Die Datenbank ist ein kritischer und lebenswichtiger Bestandteil jedes Unternehmens oder jeder Organisation. Die wachsenden Trends sagen voraus, dass 82 % der Unternehmen davon ausgehen, dass die Anzahl der Datenbanken in den nächsten 12 Monaten zunehmen wird. Eine große Herausforderung für jeden DBA besteht darin, herauszufinden, wie man mit dem massiven Datenwachstum fertig wird, und dies wird eines der wichtigsten Ziele sein. Wie können Sie die Datenbankleistung steigern, Kosten senken und Ausfallzeiten eliminieren, um Ihren Benutzern das bestmögliche Erlebnis zu bieten? Ist Datenkomprimierung eine Option? Lassen Sie uns anfangen und sehen, wie einige der vorhandenen Funktionen nützlich sein können, um mit solchen Situationen umzugehen.
In diesem Artikel erfahren wir, wie uns die Datenkomprimierungslösung dabei helfen kann, die Datenverwaltungslösung zu optimieren. In diesem Leitfaden behandeln wir die folgenden Themen:
- Komprimierung im Überblick
- Vorteile der Komprimierung
- Ein Überblick über Datenkomprimierungstechniken
- Diskussion verschiedener Arten der Datenkomprimierung
- Fakten zur Datenkomprimierung
- Überlegungen zur Implementierung
- und mehr...
Komprimierung
Die Komprimierung ist eine Technik und daher eine ressourcenempfindliche Operation, jedoch mit Hardware-Kompromissen. Man muss daran denken, die Datenkomprimierung für die folgenden Vorteile einzusetzen:
- Effektive Raumverwaltung
- Effiziente Kostensenkungstechnik
- Einfache Datenbanksicherungsverwaltung
- Effektive N/W-Bandbreitennutzung
- Sichere und schnellere Wiederherstellung oder Wiederherstellung
- Bessere Leistung – reduziert den Speicherbedarf des Systems
Hinweis: Wenn SQL Server CPU- oder Speicherbeschränkt ist, ist die Komprimierung möglicherweise nicht für Ihre Umgebung geeignet.
Die Datenkomprimierung gilt für:
- Haufen
- Clusterte Indizes
- Nicht gruppierte Indizes
- Partitionen
- Indizierte Aufrufe
Hinweis: Große Objekte werden nicht komprimiert (z. B. LOB und BLOB)
Bestens geeignet für folgende Anwendungen:
- Protokolltabellen
- Audit-Tabellen
- Faktentabellen
- Berichte
Einführung
Die Datenkomprimierung ist eine Technologie, die es seit SQL Server 2008 gibt. Die Idee der Datenkomprimierung besteht darin, dass Sie Tabellen, Indizes oder Partitionen innerhalb einer Datenbank selektiv auswählen können. E/A ist weiterhin ein Engpass beim Verschieben von Informationen zwischen dem Eingang und Ausgang der Datenbank. Die Datenkomprimierung macht sich diesen Typ zunutze und trägt dazu bei, die Effizienz einer Datenbank zu steigern. Da wir wissen, dass die Netzwerkgeschwindigkeiten so viel langsamer sind als die Verarbeitungsgeschwindigkeit, ist es möglich, Effizienzgewinne zu erzielen, indem die Verarbeitungsleistung zum Komprimieren von Daten in einer Datenbank verwendet wird, damit sie schneller übertragen werden. Und dann wieder Rechenleistung nutzen, um die Daten am anderen Ende zu dekomprimieren. Im Allgemeinen reduziert die Datenkomprimierung den von den Daten belegten Speicherplatz. Die Technik der Datenkomprimierung ist für jede Datenbank verfügbar und wird von allen Editionen von SQL Server 2016 SP1 unterstützt. Davor war es nur auf SQL Server Enterprise oder Developer Edition verfügbar, nicht auf Standard oder Express.
Funktionsunterstützung

Datenkomprimierungstypen
In SQL Server sind zwei Arten der Datenkomprimierung verfügbar, Zeilenebene und Seitenebene.
Die Komprimierung auf Zeilenebene arbeitet hinter den Kulissen und konvertiert alle Datentypen mit fester Länge in Typen mit variabler Länge. Hier wird davon ausgegangen, dass Daten häufig in einem Typ mit fester Länge gespeichert werden, z. B. char 100, und sie füllen nicht die gesamten 100 Zeichen für jeden Datensatz aus. Kleine Gewinne können erzielt werden, indem dieser zusätzliche Platz aus der Tabelle entfernt wird. Wenn Ihre Datentabellen keine Text- und numerischen Felder mit fester Länge verwenden oder dies tun und Sie tatsächlich die vollständig zulässige Anzahl von Zeichen und Ziffern speichern, sind die Komprimierungsgewinne unter dem Schema auf Zeilenebene minimal bestenfalls.
Das Konzept der Komprimierung wird auf alle Datentypen mit fester Länge ausgedehnt, einschließlich char, int und float. SQL Server ermöglicht es, Platz zu sparen, indem die Daten so gespeichert werden, als wären sie ein Typ mit variabler Größe. die Daten erscheinen und verhalten sich wie eine feste Länge.
Wenn Sie beispielsweise den Wert 100 in einem int gespeichert haben Spalte muss der SQL Server nicht alle 32 Bit verwenden, sondern verwendet einfach 8 Bit (1 Byte).
Die Komprimierung auf Seitenebene bringt die Dinge auf eine andere Ebene. Erstens wendet es automatisch eine Komprimierung auf Zeilenebene auf Datenfelder mit fester Länge an, sodass Sie diese Gewinne standardmäßig automatisch erhalten. Darüber hinaus wendet es etwas an, das als Präfixkomprimierung bezeichnet wird, und eine weitere Technik, die als Wörterbuchkomprimierung bezeichnet wird.
Zeilenkomprimierung
Die Zeilenkomprimierung ist eine innere Komprimierungsebene, die die festen Zeichenfolgen speichert, indem sie ein Format mit variabler Länge verwendet, indem die Leerzeichen nicht gespeichert werden. Die folgenden Schritte werden bei der Komprimierung auf Zeilenebene durchgeführt.
- Alle numerischen Datentypen wie int , schweben , dezimal, und Geld werden in Datentypen mit variabler Länge konvertiert. Beispielsweise ist 125 in der Spalte gespeichert und der Datentyp der Spalte ist eine ganze Zahl. Dann wissen wir, dass 4 Bytes verwendet werden, um den ganzzahligen Wert zu speichern. Aber 125 kann in 1 Byte gespeichert werden, weil 1 Byte Werte von 0 bis 255 speichern kann. Also kann 125 als winziges int gespeichert werden , sodass 3 Bytes eingespart werden können.
- Char und Nchar Datentypen werden als Datentypen mit variabler Länge gespeichert. Beispielsweise wird „SQL“ in einem char gespeichert (20) Typspalte. Aber nach der Komprimierung werden nur 3 Bytes verwendet. Nach der Datenkomprimierung wird bei dieser Art von Daten kein Leerzeichen gespeichert.
- Die Metadaten des Datensatzes werden reduziert.
- NULL- und 0-Werte werden optimiert und es wird kein Speicherplatz verbraucht.
Seitenkomprimierung
Die Seitenkomprimierung ist eine fortgeschrittene Ebene der Datenkomprimierung. Standardmäßig implementiert eine Seitenkomprimierung auch die Komprimierung auf Zeilenebene. Die Seitenkomprimierung wird in zwei Typen eingeteilt
- Präfixkomprimierung und
- Wörterbuchkomprimierung.
Präfixkomprimierung
Bei der Präfixkomprimierung für jede Seite wird für jede Spalte auf der Seite ein gemeinsamer Wert aus allen Zeilen abgerufen und unterhalb der Kopfzeile in jeder Spalte gespeichert. Jetzt wird in jeder Zeile ein Verweis auf diesen Wert anstelle des gemeinsamen Werts gespeichert.
Wörterbuchkomprimierung
Die Wörterbuchkomprimierung ähnelt der Präfixkomprimierung, aber gemeinsame Werte werden aus allen Spalten abgerufen und in der zweiten Zeile nach der Kopfzeile gespeichert. Die Wörterbuchkomprimierung sucht nach exakten Wertübereinstimmungen in allen Spalten und Zeilen auf jeder Seite.
Wir können eine Komprimierung auf Zeilen- und Seitenebene für die folgenden Datenbankobjekte durchführen.
- Eine in einem Heap gespeicherte Tabelle.
- Eine ganze Tabelle, die als Clustered-Index gespeichert ist.
- Indizierte Ansicht.
- Nicht gruppierter Index.
- Partitionierte Indizes und Tabellen.
Hinweis: Wir können die Datenkomprimierung entweder zum Zeitpunkt der Erstellung wie CREATE TABLE, CREATE INDEX oder nach der Erstellung mit dem ALTER-Befehl mit REBUILD-Option wie ALTER TABLE … durchführen. WIEDERAUFBAUEN MIT.
Demo
Die WideWorldImporters Datenbank wird während der gesamten Demo verwendet. Außerdem ein Echtzeit-DW Datenbank wird für den Komprimierungsvorgang berücksichtigt.
Lassen Sie uns die Schritte im Detail durchgehen:
1. Um die Komprimierungseinstellungen für Objekte in der Datenbank anzuzeigen, führen Sie das folgende T-SQL aus:
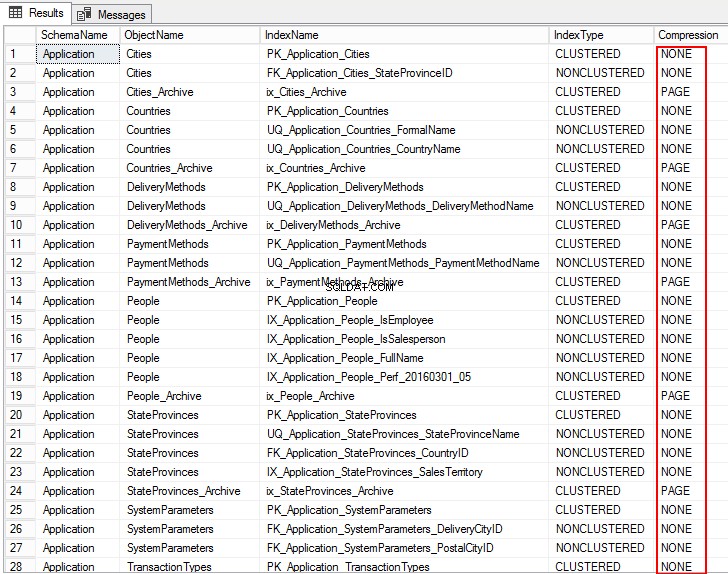
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
Die folgende Ausgabe zeigt den Komprimierungstyp als PAGE, ROW und für mehrere Tabellen als NONE an. Das bedeutet, dass es nicht für die Komprimierung konfiguriert ist.
2. Um die Komprimierung zu schätzen, führen Sie die folgende gespeicherte Systemprozedur sp_estimate_data_compression_savings aus . In diesem Fall wird die gespeicherte Prozedur für die PurchaseOrderLines-Tabellen ausgeführt.
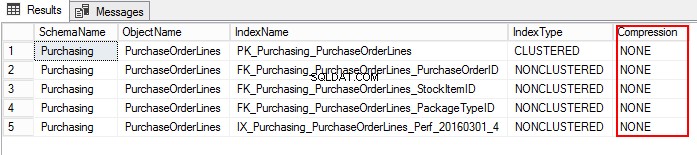
3. Lassen Sie uns die PurchaseOrderLines-Komprimierungseinstellung herausfinden, indem Sie das folgende T-SQL ausführen:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

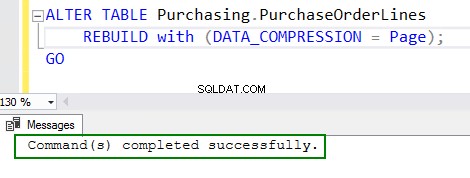
4. Aktivieren Sie die Komprimierung, indem Sie den Befehl ALTER table ausführen:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
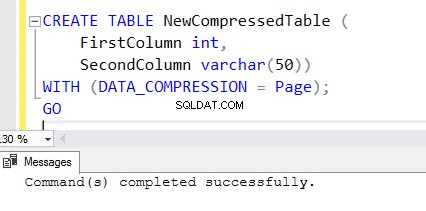
5. Um eine neue Tabelle mit aktivierter Komprimierungsfunktion zu erstellen, fügen Sie die WITH-Klausel am Ende der CREATE TABLE-Anweisung hinzu. Sie können die folgende CREATE TABLE-Anweisung sehen, die zum Erstellen von NewCompressedTable verwendet wird .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Fakten zur Datenkomprimierung
Lassen Sie uns einige der eigentlichen Informationen zur Komprimierung durchgehen
- Komprimierung kann nicht auf Systemtabellen angewendet werden
- Eine Tabelle kann nicht für die Komprimierung aktiviert werden, wenn die Zeilengröße 8060 Byte überschreitet.
- Komprimierte Daten werden im Pufferpool zwischengespeichert; es bedeutet schnellere Reaktionszeiten
- Das Aktivieren der Komprimierung kann dazu führen, dass sich Abfragepläne ändern, da die Daten mit einer anderen Anzahl von Seiten und einer anderen Anzahl von Zeilen pro Seite gespeichert werden.
- Nicht geclusterte Indizes erben keine Komprimierungseigenschaft
- Wenn ein Clustered-Index auf einem Heap erstellt wird, erbt der Clustered-Index den Komprimierungsstatus des Heaps, es sei denn, es wird ein alternativer Komprimierungsstatus angegeben.
- Die Komprimierung auf ROW- und PAGE-Ebene kann offline oder online aktiviert und deaktiviert werden.
- Wenn die Heap-Einstellung geändert wird, müssen alle nicht geclusterten Indizes neu erstellt werden.
- Die Speicherplatzanforderungen für das Aktivieren oder Deaktivieren der Zeilen- oder Seitenkomprimierung sind die gleichen wie für das Erstellen oder Neuerstellen eines Indexes.
- Wenn Partitionen mit der ALTER PARTITION-Anweisung geteilt werden, erben beide Partitionen das Datenkomprimierungsattribut der ursprünglichen Partition.
- Wenn zwei Partitionen zusammengeführt werden, erbt die resultierende Partition das Datenkomprimierungsattribut der Zielpartition.
- Um eine Partition zu wechseln, muss die Datenkomprimierungseigenschaft der Partition mit der Komprimierungseigenschaft der Tabelle übereinstimmen.
- Columnstore-Tabellen und -Indizes werden immer mit der Columnstore-Komprimierung gespeichert.
- Die Datenkomprimierung ist mit Spalten mit geringer Dichte nicht kompatibel, sodass die Tabelle nicht komprimiert werden kann.
Echtzeitszenario
Lassen Sie uns die Datenkomprimierungstechnik durchgehen und die wichtigsten Parameter der Datenkomprimierung verstehen.
Führen Sie das folgende T-SQL aus, um den von jeder Tabelle belegten Speicherplatz zu überprüfen. Die Ausgabe der Abfrage gibt uns detaillierte Informationen über die Verwendung jeder Tabelle. Dies wäre der entscheidende Faktor für die Implementierung der Datenkomprimierung.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
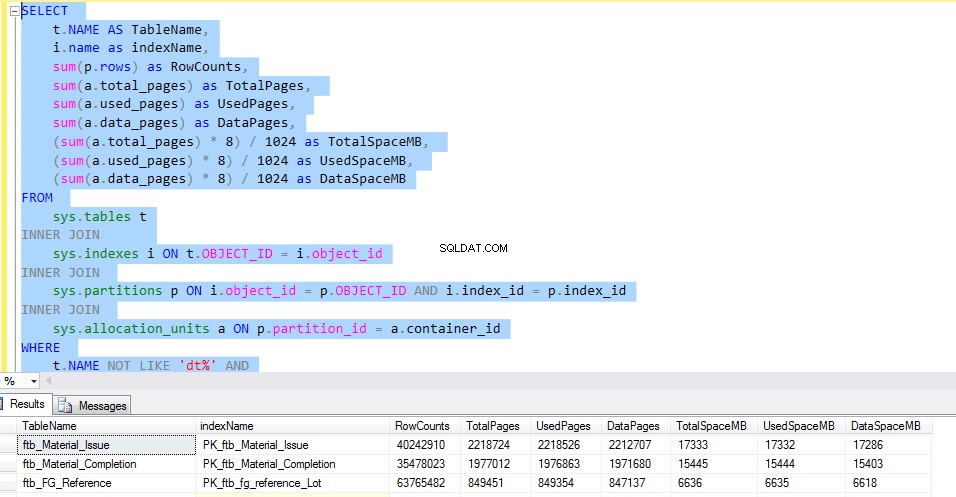
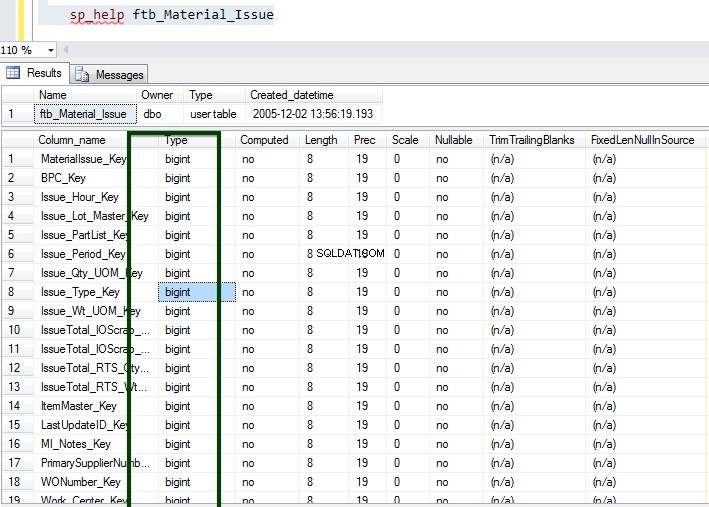
Betrachten wir das ftb_material_Issue Faktentabelle. Die Faktentabelle hat numerische BIGINT-Datentypen.
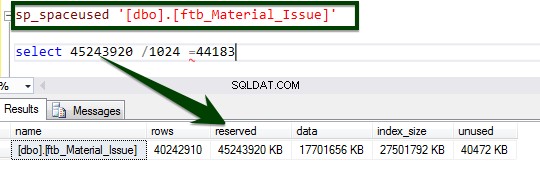
Führen Sie nun die gespeicherte Prozedur sp_spaceused aus, um die Details der Tabelle zu verstehen. Hier erfahren Sie mehr über den Befehl sp_spaceused.
Aktivieren Sie die Komprimierung auf Tabellenebene, indem Sie das folgende T-SQL ausführen. Das folgende T-SQL wurde auf dem Server ausgeführt und es dauerte 34 Minuten und 14 Sekunden, um die Seite auf Tabellenebene zu komprimieren.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
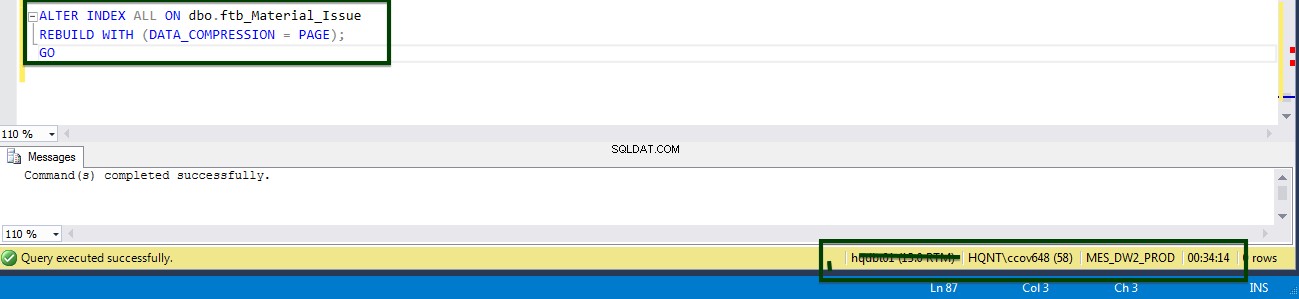
Sie können die CPU- und I/O-Schwankungen während der Ausführung des ALTER-Table-Befehls sehen.
Lassen Sie uns nun den Datenkomprimierungsvergleich „Vorher“ und „Nachher“ durchführen. Die Tabellengröße von ca. 45 GB wird auf ca. 15 GB reduziert.
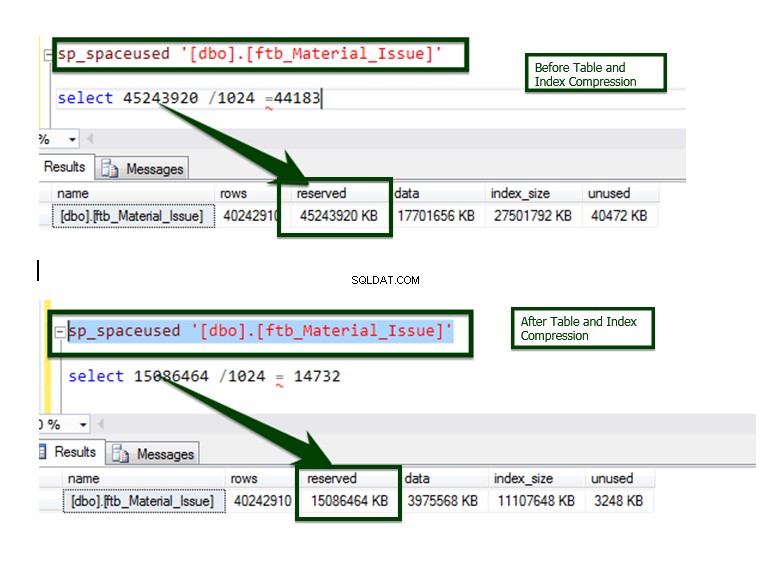
Der Prozess wird bei den meisten Objekten mithilfe eines automatisierten Skripts implementiert, und hier ist das Endergebnis des Vergleichs.
Datenvergleich zwischen vor und nach der Indexkomprimierung.

Zusammenfassung
Die Datenkomprimierung ist eine sehr effektive Technik zur Reduzierung der Datengröße. Weniger Daten erfordern weniger E/A-Prozesse. Das Hinzufügen von Komprimierung zur Datenbank erhöht die Belastung der CPU-Anforderungen. Sie müssen sicherstellen, dass Sie über die verfügbare Verarbeitungskapazität verfügen, um diese Änderungen effizient zu berücksichtigen. Daher ist es besser, zuerst ein wenig zu recherchieren und die Arten von Gewinnen zu sehen, die zu erwarten sind, bevor Sie die Änderungen anwenden, um die Datenkomprimierung zu ermöglichen. Es ist sehr vorteilhaft bei der Einrichtung von Cloud-Datenbanken, wo es um Kosten geht.
Stufen Sie die Kompressionen ein (machen Sie sie nicht alle auf einmal) und komprimieren Sie in Zeiten geringer Aktivität. Datenkomprimierung und Sicherungskomprimierung koexistieren gut und können zu zusätzlichen Speicherplatzeinsparungen führen, also machen Sie weiter und lassen Sie sich verwöhnen.
Die Komprimierung reduziert nicht nur die physische Dateigröße, sondern auch die Festplatten-E/A, was die Leistung vieler Datenbankanwendungen sowie Datenbanksicherungen erheblich verbessern kann.
Die Entscheidung zur Implementierung der Komprimierung ist einfacher, wenn wir die zugrunde liegende Infrastruktur und die Geschäftsanforderungen kennen. Wir können definitiv das verfügbare Systemverfahren verwenden, um Komprimierungseinsparungen zu verstehen und abzuschätzen. Diese gespeicherte Prozedur liefert keine Details, die Ihnen mitteilen, wie sich die Komprimierung positiv oder negativ auf Ihr System auswirkt. Es ist offensichtlich, dass es bei jeder Art von Komprimierung Kompromisse gibt. Wenn Sie die gleichen Muster großer Datenmengen haben, ist die Komprimierung der Schlüssel zum Platzsparen. Da die CPU-Leistung wächst und jedes System an Mehrkernstrukturen gebunden ist, kann die Komprimierung für viele Systeme geeignet sein. Ich würde empfehlen, Ihre Systeme zu testen. Testen Sie, um sicherzustellen, dass die Leistung nicht negativ beeinflusst wird. Wenn ein Index viele Aktualisierungen und Löschungen enthält, können die CPU-Kosten zum Komprimieren und Dekomprimieren der Daten die E/A- und RAM-Einsparungen durch die Datenkomprimierung überwiegen. Nicht jede Datenbank oder Tabelle ist automatisch ein guter Kandidat für die Anwendung der Komprimierung. Daher ist es am besten, zuerst ein wenig zu recherchieren, um zu sehen, welche Art von Gewinnen zu erwarten sind, bevor Sie die Änderungen anwenden, um die Datenkomprimierung in Ihren Datenbanken zu ermöglichen. Sie müssen die Komprimierung testen, um zu sehen, ob sie in Ihrer Umgebung gut funktioniert, da sie in Datenbanken mit vielen Einfügungen möglicherweise nicht gut funktioniert.
Referenzen
Editionen und unterstützte Features von SQL Server 2016
Datenkomprimierung
Implementierung der Zeilenkomprimierung
Implementierung der Seitenkomprimierung