Einführung
Der Transaktionsprotokollversand ist eine sehr bekannte Technologie, die in SQL Server verwendet wird, um eine Kopie der Live-Datenbank auf der Disaster Recovery-Site zu verwalten. Die Technologie hängt von drei Schlüsseljobs ab:dem Sicherungsjob, dem Kopierjob und dem Wiederherstellungsjob. Während der Sicherungsjob auf dem Primärserver ausgeführt wird, werden die Kopier- und Wiederherstellungsjobs auf dem Sekundärserver ausgeführt. Im Wesentlichen umfasst der Prozess regelmäßige Sicherungen des Transaktionsprotokolls auf eine Freigabe, von der der Kopierauftrag auf den sekundären Server verschoben wird. Anschließend wendet der Wiederherstellungsjob die Protokollsicherungen auf dem sekundären Server an. Bevor dies alles beginnt, muss die sekundäre Datenbank mit einer vollständigen Sicherung vom primären Server initialisiert werden, die mit der Option NORECOVERY wiederhergestellt wurde.
Microsoft stellt eine Reihe gespeicherter Prozeduren bereit, mit denen der Protokollversand von Anfang bis Ende konfiguriert werden kann, sowie GUI-Äquivalente, beginnend mit dem Eigenschaftenelement jeder Datenbank, für die Sie den Protokollversand konfigurieren möchten. Beachten Sie, dass die sekundäre Datenbank im NORECOVERY-Modus oder im STANDBY-Modus konfiguriert werden kann. Im NORECOVERY-Modus steht die Datenbank niemals für Abfragen zur Verfügung, aber im STANDBY-Modus kann die sekundäre Datenbank abgefragt werden, wenn kein Transaktionsprotokoll-Wiederherstellungsvorgang im Gange ist.
Umgebung einrichten
Um den Stein ins Rollen zu bringen, erstellen wir zwei SQL Server-Instanzen auf AWS mit einem identischen Amazon EC2-Image. Auf dieser Amazon EC2-Instance wird SQL Server 2017 RTM-CU5 auf Windows Server 2016 ausgeführt. Dann stellen wir eine Kopie der WideWorldImporters-Datenbank mithilfe eines von GitHub erworbenen Sicherungssatzes auf der ersten Instance, unserer primären Instance, wieder her. Wir verwenden denselben Sicherungssatz, um zwei identische Datenbanken namens BranchDB und CorporateDB zu erstellen.
Abb. 1 SQL Server-Version
Abb. 2 BranchDB und CorporateDB auf primärer Instanz (sekundäre Instanz leer)
Listing 1:Wiederherstellen der WideWorldImporters-Beispieldatenbank
restore filelistonly from disk='WideWorldImporters-Full.bak' restore database CorporateDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_1.ndf' restore database BranchDB from disk='WideWorldImporters-Full.bak' with stats=10,recovery, move 'WWI_Primary' to 'M:\MSSQL\Data\WWI_Primary1.mdf' , move 'WWI_UserData' to 'M:\MSSQL\Data\WWI_UserData1.ndf' , move 'WWI_Log' to 'N:\MSSQL\Log\WWI_Log1.ldf', move 'WWI_InMemory_Data_1' to 'M:\MSSQL\Data\WWI_InMemory_Data_11.ndf
Wir haben jetzt zwei Instanzen, die primäre Instanz, die die beiden primären Datenbanken (BranchDB und CorporateDB) hostet, und die sekundäre Instanz ohne Benutzerdatenbanken. Wir fahren mit der Konfiguration des Transaktionsprotokollversands auf beiden Datenbanken fort, unterscheiden sie jedoch, indem wir eine Verzögerung auf die Wiederherstellungskonfiguration von anwenden erste Datenbank. Denken Sie daran, dass die Datenbanken in Bezug auf die Daten, die sie enthalten, tatsächlich identisch sind. Die folgenden Grafiken zeigen die wichtigsten Optionen, die in der Protokollversandkonfiguration ausgewählt wurden.
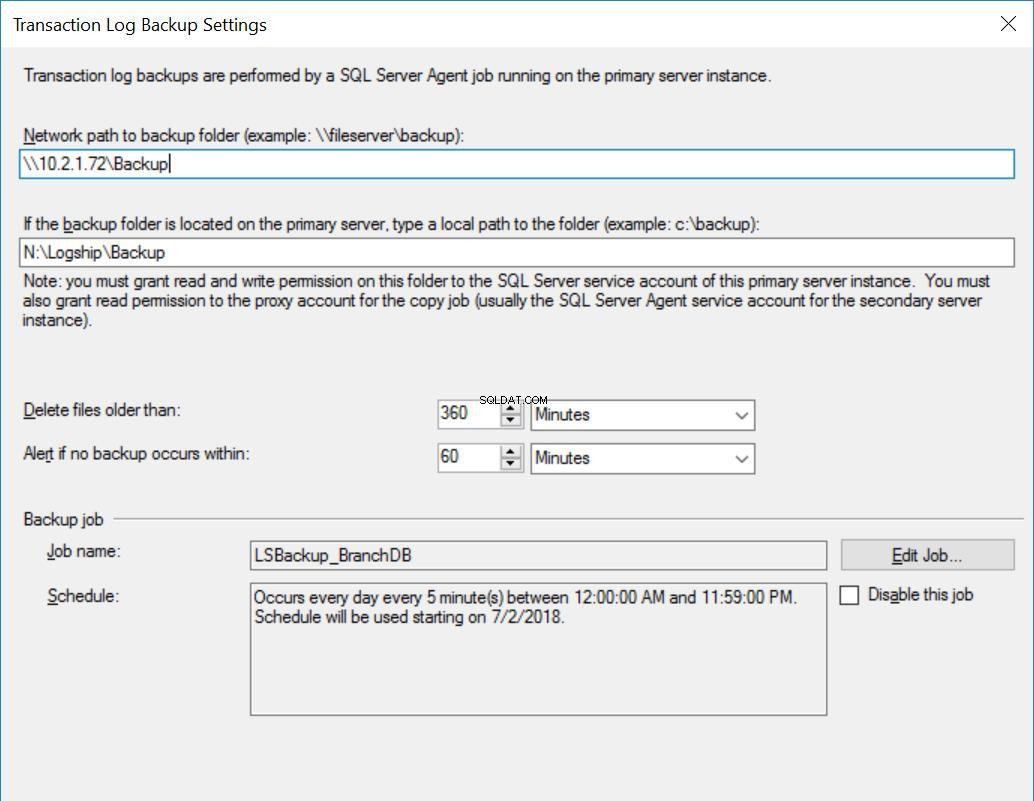
Abb. 3 Sicherungseinstellungen für BranchDB
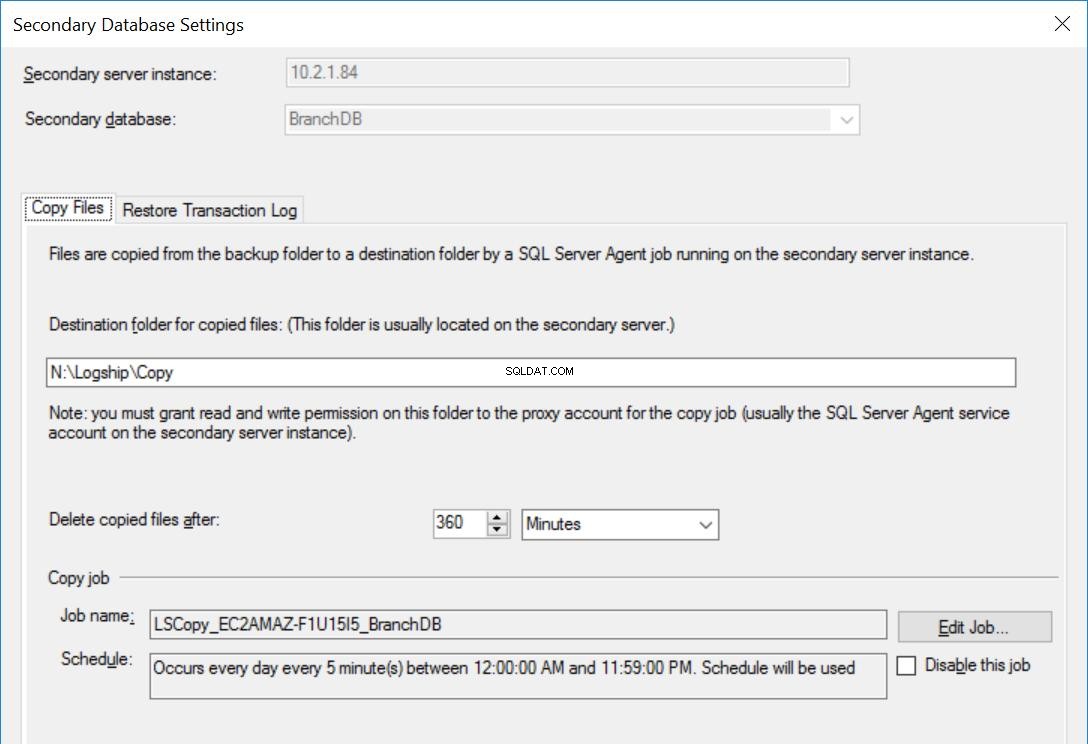
Abb. 4 Einstellungen für BranchDB kopieren
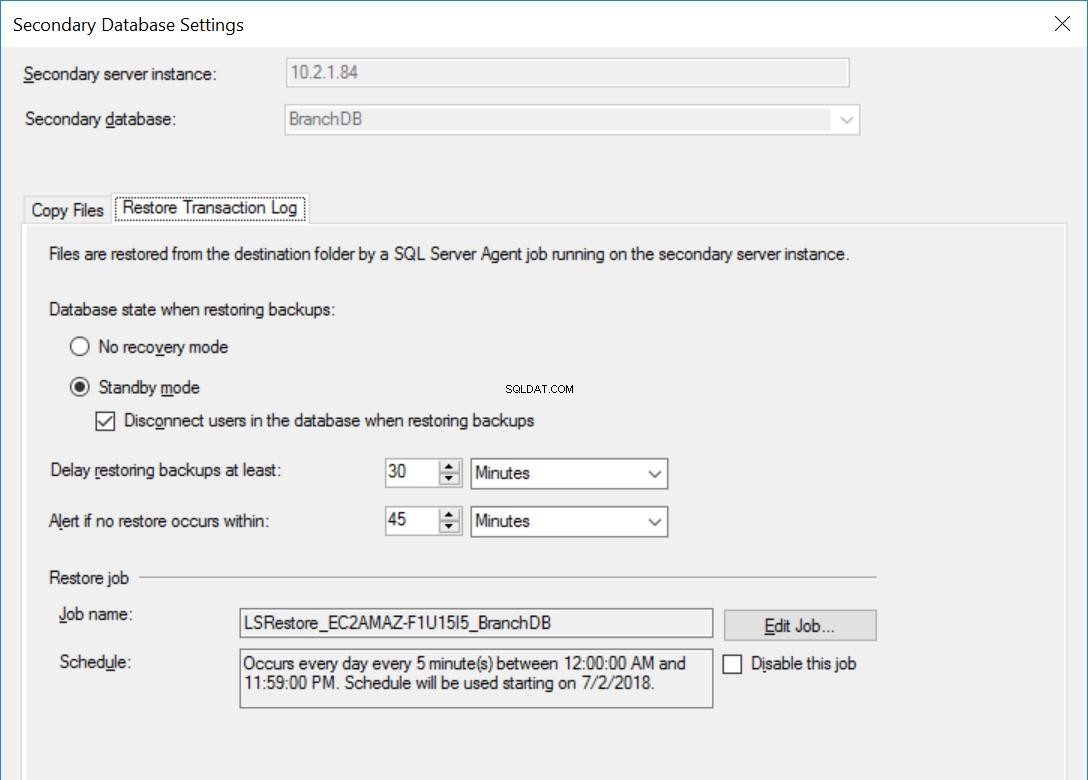
Abb. 5 Wiederherstellungseinstellungen für BranchDB
Jeder Protokollversandauftrag ist so konfiguriert, dass er alle fünf Minuten ausgeführt wird. Um „Wiederherstellen von Sicherungen verzögern“ zu verarbeiten, müssen wir den Standby-Wiederherstellungsmodus in der Protokollversandkonfiguration verwenden. Dies ist logisch, da die sekundäre Datenbank im Standby-Modus ist und anzeigt, dass wir die sekundäre Datenbank abfragen können, wenn keine Transaktionsprotokollwiederherstellung ausgeführt wird. Der Wert, den wir in dieser Option angeben (in diesem Fall 30 Minuten), gibt uns ein gutes Zeitfenster, in dem wir Berichte aus der sekundären Datenbank ausführen können, abgesehen von der Kernanforderung dieses Artikels, die in der Lage ist, Benutzerfehler zu beheben.
Außerdem sollten wir erwähnen, dass sich die Wiederherstellung von Transaktionsprotokollsicherungen tatsächlich verzögert. Sein Zeitstempel ist später als der Verzögerungswert. Dies bedeutet, dass alle Transaktionsprotokollsicherungen auf den sekundären Server kopiert werden, was auf dem Zeitplan basiert und im Kopierauftrag angegeben ist. Tatsächlich wird der Wiederherstellungsjob weiterhin planmäßig ausgeführt, aber Transaktionsprotokollsicherungen (die nicht älter als 30 Minuten sind) werden nicht wiederhergestellt. Im Wesentlichen liegt die BranchDB-Standby-Datenbank 30 Minuten hinter der primären BranchDB-Datenbank. Um diese Verzögerung zu demonstrieren, erstellen wir im nächsten Abschnitt eine Tabelle in beiden Datenbanken und erstellen einen Job, der jede Minute einen Datensatz einfügt. Wir werden diese Tabelle in den sekundären Datenbanken untersuchen.
Die Einstellungen für die CorporateDB-Datenbank sind die gleichen wie in Abb. 3 bis 5, mit Ausnahme des Wiederherstellungsjobs, der NICHT darauf eingestellt ist, Transaktionsprotokollsicherungen zu verzögern.
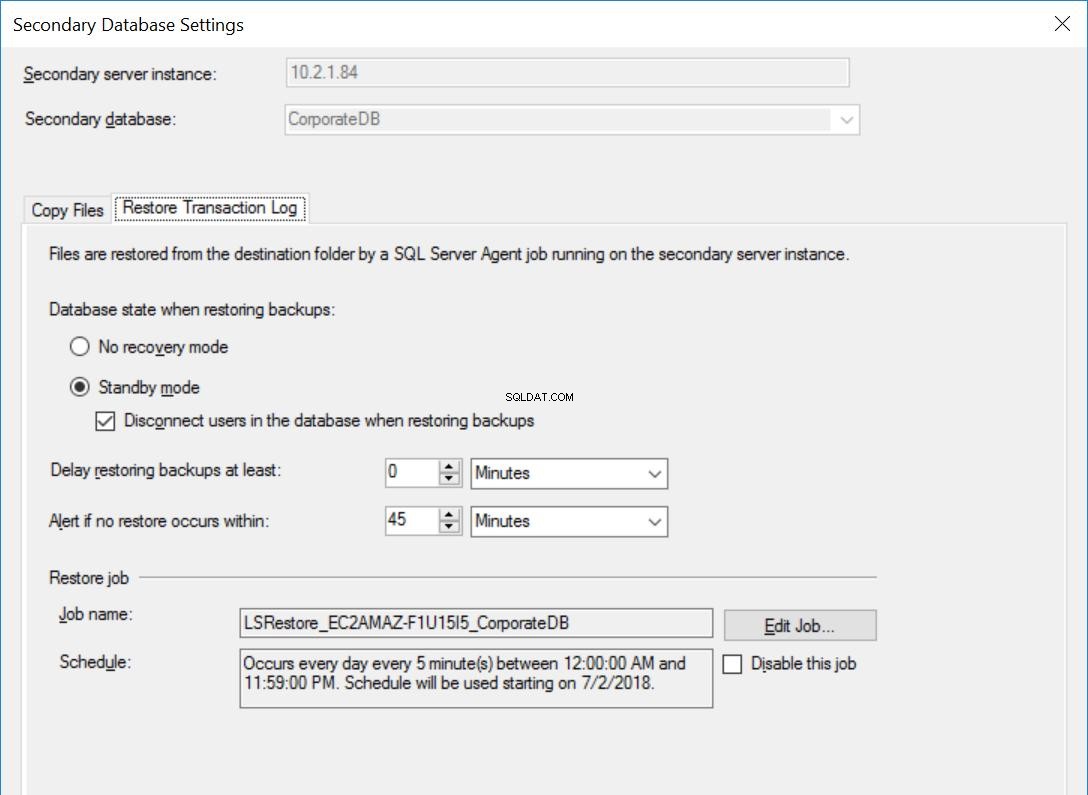
Abb. 6 Einstellungen für CorporateDB wiederherstellen
Überprüfen der Konfiguration
Sobald die Konfiguration abgeschlossen ist, können wir überprüfen, ob die Konfiguration in Ordnung ist, und mit der Beobachtung ihrer Arbeit beginnen. Der Transaktionsprotokoll-Versandbericht zeigt uns, dass die Branch-DB der CorporateDB in Bezug auf Wiederherstellungen tatsächlich hinterherhinkt:
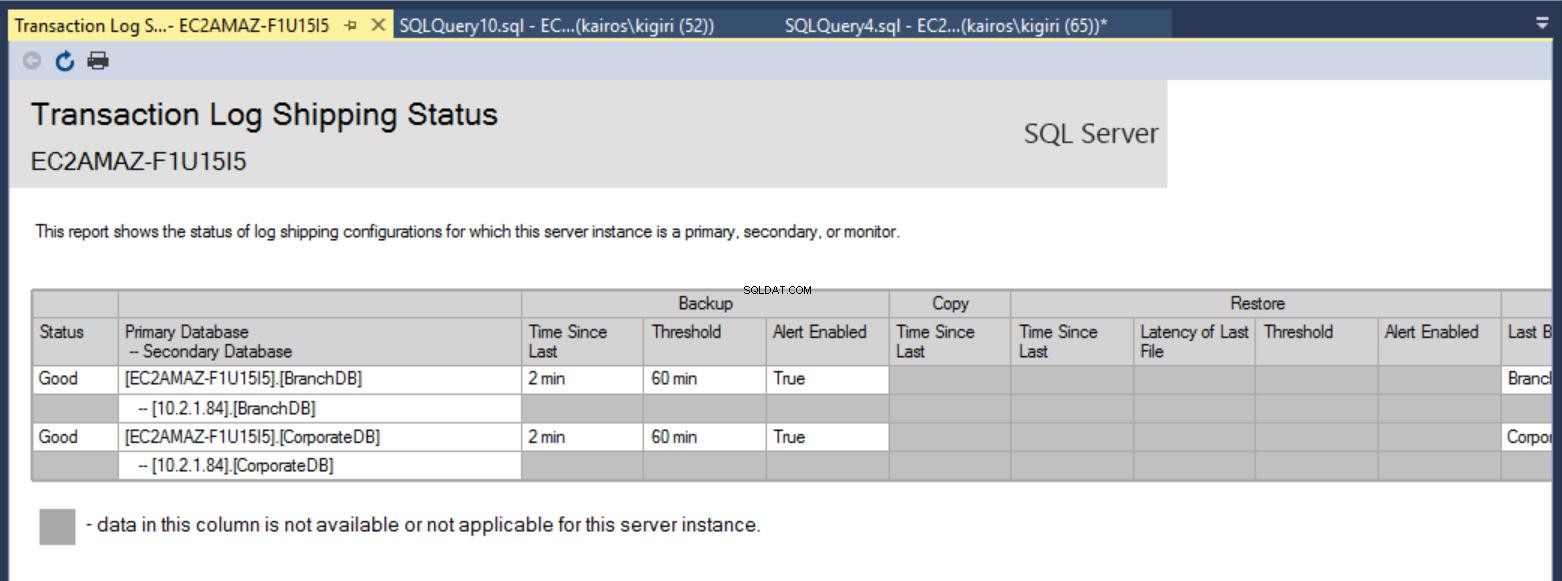
Abb. 7a Transaktionsprotokoll-Versandbericht auf Primärserver
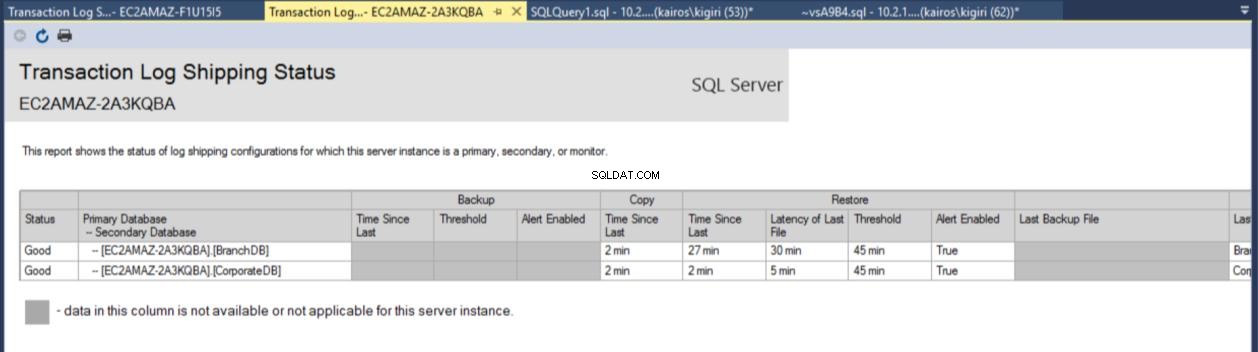
Abb. 7b Transaktionsprotokoll-Versandbericht auf sekundärem Server
Außerdem sehen Sie die folgende Meldung im Verlauf des Wiederherstellungsauftrags für die BranchDB:
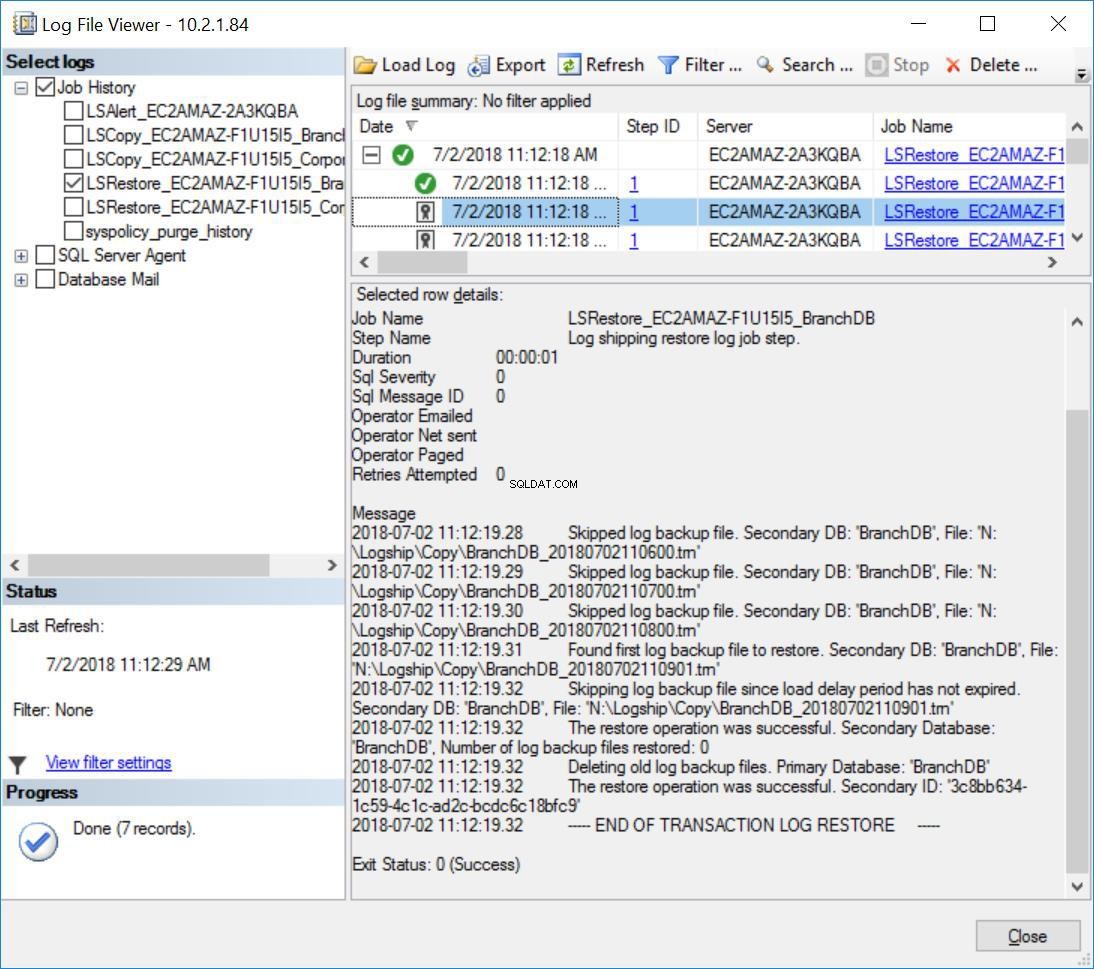
Abb. 8 Übersprungene Wiederherstellung des Transaktionsprotokolls auf dem sekundären Server
Wir können mit dieser Überprüfung weiter gehen, indem wir eine Tabelle erstellen und einen Job verwenden, um diese Tabelle jede Minute mit Zeilen zu füllen. Der Job ist eine einfache Möglichkeit, zu simulieren, was eine Anwendung mit einer Benutzertabelle machen könnte. Dies kann uns zeigen, dass diese Verzögerung definitiv in den Benutzerdaten angezeigt wird.
Listing 2 – Log-Tracker-Tabelle erstellen
use BranchDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername) use CorporateDB go create table log_ship_tracker ( ID int identity (100,1) ,Database_Name sysname default db_name() ,RecordTime datetime default getdate() ,ServerName sysname default @@servername)
Listing 3 – Job zum Füllen der Log-Tracker-Tabelle erstellen
/* ==Scripting Parameters== Source Server Version : SQL Server 2017 (14.0.3023) Source Database Engine Edition : Microsoft SQL Server Standard Edition Source Database Engine Type : Standalone SQL Server Target Server Version : SQL Server 2017 Target Database Engine Edition : Microsoft SQL Server Standard Edition Target Database Engine Type : Standalone SQL Server */ USE [msdb] GO /****** Object: Job [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ BEGIN TRANSACTION DECLARE @ReturnCode INT SELECT @ReturnCode = 0 /****** Object: JobCategory [[Uncategorized (Local)]] Script Date: 7/2/2018 3:32:00 PM ******/ IF NOT EXISTS (SELECT name FROM msdb.dbo.syscategories WHERE name=N'[Uncategorized (Local)]' AND category_class=1) BEGIN EXEC @ReturnCode = msdb.dbo.sp_add_category @class=N'JOB', @type=N'LOCAL', @name=N'[Uncategorized (Local)]' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback END DECLARE @jobId BINARY(16) EXEC @ReturnCode = msdb.dbo.sp_add_job @job_name=N'InsertRecords', @enabled=1, @notify_level_eventlog=0, @notify_level_email=0, @notify_level_netsend=0, @notify_level_page=0, @delete_level=0, @description=N'No description available.', @category_name=N'[Uncategorized (Local)]', @owner_login_name=N'kairos\kigiri', @job_id = @jobId OUTPUT IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback /****** Object: Step [InsertRecords] Script Date: 7/2/2018 3:32:00 PM ******/ EXEC @ReturnCode = msdb.dbo.sp_add_jobstep @example@sqldat.com, @step_name=N'InsertRecords', @step_id=1, @cmdexec_success_code=0, @on_success_action=1, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'TSQL', @command=N'use BranchDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) use CorporateDB go insert into log_ship_tracker values (db_name(),getdate(),@@servername) GO', @database_name=N'master', @flags=0 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1 IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobschedule @example@sqldat.com, @name=N'Schedule', @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=4, @freq_subday_interval=1, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20180702, @active_end_date=99991231, @active_start_time=0, @active_end_time=235959, @schedule_uid=N'03e5f1b2-2e0b-4b30-8d60-3643c84aa08d' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback EXEC @ReturnCode = msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)' IF (@@ERROR <> 0 OR @ReturnCode <> 0) GOTO QuitWithRollback COMMIT TRANSACTION GOTO EndSave QuitWithRollback: IF (@@TRANCOUNT > 0) ROLLBACK TRANSACTION EndSave: GO
Wenn wir die Tabelle jeweils in den primären Datenbanken abfragen, können wir (unter Verwendung der RecordTime-Spalte) bestätigen, dass die Zeilen in BranchDB und CorporateDB übereinstimmen. Wenn wir die Tabelle in den sekundären Datenbanken auf die gleiche Weise untersuchen, sehen wir deutlich, dass wir eine 30-minütige Lücke zwischen BranchDB und CorporateDB haben.
Listing 4 – Abfragen der Log-Tracker-Tabelle
select top 10 @@servername [Current_Server],* from BranchDB.dbo.log_ship_tracker order by RecordTime desc select top 10 @@servername [Current_Server], * from CorporateDB.dbo.log_ship_tracker order by RecordTime desc
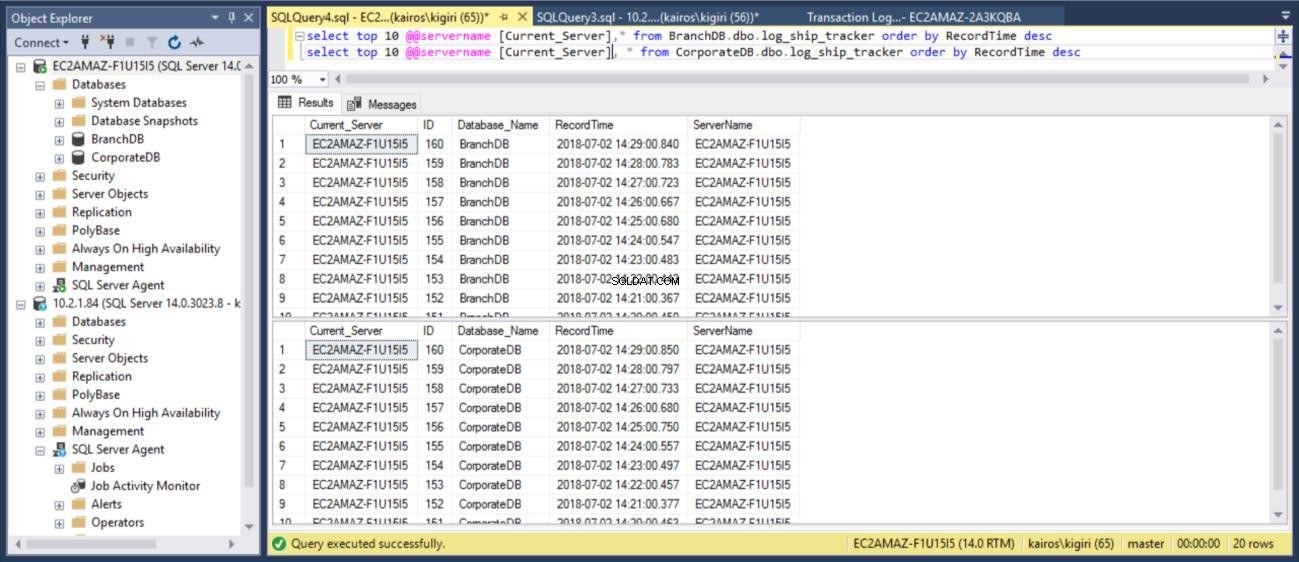
Abb. 9 Log Tracker-Tabellen stimmen in Primärdatenbanken überein
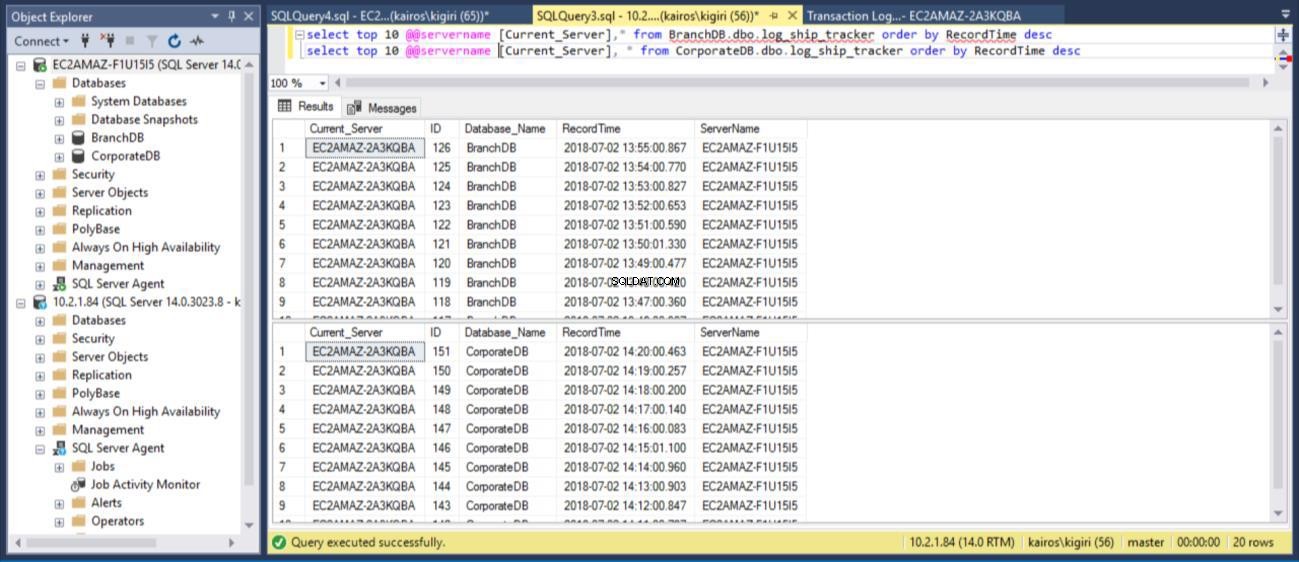
Abb. 10 Log-Tracker-Tabellen haben eine ~30-Minuten-Lücke in sekundären Datenbanken
Wiederherstellung nach Benutzerfehler
Lassen Sie uns nun über den Hauptvorteil dieser Verzögerung sprechen. In dem Szenario, in dem ein Benutzer versehentlich eine Tabelle löscht, können wir die Daten schnell aus der sekundären Datenbank wiederherstellen, solange die Verzögerungszeit nicht abgelaufen ist. In diesem Beispiel löschen wir die Tabelle Sales.Orderlines in BEIDEN Datenbanken und prüfen, ob die Tabelle nicht mehr in BEIDEN Datenbanken existiert.
Listing 5 – Tabelle mit fallenden Bestellposten
drop table BranchDB.Sales.Orderlines drop table CorporateDB.Sales.Orderlines GO use BranchDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO use CorporateDB go select @@servername [Current_Server] , db_name() [Database_Name] , name , schema_name(schema_id) [schema] , type_desc , create_date , modify_date from sys.tables where name='Orderlines' GO
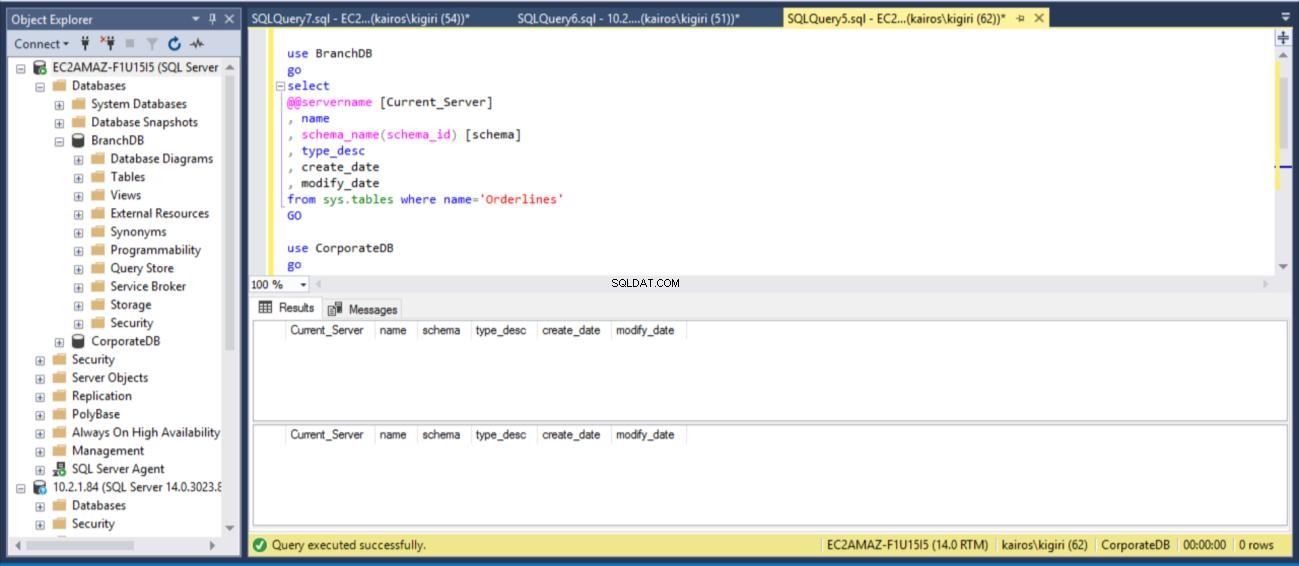
Abb. 11 Dropping-Tabelle Sales.Orderlines
Wenn wir auf dem sekundären Server nach der Tabelle suchen, stellen wir fest, dass die Tabelle noch in BEIDEN Datenbanken verfügbar ist. Daher haben wir für CorporateDB weniger als fünf Minuten Zeit, um die Daten wiederherzustellen. (Abb. 12). Aber sobald der nächste Wiederherstellungszyklus ausgeführt wird, verlieren wir die Tabelle in der Corporate DB-Datenbank. Um diese Tabelle wiederherzustellen, müssen wir eine Point-in-Time-Wiederherstellung mit einer vollständigen Sicherung in einer separaten Umgebung durchführen und dann diese spezifische Tabelle extrahieren. Sie werden zustimmen, dass es einige Zeit dauern wird. Für die BranchDB Orderlines-Tabelle haben wir etwas mehr Zeit und können die Tabelle mit einem einzigen SQL-Statement über einen Linked Server wiederherstellen (siehe Listing 6).
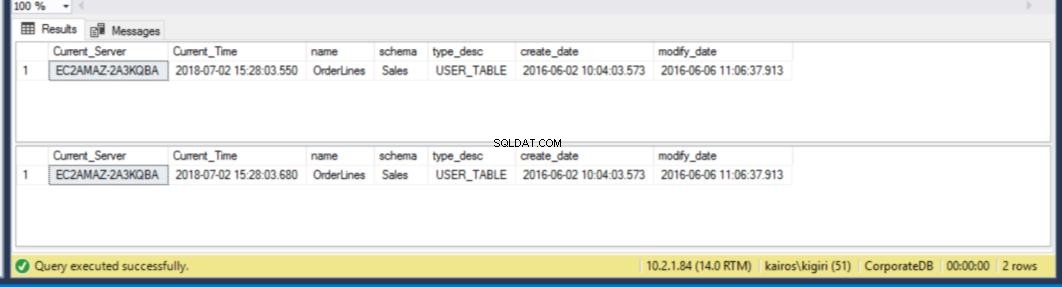
Abb. 12 Fünf-Minuten-Countdown:Tabelle existiert in beiden sekundären Datenbanken
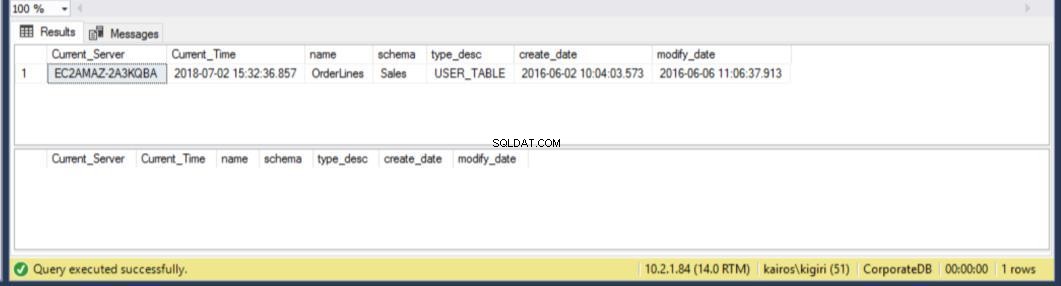
Abb. 13 Zusätzliche 25 Minuten zum Wiederherstellen der BranchDB-Tabelle
Listing 6 – Tabelle „Bestellposten wiederherstellen“
USE [master] GO /****** Object: LinkedServer [10.2.1.84] Script Date: 7/2/2018 4:14:59 PM ******/ EXEC master.dbo.sp_addlinkedserver @server = N'10.2.1.84', @srvproduct=N'SQL Server' /* For security reasons the linked server remote logins password is changed with ######## */ EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'10.2.1.84',@useself=N'True',@locallogin=NULL,@rmtuser=NULL,@rmtpasswo rd=NULL GO select * into BranchDB.Sales.Orderlines from [10.2.1.84].BranchDB.Sales.Orderlines
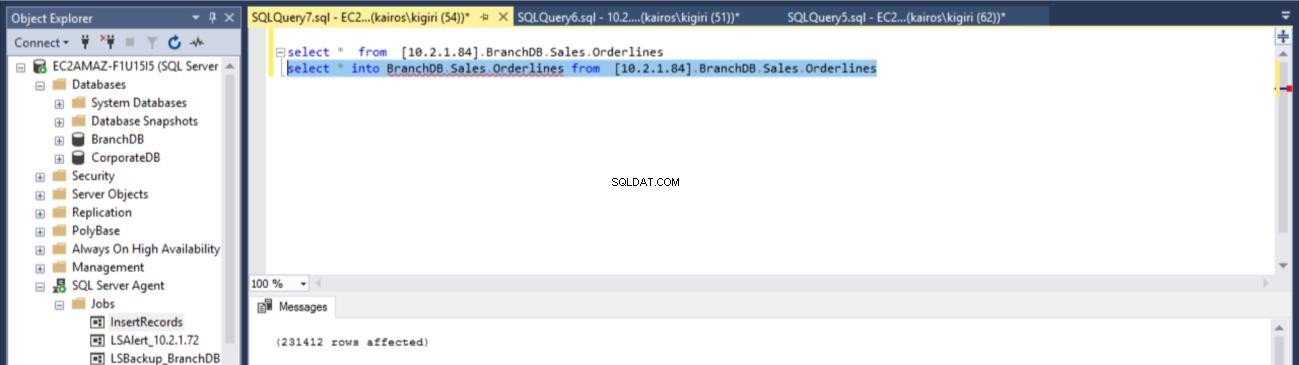
Abb. 14 Stellen Sie die Tabelle Sales.Orderlines von BranchDB wieder her
Dann überprüfen wir den primären Server (BranchDB-Datenbank), ob die Tabelle wiederhergestellt ist.
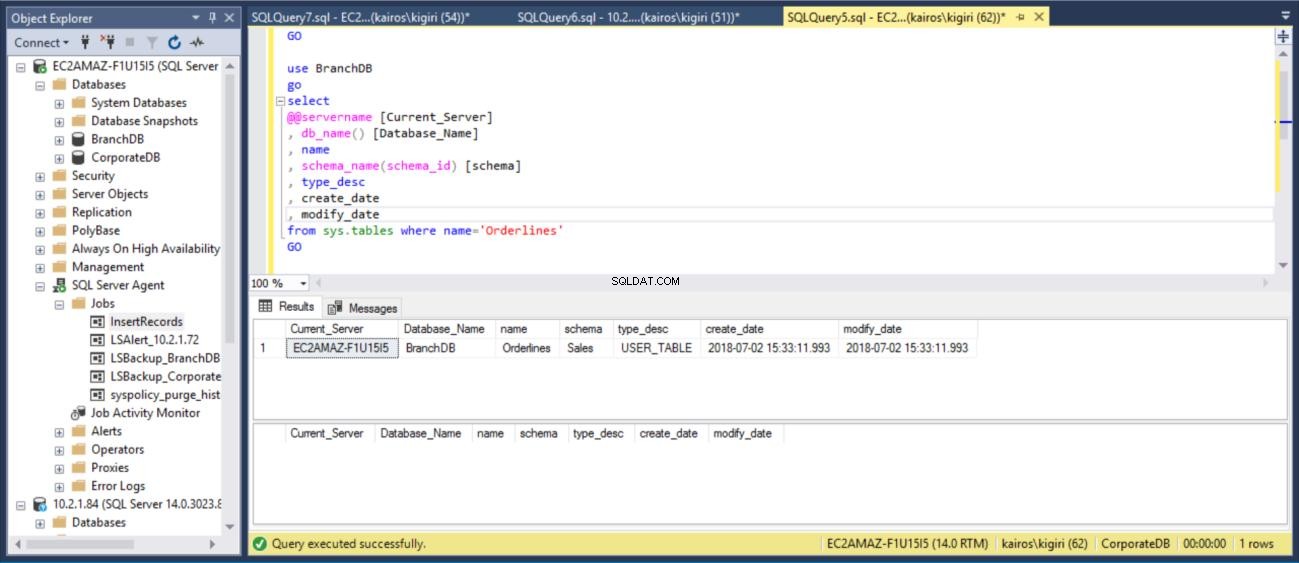
Abb. 15 Stellen Sie die Tabelle Sales.Orderlines von BranchDB wieder her
Schlussfolgerung
SQL Server bietet eine Reihe von Möglichkeiten zur Wiederherstellung nach Datenverlust aus einer Vielzahl von Ursachen – Festplattenfehler, Beschädigung, Benutzerfehler usw. Die Point-in-Time-Wiederherstellung aus Backups ist wahrscheinlich die bekannteste dieser Methoden. Für bestimmte einfache Fälle von Benutzerfehlern oder ähnlichen Fällen, in denen ein oder zwei Objekte verloren gehen, ist die Verwendung des Transaktionsprotokollversands mit verzögerter Wiederherstellung ein guter Ansatz. Es sollte jedoch beachtet werden, dass für niedrigere RPOs eine sekundäre Datenbank ausgewählt werden muss, die ausschließlich für DR-Anforderungen konfiguriert ist.