Zeitreihendatenbanken sind, wie der Name schon sagt, darauf ausgelegt, Daten zu speichern, die sich mit der Zeit ändern. Dies können alle Arten von Daten sein, die im Laufe der Zeit gesammelt wurden. Es können Metriken sein, die von einigen Systemen gesammelt wurden, und tatsächlich sind alle Trendsysteme Beispiele für die Zeitreihendaten.
Wir haben verschiedene Arten von Zeitreihendatenbanken, welche sollten wir verwenden?
In diesem Blog werden wir sehen, was die Hauptunterschiede zwischen zwei der Hauptoptionen sind, TimescaleDB und InfluxDB.
InfluxDB
InfluxDB wurde von InfluxData erstellt. Es ist eine benutzerdefinierte Open-Source-NoSQL-Zeitreihendatenbank, die in Go geschrieben wurde. Der Datenspeicher bietet eine SQL-ähnliche Sprache zum Abfragen der Daten namens InfluxQL, die es den Entwicklern leicht macht, sie in ihre Anwendungen zu integrieren. Es hat auch eine neue benutzerdefinierte Abfragesprache namens Flux, diese Sprache mag einige Aufgaben erleichtern, aber es gibt immer eine Lernkurve bei der Übernahme einer benutzerdefinierten Abfragesprache.
Dies ist ein Beispiel für eine Flux-Abfrage:
from(db:"testing")
|> range(start:-1h)
|> filter(fn: (r) => r._measurement == "cpu")
|> exponentialMovingAverage()In dieser Datenbank hat jede Messung einen Zeitstempel und einen zugeordneten Satz von Tags und Feldern. Das Feld stellt die tatsächlichen Messwerte dar, während das Tag die Metadaten zur Beschreibung der Messungen darstellt. Die Felddatentypen sind auf Floats, Ints, Strings und Booleans beschränkt und können nicht geändert werden, ohne die Daten neu zu schreiben. Die Tag-Werte werden indiziert. Sie werden als Zeichenfolgen dargestellt und können nicht aktualisiert werden.
Der Einstieg in InfluxDB ist recht einfach, da Sie sich keine Gedanken über das Erstellen von Schemas oder Indizes machen müssen. Es ist jedoch ziemlich starr und begrenzt, ohne die Möglichkeit, zusätzliche Indizes zu erstellen, Indizes für fortlaufende Felder, Metadaten nachträglich zu aktualisieren, Datenvalidierung zu erzwingen usw.
Es ist nicht schemalos. Es gibt ein zugrunde liegendes Schema, das automatisch aus den Eingabedaten erstellt wird.
InfluxDB muss mehrere Tools für die Fehlertoleranz von Grund auf neu implementieren, wie Replikation, Hochverfügbarkeit und Backup/Restore, und ist für die Zuverlässigkeit auf der Festplatte verantwortlich. Wir sind auf die Verwendung dieser Tools beschränkt und viele dieser Funktionen, wie HA, sind nur in der Enterprise-Version verfügbar.
Das InfluxDB-Backup-Tool kann ein vollständiges oder inkrementelles Backup durchführen und für die Point-in-Time-Recovery verwendet werden.
InfluxDB bietet auch eine deutlich bessere Komprimierung auf der Festplatte als PostgreSQL und TimescaleDB.
TimescaleDB
TimescaleDB ist eine Open-Source-Zeitreihendatenbank, die für schnelle Aufnahme und komplexe Abfragen optimiert ist und vollständiges SQL unterstützt. Es basiert auf PostgreSQL und bietet das Beste aus NoSQL- und relationalen Welten für Zeitreihendaten.
Dies ist ein Beispiel für eine TimescaleDB-Abfrage:
SELECT time,
exponential_moving_average(value, 0.5) OVER (ORDER BY time)
FROM testing
WHERE measurement = cpu and time > now() - '1 hour';TimescaleDB ist als PostgreSQL-Erweiterung eine relationale Datenbank. Dies ermöglicht eine kurze Lernkurve für neue Benutzer und das Vererben von Tools wie pg_dump oder pg_backup zum Sichern und Hochverfügbarkeitstools, was ein Vorteil gegenüber anderen Zeitreihendatenbanken ist. Es unterstützt auch die Streaming-Replikation als primäre Replikationsmethode, die in einer Einrichtung mit hoher Verfügbarkeit verwendet werden kann. In Bezug auf Failover und Backups können Sie diesen Prozess automatisieren, indem Sie ein externes System wie ClusterControl verwenden.
In TimescaleDB wird jede Zeitreihenmessung in einer eigenen Zeile aufgezeichnet, mit einem Zeitfeld, gefolgt von einer beliebigen Anzahl anderer Felder, die Floats, Ints, Strings, Boolesche Werte, Arrays, JSON-Blobs, Geodaten, Datum/Uhrzeit/ Zeitstempel, Währungen, Binärdaten und mehr.
Sie können Indizes für jedes Feld (Standardindizes) oder mehrere Felder (zusammengesetzte Indizes) oder für Ausdrücke wie Funktionen erstellen oder sogar einen Index auf eine Teilmenge von Zeilen beschränken (Teilindex). Jedes dieser Felder kann als Fremdschlüssel für sekundäre Tabellen verwendet werden, die dann zusätzliche Metadaten speichern können.
Auf diese Weise müssen Sie ein Schema auswählen und entscheiden, welche Indizes Sie für Ihr System benötigen.
Leistung
Wenn wir über Leistung sprechen, können wir den großartigen TimescaleDB-Vergleichsblog lesen. Dort haben Sie einen detaillierten Leistungsvergleich zwischen beiden Datenbanken mit Diagrammen und Metriken. Sehen wir uns einige der wichtigsten Informationen aus diesem Blog an.
Einfügungen
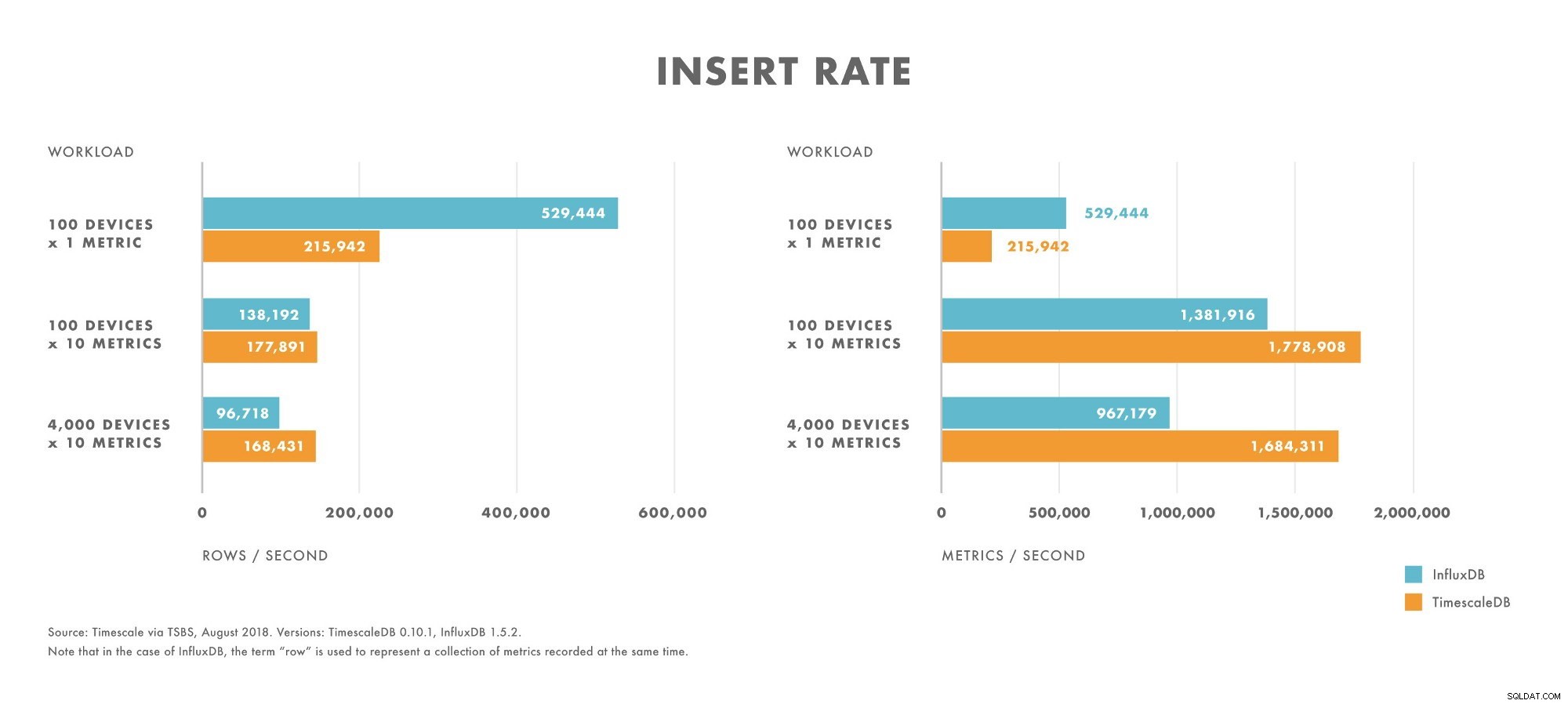
- Bei Workloads mit sehr niedriger Kardinalität (z. B. 100 Geräte) übertrifft InfluxDB TimescaleDB.
- Wenn die Kardinalität zunimmt, fällt die Einfügungsleistung von InfluxDB schneller ab als auf TimescaleDB.
- Bei Workloads mit mittlerer bis hoher Kardinalität (z. B. 100 Geräte, die 10 Metriken senden) übertrifft TimescaleDB InfluxDB.

Leselatenz
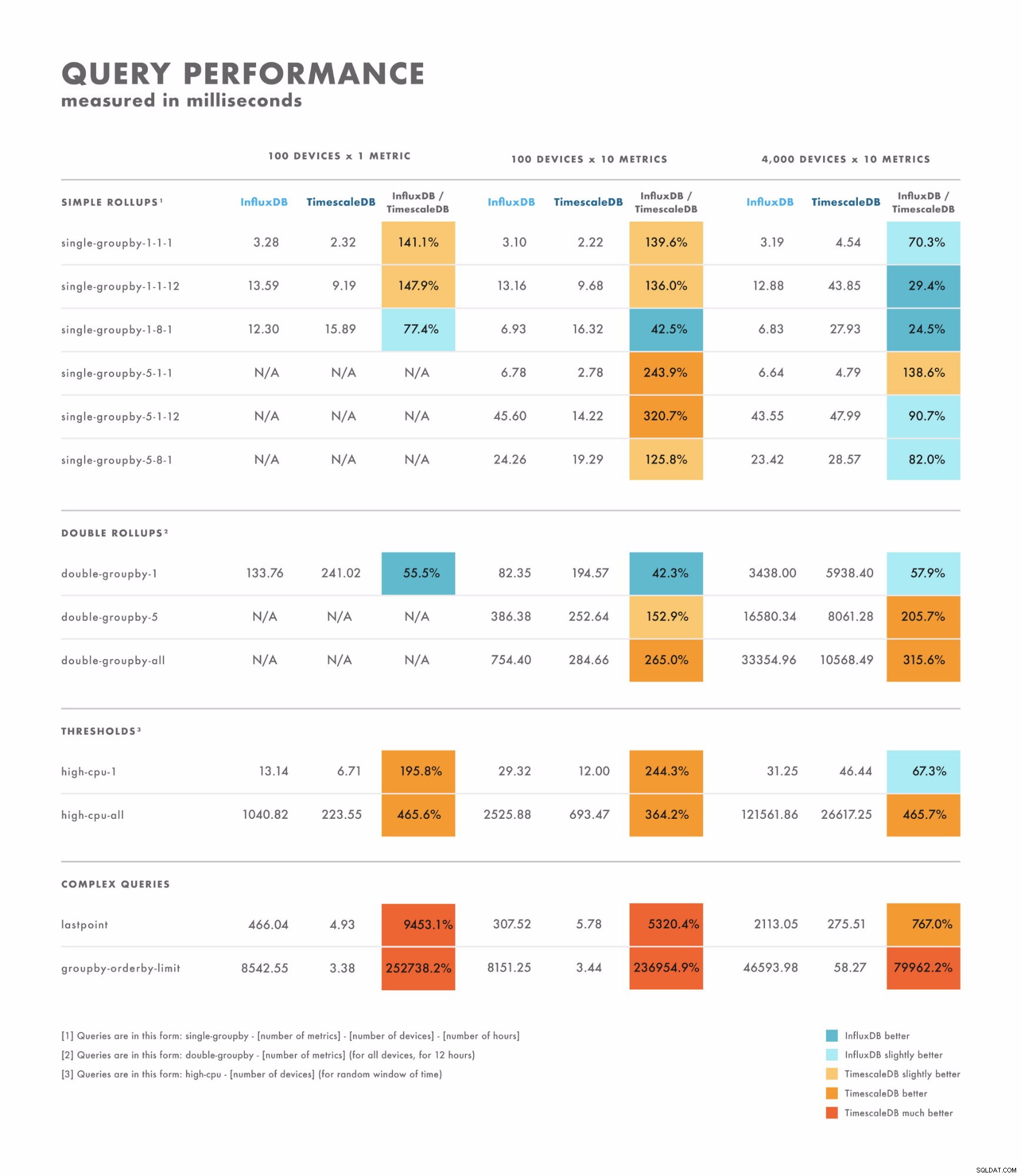
- Bei einfachen Abfragen variieren die Ergebnisse ziemlich stark:Es gibt einige, bei denen eine Datenbank eindeutig besser ist als die andere, während andere von der Kardinalität Ihres Datensatzes abhängen. Der Unterschied liegt hier oft im Bereich einstelliger bis zweistelliger Millisekunden.
- Bei komplexen Abfragen übertrifft TimescaleDB InfluxDB bei weitem und unterstützt eine breitere Palette von Abfragetypen. Der Unterschied liegt hier oft im Bereich von Sekunden bis zu mehreren zehn Sekunden.
- In Anbetracht dessen besteht die beste Methode zum ordnungsgemäßen Testen darin, Benchmarks mit den Abfragen durchzuführen, die Sie ausführen möchten.
Stabilitätsprobleme
- InfluxDB hat Stabilitäts- und Leistungsprobleme bei hohen (100K+) Kardinalitäten.
Schlussfolgerung
Wenn Ihre Daten in das InfluxDB-Datenmodell passen und Sie nicht davon ausgehen, dass sich dies in Zukunft ändern wird, sollten Sie die Verwendung von InfluxDB in Betracht ziehen, da dieses Modell für den Einstieg einfacher ist und wie die meisten Datenbanken, die einen spaltenorientierten Ansatz verwenden, bietet eine bessere Komprimierung auf der Festplatte als PostgreSQL und TimescaleDB.
Das relationale Modell ist jedoch vielseitiger und bietet mehr Funktionalität, Flexibilität und Kontrolle als das InfluxDB-Modell. Dies ist besonders wichtig, wenn sich Ihre Anwendung weiterentwickelt. Und bei der Planung Ihres Systems sollten Sie sowohl die aktuellen als auch die zukünftigen Anforderungen berücksichtigen.
In diesem Blog konnten wir einen kurzen Vergleich zwischen TimescaleDB und InfluxDB sehen, und wir könnten sagen, dass TimescaleDB als PostgreSQL-Erweiterung ziemlich ausgereift und funktionsreich aussieht, da es viel von PostgreSQL erbt. Aber Sie können Ihre eigene Entscheidung basierend auf den zuvor in diesem Blog erwähnten Vor- und Nachteilen treffen und sicherstellen, dass Sie Ihre eigene Arbeitslast bewerten. Viel Glück in dieser neuen Welt der Zeitreihendatenbanken!