SQL Server bietet uns verschiedene Lösungen zum Replizieren oder Archivieren einer oder mehrerer Datenbanktabellen in einer anderen Datenbank oder derselben Datenbank mit unterschiedlichen Namen. Als SQL Server-Entwickler oder Datenbankadministrator können Sie Situationen begegnen, in denen Sie überprüfen müssen, ob die Daten in diesen beiden Tabellen identisch sind, und wenn die Daten versehentlich nicht zwischen diesen beiden Tabellen repliziert werden, müssen Sie die Daten synchronisieren zwischen den Tischen. Wenn Sie außerdem eine Fehlermeldung erhalten, die den Datensynchronisierungs- oder Replikationsprozess aufgrund von Schemaunterschieden zwischen den Quell- und Zieltabellen unterbricht, müssen Sie einen einfachen und schnellen Weg finden, um die Schemaunterschiede zu identifizieren, ALTER the tables to make das Schema auf beiden Seiten identisch und setzen Sie den Datensynchronisierungsprozess fort.
In anderen Situationen benötigen Sie eine einfache Möglichkeit, die Antwort JA oder NEIN zu erhalten, wenn die Daten und das Schema zweier Tabellen identisch sind oder nicht. In diesem Artikel werden wir die verschiedenen Möglichkeiten zum Vergleichen der Daten und des Schemas zwischen zwei Tabellen durchgehen. Die in diesem Artikel bereitgestellten Methoden vergleichen Tabellen, die in verschiedenen Datenbanken gehostet werden, was das kompliziertere Szenario darstellt, und können auch leicht verwendet werden, um die Tabellen zu vergleichen, die sich in derselben Datenbank mit unterschiedlichen Namen befinden.
Bevor wir die verschiedenen Methoden und Tools beschreiben, die zum Vergleichen der Tabellendaten und -schemata verwendet werden können, bereiten wir unsere Demoumgebung vor, indem wir zwei neue Datenbanken erstellen und in jeder Datenbank eine Tabelle mit einem kleinen Datentypunterschied zwischen diesen beiden Tabellen erstellen in den folgenden T-SQL-Anweisungen CREATE DATABASE und CREATE TABLE gezeigt:
CREATE DATABASE TESTDB CREATE DATABASE TESTDB2 CREATE TABLE TESTDB.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address VARCHAR (500) ) GO CREATE TABLE TESTDB2.dbo.FirstComTable ( ID INT IDENTITY (1,1) PRIMARY KEY, FirstName VARCHAR (50), LastName VARCHAR (50), Address NVARCHAR (400) ) GO
Nach dem Erstellen der Datenbanken und Tabellen füllen wir die beiden Tabellen mit fünf identischen Zeilen und fügen dann nur in die erste Tabelle einen weiteren neuen Datensatz ein, wie in den INSERT INTO T-SQL-Anweisungen unten gezeigt:
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB2.dbo.FirstComTable VALUES ('AAA','BBB','CCC')
GO 5
INSERT INTO TESTDB.dbo.FirstComTable VALUES ('DDD','EEE','FFF')
GO Jetzt ist die Testumgebung bereit, um mit der Beschreibung der Daten- und Schemavergleichsmethoden zu beginnen.
Tabellendaten mit einem LEFT JOIN vergleichen
Das T-SQL-Schlüsselwort LEFT JOIN wird verwendet, um Daten aus zwei Tabellen abzurufen, indem alle Datensätze aus der linken Tabelle und nur die übereinstimmenden Datensätze aus der rechten Tabelle und NULL-Werte aus der rechten Tabelle zurückgegeben werden, wenn es keine Übereinstimmung zwischen den beiden Tabellen gibt.
Für Datenvergleichszwecke kann das Schlüsselwort LEFT JOIN verwendet werden, um zwei Tabellen zu vergleichen, basierend auf der gemeinsamen eindeutigen Spalte, wie in unserem Fall der ID-Spalte, wie in der folgenden SELECT-Anweisung:
SELECT * FROM TESTDB.dbo.FirstComTable F LEFT JOIN TESTDB2.dbo.FirstComTable S ON F.ID =S.ID
Die vorherige Abfrage gibt die gemeinsamen fünf Zeilen zurück, die in den beiden Tabellen vorhanden sind, zusätzlich zu der Zeile, die in der ersten Tabelle vorhanden ist und in der zweiten fehlt, indem NULL-Werte auf der rechten Seite des Ergebnisses angezeigt werden, wie unten gezeigt:
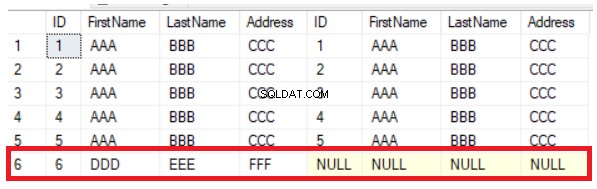
Sie können aus dem vorherigen Ergebnis leicht ableiten, dass die sechste Spalte, die in der ersten Tabelle vorhanden ist, in der zweiten Tabelle fehlt. Um die Zeilen zwischen den Tabellen zu synchronisieren, müssen Sie den neuen Datensatz manuell in die zweite Tabelle einfügen. Die LEFT JOIN-Methode ist hilfreich beim Überprüfen der neuen Zeilen, hilft jedoch nicht beim Aktualisieren der Spaltenwerte. Wenn Sie den Wert der Adressspalte der 5. Zeile ändern, erkennt die LEFT JOIN-Methode diese Änderung nicht, wie unten deutlich gezeigt wird:
Tabellendaten mit EXCEPT-Klausel vergleichen
Die EXCEPT-Anweisung gibt die Zeilen aus der ersten Abfrage (linke Abfrage) zurück, die nicht von der zweiten Abfrage (rechte Abfrage) zurückgegeben werden. Mit anderen Worten, die EXCEPT-Anweisung gibt die Differenz zwischen zwei SELECT-Anweisungen oder Tabellen zurück, was uns hilft, die Daten in diesen Tabellen einfach zu vergleichen.
Die EXCEPT-Anweisung kann verwendet werden, um die Daten in den zuvor erstellten Tabellen zu vergleichen, indem die Differenz zwischen der SELECT *-Abfrage aus der ersten Tabelle und der SELECT *-Abfrage aus der zweiten Tabelle unter Verwendung der folgenden T-SQL-Anweisungen genommen wird:
SELECT * FROM TESTDB.dbo.FirstComTable F EXCEPT SELECT * FROM TESTDB2.dbo. FirstComTable S
Das Ergebnis der vorherigen Abfrage ist die Zeile, die in der ersten Tabelle verfügbar und in der zweiten nicht verfügbar ist, wie unten gezeigt:
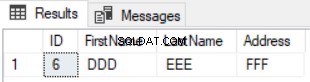
Die Verwendung der EXCEPT-Anweisung zum Vergleichen zweier Tabellen ist insofern besser als die LEFT JOIN-Anweisung, da die aktualisierten Datensätze im Ergebnis der Datenunterschiede erfasst werden. Angenommen, wir haben die Adresse der Zeile Nummer 5 in der zweiten Tabelle aktualisiert und den Unterschied erneut mit der EXCEPT-Anweisung überprüft, Sie werden sehen, dass die Zeile Nummer 5 mit dem unten gezeigten Unterschiedsergebnis zurückgegeben wird:
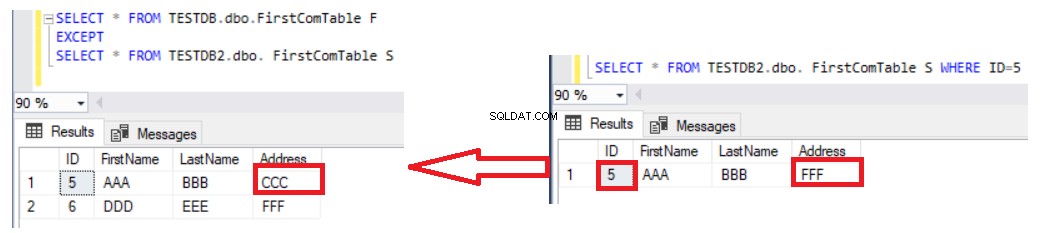
Der einzige Nachteil der Verwendung der EXCEPT-Anweisung zum Vergleichen der Daten in zwei Tabellen besteht darin, dass Sie die Daten manuell synchronisieren müssen, indem Sie eine INSERT-Anweisung für die fehlenden Datensätze in der zweiten Tabelle schreiben. Berücksichtigen Sie, dass die beiden verglichenen Tabellen Schlüsseltabellen sind, um das richtige Ergebnis zu erhalten, wobei ein eindeutiger Schlüssel für den Vergleich verwendet wird. Wenn wir die eindeutige ID-Spalte aus der SELECT-Anweisung auf beiden EXCEPT-Anweisungsseiten entfernen und die restlichen Nicht-Schlüsselspalten auflisten, wie in der folgenden Anweisung:
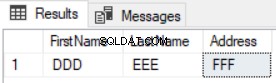
SELECT FirstName, LastName, Address FROM TESTDB.dbo. FirstComTable F EXCEPT SELECT FirstName, LastName, Address FROM TESTDB2.dbo. FirstComTable S
Das Ergebnis zeigt, dass nur die neuen Datensätze zurückgegeben werden und die aktualisierten nicht aufgelistet werden, wie im folgenden Ergebnis gezeigt:
Tabellendaten mit UNION ALL … GROUP BY vergleichen
Die UNION ALL-Anweisung kann auch verwendet werden, um die Daten in zwei Tabellen basierend auf einer eindeutigen Schlüsselspalte zu vergleichen. Um die UNION ALL-Anweisung zum Zurückgeben der Differenz zwischen zwei Tabellen zu verwenden, müssen Sie die zu vergleichenden Spalten in der SELECT-Anweisung auflisten und diese Spalten in der GROUP BY-Klausel verwenden, wie in der T-SQL-Abfrage unten gezeigt:
SELECT DISTINCT *
FROM
(
SELECT * FROM
( SELECT * FROM TESTDB.dbo. FirstComTable
UNION ALL
SELECT * FROM TESTDB2.dbo. FirstComTable) Tbls
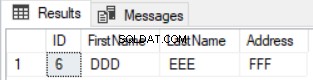
GROUP BY ID,FirstName, LastName, Address
HAVING COUNT(*)<2) Diff Und nur die Zeile, die in der ersten Tabelle vorhanden ist und in der zweiten Tabelle fehlt, wird wie unten gezeigt zurückgegeben:
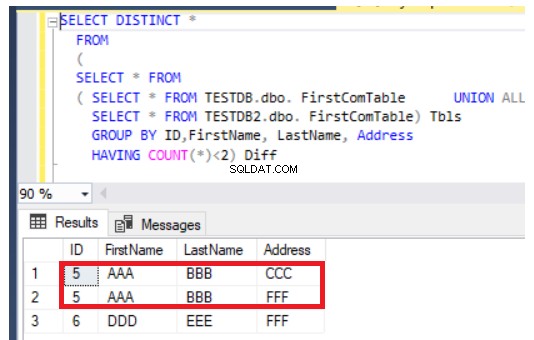
Die vorherige Abfrage funktioniert auch beim Aktualisieren von Datensätzen, jedoch auf andere Weise. Es gibt die neu eingefügten Datensätze zusätzlich zu den aktualisierten Spalten aus beiden Tabellen zurück, wie im Fall von Zeile Nummer 5, unten gezeigt:
Tabellendaten mit SQL Server Data Tools vergleichen
SQL Server Data Tools, auch bekannt als SSDT, das auf Microsoft Visual Studio aufgebaut ist, kann einfach verwendet werden, um die Daten in zwei Tabellen mit demselben Namen zu vergleichen, basierend auf einer eindeutigen Schlüsselspalte, die in zwei verschiedenen Datenbanken gehostet wird, und die Daten in diesen Tabellen zu synchronisieren , oder generieren Sie ein Synchronisationsskript zur späteren Verwendung.
Klicken Sie im geöffneten SSDT-Fenster auf das Menü Extras -> SQL Server-Liste und wählen Sie Neuer Datenvergleich Option, wie unten gezeigt:
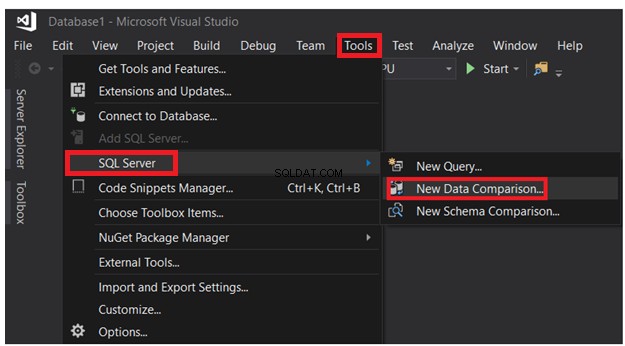
Im angezeigten Verbindungsfenster können Sie aus den zuvor verbundenen Sitzungen auswählen oder das Fenster Verbindungseigenschaften mit dem SQL Server-Namen, den Anmeldeinformationen und dem Datenbanknamen füllen und dann auf Verbinden klicken , wie unten gezeigt:

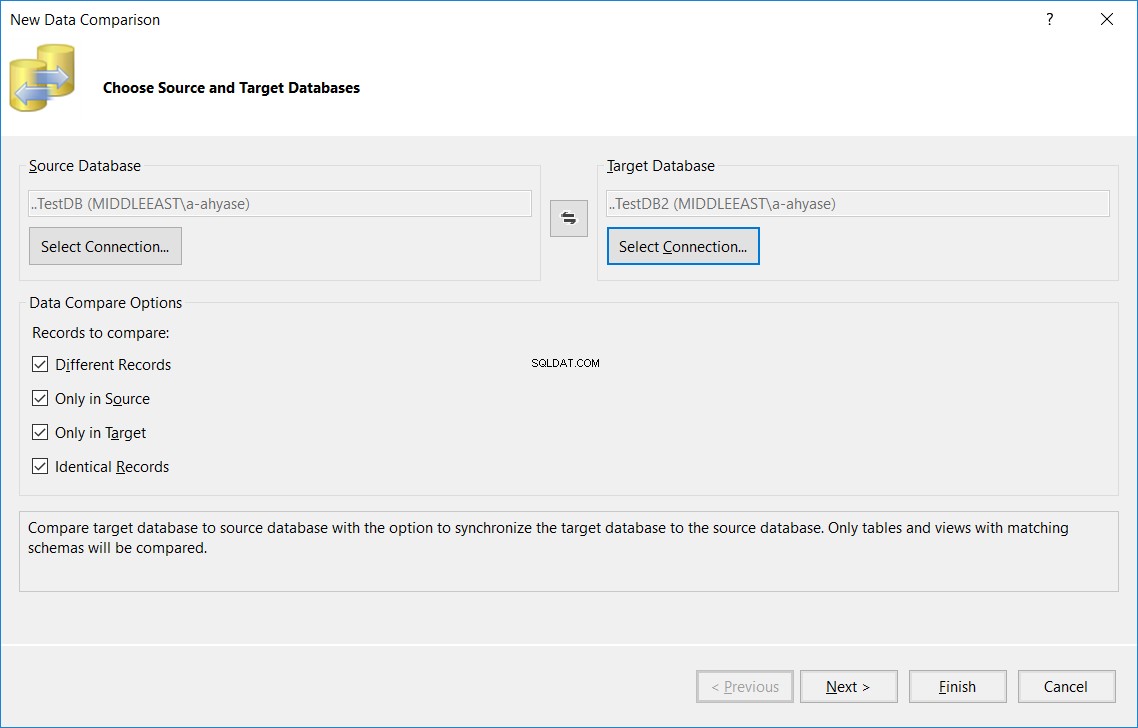
Geben Sie im angezeigten Assistenten für den Vergleich neuer Daten die Quell- und Zieldatenbanknamen sowie die Vergleichsoptionen an, die im Tabellenvergleichsprozess verwendet werden, und klicken Sie dann auf Weiter , wie unten gezeigt:
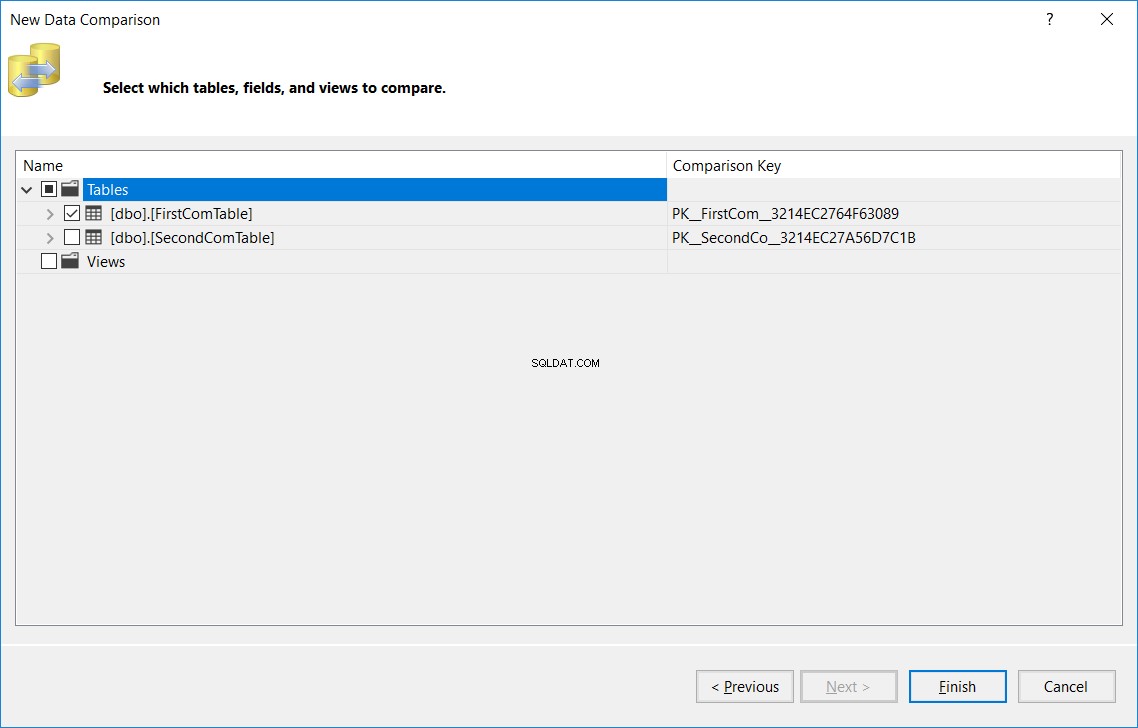
Geben Sie im nächsten Fenster den Namen der Tabelle an, die in den Quell- und Zieldatenbanken identisch sein sollte, die in beiden Datenbanken verglichen werden soll, und klicken Sie auf Fertig stellen , wie unten:
Das angezeigte Ergebnis zeigt Ihnen die Anzahl der Datensätze, die in der Quelle gefunden und vom Ziel übersehen wurden, die im Ziel gefunden und von der Quelle übersehen wurden, die Anzahl der aktualisierten Datensätze mit demselben Schlüssel und unterschiedlichen Spaltenwerten (Unterschiedliche Datensätze). und schließlich die Anzahl identischer Datensätze, die in beiden Tabellen gefunden wurden, wie unten gezeigt:
Klicken Sie auf den Tabellennamen im vorherigen Ergebnis, Sie finden eine detaillierte Ansicht dieser Ergebnisse, wie unten gezeigt:

Sie können dasselbe Tool verwenden, um ein Skript zum Synchronisieren der Quell- und Zieltabellen zu generieren oder die Zieltabelle direkt mit den fehlenden oder anderen Änderungen zu aktualisieren, wie unten gezeigt:
Wenn Sie auf die Option Skript generieren klicken, wird eine INSERT-Anweisung mit der fehlenden Spalte in der Zieltabelle angezeigt, wie unten gezeigt:
BEGIN TRANSACTION
BEGIN TRANSACTION SET IDENTITY_INSERT [dbo].[FirstComTable] ON INSERT INTO [dbo].[FirstComTable] ([ID], [FirstName], [LastName], [Address]) VALUES (6, N'DDD', N'EEE', N'FFF') SET IDENTITY_INSERT [dbo].[FirstComTable] OFF COMMIT TRANSACTION
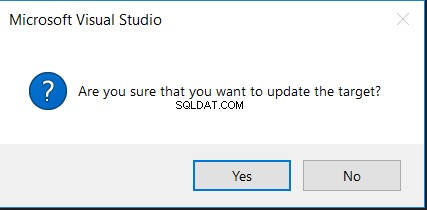
Wenn Sie die Option „Ziel aktualisieren“ auswählen, werden Sie zunächst um Ihre Bestätigung gebeten, um die Änderung durchzuführen, wie in der folgenden Meldung dargestellt:
Nach der Synchronisierung werden Sie sehen, dass die Daten in den beiden Tabellen identisch sind, wie unten gezeigt:
Tabellendaten mit dem Drittanbieter-Tool „dbForge Studio for SQL Server“ vergleichen
In der SQL-Server-Welt finden Sie eine Vielzahl von Tools von Drittanbietern, die das Leben der Datenbankadministratoren und -entwickler erleichtern. Eines dieser Tools, das die Aufgaben der Datenbankverwaltung zu einem Kinderspiel macht, ist dbForge Studio für SQL Server, das uns einfache Möglichkeiten zur Durchführung der Datenbankverwaltungs- und -entwicklungsaufgaben bietet. Dieses Tool kann uns auch dabei helfen, die Daten in den Datenbanktabellen zu vergleichen und diese Tabellen zu synchronisieren.
Wählen Sie im Vergleichsmenü Neuer Datenvergleich Option, wie unten gezeigt:
Geben Sie im Assistenten für den neuen Datenvergleich die Quell- und Zieldatenbank an und klicken Sie dann auf Weiter :
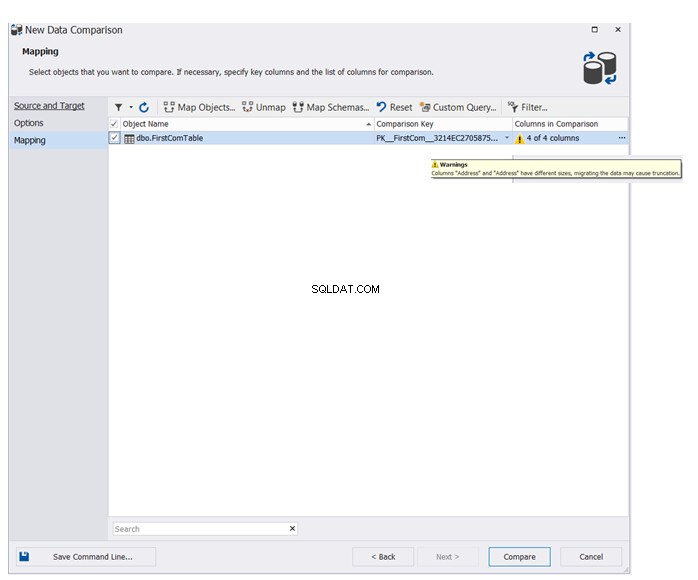
Wählen Sie aus der Vielzahl der verfügbaren Zuordnungs- und Vergleichsoptionen die passenden aus und klicken Sie auf Weiter :
Geben Sie den Namen der Tabelle oder Tabellen an, die am Datenvergleichsprozess teilnehmen. Der Assistent zeigt eine Warnmeldung an, falls Schemaunterschiede zwischen den Quell- und Zieldatenbanktabellen bestehen. Klicken Sie auf Vergleichen um fortzufahren:
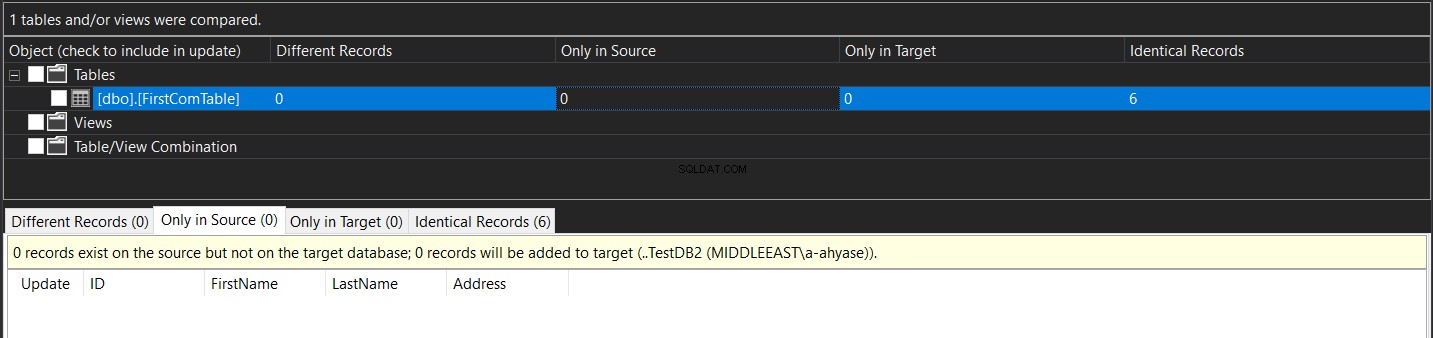
Das Endergebnis zeigt Ihnen im Detail die Datenunterschiede zwischen den Quell- und Zieltabellen mit der Möglichkeit zum Klicken  zum Synchronisieren der Quell- und Zieltabellen, wie unten gezeigt:
zum Synchronisieren der Quell- und Zieltabellen, wie unten gezeigt:
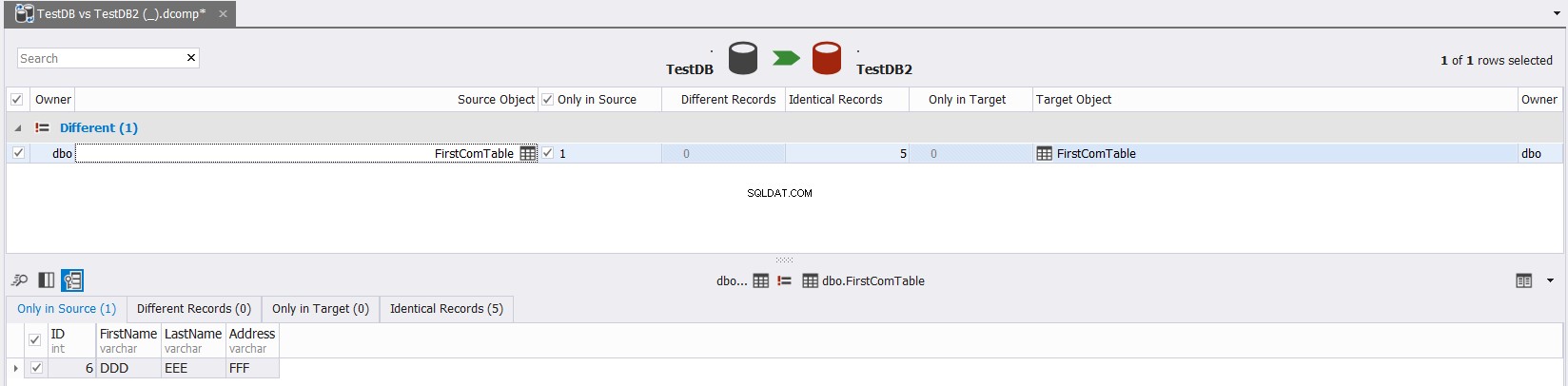
Tabellenschema mit sys.columns vergleichen
Wie am Anfang dieses Artikels erwähnt, müssen Sie zum Replizieren oder Archivieren einer Tabelle sicherstellen, dass das Schema der Quell- und Zieltabelle identisch ist. SQL Server bietet uns verschiedene Möglichkeiten, das Schema der Tabellen in derselben Datenbank oder in verschiedenen Datenbanken zu vergleichen. Die erste Methode ist die Abfrage der Systemkatalogansicht sys.columns, die eine Zeile für jede Spalte eines Objekts zurückgibt, das eine Spalte mit den Eigenschaften jeder Spalte enthält.
Um das Schema von Tabellen zu vergleichen, die sich in verschiedenen Datenbanken befinden, müssen Sie die sys.columns mit dem Tabellennamen unter der aktuellen Datenbank bereitstellen, ohne eine in einer anderen Datenbank gehostete Tabelle bereitstellen zu können. Um dies zu erreichen, werden wir die sys.columns zweimal abfragen, das Ergebnis jeder Abfrage in einer temporären Tabelle speichern und schließlich das Ergebnis dieser beiden Abfragen mit dem EXCEPT T-SQL-Befehl vergleichen, wie unten deutlich gezeigt:
USE TESTDB SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DBSchema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable') GO USE TestDB2 GO SELECT name, system_type_id, user_type_id,max_length, precision,scale, is_nullable, is_identity INTO #DB2Schema FROM sys.columns WHERE object_id = OBJECT_ID(N'dbo.FirstComTable '); GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Das Ergebnis zeigt uns, dass die Definition der Adressspalte in diesen beiden Tabellen unterschiedlich ist, ohne spezifische Informationen über den genauen Unterschied, wie unten gezeigt:

Tabellenschema mit INFORMATION_SCHEMA.COLUMNS vergleichen
Die Systemansicht INFORMATION_SCHEMA.COLUMNS kann auch verwendet werden, um das Schema verschiedener Tabellen zu vergleichen, indem der Tabellenname angegeben wird. Um zwei Tabellen zu vergleichen, die in unterschiedlichen Datenbanken gehostet werden, fragen wir erneut INFORMATION_SCHEMA.COLUMNS zweimal ab, speichern das Ergebnis jeder Abfrage in einer temporären Tabelle und vergleichen schließlich das Ergebnis dieser beiden Abfragen mit dem T-SQL-Befehl EXCEPT, wie gezeigt deutlich unten:
USE TestDB SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DBSchema FROM [INFORMATION_SCHEMA].[COLUMNS] SC1 WHERE SC1.TABLE_NAME='FirstComTable' GO USE TestDB2 SELECT COLUMN_NAME, IS_NULLABLE,DATA_TYPE,CHARACTER_MAXIMUM_LENGTH, NUMERIC_PRECISION,NUMERIC_SCALE INTO #DB2Schema FROM [INFORMATION_SCHEMA].[COLUMNS] SC2 WHERE SC2.TABLE_NAME='FirstComTable' GO SELECT * FROM #DBSchema EXCEPT SELECT * FROM #DB2Schema
Und das Ergebnis wird dem vorherigen irgendwie ähnlich sein, was zeigt, dass die Definition der Adressspalte in diesen beiden Tabellen unterschiedlich ist, ohne spezifische Informationen über den genauen Unterschied, wie unten gezeigt:

Tabellenschema mit dm_exec_describe_first_result_set vergleichen
Die Tabellenschemata können auch durch Abfragen der dynamischen Verwaltungsfunktion dm_exec_describe_first_result_set verglichen werden, die eine Transact-SQL-Anweisung als Parameter verwendet und die Metadaten der ersten Ergebnismenge für die Anweisung beschreibt.
Um das Schema zweier Tabellen zu vergleichen, müssen Sie die DMF dm_exec_describe_first_result_set mit sich selbst verknüpfen und die SELECT-Anweisung aus jeder Tabelle als Parameter bereitstellen, wie in der folgenden T-SQL-Abfrage:
SELECT FT.name , ST.name , FT.system_type_name , ST.system_type_name , FT.max_length , ST.max_length , FT.precision , ST.precision , FT.scale , ST.scale , FT.is_nullable , ST.is_nullable , FT.is_identity_column , ST.is_identity_column FROM sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB.DBO.FirstComTable', NULL, 0) FT LEFT OUTER JOIN sys.dm_exec_describe_first_result_set (N'SELECT * FROM TestDB2.DBO.FirstComTable', NULL, 0) ST ON FT.Name =ST.Name GO
Das Ergebnis wird dieses Mal klarer, da Sie den Unterschied zwischen den beiden Tabellen, dh die Größe und den Typ der Adressspalte, wie unten gezeigt, mit dem Auge vergleichen können:

Tabellenschema mit SQL Server Data Tools vergleichen
SQL Server Data Tools kann auch verwendet werden, um das Schema von Tabellen zu vergleichen, die sich in verschiedenen Datenbanken befinden. Wählen Sie im Menü „Extras“ die Option Neuer Schemavergleich aus Option aus der SQL Server-Optionsliste, wie unten gezeigt:
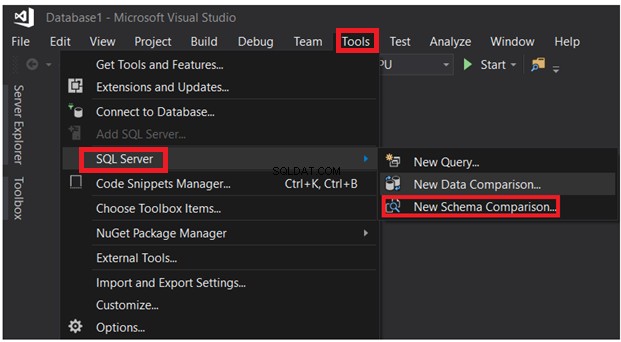
Nachdem Sie die Verbindungsparameter angegeben haben, klicken Sie auf die Schaltfläche Vergleichen:

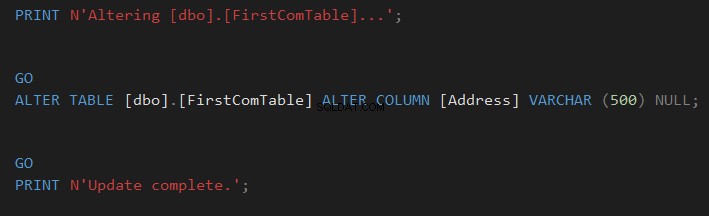
Das Vergleichsergebnis zeigt Ihnen insbesondere den Schemaunterschied zwischen den beiden Tabellen in Form von CREATE TABLE T-SQL-Befehlen, schattiert wie im folgenden Schnappschuss:
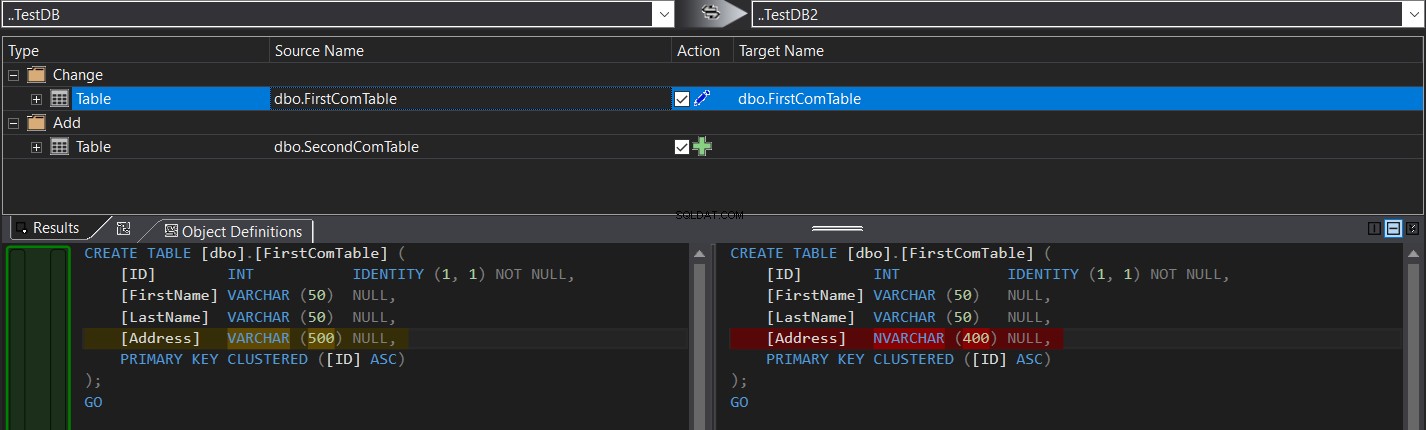
Sie können ganz einfach klicken  zum Synchronisieren des Tabellenschemas oder klicken Sie auf
zum Synchronisieren des Tabellenschemas oder klicken Sie auf  um die Änderung zu skripten und später auszuführen, wie unten gezeigt:
um die Änderung zu skripten und später auszuführen, wie unten gezeigt:
Tabellenschema mit dbForge Studio für SQL Server-Drittanbieter-Tool vergleichen
Das Tool dbForge Studio für SQL Server bietet uns die Möglichkeit, das Schema der verschiedenen Datenbanktabellen zu vergleichen. Wählen Sie im Menü „Vergleich“ die Option Neuer Schemavergleich aus Option, wie unten:
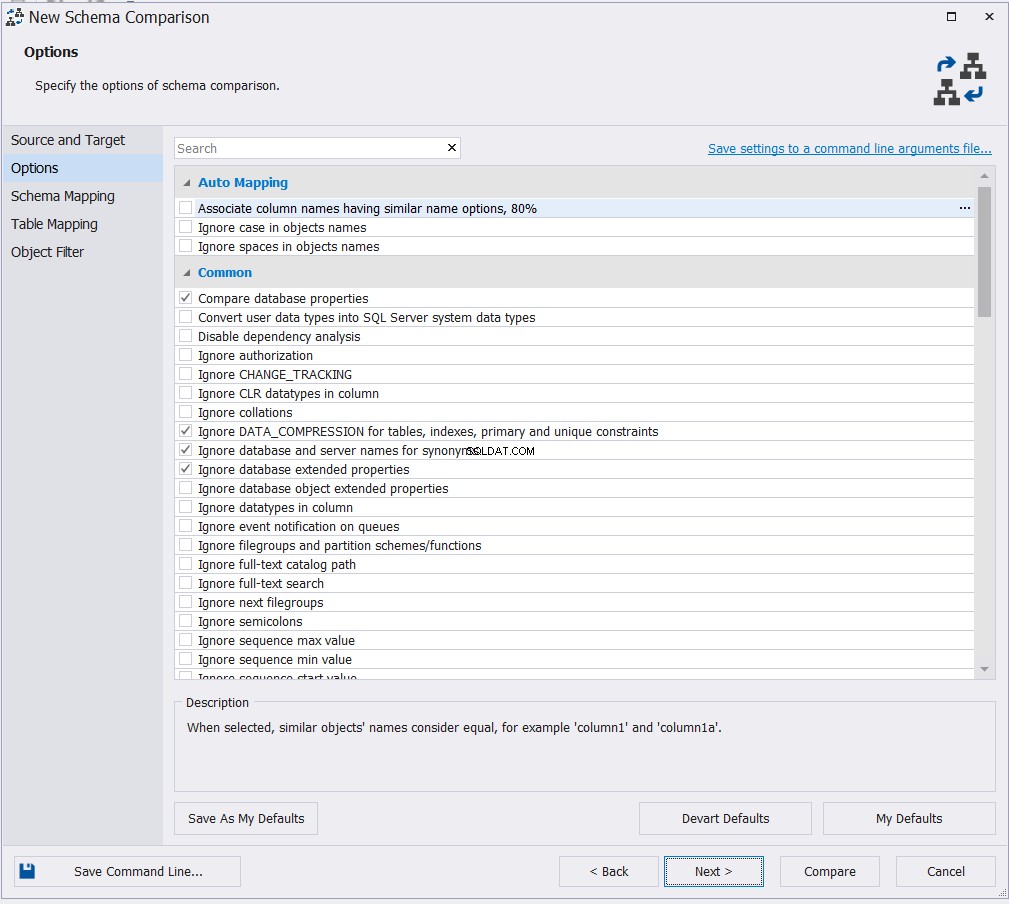
Nachdem Sie die Verbindungseigenschaften sowohl der Quell- als auch der Zieldatenbank angegeben haben, wählen Sie die geeignete Zuordnungsoption aus den verfügbaren Optionen aus und klicken Sie auf Weiter :
Wählen Sie die Schemas aus, deren Objekt Sie vergleichen möchten, und klicken Sie auf Weiter :
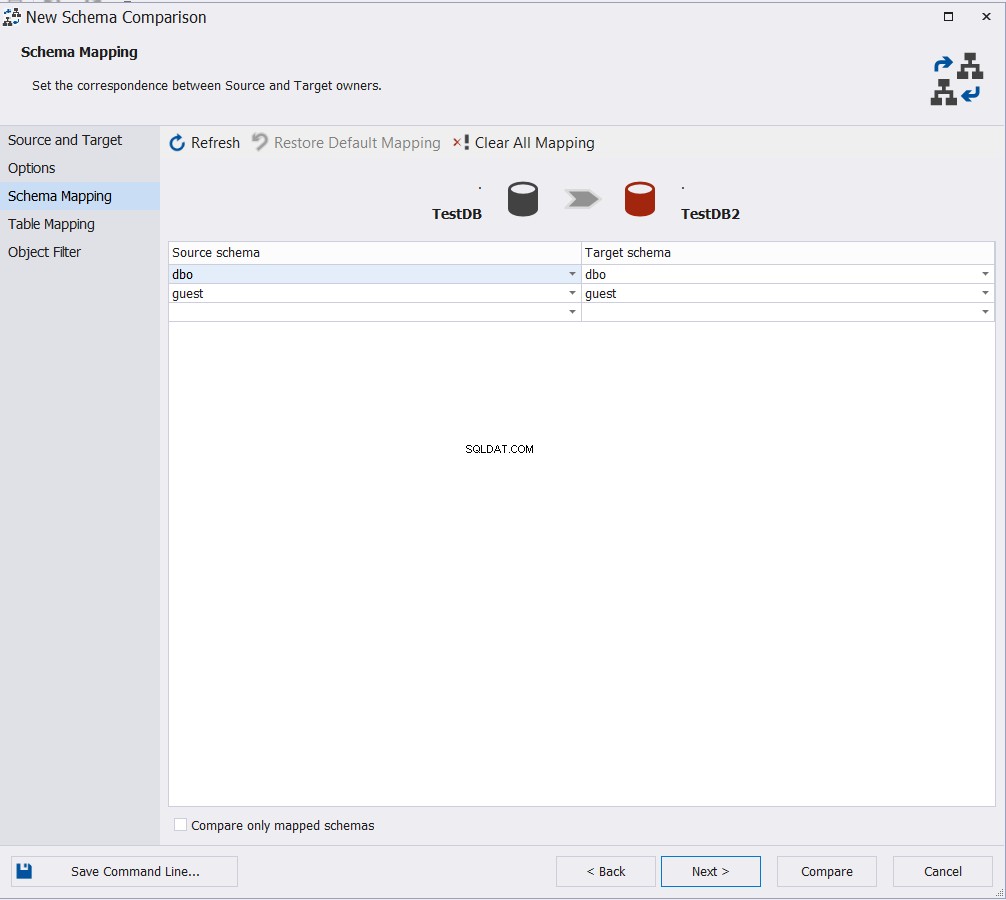
Geben Sie die Tabelle oder Tabellen an, die am Schemavergleichsprozess teilnehmen, und klicken Sie auf Vergleichen , wenn Sie die Änderung der Standardeinstellungen im Objektfilterfenster wie folgt überspringen möchten:
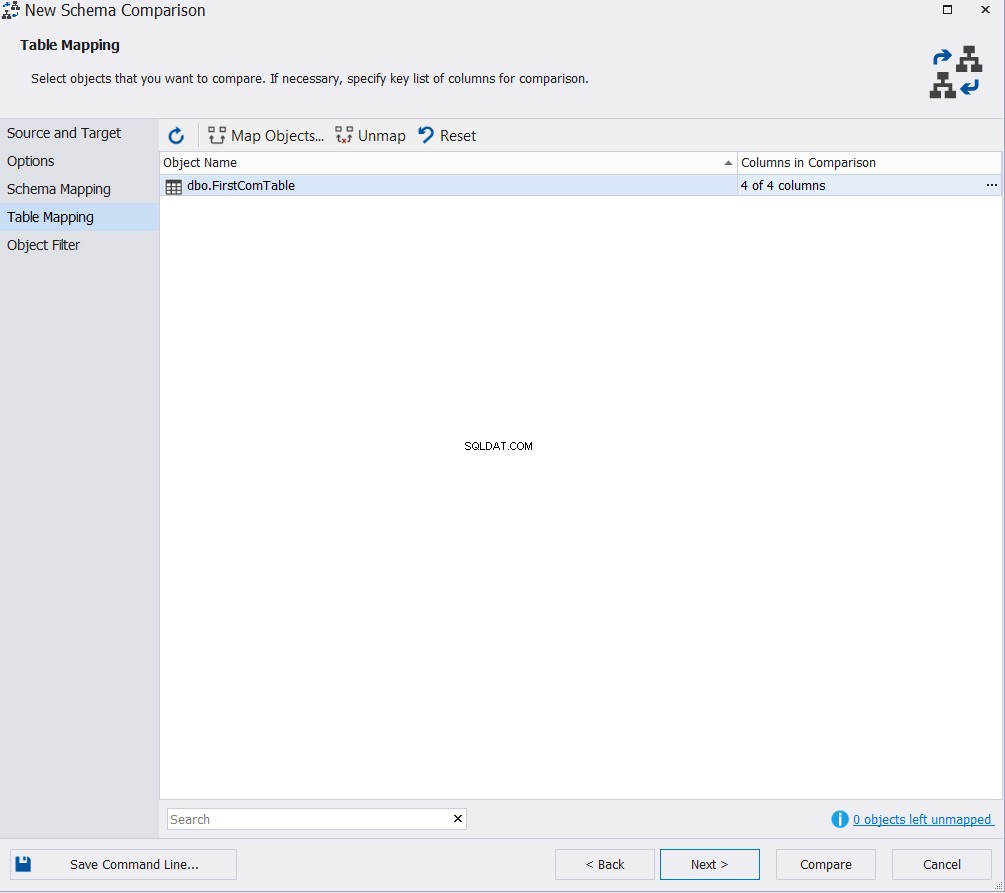
Das angezeigte Vergleichsergebnis zeigt Ihnen den Unterschied zwischen dem Schema der beiden Tabellen, indem genau der Teil des Datentyps hervorgehoben wird, der sich zwischen den beiden Spalten unterscheidet, mit der Möglichkeit, anzugeben, welche Aktion zum Synchronisieren der beiden Tabellen durchgeführt werden soll, wie unten gezeigt :
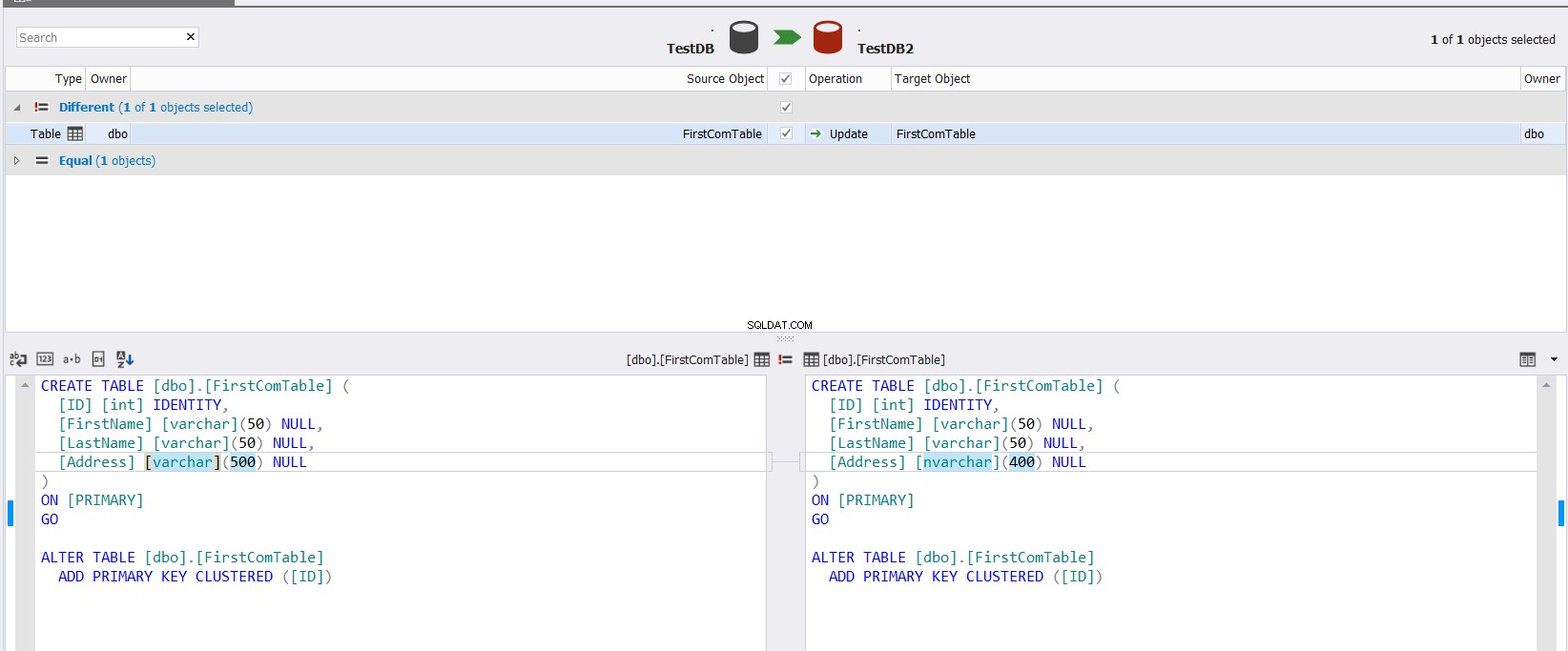
Wenn Sie das Schema der beiden Tabellen synchronisieren möchten, klicken Sie auf die Schaltfläche und geben Sie im Assistenten für die Schemasynchronisierung an, ob Sie die Änderung direkt in der Zieltabelle ausführen oder sie einfach per Skript für die zukünftige Verwendung wie folgt ausführen können:
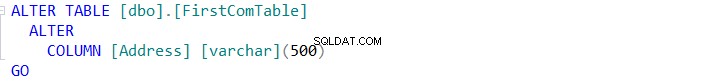
Nützliche Links:
- Festlegen von Operatoren – EXCEPT und INTERSECT (Transact-SQL)
- Operatoren festlegen – UNION (Transact-SQL)
- Laden Sie SQL Server Data Tools (SSDT) herunter
- Daten in einer oder mehreren Tabellen mit Daten in einer Referenzdatenbank vergleichen und synchronisieren
- sys.dm_exec_describe_first_result_set (Transact-SQL)
- sys.columns (Transact-SQL)
- Ansichten des Systeminformationsschemas (Transact-SQL)
Nützliche Tools:
dbForge Schema Compare für SQL Server – zuverlässiges Tool, das Ihnen Zeit und Mühe beim Vergleichen und Synchronisieren von Datenbanken auf SQL Server spart.
dbForge Data Compare for SQL Server – leistungsstarkes SQL-Vergleichstool, das mit großen Datenmengen arbeiten kann.