtuell ist (suchen Sie nach dem Eintrag des Systemherstellers)
- Trace-Flags beim Start aktiviert
- Wenn Sie im Eintrag für die Startparameter der Registrierung ganz nach rechts scrollen, sehen Sie, ob Trace-Flags aktiviert sind:
 Trace-Flags beim Start aktiviert
Trace-Flags beim Start aktiviert
- Wenn Sie im Eintrag für die Startparameter der Registrierung ganz nach rechts scrollen, sehen Sie, ob Trace-Flags aktiviert sind:
- Trace-Flags aktiviert oder deaktiviert, nachdem die Instanz gestartet wurde
- Wenn Benutzer (oder eine Anwendung) ein Trace-Flag mit DBCC TRACEON oder DBCC TRACEOFF aktivieren oder deaktivieren, erscheint ein Eintrag im Protokoll
- Anzahl der von SQL Server erkannten Kerne und Sockets
- Ich vergewissere mich immer gerne, dass SQL Server die gesamte verfügbare Hardware erkennt – und wenn nicht, ist dies ein Warnsignal für weitere Untersuchungen. Ein gutes Beispiel finden Sie in Jonathans Beitrag „Performance Problems with SQL Server 0212 Enterprise Edition Under CAL Licensing“ und Glenns Beitrag „Balancing Your Available SQL Server Core Licenses Evenly Across NUMA Nodes“, der auch einige nützliche TSQL-Dateien zum Abfragen des Protokolls enthält. li>
- Beachten Sie, dass der Text für diesen Eintrag zwischen den SQL Server-Versionen variiert.
- Menge an Arbeitsspeicher, die von SQL Server erkannt wurde
- Ich möchte noch einmal überprüfen, ob SQL Server den gesamten verfügbaren Speicher sieht.
- Bestätigung, dass Locked Pages in Memory (LPIM) aktiviert ist
- Obwohl diese Option über die Windows-Sicherheitsrichtlinie aktiviert ist, können Sie bestätigen, dass sie aktiviert ist, indem Sie im Protokoll nach der Meldung „Verwendung gesperrter Seiten im Speichermanager“ suchen.
- Beachten Sie, dass, wenn Sie das Ablaufverfolgungs-Flag 834 verwenden, die Meldung keine gesperrten Seiten enthält, sondern dass große Seiten für den Pufferpool verwendet werden.
- Verwendete CLR-Version
- Erfolg oder Fehler bei der Registrierung des Dienstprinzipalnamens (SPN)
- Wie lange es dauert, bis eine Datenbank online ist
- Das Protokoll zeichnet auf, wann die Datenbank gestartet wird und wann sie online ist – ich überprüfe, ob eine Datenbank zu lange braucht, um hochzufahren.
- Status von Service Broker- und Datenbankspiegelungs-Endpunkten – wichtig, wenn Sie eine der beiden Funktionen verwenden
- Bestätigung, dass Instant File Initialization (IFI) aktiviert ist*
- Standardmäßig werden diese Informationen nicht protokolliert, aber wenn Sie Trace Flag 3004 aktivieren (und 3605, um die Ausgabe in das Protokoll zu erzwingen), werden Sie beim Erstellen oder Vergrößern einer Datendatei Meldungen im Protokoll sehen, die angeben, ob IFI verwendet wird oder nicht.
- Status von SQL-Traces
- Wenn Sie einen SQL-Trace starten oder stoppen, wird er protokolliert, und ich schaue, ob irgendwelche Traces über den Standard-Trace hinaus existieren (entweder vorübergehend oder langfristig). Wenn Sie ein Überwachungstool eines Drittanbieters ausführen, z. B. den Leistungsratgeber von SQL Sentry, sehen Sie möglicherweise eine aktive Ablaufverfolgung, die immer ausgeführt wird, aber nur bestimmte Ereignisse erfasst, oder Sie sehen möglicherweise einen Ablaufverfolgungsstart, der dann nur für kurze Zeit ausgeführt wird halt. Ich mache mir keine Sorgen um ein oder zwei zusätzliche Ablaufverfolgungen, es sei denn, sie erfassen viele Ereignisse, aber ich achte definitiv darauf, wenn mehrere Ablaufverfolgungen ausgeführt werden.
- Der letzte Zeitpunkt, zu dem CHECKDB abgeschlossen wurde
- Diese Nachricht wird oft missverstanden – wenn die Instanz startet, liest sie die Boot-Seite für jede Datenbank und notiert, wann CHECKDB zuletzt erfolgreich ausgeführt wurde. Die meisten Leute lesen nicht die ganze Nachricht:
 Datum, an dem DBCC CHECKDB zuletzt erfolgreich abgeschlossen wurde
Datum, an dem DBCC CHECKDB zuletzt erfolgreich abgeschlossen wurde Das Datum für die Fertigstellung von CHECKDB ist der 11. November 2012, aber das Datum für ERRORLOG ist der 7. Juli 2015. Es ist wichtig zu verstehen, dass SQL Server dies nicht tut Wenn Sie CHECKDB beim Start gegen Datenbanken ausführen, prüft es den dbcclastknowngood-Wert auf der Boot-Seite (um zu sehen, wann das aktualisiert wird, lesen Sie meinen Beitrag What Checks Update dbcclastknowngood. Wenn DBCC CHECKDB noch nie gegen eine Datenbank ausgeführt wurde, dann kein Eintrag wird hier für die Datenbank angezeigt.
- Diese Nachricht wird oft missverstanden – wenn die Instanz startet, liest sie die Boot-Seite für jede Datenbank und notiert, wann CHECKDB zuletzt erfolgreich ausgeführt wurde. Die meisten Leute lesen nicht die ganze Nachricht:
- CHECKDB-Vervollständigung
- Wenn CHECKDB gegen eine Datenbank ausgeführt wird, wird die Ausgabe im Protokoll aufgezeichnet.
- Änderungen an Instanzeinstellungen
- Wenn Sie Einstellungen auf Instanzebene (z. B. maximaler Serverspeicher, Kostenschwelle für Parallelität) mit sp_configure oder über die Benutzeroberfläche ändern (beachten Sie, dass wer nicht protokolliert wird geändert).
- Änderungen an Datenbankeinstellungen
- Hat jemand AUTO_SHRINK aktiviert? Ändern Sie die Option WIEDERHERSTELLUNG auf EINFACH und dann zurück auf VOLLSTÄNDIG? Hier findest du es.
- Änderungen am Datenbankstatus
- Wenn jemand eine Datenbank OFFLINE nimmt (oder ONLINE bringt), wird dies protokolliert.
- Deadlock-Informationen*
- Wenn Sie Deadlock-Informationen erfassen müssen, möchten Sie keine Ablaufverfolgung ausführen, und Wenn Sie SQL Server 2005 bis 2008R2 ausführen, verwenden Sie das Ablaufverfolgungsflag 1222, um Deadlock-Informationen im XML-Format in das Protokoll zu schreiben. Für diejenigen unter Ihnen, die SQL Server 2000 und niedriger verwenden, können Sie das Ablaufverfolgungsflag 1204 verfolgen (dieses Ablaufverfolgungsflag ist auch in SQL Server 2005+ verfügbar, gibt jedoch nur minimale Informationen aus). Wenn Sie SQL Server 2012 oder höher ausführen, ist dies nicht erforderlich, da die system_health-Ereignissitzung diese Informationen erfasst (und sie ist auch in 2008 und 20082 vorhanden, aber Sie müssen sie aus dem ring_buffer im Vergleich zum event_file-Ziel abrufen).
- FlushCache-Nachrichten
- Wenn der Cache von SQL Server geleert wird, weil der Prüfpunktprozess das Wiederherstellungsintervall für die Datenbank überschreitet, sehen Sie eine Reihe von FlushCache-Meldungen im Protokoll (weitere Informationen finden Sie in diesem Beitrag von Bob Dorr). Verwechseln Sie diese Meldungen nicht mit denen, die angezeigt werden, wenn Sie DBCC FREEPROCCACHE oder DBCC FREESYSTEMCACHE ausführen:
 Meldung nach dem Ausführen von DBCC FREEPROCCACHE oder DBCC FREESYSTEMCACHE
Meldung nach dem Ausführen von DBCC FREEPROCCACHE oder DBCC FREESYSTEMCACHE
- Wenn der Cache von SQL Server geleert wird, weil der Prüfpunktprozess das Wiederherstellungsintervall für die Datenbank überschreitet, sehen Sie eine Reihe von FlushCache-Meldungen im Protokoll (weitere Informationen finden Sie in diesem Beitrag von Bob Dorr). Verwechseln Sie diese Meldungen nicht mit denen, die angezeigt werden, wenn Sie DBCC FREEPROCCACHE oder DBCC FREESYSTEMCACHE ausführen:
- AppDomain-Entladenachrichten
- Das Protokoll vermerkt auch, wann AppDomains erstellt werden, und Sie sehen beides nur, wenn Sie CLR verwenden. Wenn ich AppDomain-Entlademeldungen aufgrund von Speichermangel sehe, muss ich dies weiter untersuchen.
Das Protokoll enthält weitere nützliche Informationen, z. B. den verwendeten Authentifizierungsmodus, ob die dedizierte Admin-Verbindung (DAC) aktiviert ist oder nicht usw., aber ich kann diese auch aus sys.configurations abrufen und diese mit den Instanz-Baselines überprüfen Ich habe bereits darüber gesprochen (Proaktive Integritätsprüfungen für SQL Server, Teil 3:Instanz- und Datenbankeinstellungen).
Was ist nicht im ERROLOG, was Sie vielleicht erwarten?
Dies ist vorerst eine kurze Liste, da ich vermute, dass einige von Ihnen andere Dinge gefunden haben, von denen Sie dachten, dass sie im Protokoll enthalten wären, aber nicht waren ...
- Hinzufügen oder Entfernen von Datenbankdateien oder Dateigruppen
- Starten oder Stoppen von Sitzungen mit erweiterten Ereignissen
- Wenn Sie jedoch einen DDL-Trigger oder eine Ereignisbenachrichtigung auf Serverebene bereitstellen, können Sie diese Informationen protokollieren. Weitere Einzelheiten finden Sie in Jonathans Post Logging Extended Events changes to the ERRORLOG.
- Das Ausführen von DBCC DROPCLEANBUFFERS wird im ERRORLOG angezeigt
Verwalten des Protokolls
Denken Sie daran, dass SQL Server standardmäßig nur die letzten sechs (6) Protokolldateien (zusätzlich zur aktuellen Datei) aufbewahrt und die Protokolldatei bei jedem Neustart von SQL Server aktualisiert wird. Infolgedessen können Sie manchmal extrem große Protokolldateien haben, deren Öffnen eine Weile dauert und deren Durchsuchen mühsam ist. Wenn Sie auf der anderen Seite auf einen Fall stoßen, in dem die Instanz ein paar Mal neu gestartet wird, können Sie wichtige Informationen verlieren. Es wird empfohlen, die Anzahl der aufbewahrten Dateien auf einen höheren Wert (z. B. 30) zu erhöhen und einen Agent-Job zu erstellen, um die Datei einmal pro Woche mit sp_cycle_errorlog zu übertragen.
Neben der Verwaltung der Dateien können Sie beeinflussen, welche Informationen in das Protokoll geschrieben werden. Einer der häufigsten Einträge, der Unordnung im ERRORLOG verursacht, ist der erfolgreiche Backup-Eintrag:
 Sicherung erfolgreich abgeschlossen
Sicherung erfolgreich abgeschlossen
Wenn Sie eine Instanz mit zahlreichen Datenbanken haben und Transaktionsprotokoll-Backups regelmäßig erstellt werden (z. B. alle 15 Minuten), werden Sie feststellen, dass sich das Protokoll schnell mit Nachrichten füllt, was das Auffinden eines echten Problems erschwert. Glücklicherweise können Sie das Trace-Flag 3226 verwenden, um Meldungen über erfolgreiche Sicherungen zu deaktivieren (Fehler werden weiterhin im Protokoll angezeigt, und alle Einträge sind weiterhin in msdb vorhanden).
Eine weitere Gruppe von Meldungen, die das Protokoll überladen, sind erfolgreiche Anmeldemeldungen. Dies ist eine Option, die Sie für die Instanz auf der Registerkarte Sicherheit konfigurieren:
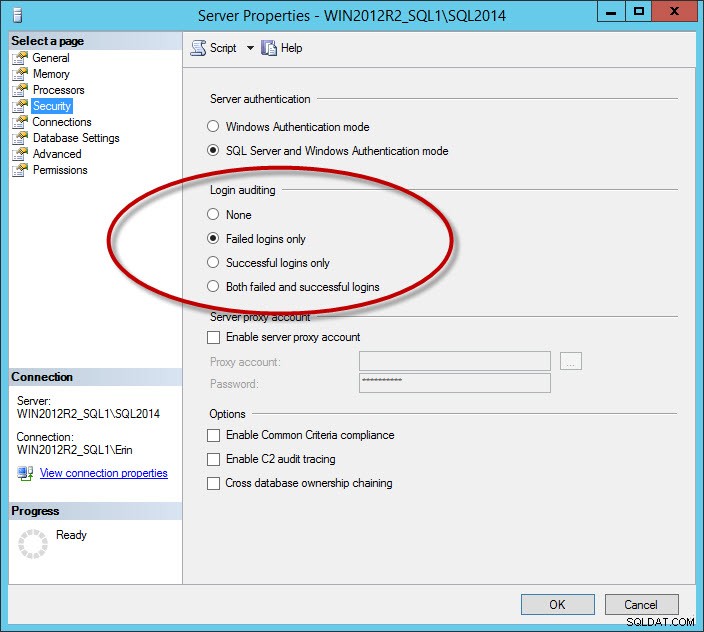 Sicherheitsoption zum Protokollieren erfolgreicher und/oder fehlgeschlagener Anmeldungen
Sicherheitsoption zum Protokollieren erfolgreicher und/oder fehlgeschlagener Anmeldungen
Wenn Sie erfolgreiche Anmeldungen oder fehlgeschlagene und erfolgreiche Anmeldungen protokollieren, können Sie sehr große Protokolldateien haben, selbst wenn Sie die Dateien täglich übertragen (es hängt davon ab, wie viele Benutzer eine Verbindung herstellen). Ich empfehle, nur fehlgeschlagene Anmeldungen zu erfassen. Für Unternehmen, die erfolgreiche Anmeldungen protokollieren müssen, sollten Sie die in SQL Server 2008 hinzugefügte Überwachungsfunktion verwenden. Randnotiz:Wenn Sie die Anmeldeüberwachungseinstellung ändern, wird sie erst wirksam, wenn Sie die Instanz neu starten.
Unterschätzen Sie nicht das ERRORLOG
Wie Sie sehen, enthält das ERRORLOG einige nützliche Informationen, die Sie nicht nur bei der Fehlerbehebung bei der Leistung oder der Untersuchung von Fehlern verwenden können, sondern auch, wenn Sie eine Instanz proaktiv überwachen. Sie können Informationen im Protokoll finden, die nirgendwo anders zu finden sind; Stellen Sie sicher, dass Sie es regelmäßig überprüfen und es nicht als nachträglichen Einfall belassen.
Siehe die anderen Teile dieser Serie:
- Teil 1:Speicherplatz
- Teil 2:Wartung
- Teil 3:Instanz- und Datenbankeinstellungen