Einführung
In diesem Artikel werden wir über die Verwendung von nvarchar sprechen Datentyp. Wir werden untersuchen, wie SQL Server diesen Datentyp auf der Festplatte speichert und wie er im RAM verarbeitet wird. Wir werden auch untersuchen, wie sich die Größe von nvarchar auf die Leistung auswirken kann.
Tatsächliche Datengröße:nchar vs. nvarchar
Wir verwenden nvarchar wenn die Größe der Spaltendateneinträge wahrscheinlich erheblich variieren wird. Die Speichergröße (in Bytes) ist doppelt so groß wie die tatsächliche Länge der eingegebenen Daten + 2 Bytes. Dadurch können wir Festplattenspeicher im Vergleich zur Verwendung von nchar sparen Datentyp. Betrachten wir folgendes Beispiel. Wir erstellen zwei Tabellen. Eine Tabelle enthält eine nvarchar-Spalte, eine andere Tabelle enthält nchar-Spalten. Die Größe der Spalte beträgt 2000 Zeichen (4000 Byte).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
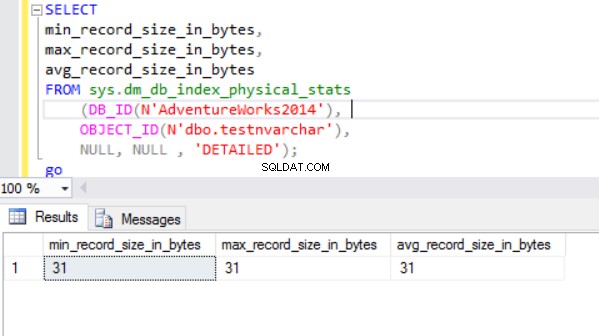
Die tatsächliche Zeilengröße ist:
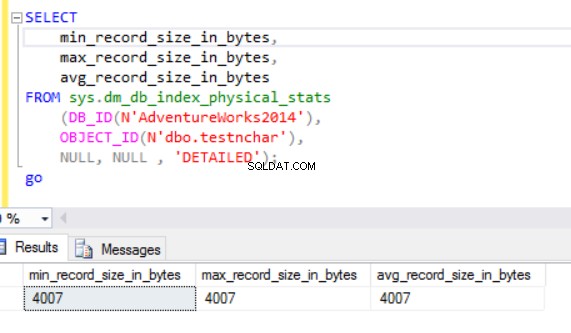
Wie wir sehen können, ist die tatsächliche Zeilengröße des nvarchar-Datentyps viel kleiner als die des nchar-Datentyps. Im Fall des Nchar-Datentyps verwenden wir ~4000 Bytes, um eine Zeichenkette mit 10 Symbolen zu speichern. Wir verwenden ~20 Bytes, um dieselbe Zeichenfolge im Fall des nvarchar-Datentyps zu speichern.
Die SQL Server-Engine verarbeitet Daten im RAM (Pufferpool). Was ist mit der Zeilengröße im Speicher?
Tatsächliche Datengröße:HDD vs. RAM
Lassen Sie uns die folgende Abfrage ausführen:
SELECT col1 FROM dbo.testnchar;

Bei der Zeichenkette fester Länge gibt es keinen Unterschied zwischen Platten- und RAM-Auslastung.
SELECT col1 FROM dbo.testnvarchar;

Wir können sehen, dass die SQL Server-Engine den Speicher nur für die Hälfte der deklarierten Zeilengröße (2000 Bytes anstelle der tatsächlichen 20 Bytes) und mehrere Bytes für zusätzliche Informationen angefordert hat. Auf der einen Seite verringern wir die Speicherplatznutzung, auf der anderen Seite können wir den angeforderten Arbeitsspeicher aufblähen. Dies ist ein Nebeneffekt der Verwendung unterschiedlicher Zeichendatentypen. Dieser Nebeneffekt kann sich in manchen Fällen stark auf die Ressourcen auswirken.
FORMAT():Angeforderter RAM vs. verwendeter RAM
Wir verwenden die FORMAT-Funktion, die einen formatierten Wert mit dem angegebenen Format und der optionalen Kultur zurückgibt. Der Rückgabewert ist nvarchar oder null. Die Länge des Rückgabewerts wird durch das Format bestimmt . FORMAT(getdate(), ‘yyyyMMdd’,’en-US’) ergibt ‘20170412’. Wir benötigen 16 Bytes, um dieses Ergebnis in der Spalte auf der Disc zu speichern (das Ergebnis ist nvarchar(8)). Wie groß ist die Datengröße im RAM für die jeweiligen Daten?
Lassen Sie uns die folgende Abfrage ausführen. Wir verwenden die folgende Umgebung:
- AdventureWorks2014
- MS SQL 2016 Entwicklungsversion
- dbo.Customer (19’820’000 Datensätze) enthält Daten von Sales.Customer (19’820 Datensätze wurden 1000 Mal hochgeladen)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
Der Abfrageausführungsplan ist ganz einfach:

Die erste Operation ist „Clustered Index Scan“ in der dbo.Customer-Tabelle. ~19 000 000 Datensätze wurden gelesen. Die geschätzte Datengröße beträgt 435 MB.
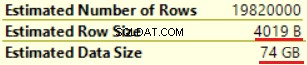
Die nächste Operation ist „Compute Scalar“ (Berechnung der Funktion FORMAT()). Das Ergebnis ist ziemlich unerwartet, da wir eine 16-Byte-Zeichenfolge formatieren. Die Zeilengröße stieg dramatisch von 23 Byte auf 4019 Byte. Dasselbe gilt für die geschätzte Datengröße – von 435 MB bis 74 GB. Wir können sehen, dass FORMAT() NVARCHAR(4000) zurückgibt.
MS SQL Server 2016 hat die großartige Fähigkeit, eine übermäßige Speicherzuweisung anzuzeigen. Wir können die Warnung in der letzten Operation sehen (T-SQL SELECT INTO):
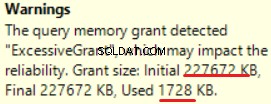
Dies ist eine „Überbewilligung“ des Arbeitsspeichers:mehr als 90 % des gewährten Arbeitsspeichers werden nicht verwendet.
Die Abfragezeitstatistiken sind:
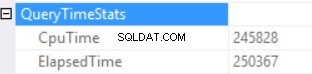
Die lange Ausführungszeit hängt von einer nicht effektiven Skalarfunktionsausführung und dem rückseitigen Effekt eines Excessive Memory Grant – Hash Match (Right Outer Join) ab. Wir haben einen kumulativen Effekt aus zwei verschiedenen Ursachen:mehrfache Skalarfunktionsausführung und übermäßige Speicherzuweisung.
Die SQL Server-Engine kann nicht mehr als 25 % des zulässigen Arbeitsspeichers pro Abfrage gewähren. Diesen Betrag können wir in der Enterprise Edition des MS SQL Servers über den Resource Governor verändern. Der gewährte Speicher besteht aus zwei Teilen:erforderlich und zusätzlich. Ein erforderlicher Speicher wird für den internen Bedarf verwendet – für Sortier- und Hash-Join-Operationen. Zusätzlicher Arbeitsspeicher basiert auf der geschätzten Datengröße. Wenn sowohl der erforderliche als auch der zusätzliche Arbeitsspeicher die Grenze von 25 % überschreiten, gewährt die SQL Server-Engine weitere 25 % des verfügbaren Arbeitsspeichers. Weitere Informationen finden Sie im Beitrag zur Arbeitsspeicherzuteilung für SQL Server.
Lassen Sie uns dieselbe Abfrage ohne die FORMAT()-Funktion ausführen.
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
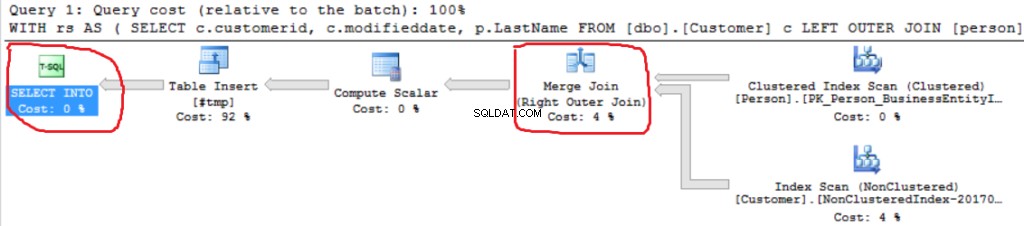
Wir können eine weitere Right Outer Join-Implementierung sehen (Merge Join anstelle von Hash Join).
Informationen zur Speicherzuteilung sind (wenn keine Sortierung und der Hash-Join SQL Server keinen Speicher zuteilen kann):
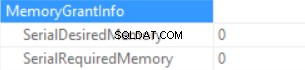
Die Statistiken zur Abfragezeit sind (die Zeit wird vorhersagbar verringert:keine Skalarfunktionsausführung, die geschätzte Datengröße ist kleiner als im vorherigen Beispiel):

Also blähen wir den „gewährten Speicher“ auf bis zu 222 MB auf (und verwenden weniger als 2 MB davon), indem wir die Funktion FORMAT() verwenden. Das Datenvolumen im Beispiel ist gering.
Langzeitausführungsabfrage
Betrachten Sie die echte SQL-Abfrage aus einer Produktionsumgebung. Diese Abfrage wurde während eines Stapelladevorgangs ausgeführt (kein klassisches Transaktionsszenario). Wir verwenden MS SQL Server gestartet auf Amazon Web Services (AWS, Amazon Relational Database Service). DB-Instance-Merkmale sind 160 GB RAM (pro Abfrage können nicht mehr als ~30 GB RAM gewährt werden) und 40 vCPU. Die SQL-Abfrage war fast die gleiche wie im obigen Beispiel (der Unterschied liegt in der Anzahl der Tabellen und der Datengröße):CTE enthielt einen Join zwischen 6 Tabellen. Die „Master-Tabelle“ (eine Tabelle in der FROM-Klausel) enthält ~175.000.000 Datensätze und die Datengröße beträgt 20 GB. Die Lookup-Tabellen (rechte Tabelle in der JOIN-Klausel) sind klein (im Vergleich zur Haupttabelle). Die SQL-Abfrage enthält zwei Aufrufe der Funktion FORMAT() (zwei Spalten aus der Tabelle „Master-Tabelle“ sind der Parameter dieser Funktion).
Die Produktionsabfrage sieht folgendermaßen aus:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
Das „Bild“ des Ausführungsplans ist unten (der Ausführungsplan ist einfach:sequentielle Joins und Sortierung (DISTINCT-Schlüsselwörter) oben):

Lassen Sie uns die Informationen im Detail untersuchen.
Die erste Operation ist „Table scan“ (alles ist korrekt, keine Überraschungen):

Die Operation „Skalare Berechnung“ erhöht die geschätzte Zeilengröße sowie die geschätzte Zeilengröße dramatisch (von 19 GB auf bis zu 1,3 TB). Zwei Aufrufe der Funktion FORMAT() fügten der geschätzten Zeilengröße etwa 8000 Bytes hinzu (aber die tatsächliche Datengröße ist kleiner).

Eine der JOIN-Operationen (Hash Match, Right Outer Join) verwendet nicht eindeutige Spalten aus der rechten Tabelle. Bei wenigen Datensätzen spielt es keine Rolle. Dies ist nicht unser Fall. Infolgedessen steigt die geschätzte Datengröße auf ~2,4 TB.

Es gibt auch eine Warnung (nicht genügend RAM, um diesen Vorgang auszuführen):
Die SQL-Abfrage enthält oben eine „Distinct Sort“-Operation, die wie die Kirsche auf einem Kuchen aussieht. Dort sehen wir dieselbe Warnung.
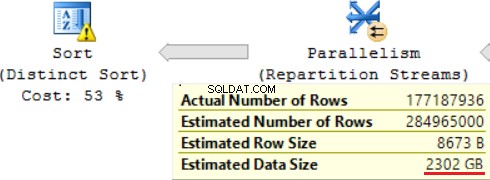
Ein Ergebnis der Verwendung einer Skalarfunktion ist eine lange Zeit für die Abfrageausführung:24 Stunden. Eine der Ursachen für dieses Problem ist eine falsche Schätzung der angeforderten Datengröße basierend auf „Geschätzte Datengröße“. Ohne die FORMAT()-Funktion führt MS SQL Server diese Abfrage in 2 Stunden aus.
Schlussfolgerung
Entwickler sollten vorsichtig sein, wenn sie die Datentypen nvarchar und varchar verwenden. Die Auswahl redundanter Datentypen für Spalten kann zu einer Aufblähung des erforderlichen Speichers führen. Als Ergebnis wird RAM verschwendet, die Datenbankleistung wird herabgesetzt.