Datenbankreplikation ist die Technologie zur Verteilung von Daten vom Primärserver auf Sekundärserver. Die Replikation funktioniert nach dem Master-Slave-Konzept, bei dem die Master-Datenbank Daten an einen oder mehrere Slave-Server verteilt. Die Replikation kann zwischen mehreren SQL Server-Instanzen auf demselben Server ODER zwischen mehreren Datenbankservern in denselben oder geografisch getrennten Rechenzentren eingerichtet werden.
Die Verwendung der SQL Server-Replikation bietet zwei Hauptvorteile:
- Durch die Replikation können wir Daten nahezu in Echtzeit erhalten, die für Berichtszwecke verwendet werden können. Wenn Sie beispielsweise die schreibintensive OLTP-Last auf einem Server und die leseintensive Last auf einem anderen Server trennen möchten, können Sie die Replikation einrichten, um die Daten auf beiden Servern zu synchronisieren.
- Der zweite Vorteil besteht darin, dass Sie die Replikation so planen können, dass sie zu einer bestimmten Zeit ausgeführt wird. Wenn Sie beispielsweise möchten, dass der Berichtsserver Daten des abgeschlossenen Tages enthält, können Sie den Replikations-Snapshot entsprechend planen. Wir müssen keine zusätzliche Logik schreiben, um mit aktuellen Daten umzugehen.
Die Replikation bietet viel Flexibilität. Mithilfe der Replikation können wir die Zeilen herausfiltern und auch die Teilmenge der Daten einer beliebigen Tabelle replizieren. Wir können die replizierten Daten ändern oder nur replizieren, aktualisieren und einfügen und die Löschungen ignorieren. Wir können die Daten auch von einem anderen Datenbanksystem wie Oracle replizieren.
Komponenten der Replikation
Es gibt sieben Kernkomponenten der SQL Server-Replikation. Es folgt die Liste:
- Herausgeber.
- Händler.
- Abonnent.
- Artikel.
- Veröffentlichung.
- Push-Abonnement.
- Abonnement ziehen.
Im Folgenden sind die Details aufgeführt:
Artikel
Ein Artikel ist ein Datenbankobjekt wie eine SQL-Tabelle oder eine gespeicherte Prozedur. Wie ich oben erwähnt habe, können wir mit der Replikation Daten filtern oder die ausgewählte Tabellenspalte replizieren, daher werden Tabellenspalten oder -zeilen als Artikel betrachtet.
Veröffentlichung
Artikel können nicht repliziert werden, bis sie Teil der Publikation werden. Veröffentlichung ist die Gruppe der Artikel/Datenbankobjekte. Es stellt auch das Dataset dar, das von SQL Server repliziert wird.
Herausgeber
Publisher enthält eine Master-Datenbank mit den zu veröffentlichenden Daten. Es bestimmt, welche Daten über alle Abonnenten verteilt werden sollen.
Händler
Der Distributor ist die Brücke zwischen Herausgeber und Abonnent. Der Verteiler sammelt alle veröffentlichten Daten und speichert sie, bis sie an alle Abonnenten gesendet werden. Es ist eine Brücke zwischen Herausgeber und Abonnent. Es unterstützt das Konzept mehrerer Herausgeber und Abonnenten. Es ist nicht zwingend erforderlich, den Verteiler auf einer separaten SQL-Instanz oder einem separaten Server zu konfigurieren. Wenn wir es nicht konfigurieren, kann der Herausgeber als Verteiler fungieren. Organisationen mit umfangreicher Replikation können den Verteiler auf einem separaten System konfigurieren.
Abonnenten
Der Abonnent ist das Ende der Quelle oder das Ziel, an das Daten oder replizierte Veröffentlichungen übertragen werden. Bei der Replikation gibt es einen Herausgeber, der mehrere Abonnenten haben kann.
Push-Abonnement
Bei einem Push-Abonnement aktualisiert der Herausgeber die Daten für den Abonnenten. Bei einem Push-Abonnement ist der Abonnent passiv. Der Verlag versendet Artikel oder Veröffentlichungen an alle seine Abonnenten. Basierend auf den Anforderungen der Organisation können Sie im Erstellungsassistenten für die Replikation auf dem Bildschirm das zu verwendende Abonnement auswählen. Transaktionsreplikation und Peer-to-Peer-Replikation verwenden das Push-Abonnement, um die Echtzeitverfügbarkeit von Daten aufrechtzuerhalten.
Abonnement ziehen
Bei einem Pull-Abonnement fordern alle Abonnenten die neuen Daten oder aktualisierten Daten von ihrem Herausgeber an. In einem Pull-Abonnement können wir steuern, welche Daten oder Datenänderungen für Abonnenten erforderlich sind. Es ist nützlich, wenn wir die geänderten Daten nicht sofort benötigen.
Replikationstypen
SQL Server unterstützt drei Replikationstypen:
- Transaktionsreplikation.
- Snapshot-Replikation.
- Mergereplikation.
Transaktionsreplikation
Transaktionsreplikation, alle Schemaänderungen, Datenänderungen, die in der Herausgeberdatenbank auftreten, werden in der Abonnentendatenbank repliziert. Wann immer Aktualisierungs-, Lösch- oder Einfügevorgänge in der Herausgeberdatenbank stattfinden, werden die Änderungen nachverfolgt und diese Änderungen an die Abonnentendatenbanken gesendet. Die Transaktionsreplikation sendet nur eine begrenzte Datenmenge über ein Netzwerk. Darüber hinaus erfolgen Änderungen nahezu in Echtzeit, sodass sie zum Einrichten der DR-Site oder zum Aufskalieren der Berichtsvorgänge verwendet werden können. Die Transaktionsreplikation ist ideal für die folgenden Situationen:
- Wenn Sie ein System einrichten möchten, bei dem Änderungen am Publisher sofort auf die Abonnenten angewendet werden sollen.
- Der Publisher hat hoch niedrig INSERT, UPDATES und DELETES.
- Wenn Sie eine heterogene Replikation einrichten möchten, d. h. Herausgeber oder Abonnenten für Nicht-SQL-Server-Datenbanken wie Oracle.
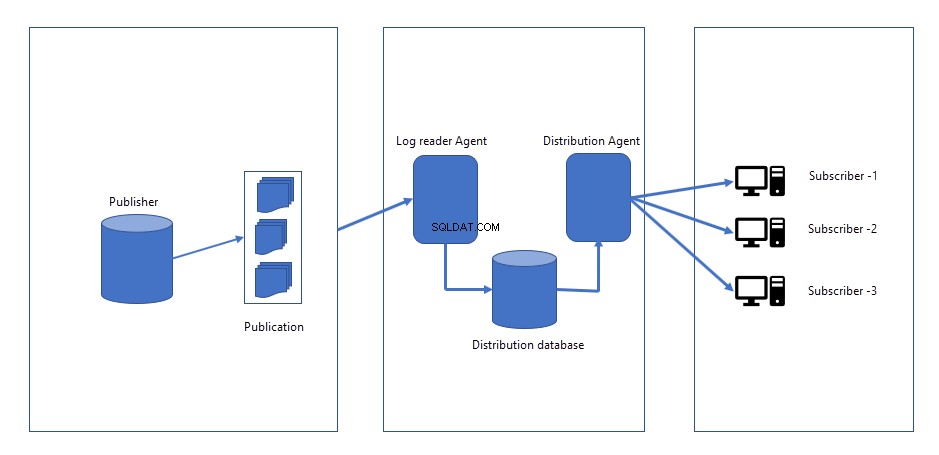
Wenn Änderungen an der Herausgeberdatenbank vorgenommen werden, werden die Änderungen in einer Protokolldatei in der Herausgeberdatenbank protokolliert. Verteiler-/Publisher-Site, es werden zwei Jobs erstellt.
- Snapshot-Agent :Snapshot-Agent-Job generiert den Snapshot des Schemas, Daten der Objekte, die wir replizieren oder veröffentlichen möchten. Dateien des Snapshots können auf dem Publisher-Server oder an einem Netzwerkspeicherort gespeichert werden. Wenn wir die Replikation zum ersten Mal initiieren, erstellt sie einen Snapshot und wendet ihn auf alle Abonnenten an. Der Snapshot-Agent bleibt im Leerlauf, bis er manuell ausgelöst oder für eine bestimmte Zeit geplant wird.
- Protokolllese-Agent :Der Auftrag des Protokollleseagenten wird kontinuierlich ausgeführt. Es liest die aufgetretenen Änderungen (INSERT, UPDATES und DELETES) aus dem Transaktionsprotokoll der Herausgeberdatenbank und sendet sie an einen Verteilungsagenten.
- Vertriebsagent :Nachdem die Änderungen vom Protokollleseagenten abgerufen wurden, sendet der Verteilungsagent alle Änderungen an die Abonnenten.
Wenn wir die Transaktionsreplikation konfigurieren, führt sie die folgenden Aktivitäten durch
- Es wird initiiert, indem der erste Snapshot von Veröffentlichungsdaten und Datenbankobjekten erstellt und ein Snapshot auf Abonnenten angewendet wird.
- Der Protokollleseagent überwacht kontinuierlich das T-Protokoll des Herausgebers und sendet diese bei Änderungen an den Verteiler oder direkt an die Abonnenten.
Das folgende Bild zeigt, wie die Transaktionsreplikation funktioniert:
Vorteile:
- Die Transaktionsreplikation kann als Standby-SQL-Server verwendet werden, oder sie kann für den Lastausgleich oder die Trennung von Berichtssystem und OLTP-System verwendet werden.
- Publisher-Server repliziert Daten mit geringer Latenz auf Abonnenten-Server.
- Mit Transaktionsreplikation kann Replikation auf Objektebene implementiert werden.
- Transaktionsreplikation kann angewendet werden, wenn Sie weniger Daten schützen müssen und Sie einen schnellen Datenwiederherstellungsplan haben sollten.
Nachteile:
- Sobald die Replikation eingerichtet ist, gelten die Schemaänderungen auf dem Herausgeber nicht auf dem Abonnentenserver. Wir müssen diese Änderungen manuell vornehmen, indem wir einen neuen Snapshot erstellen und ihn auf die Abonnenten anwenden.
- Wenn wir die Server wechseln, müssen wir die Replikation neu konfigurieren.
- Wenn die Transaktionsreplikation als DR-Setup verwendet wird, müssen wir ein Failover manuell durchführen.
Snapshot-Replikation
Die Snapshot-Replikation generiert ein vollständiges Bild/einen vollständigen Snapshot der Veröffentlichung nach einem definierten Zeitplan und sendet die Snapshot-Dateien an die Abonnenten. Bei der Snapshot-Replikation werden die Zieldaten durch einen neuen Snapshot ersetzt. Snapshot-Replikation ist die beste Option, wenn Daten weniger volatil sind. Beispielsweise sind Master-Tabellen wie Stadt, Postleitzahl, PIN-Code die besten Kandidaten für die Snapshot-Replikation.
Beim Konfigurieren der Snapshot-Replikation werden die folgenden wichtigen Komponenten definiert:
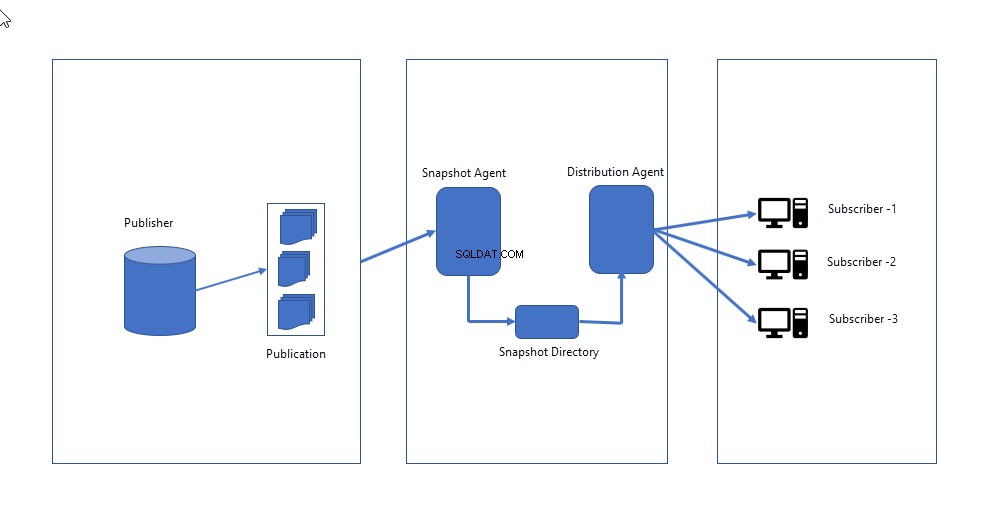
- Snapshot-Agent :Es erstellt ein vollständiges Abbild des in der Veröffentlichung definierten Schemas und der Daten und sendet es an den Verteiler. Der Snapshot-Agent bleibt im Leerlauf, bis er manuell ausgelöst ODER für eine bestimmte Zeit geplant wird.
- Vertriebsagent :Es sendet die Snapshot-Dateien an Abonnenten und wendet Schema und Daten an, indem es die vorhandenen ersetzt.
Die Snapshot-Replikation führt die folgenden Aktivitäten aus:
- Der Snapshot-Agent platziert nach dem definierten Zeitplan eine gemeinsame Sperre für das Schema und die zu veröffentlichenden Daten.
- Vollständiger Schnappschuss der veröffentlichten Daten, die auf die Verteilerseite kopiert wurden. Der Snapshot-Agent erstellt drei Dateien
- Datei zum erstellten Datenbankschema veröffentlichter Daten.
- BCP-Datei zum Exportieren von Daten in SQL-Tabellen
- Indexdateien zum Exportieren von Indexdaten.
- Sobald Dateien erstellt sind, hebt der Snapshot-Agent freigegebene Sperren für veröffentlichte Daten und Daten auf.
- Distributor-Agents starten und ersetzen das Abonnentenschema und die Daten mithilfe von Dateien, die vom Snapshot-Agent erstellt wurden.
Das folgende Bild zeigt, wie die Snapshot-Replikation funktioniert.
Vorteile
- Die Snapshot-Replikation ist sehr einfach einzurichten. Wenn Daten nicht häufig geändert werden, ist die Snapshot-Replikation eine sehr geeignete Option.
- Sie können steuern, wann Daten gesendet werden. Beispielsweise eine Haupttabelle mit einem hohen Datenvolumen, die sich jedoch seltener ändert, als dass Sie die Daten bei geringem Datenverkehr replizieren können.
Nachteile
- Der vom Snapshot-Agent generierte Snapshot enthält geänderte und unveränderte veröffentlichte Daten, daher kann der über das Netzwerk übertragene Snapshot Latenz erzeugen und andere Vorgänge beeinträchtigen.
- Mit zunehmender Datenmenge nimmt die Größe des Snapshots zu und es dauert länger, den Snapshot zu erstellen und an die Abonnenten zu verteilen.
Mergereplikation
Die Mergereplikation kann verwendet werden, wenn wir Änderungen auf mehreren Servern verwalten müssen und diese Änderungen konsolidiert werden müssen.
Wenn wir die Mergereplikation konfigurieren, werden die folgenden Komponenten erstellt:
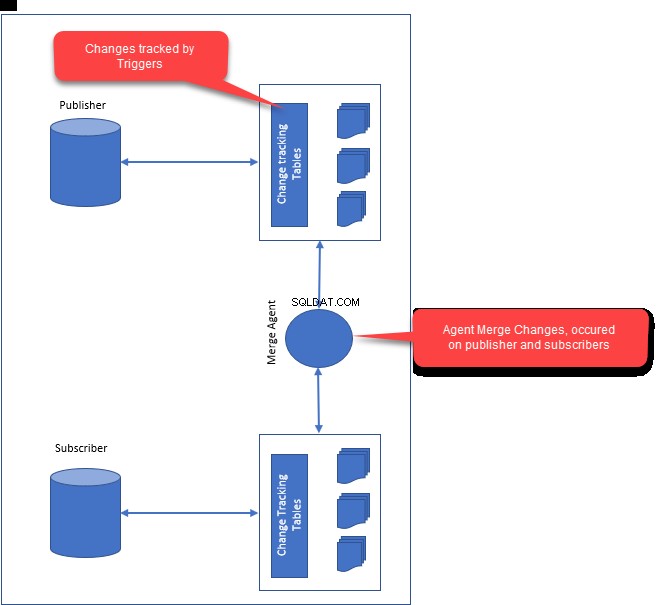
- Snapshot-Agent :Snapshot-Agent generiert den ersten Snapshot von Veröffentlichungsdaten und Datenbankobjekten. Sobald der Snapshot erstellt ist, wird er an alle Abonnenten verteilt.
- Merge-Agent :Der Merge-Agent ist für die Lösung der Konflikte zwischen Herausgeber und Abonnenten verantwortlich. Alle Konflikte werden durch den Merge-Agent gelöst, der eine Konfliktlösung verwendet. Je nachdem, wie Sie die Konfliktlösung konfiguriert haben, werden die Konflikte vom Merge-Agent gelöst.
Wenn wir die Mergereplikation konfigurieren, führt sie die folgenden Aktivitäten aus:
- Es wird initiiert, indem ein Schnappschuss von Veröffentlichungsdaten und Datenbankobjekten erstellt und ein Schnappschuss auf Abonnenten angewendet wird.
- Während der Konfiguration der Mergereplikation werden Trigger auf Herausgeber und Abonnent erstellt. Auslöser sind dafür verantwortlich, nachfolgende Änderungen und Tabellenmodifikationen bei Herausgebern und Abonnenten nachzuverfolgen.
- Wenn sich Herausgeber und Abonnenten mit dem Netzwerk verbinden, werden Änderungen an Datenzeilen und Schemaänderungen miteinander synchronisiert. Beim Zusammenführen der Änderungen des Herausgebers und der Abonnenten löst der Merge-Agent die Konflikte basierend auf den im Merge-Agent definierten Bedingungen.
Die Mergereplikation wird in Server-zu-Client-Umgebungen verwendet und ist ideal für Situationen, in denen Abonnenten Daten vom Herausgeber abrufen, Änderungen offline vornehmen und dann Änderungen mit dem Herausgeber und anderen Abonnenten synchronisieren müssen.
Es kann praktische Situationen geben, in denen dieselbe Zeile von verschiedenen Herausgebern und Abonnenten geändert wird. Zu diesem Zeitpunkt prüft der Merge-Agent, welche Konfliktlösung definiert ist, und nimmt entsprechende Änderungen vor.
SQL Server identifiziert eine Spalte eindeutig mithilfe eines global eindeutigen Bezeichners für jede Zeile in einer veröffentlichten Tabelle. Wenn die Tabelle bereits über eine eindeutige Bezeichnerspalte verfügt, verwendet SQL Server automatisch diese Spalte. Andernfalls wird der Tabelle eine rowguid-Spalte hinzugefügt und ein Index basierend auf der Spalte erstellt.
Auslöser werden für die veröffentlichten Tabellen sowohl für Herausgeber als auch für Abonnenten erstellt. Sie werden verwendet, um die Änderungen basierend auf den Zeilen- oder Spaltenänderungen zu verfolgen.
Das folgende Bild zeigt, wie die Mergereplikation funktioniert:
Vorteile:
- Dies ist die einzige Möglichkeit, Änderungen an mehreren Serverdaten zu konsolidieren.
Nachteile:
- Es braucht viel Zeit, um beide Enden zu replizieren und zu synchronisieren.
- Die Konsistenz ist gering, da viele Parteien synchronisiert werden müssen.
- Beim Zusammenführen der Replikation können Konflikte auftreten, wenn dieselben Zeilen in mehr als einem Abonnenten und Herausgeber betroffen sind. Es kann mit der Konfliktlösung behoben werden, macht aber die Einrichtung der Replikation komplizierter.
T-SQL-Code zum Überprüfen der Replikationskonfiguration
Ich habe die Snapshot-Replikation und die Transaktionsreplikation auf zwei Instanzen meiner Maschine konfiguriert. Mithilfe von SQL Dynamic Management (DMVs) können wir die Konfiguration der Replikation überprüfen. Um die Konfiguration der Replikation zu überprüfen, können wir T-SQL-Code verwenden. Der Skriptcode füllt Folgendes aus:
- Name der Abonnentendatenbank.
- Herausgebername.
- Abonnementtyp.
- Publisher-Datenbank.
- Name des Replikationsagenten.
Unten ist das Skript:
SELECT DistributionAgent.subscriber_db [Subscriber DB], DistributionAgent.publication [PUB Name], RIGHT(LEFT(DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 )), Len(LEFT( DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 ))) - ( 10 + Len(DistributionAgent.publisher_db) + ( CASE WHEN DistributionAgent.publisher_db = 'ALL' THEN 1 ELSE Len( DistributionAgent.publication) + 2 END ) )) [SUBSCRIBER], ( CASE WHEN DistributionAgent.subscription_type = '0' THEN 'Push' WHEN DistributionAgent.subscription_type = '1' THEN 'Pull' WHEN DistributionAgent.subscription_type = '2' THEN 'Anonymous' ELSE Cast(DistributionAgent.subscription_type AS VARCHAR) END ) [Subscrition Type], DistributionAgent.publisher_db + ' - ' + Cast(DistributionAgent.publisher_database_id AS VARCHAR) [Publisher Database], DistributionAgent.NAME [Pub - DB - Publication - SUB - AgentID] FROM distribution.dbo.msdistribution_agents DistributionAgent WHERE DistributionAgent.subscriber_db <> 'virtual'
Es folgt die Ausgabe:

Zusammenfassung
In diesem Artikel habe ich erklärt:
- Das Fundament und die Vorteile der Replikation und ihrer Komponenten.
- Transaktionsreplikation.
- Snapshot-Replikation.
- Mergereplikation.