Analysieren Sie die Abfrage der Schlüsselpopulation weiter
In Teil 3 unserer Serie zur ODBC-Ablaufverfolgung werden wir einen weiteren Einblick in die Verwaltung von Schlüsseln für ODBC-verknüpfte Tabellen durch Access erhalten und wie die SELECT-Abfragen sortiert und gruppiert werden. Im vorherigen Artikel haben wir gelernt, dass ein Datensatz vom Typ Dynaset tatsächlich aus zwei separaten Abfragen besteht, wobei die erste Abfrage nur die Schlüssel der mit ODBC verknüpften Tabelle abruft, die dann anschließend zum Auffüllen der Daten verwendet wird. In diesem Artikel werden wir ein wenig mehr darüber untersuchen, wie Access die Schlüssel verwaltet und wie daraus abgeleitet wird, welcher Schlüssel für eine ODBC-verknüpfte Tabelle verwendet werden soll, und welche Auswirkungen dies hat. Wir beginnen mit der Sortierung.
Hinzufügen einer Sortierung zur Abfrage
Sie haben im vorherigen Artikel gesehen, dass wir mit einem einfachen SELECT begonnen haben ohne besondere Bestellung. Sie haben auch gesehen, wie Access zuerst die CityID abgerufen hat und verwenden Sie das Ergebnis der ersten Abfrage, um dann die nachfolgenden Abfragen zu füllen, um dem Benutzer beim Öffnen eines großen Datensatzes den Anschein zu erwecken, schnell zu sein. Wenn Sie jemals eine Situation erlebt haben, in der das Hinzufügen einer Sortierung oder Gruppierung zu einer Abfrage plötzlich langsam wurde, wird dies erklären, warum.
Fügen wir der StateProvinceID eine Sortierung hinzu in einer Access-Abfrage:
SELECT Cities.* FROM Cities ORDER BY Cities.StateProvinceID;Wenn wir nun das ODBC-SQL verfolgen, sollten wir die Ausgabe sehen:
SQLExecDirect: SELECT "Application"."Cities"."CityID" FROM "Application"."Cities" ORDER BY "Application"."Cities"."StateProvinceID" SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? SQLExecute: (GOTO BOOKMARK) SQLPrepare: SELECT "CityID", "CityName", "StateProvinceID", "Location", "LatestRecordedPopulation", "LastEditedBy", "ValidFrom", "ValidTo" FROM "Application"."Cities" WHERE "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? OR "CityID" = ? SQLExecute: (MULTI-ROW FETCH) SQLExecute: (MULTI-ROW FETCH)Wenn Sie mit dem Trace aus dem vorherigen Artikel vergleichen, können Sie sehen, dass sie bis auf die erste Abfrage identisch sind. Access hat die Sortierung in die erste Abfrage eingefügt, in der es die Schlüssel erhält. Das ist sinnvoll, da durch die Erzwingung der Sortierung der Schlüssel, die zum Durchlaufen der Datensätze verwendet werden, Access garantiert eine Eins-zu-Eins-Entsprechung zwischen der Ordnungsposition eines Datensatzes und der Art und Weise hat, wie er sortiert werden sollte. Anschließend werden die Datensätze auf die gleiche Weise gefüllt. Der einzige Unterschied besteht in der Reihenfolge der Schlüssel, die zum Ausfüllen der anderen Abfragen verwendet werden.
Betrachten wir, was passiert, wenn wir ein GROUP BY hinzufügen indem Sie die Städte pro Staat zählen:
SELECT Cities.StateProvinceID ,Count(Cities.CityID) AS CountOfCityID FROM Cities GROUP BY Cities.StateProvinceID;Die Ablaufverfolgung sollte Folgendes ausgeben:
SQLExecDirect:
SELECT
"StateProvinceID"
,COUNT("CityID" )
FROM "Application"."Cities"
GROUP BY "StateProvinceID" Möglicherweise haben Sie auch bemerkt, dass die Abfrage jetzt langsam geöffnet wird, und obwohl sie möglicherweise als Recordset vom Typ Dynaset festgelegt ist, hat Access dies ignoriert und im Grunde als Recordset vom Typ Snapshot behandelt. Dies ist sinnvoll, da die Abfrage nicht aktualisierbar ist und Sie in einer solchen Abfrage nicht wirklich zu einer beliebigen Position navigieren können. Daher müssen Sie warten, bis alle Zeilen abgerufen wurden, bevor Sie frei browsen können. Die StateProvinceID kann nicht verwendet werden, um einen Datensatz zu finden, da es mehrere Datensätze in den Cities geben würde Tisch. Obwohl ich ein GROUP BY verwendet habe In diesem Beispiel muss es sich nicht um eine Gruppierung handeln, die dazu führt, dass Access stattdessen ein Recordset vom Snapshot-Typ verwendet. Verwendung von DISTINCT zum Beispiel hätte den gleichen Effekt. Eine nützliche Faustregel, um vorherzusagen, ob Access ein Recordset vom Typ Dynaset verwendet, besteht darin, zu fragen, ob eine bestimmte Zeile im resultierenden Recordset genau einer Zeile in der ODBC-Datenquelle zugeordnet ist. Wenn dies nicht der Fall ist, verwendet Access das Snapshot-Verhalten, selbst wenn die Abfrage Dynaset verwenden sollte. Nur weil der Standardwert ein Recordset vom Typ Dynaset ist, ist folglich nicht garantiert, dass es sich tatsächlich um ein Recordset vom Typ Dynaset handelt. Es ist lediglich eine Anfrage , keine Nachfrage.
Festlegen des Schlüssels zum Auswählen
Möglicherweise haben Sie im vorherigen nachverfolgten SQL sowohl in diesem als auch in früheren Artikeln bemerkt, dass Access die CityID verwendet hat als Schlüssel. Diese Spalte wurde in der ersten Abfrage abgerufen und dann in nachfolgenden vorbereiteten Abfragen verwendet. Aber woher weiß Access, welche Spalte(n) einer verknüpften Tabelle es verwenden soll? Die erste Neigung wäre zu sagen, dass es nach einem Primärschlüssel sucht und diesen verwendet. Das wäre jedoch falsch. Tatsächlich verwendet die Access-Datenbank-Engine die SQLStatistics von ODBC Funktion beim Verknüpfen oder erneuten Verknüpfen der Tabelle, um zu prüfen, welche Indizes verfügbar sind. Diese Funktion gibt eine Ergebnismenge mit einer Zeile für jede Spalte zurück, die an einem Index für alle Indizes teilnimmt. Diese Ergebnismenge ist immer sortiert und sortiert gemäß Konvention immer geclusterte Indizes, gehashte Indizes und dann andere Indextypen. Innerhalb jedes Indextyps werden die Indizes alphabetisch nach ihren Namen sortiert. Das Access-Datenbankmodul wählt den ersten eindeutigen Index aus, den es findet, auch wenn es sich nicht um den tatsächlichen Primärschlüssel handelt. Um dies zu beweisen, erstellen wir eine dumme Tabelle mit einigen ungeraden Indizes:
CREATE TABLE dbo.SillyTable ( ID int CONSTRAINT PK_SillyTable PRIMARY KEY NONCLUSTERED, OtherStuff int CONSTRAINT UQ_SillyTable_OtherStuff UNIQUE CLUSTERED, SomeValue nvarchar(255) );Wenn wir die Tabelle dann mit einigen Daten füllen und in Access darauf verlinken und eine Datenblattansicht für die verknüpfte Tabelle öffnen, sehen wir dies in nachverfolgtem ODBC-SQL. Der Kürze halber sind nur die ersten beiden Befehle enthalten.
SQLExecDirect: SELECT "dbo"."SillyTable"."OtherStuff" FROM "dbo"."SillyTable" SQLPrepare: SELECT "ID" ,"OtherStuff" ,"SomeValue" FROM "dbo"."SillyTable" WHERE "OtherStuff" = ?Weil das
OtherStuff an einem gruppierten Index teilnimmt, kam er vor dem eigentlichen Primärschlüssel und wurde daher von der Access-Datenbank-Engine ausgewählt, um in einem Recordset vom Typ Dynaset zum Auswählen einer einzelnen Zeile verwendet zu werden. Und das, obwohl der Name des eindeutigen Clustered-Index nach dem Namen des Primärindex gekommen wäre. Eine Taktik, um das Access-Datenbankmodul zu zwingen, einen bestimmten Index für eine Tabelle auszuwählen, besteht darin, seinen Typ zu ändern oder den Namen umzubenennen, sodass er innerhalb der Gruppe des Indextyps alphabetisch sortiert wird. Im Fall von SQL Server sind Primärschlüssel normalerweise gruppiert, und es kann nur einen gruppierten Index geben, daher ist es ein glücklicher Zufall, dass dies normalerweise der richtige Index für die Verwendung der Access-Datenbank-Engine ist. Wenn die SQL Server-Datenbank jedoch Tabellen mit nicht gruppierten Primärschlüsseln enthält und es einen gruppierten eindeutigen Index gibt, ist dies möglicherweise nicht die optimale Wahl. In den Fällen, in denen überhaupt keine geclusterten Indizes vorhanden sind, können Sie beeinflussen, welche eindeutigen Indizes verwendet werden, indem Sie den Index so benennen, dass er vor anderen Indizes sortiert wird. Dies kann bei anderer RDBMS-Software hilfreich sein, bei der das Erstellen eines gruppierten Indexes für den Primärschlüssel nicht praktikabel oder möglich ist. Zugriffsseitiger Index für verknüpfte SQL-Ansicht oder -Tabelle ohne Indizes
Beim Verknüpfen mit einer SQL-Ansicht oder einer SQL-Tabelle, für die keine Indizes oder Primärschlüssel definiert sind, stehen keine Indizes zur Verfügung, die von der Access-Datenbank-Engine verwendet werden können. Wenn Sie Linked Table Manager verwendet haben, um eine Tabelle oder eine SQL-Ansicht ohne Indizes zu verknüpfen, haben Sie möglicherweise einen Dialog wie diesen gesehen:
 Wenn wir die
Wenn wir die ID auswählen , schließen Sie die Verknüpfung ab, öffnen Sie die verknüpfte Tabelle in der Entwurfsansicht und dann den Indexdialog, wir sollten Folgendes sehen:
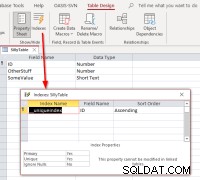 Es zeigt, dass die Tabelle einen Index namens
Es zeigt, dass die Tabelle einen Index namens __uniqueindex hat aber es existiert nicht in der ursprünglichen Datenquelle. Was ist los? Die Antwort ist, dass Access eine Access-Seite erstellt hat Index für seine Verwendung, um zu identifizieren, was als Datensatzkennung für solche Tabellen oder Ansichten verwendet werden kann. Wenn Sie die Tabellen programmgesteuert neu verknüpfen, anstatt den Linked Table Manager zu verwenden, müssen Sie das Verhalten replizieren, um solche verknüpften Tabellen aktualisierbar zu machen. Dies kann durch Ausführen eines Access SQL-Befehls erfolgen:
CREATE UNIQUE INDEX [__uniqueindex] ON SillyTable (ID);Sie können zum Beispiel
CurrentDb.Execute verwenden um die Access-SQL auszuführen, um den Index für die verknüpfte Tabelle zu erstellen. Sie sollten es jedoch nicht als Pass-Through-Abfrage ausführen, da der Index nicht wirklich auf dem Server erstellt wird. Es dient nur den Vorteilen von Access, die Aktualisierung dieser verknüpften Tabelle zuzulassen. Es ist erwähnenswert, dass Access nur genau einen Index für eine solche verknüpfte Tabelle zulässt und nur dann, wenn es noch keine Indizes gibt. Dennoch können Sie sehen, dass die Verwendung einer SQL-Ansicht eine wünschenswerte Option für Fälle sein kann, in denen das Datenbankdesign die Verwendung von gruppierten Indizes nicht zulässt und Sie nicht mit dem Namen des Index herumspielen möchten, um die Access-Datenbank-Engine davon zu überzeugen, diesen Index zu verwenden. nicht dieser Index. Sie können den Index und die darin enthaltenen Spalten explizit steuern, wenn Sie die SQL-Ansicht verknüpfen.
Schlussfolgerungen
Aus dem vorherigen Artikel haben wir gesehen, dass ein Recordset vom Typ Dynaset normalerweise zwei Abfragen ausgibt. Die erste Abfrage befasst sich normalerweise mit dem Auffüllen der Wir haben uns genauer angesehen, wie Access mit dem Auffüllen von Schlüsseln umgeht, die für ein Recordset vom Typ Dynaset verwendet werden. Wir haben gesehen, wie Access tatsächlich jede Sortierung aus der ursprünglichen Access-Abfrage konvertiert und diese dann in der Schlüsselauffüllungsabfrage verwendet. Wir haben gesehen, dass sich die Reihenfolge der Schlüsselauffüllungsabfrage direkt darauf auswirkt, wie die Daten im Recordset sortiert und dem Benutzer präsentiert werden. Dies ermöglicht dem Benutzer Dinge wie das Springen zu einem beliebigen Datensatz basierend auf der Ordnungsposition der Liste.
Wir haben dann gesehen, dass Gruppierungen und andere SQL-Vorgänge, die eine Eins-zu-Eins-Zuordnung zwischen der zurückgegebenen Zeile und der ursprünglichen Zeile verhindern, dazu führen, dass Access die Access-Abfrage so behandelt, als wäre es ein Recordset vom Snapshot-Typ, obwohl ein Recordset vom Typ Dynaset angefordert wird.
Wir haben uns dann angesehen, wie Access den Schlüssel bestimmt, der zum Verwalten von Updates mit einer ODBC-verknüpften Tabelle verwendet werden soll. Im Gegensatz zu dem, was wir erwarten könnten, wird es nicht unbedingt den Primärschlüssel der Tabelle auswählen, sondern den ersten eindeutigen Index, den es findet, abhängig von der Art des Index und dem Namen des Index. Wir haben Strategien besprochen, um sicherzustellen, dass Access den richtigen eindeutigen Index auswählt. Wir haben uns die SQL-Ansicht angesehen, die normalerweise keine Indizes hat, und eine Methode besprochen, mit der wir Access darüber informieren können, wie eine SQL-Ansicht oder eine Tabelle ohne Primärschlüssel verschlüsselt werden muss, sodass wir mehr Kontrolle darüber haben, wie Access die Aktualisierungen handhabt diese ODBC-verknüpften Tabellen.
Im nächsten Artikel werden wir uns ansehen, wie Access tatsächlich Aktualisierungen an den Daten durchführt, wenn Benutzer Änderungen über die Access-Abfrage oder Datensatzquelle vornehmen.
Unsere Zugangsexperten stehen Ihnen zur Verfügung. Rufen Sie uns unter 773-809-5456 an oder senden Sie uns eine E-Mail an sales@itimpact.com.