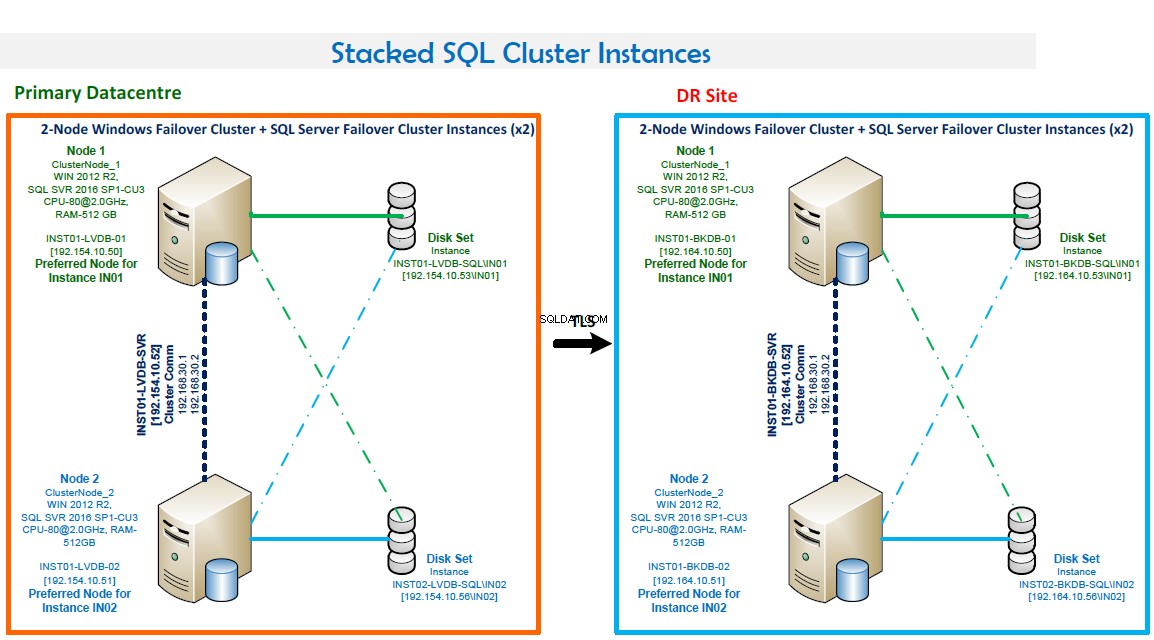
HINWEISE:
- Windows-Failover-Clustering mit zwei Knoten.
- Zwei SQL Server-Failover-Cluster-Instanzen. Diese Konfiguration optimiert die Hardware. IN01 wird auf Knoten1 bevorzugt und IN02 wird auf Knoten2 bevorzugt.
- Portnummern:IN01 lauscht auf Port 1435 und IN02 lauscht auf Port 1436.
- Hohe Verfügbarkeit. Beide Knoten sichern sich gegenseitig. Failover erfolgt automatisch im Fehlerfall.
- Der Quorum-Modus ist Knoten- und Festplattenmehrheit.
- Backup-LAN vorhanden und routinemäßiges Backup mit Veritas konfiguriert
Einführung
Es ist nicht ungewöhnlich, dass Entwickler und Projektmanager für jede neue Anwendung oder jeden neuen Dienst eine neue Instanz von SQL Server fordern. Während Technologien wie Virtualisierung und Cloud das Hochfahren neuer Instanzen zu einem Kinderspiel gemacht haben, ermöglichen einige uralte Techniken, die in SQL Server integriert sind, kurze Durchlaufzeiten, wenn eine neue Datenbank für einen neuen Dienst oder eine neue Anwendung bereitgestellt werden muss. Dieser Zustand kann von einem DBA erstellt werden, der einen großen SQL Server-Cluster entwerfen und bereitstellen kann, der die meisten von der Organisation benötigten SQL Server-Datenbanken unterstützen kann. Diese Art der Konsolidierung bietet zusätzliche Vorteile wie niedrigere Lizenzkosten, bessere Governance und einfache Verwaltung. In diesem Artikel werden wir einige Überlegungen hervorheben, die wir bei der Verwendung von Clustering und Stacking als Mittel zur Konsolidierung von SQL Server-Datenbanken erleben durften.
Clustering
Windows Server Failover Clustering ist eine sehr bekannte Hochverfügbarkeitslösung, die viele Versionen von Windows Server überdauert hat und in die Microsoft weiter investieren und sie verbessern will. SQL Server-Failoverclusterinstanzen basieren auf WSFC. Sowohl die Standard- als auch die Enterprise-Edition von SQL Server unterstützen SQL Server-Failoverclusterinstanzen, aber die Standard-Edition ist auf nur zwei Knoten beschränkt. Die Konsolidierung von Datenbanken auf einer einzigen SQL Server-FCI bietet folgende Vorteile:
- HA standardmäßig — Alle Datenbanken, die auf einer geclusterten SQL Server-Instanz bereitgestellt werden, sind standardmäßig hochverfügbar! Sobald eine geclusterte Instanz erstellt ist, werden neue Bereitstellungen im Hinblick auf HA im Voraus erledigt.
- Einfache Verwaltung – Weniger DBAs können Zeit für die Konfiguration, Überwachung und gegebenenfalls Fehlerbehebung einer geclusterten Instanz aufwenden, die viele Anwendungen unterstützt. Auch die ordnungsgemäße Dokumentation der Instanz wird beim Umgang mit einer großen Umgebung erheblich vereinfacht. Die Konfiguration einer Enterprise Backup-Lösung zur Handhabung aller Datenbanken in Ihrer Umgebung wird durch die Tatsache vereinfacht, dass Sie diese Konfiguration nur einmal vornehmen müssen, wenn Sie konsolidierte Instanzen verwenden.
- Konformität – Schlüsselanforderungen wie Patchen und sogar Härtung können einmal mit minimaler Ausfallzeit für eine große Anzahl von Datenbanken in einem einzigen Verwaltungsaufwand durchgeführt werden. In unserem Shop haben wir Transaktionsprotokollversand zwischen geclusterten Instanzen in zwei Rechenzentren verwendet, um sicherzustellen, dass Datenbanken vor dem Risiko von Katastrophen geschützt sind.
- Standardisierung – Die Durchsetzung von Standards wie Namenskonventionen, Zugriffsverwaltung, Windows-Authentifizierung, Auditing und richtlinienbasierter Verwaltung ist viel einfacher, wenn Sie sich je nach Größe Ihres Shops mit nur einer oder zwei Umgebungen befassen
Auflistung 1: Extrahieren Sie Informationen über Ihre Instanz
-- Extract Instance Details
-- Includes a Column to Check Whether Instance is Clustered
SELECT SERVERPROPERTY('MachineName') AS [MachineName]
, SERVERPROPERTY('ServerName') AS [ServerName]
, SERVERPROPERTY('InstanceName') AS [Instance]
, SERVERPROPERTY('IsClustered') AS [IsClustered]
, SERVERPROPERTY('ComputerNamePhysicalNetBIOS') AS [ComputerNamePhysicalNetBIOS]
, SERVERPROPERTY('Edition') AS [Edition]
, SERVERPROPERTY('ProductLevel') AS [ProductLevel]
, SERVERPROPERTY('ProductVersion') AS [ProductVersion]
, SERVERPROPERTY('ProcessID') AS [ProcessID]
, SERVERPROPERTY('Collation') AS [Collation]
, SERVERPROPERTY('IsFullTextInstalled') AS [IsFullTextInstalled]
, SERVERPROPERTY('IsIntegratedSecurityOnly') AS [IsIntegratedSecurityOnly]
, SERVERPROPERTY('IsHadrEnabled') AS [IsHadrEnabled]
, SERVERPROPERTY('HadrManagerStatus') AS [HadrManagerStatus]
, SERVERPROPERTY('IsXTPSupported') AS [IsXTPSupported];
Stapeln
SQL Server unterstützt bis zu fünfzig Einzelinstanzen auf einem Server und bis zu 25 Failoverclusterinstanzen auf einem Windows Server-Failovercluster. Verschiedene Versionen von SQL Server können in derselben Umgebung gestapelt werden, um eine robuste Umgebung bereitzustellen, die verschiedene Anwendungen unterstützt. In einer solchen Konfiguration kann das Upgrade von Datenbanken einfach so erfolgen, dass sie von einer SQL Server-Instanz auf die nächste Version im selben Cluster hochgestuft werden, bis die Hardware veraltet ist. Eine wichtige Überlegung beim Stacking von SQL Server ist, dass Sie jeder Instanz Speicher so zuweisen müssen, dass die Gesamtmenge des zugewiesenen Speichers den auf dem Betriebssystem verfügbaren Speicher nicht überschreitet. Der andere Punkt in diese Richtung besteht darin, sicherzustellen, dass das SQL Server-Dienstkonto für jede Instanz über die Berechtigungen zum Sperren von Seiten im Arbeitsspeicher verfügen muss. Durch das Zuweisen von Sperrseiten im Arbeitsspeicher wird sichergestellt, dass das Betriebssystem beim Abrufen von Arbeitsspeicher durch SQL Server nicht versucht, diesen Arbeitsspeicher wiederherzustellen, wenn andere Prozesse auf dem Server Arbeitsspeicher benötigen. Das Einrichten eines definierten SQL Server-Dienstkontos, das Konfigurieren von MAX_SERVER_MEMORY und das Gewähren der Berechtigung zum Sperren von Seiten im Speicher sind ein wesentliches Trio beim Stapeln von SQL Server-Instanzen.
Microsoft berechnet ein paar tausend Dollar pro CPU-Kernpaar. Durch das Stapeln von SQL Server-Instanzen können Sie dieses Lizenzmodell nutzen, indem Sie Instanzen denselben Satz von CPUs gemeinsam nutzen lassen (das Asset schwitzen). Wir haben bereits erwähnt, dass Sie verschiedene Versionen von SQL Server stapeln können und sich so um ältere Anwendungen kümmern können, auf denen beispielsweise noch ältere Versionen als SQL Server 2016 ausgeführt werden. Wenn Sie verschiedene Editionen von SQL Server verwenden, sollten Sie die Verwendung von Processor Affinity in Betracht ziehen, wie von Glen Berry in diesem Artikel beschrieben. Die Prozessoraffinität kann auch verwendet werden, um zu steuern, wie CPU-Ressourcen zwischen Instanzen geteilt werden, genau wie Sie den Arbeitsspeicher steuern. Stacking berücksichtigt auch Sicherheitsbedenken für Anwendungen, die beispielsweise das SA-Konto verwenden müssen, oder Konfigurationsbedenken für Anwendungen, die eine dedizierte Instanz erfordern, oder solche Optionen sind eine bestimmte Sortierung. Bedenken hinsichtlich der Leistung der gemeinsam genutzten TempDB sind ein weiterer Grund dafür, dass Sie möglicherweise alle Datenbanken auf einer geclusterten Instanz stapeln sollten, anstatt sie in einen Topf zu werfen.
Es ist erwähnenswert, dass der Wert des Clustering, wie zuvor hervorgehoben, beim Stacking sogar noch weiter geht. Wenn Sie beispielsweise eine SQL Server-Instanz mit mehreren FCIs patchen, können alle FCIs auf einmal gepatcht werden.
Hinweise
Bei der Verwendung von Clustering werden bestimmte Konventionen die Verwaltung und Verwaltung der Umgebung ein wenig einfacher machen und die Assets besser schwitzen. Wir werden einige davon kurz ansprechen:
- Aktuelle Client-Tools – Möglicherweise erhalten Sie ungewöhnliche Fehler, wenn Sie versuchen, eine SQL Server 2016-Instanz mit SQL Server Management Studio 2012 zu verwalten. Die Fehler weisen nicht ausdrücklich darauf hin, dass das Problem die Client-Tool-Version ist. Wir haben normalerweise eine SQL Server Management Studio 17.3-Instanz auf dem Client, den wir verwenden möchten, um eine Verbindung zu unseren Instanzen herzustellen.
- Namenskonventionen – Eine Namenskonvention macht es Ihnen leicht, sicher zu sein, an welcher Instanz Sie zu einem bestimmten Zeitpunkt arbeiten. Durch die Verwendung von Aliasnamen können Sie die Last reduzieren, sich lange Instanznamen für Endbenutzer zu merken, die Zugriff auf die Datenbank benötigen.
- Bevorzugter Knoten – Das Festlegen eines bevorzugten Knotens für jede SQL Server-Rolle im Failovercluster-Manager ist eine gute Idee, um sicherzustellen, dass die Verarbeitungsleistung aller Ihrer Cluster-Knoten genutzt wird. In unserem Shop haben wir nach dem Einrichten bevorzugter Knoten die Rolle so konfiguriert, dass sie zwischen 05:00 Uhr und 06:00 Uhr zurückfällt, falls es zu einem versehentlichen Failover kommt.
- Versand von Transaktionsprotokollen – Bei der Konfiguration von Disaster Recovery für FCIs ist es sinnvoll, alle UNC-Pfade mit virtuellen Namen zu identifizieren, nicht mit den Namen oder IP-Adressen der Cluster-Knoten. Dadurch wird sichergestellt, dass die Dinge weiterhin ordnungsgemäß funktionieren, wenn ein Failover auftritt. Es ist auch sehr wichtig sicherzustellen, dass die SQL Server-Agent-Konten auf beiden Sites die volle Kontrolle über diese Pfade haben.
Auflistung 2: Konfigurieren Sie die Überwachung für den Versand von Transaktionsprotokollen per E-Mail
-- Create Table to Store Log Shipping Data
create table msdb dbo log_shipping_report
(status bit,
is_primary bit,
server sysname,
database_name sysname,
time_since_last_backup int,
last_backup_file nvarchar (500),
backup_threshold int,
is_backup_alert_enabled bit,
time_since_last_copy int,
last_copied_file nvarchar 500),
time_since_last_restore int,
last_restored_file nvarchar(500),
last_restored_latency int,
restore_threshold int,
is_restore_alert_enabled bit);
go
-- Create an SQL Agent Job with the Following Script
-- This will send an Email at Intervals determined by the job Schedule
-- The Job Should be Created on the Log Shipping Secondary Clustered Instance
-- This Job Requires that Database Mail is Enabled
truncate table msdb dbo log_shipping_report
go
insert into msdb dbo log_shipping_report
EXEC sp_help_log_shipping_monitor;
go
/*
select [server]
, database_name [database]
, time_since_last_copy [Last Copy Time]
, last_copied_file [Last Copied File]
, time_since_last_restore [Last Restore Time]
, last_restored_file [Last Restored File]
, restore_threshold [Restore Threshold]
, restore_threshold - time_since_last_restore [Restore Latency]
from msdb.dbo.log_shipping_report;
go
*/
DECLARE @tableHTML NVARCHAR(MAX) ;
DECLARE @SecServer SYSNAME ;
SET @SecServer = @@SERVERNAME
SET @tableHTML =
N'<H1><font face="Verdana" size="4">Transaction Logshipping Status from Secondary
Server ' + @SecServer + N'</H1>' +
N'<p style="margin-top: 0; margin-bottom: 0"><font face="Verdana" size="2">Please
find below status of Secondary databases: </font></p> ' +
N'<table border="1" style="BORDER-COLLAPSE: collapse" borderColor="#111111"
cellPadding="0" width="2000" bgColor="#ffffff" borderColorLight="#000000"
border="1"><font face="Verdana" size="2">' +
N'<tr><th><font face="Verdana" size="2">Secondary Server</th>
<th><font face="Verdana" size="2">Secondary Database</th>
<th><font face="Verdana" size="2">Last Copy Time</th>' +
N'<th><font face="Verdana" size="2">Last Copied File</th><th>
<font face="Verdana" size="2">Last Restore Time</th>' +
N'<th><font face="Verdana" size="2">Last Restored File</th><th>
<font face="Verdana" size="2">Restore Threshold</th>
<th><font face="Verdana" size="2">Restore Latency</th>' +
CAST ( ( SELECT td = lsr.server, '',
td = lsr [database_name], td = lsr time_since_last_copy '',
td = lsr last_copied_file td = lsr time_since_last_restore '',
td = lsr last_restored_file, '',
td = lsr restore_threshold '',
td =
case
when lsr restore_threshold
lsr time_since_last_restore < 0 then + '<td bgcolor="#FFCC99"><b><font face="Verdana"
size="1">' + 'CRITICAL' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore < 20 and lsr restore_threshold
lsr time_since_last_restore > 0 then + '<td bgcolor="#FFBB33"><b><font face="Verdana
size="1">' + 'WARNING' + '</font></b></td>'
when lsr restore_threshold
lsr time_since_last_restore > 20 then + '<td bgcolor="#21B63F"><b><font face="Verdana
size="1">' + 'OK' + '</font></b></td>'
end , ''
FROM msdb dbo log_shipping_report as lsr
ORDER BY lsr.[database_name]
FOR XML PATH('tr'), TYPE ) AS NVARCHAR(MAX) ) +
N'</table>' + ' ';
EXEC msdb dbo.sp_send_dbmail
@recipients='example@sqldat.com',
@copy_recipients='example@sqldat.com',
@subject = 'Transaction Log Shipping Report',
@body = @tableHTML,
@body_format = 'HTML' ;
Laufwerke
Ein Nebeneffekt des Stapelns von SQL Server-Instanzen und des Bereitstellens mehrerer Datenbanken ist die Tendenz, dass die Laufwerksbuchstaben ausgehen. Wir haben dieses Problem umgangen, indem wir Volume Mount Points konfiguriert haben. Jeder einer Clusterrolle zugewiesene Datenträger wird als Bereitstellungspunkt mit einem Laufwerksbuchstaben konfiguriert, der nur für ein oder zwei Laufwerke pro Instanz erforderlich ist. Ein wichtiger Punkt, der bei der Verwendung von Volume-Mount-Punkten in einem Cluster zu beachten ist, ist, dass es in Zukunft erforderlich sein wird, SOWOHL das primäre Laufwerk, das den Laufwerksbuchstaben besitzt, als auch das Mount zu platzieren, wenn Sie weitere Mount-Punkte hinzufügen müssen, um ähnliche Wartungsaufgaben durchzuführen Punkt im Wartungsmodus auf dem Cluster.
In unserem Fall haben wir den Namen jedes Volume-Bereitstellungspunkts basierend auf der Cluster-Rolle gefunden, der er zugewiesen wurde. Bei so vielen Laufwerken, mit denen Sie sich befassen müssen, müssten Sie und der Speicheradministrator auf jeden Fall einen Weg finden, um eine Festplatte eindeutig zu identifizieren, sodass beispielsweise die Verwaltung der Festplatten auf Speicherebene kein großer Aufwand wäre.
Auflistung 3: Überwachen Sie die Speicherplatznutzung bei der Verwendung von Volume-Bereitstellungspunkten
-- The Following Script Will Show Disk Space Usage from Within SQL Server -- It is Especially Helpful When Using Volume Mount Points -- Volume Mount Point Space Usage Can Also Be Monitored from Computer Management (OS Level) SELECT DISTINCT vs volume_mount_point , vs file_system_type , vs logical_volume_name , CONVERT(DECIMAL!18 2 vs total_bytes 1073741824.0) AS [Total Size (GB)] , CONVERT(DECIMAL(18 2 vs available_bytes 1073741824.0' AS [Available Size (GB)] , CAST(CAST(vs available_bytes AS FLOAT)/ CAST(vs total_bytes AS FLOAT) AS DECIMAL (18,2)) * 100 AS [Space Free %] FROM sys.master_files AS f WITH (NOLOCK) CROSS APPLY sys.dm_os_volume_stats f database_id, f [file_id]i AS vs OPTION (RECOMPILE);
Datenbankbereitstellung
In unserem Fall bestand unsere Strategie darin sicherzustellen, dass neue Datenbanken unserem Standard entsprechen. Ältere Datenbanken wurden mit etwas mehr Sorgfalt behandelt, da wir gleichzeitig eine Art Konsolidierung und Aktualisierung durchführten. Der Datenbankmigrationsassistent hat uns geholfen, uns mitzuteilen, welche Datenbanken definitiv nicht mit unserer geheiligten SQL Server 2016-Instanz kompatibel wären, und wir haben sie in Ruhe gelassen (einige mit Kompatibilitätsstufen von nur 100). Jede bereitgestellte Datenbank sollte je nach Größe über eigene Volumes für Daten und Protokolldateien verfügen. Die Verwendung separater Volumes für jede Datenbank ist ein weiterer Schritt in Richtung einer sehr gut organisierten Umgebung, was angesichts der potenziellen Komplexität dieser konsolidierten Umgebung wichtig ist. Die letzte Anweisung impliziert auch, dass Sie als DBA die Datendateien nach Abschluss der Bereitstellung verschieben müssen, wenn Sie einer Anwendung erlauben, ihre eigenen Datenbanken zu erstellen, da die Anwendung dieselben Dateispeicherorte verwendet, die von der Modelldatenbank verwendet werden.
Auflistung 4: Benutzerdatenbanken verschieben
-- 1. Set the database offline -- Be sure to replace DB_NAME with the actual database name ALTER DATABASE DB_NAME SET OFFLINE -- 2. Move the file or files to the new location. -- This means actually copying the datafiles at OS level -- You may also need grant the SQL Server Service account full permissions on the data file -- 3. For each file moved, run the following statement. ALTER DATABASE DB_NAME MODIFY FILE ( NAME = logical_name FILENAME = 'new_path\os_file_name') -- 4. Bring the database back online ALTER DATABASE database name SET ONLINE -- 5. Verify the file change: SELECT name, physical_name AS CurrentLocation, state_desc FROM sys.master_files WHERE database_id = DB_ID(N'DB_NAME');
Zugriffsverwaltung
Sie werden zustimmen, dass wir in unserer konsolidierten Umgebung am Ende eine sehr lange Liste von Objekten auf Serverebene haben könnten, wie z. B. Anmeldungen. Die Verwendung von Windows-Gruppen trägt dazu bei, diese Liste zu verkürzen und die Zugriffsverwaltung auf jeder geclusterten Instanz zu vereinfachen. In der Regel benötigen Sie in Active Directory erstellte Gruppen für Anwendungsadministratoren, die Zugriff benötigen, Anwendungsdienstkonten, Geschäftsbenutzer, die Berichte abrufen müssen, und natürlich Datenbankadministratoren. Ein wesentlicher Vorteil der Verwendung von Windows-Gruppen besteht darin, dass der Zugriff einfach gewährt oder entzogen werden kann, indem die Mitgliedschaft dieser Gruppen direkt in Active Directory verwaltet wird.
Dass dieser Vorteil im Bereich Access Management nur mit der Windows-Authentifizierung möglich ist, dürfte mittlerweile klar sein. SQL Server-Anmeldungen können nicht in Gruppen verwaltet werden.
Auflistung 5: Instanzanmeldungen, Datenbankbenutzer und ihre Rollen
create table #userlist (
[Server Name] varchar(20)
,[Database Name] varchar(50)
,[Database User] varchar(50)
, [Database Role] varchar(50)
, [Instance Login] varchar(50)
, [Status] varchar(15)
)
go
insert into #userlist
exec sp_MSforeachdb @command1 ='
USE [?]
IF ''?'' NOT IN ("tempdb","model"J"msdb"J"master")
BEGIN
select @@servername as instance_name , ''?'' as database_name , rp.name as database_user , mp.name as database_role , sp.name as instance_login , case
when sp.is_disabled = 1 then ''Disabled'' when sp.is_disabled = 0 then ''Enabled'' end
[login_status]
from sys.database_principals rp
left outer join sys.database_role_members drm on (drm.member_principal_id = rp.principal_id)
left outer join sys.database_principals mp on (drm.role_principal_id = mp.principal_id)
left outer join sys.server_principals sp on (rp.sid=sp.sid)
where rp.type_desc in (''WINDOWS_GROUP'',''WINDOWS_USER'',''SQL_USER'')
END' go
select * from #userlist go
drop table #userlist
Schlussfolgerung
Wir haben auf sehr hohem Niveau die Vorteile untersucht, die durch Clustering und Stacking von SQL Server-Instanzen als Mittel zur Erreichung von Konsolidierung, Kostenoptimierung und einfacher Verwaltung erzielt werden können. Wenn Sie in der Lage sind, große Hardware zu kaufen, können Sie diese Option ausprobieren und von den oben beschriebenen Vorteilen profitieren.