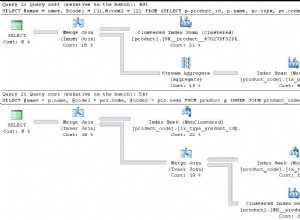
Dies ist der zweite Teil des Materials zur semantischen Suche in SQL Server . Im vorherigen Artikel haben wir die Grundlagen untersucht. Jetzt konzentrieren wir uns auf den Vergleich von Dokumenten, die im Windows-Dateisystem gespeichert sind, und die vergleichende Analyse mit der semantischen Suche in SQL Server.
Durchführen einer vergleichenden Analyse namensbasierter Dokumente
Wir werden eine vergleichende Analyse von Dokumenten anhand ihrer Standardbenennung durchführen. Lassen Sie uns an dieser Stelle eine schnelle Überprüfung durchführen, indem wir das EmployeesFilestreamSample abfragen Datenbank, die wir zuvor eingerichtet haben:
-- View stored documents managed by File Table to check
SELECT stream_id
,[name]
,file_type
,creation_time
FROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore
Die Ergebnisse müssen uns gespeicherte Dokumente zeigen:
Checkliste für semantische Suche
Wir haben bereits die Datenbank und zwei Beispiel-MS-Word-Dokumente im Dateisystem, die die Dateitabelle verwenden (Sie können sich auf Teil 1 beziehen, um das Wissen bei Bedarf aufzufrischen). Das ist jedoch nicht der Fall qualifizieren unsere Dokumente automatisch für das semantische Suchszenario.
Die semantische Suche kann auf eine der folgenden Arten aktiviert werden:
- Falls Sie die Volltextsuche bereits eingerichtet haben , können Sie die semantische Suche in einem einzigen Schritt aktivieren.
- Sie können die semantische Suche direkt einrichten, aber zuvor müssen Sie auch die Volltextsuche einrichten.
Test der Volltextsuche vor der Einrichtung der semantischen Suche
Wenn eine Volltextabfrage funktioniert, müssen wir nur die semantische Suche aktivieren. Um dies zu überprüfen, führen Sie eine Volltextabfrage für die gewünschte Tabelle aus:
-- Searching word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
Die Ausgabe:
Daher müssen wir zuerst die Anforderungen für die Volltextsuche erfüllen und dann die semantische Suche aktivieren.
Ermöglichung der semantischen Suche zur Verwendung
Mindestens zwei der folgenden Punkte sind für die Nutzung der Semantischen Suche notwendig:
- Eindeutiger Index
- Ein Volltextkatalog
- Ein Volltextindex
Führen Sie das folgende T-SQL-Skript aus, um einen eindeutigen Index zu erstellen:
-- Create unique index required for Semantic Search
CREATE UNIQUE INDEX UQ_Stream_Id
ON EmployeesDocumentStore(stream_id)
GO
Erstellen Sie einen Volltextkatalog basierend auf dem neu erstellten eindeutigen Index. Erstellen Sie dann wie unten gezeigt einen Volltextindex:
-- Getting Semantic Search ready to be used with File Table
CREATE FULLTEXT CATALOG EmployeesFileTableCatalog WITH ACCENT_SENSITIVITY = ON;
CREATE FULLTEXT INDEX ON EmployeesDocumentStore
(
name LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_type LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_stream TYPE COLUMN file_type LANGUAGE 1033 STATISTICAL_SEMANTICS
)
KEY INDEX UQ_Stream_Id
ON EmployeesFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM;
Die Ergebnisse:
Test der Volltextsuche nach Einrichtung der semantischen Suche
Lassen Sie uns dieselbe Volltextabfrage ausführen, um nach dem Wort Employee zu suchen in den hinterlegten Dokumenten:
-- Searching (after Semantic Search setup) word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
Die Ausgabe:
Es ist in Ordnung, dass Volltextabfragen gegen die Dateitabelle arbeiten, während wir sie für die semantische Suche vorbereiten.
Weitere MS Word-Dokumente hinzufügen
Wir gehen zum EmployeesDocumentStore Dateitabelle und klicken Sie auf Dateitabellenverzeichnis durchsuchen :
Erstellen und speichern Sie ein neues Dokument namens Sadaf Contract Employee :
Als nächstes fügen Sie dem neu erstellten Dokument den folgenden Text hinzu. Die erste Zeile muss der Titel des Dokuments sein!
Sadaf-Vertragsangestellter (Titel)
Sadaf ist ein sehr effizienter Business Analyst, der auf Kontaktbasis arbeitet. Sie ist in der Lage, geschäftliche Anforderungen zu handhaben und sie in technische Spezifikationen umzuwandeln, an denen die Entwickler arbeiten können. Sie ist eine sehr erfahrene Business-Analystin.
Fügen Sie ein weiteres Dokument namens Mike Permanent Employee hinzu :
Aktualisieren Sie das Dokument mit dem folgenden Text:
Mike Festangestellter (Titel des Dokuments)
Mike ist ein frischgebackener Programmierer, dessen Expertise die Webentwicklung umfasst. Er lernt schnell und freut sich über jedes Projekt. Er hat starke Fähigkeiten zur Problemlösung, aber er hat weniger Geschäftskenntnisse. Er benötigt Unterstützung von anderen Entwicklern oder Geschäftsanalysten, um das Problem zu verstehen und die Anforderungen zu erfüllen.
Er ist gut, wenn er an kleinen Projekten arbeitet, aber er kämpft, wenn er ein großes oder komplexes Projekt bekommt.
Wir haben vier Dokumente im Windows-Dateisystem gespeichert, das von File Table verwaltet wird. Diese Dokumente sollten von der semantischen Suche (einschließlich Volltextsuche) verwendet werden.
Wichtig:Obwohl wir gerade vier MS Word-Dokumente als Beispiel in dem Ordner gespeichert haben, können Sie sich vorstellen, wie wichtig die Verwendung der semantischen Suche ist, wenn Hunderte solcher Dokumente von einer SQL Server-Datenbank verwaltet werden und Sie diese Dokumente abfragen müssen um wertvolle Informationen zu finden.
Die Standardbenennung von Dokumenten ist sehr wichtig für die erfolgreiche Implementierung dieses Ansatzes.
Einfaches Zählen von Dokumenten
Wir können diese Dokumente vergleichen und die Unterschiede und Ähnlichkeiten anhand ihrer Standardbenennung mithilfe der semantischen Suche definieren. Beispielsweise kann uns eine einfache Abfrage die Gesamtzahl der im Windows-Ordner gespeicherten Dokumente mitteilen:
-- Getting total number of stored documents
SELECT COUNT(*) AS Total_Documents FROM EmployeesDocumentStore

Vergleich von unbefristeten und vertragsbasierten Mitarbeitern
Dieses Mal verwenden wir die semantische Suche, um die Anzahl der festangestellten und vertragsbasierten Mitarbeiter in unserer Organisation zu vergleichen:
-- Creating a summary table variable
DECLARE @Documents TABLE
(DocumentType VARCHAR(100),
DocumentsCount INT)
INSERT INTO @Documents -- Storing total number of stored documents into summary table
SELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStore
INSERT INTO @Documents -- Storing total number of permanent employees documents stored into summary table
SELECT 'Total Permanent Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Permanent'
INSERT INTO @Documents --Storing total number of permanent employees documents stored
SELECT 'Total Contract Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Contract'
SELECT DocumentType,DocumentsCount FROM @Documents
Die Ausgabe:
Lassen Sie uns eine einfache (auf Dokumentnamen basierende) semantische Suchabfrage ausführen, um den Schlüsselsatz anzuzeigen und seine relative Punktzahl für jedes Dokument:
-- Getting keyphrase and relative score for all the documents
SELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
ORDER BY score
Die Ausgabe:
Lassen Sie uns den Dokumentnamen weitere Details hinzufügen. Wir werden sie wie folgt umbenennen:
- Festangestellter Asif – Erfahrener Projektmanager
- Mike Festangestellter – Frischer Programmierer
- Peter Festangestellter – Fresh Project Manager
- Sadaf Vertragsangestellter – Erfahrener Business Analyst
Neue Mitarbeiter finden (Dokumente)
Finden Sie die Dokumente zu neuen Mitarbeitern anhand ihrer Titel (Standardbenennung):
-- Getting document name-based scoring to find fresh employees for a new project
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName
,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) where keyphrase='fresh'
order by DocumentName desc
Die Ergebnisse:
Erfahrene Mitarbeiter finden (Dokumente)
Angenommen, wir möchten schnell alle Details erfahrener Mitarbeiter für das bevorstehende komplexe Projekt überprüfen. Verwenden Sie die folgende semantische Suchabfrage:
-- Getting document name-based scoring to find all experienced employees
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='experienced' order by DocumentName
Die Ausgabe:
Alle Projektmanager finden (Dokumente)
Wenn wir schließlich die Dokumente für alle Projektmanager schnell durchgehen möchten, benötigen wir die folgende Semantic-Search-Abfrage:
-- Getting document name-based scoring to find all project managers
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='Project'
Die Ergebnisse:
Nach der Implementierung der exemplarischen Vorgehensweise können Sie mithilfe der Dateitabelle erfolgreich unstrukturierte Daten wie MS Word-Dokumente in einem Windows-Ordner speichern.
Namensbasierte Analyseprüfung
Bisher haben wir gelernt, wie man mithilfe der semantischen Suche eine namensbasierte Analyse von Dokumenten durchführt, die in einer Dateitabelle gespeichert sind. Wir müssen jedoch die folgenden Bedingungen erfüllen:
- Standardbenennung sollte vorhanden sein.
- Namen sollten die für die Analyse erforderlichen Informationen enthalten.
Diese Bedingungen sind auch Einschränkungen der namensbasierten Analyse. Aber das bedeutet nicht, dass wir damit nicht viel anfangen können.
Unser Fokus bleibt auf dem namens-/spaltenbasierten Ansatz der semantischen Suche.
Sehen Sie sich die Namensspalten der Dokumente an
Sehen wir uns einige der Hauptspalten der Tabelle Dokumente an, einschließlich des Namens Spalte:
USE EmployeesFilestreamSample
-- View name column with the file types of the stored documents in File Table for analysis
SELECT name,file_type
FROM dbo.EmployeesDocumentStore
Die Ausgabe:
Die SEMANTICKEYPHRASETABLE-Funktion verstehen
SQL Server bietet die SEMANTICKEYPHRASETABLE an Funktion, um das Dokument mit der semantischen Suche zu analysieren. Die Syntax lautet wie folgt:
SEMANTICKEYPHRASETABLE
(
table,
{ column | (column_list) | * }
[ , source_key ]
)
Diese Funktion gibt uns Schlüsselphrasen, die mit dem Dokument verbunden sind. Wir können sie verwenden, um Dokumente anhand ihres Namens oder Inhalts zu analysieren. In unserem Fall müssen wir diese Funktion nicht nur verwenden, sondern auch verstehen, wie man sie richtig einsetzt.
Die Funktion benötigt folgende Daten:
- Name der Dateitabelle, die für die Analyse der semantischen Suche verwendet werden soll.
- Name der Spalte, die für die Analyse der semantischen Suche verwendet werden soll.
Dann gibt es die folgenden Daten zurück:
- Spalten-ID – die Spaltennummer
- Document_Key – der standardmäßige Primärschlüssel für das Dateitabellendokument
- Schlüsselwort – ist ein Satz, den Semantic Search für die Analyse indiziert. Dies gilt sowohl für den Namen als auch für den Inhalt des Dokuments, je nachdem, für welche Spalte wir die Schlüsselphrasen sehen möchten
- Ergebnis – bestimmt die Stärke einer mit einem Dokument verknüpften Schlüsselphrase, z. B. wie ein Dokument am besten anhand seiner Schlüsselphrase erkannt wird. Die Punktzahl kann zwischen 0,0 und 1,0 liegen.
Alle Dokumente mit der SEMANTICKEYPHRASETABLE-Funktion analysieren
Wir verwenden die SEMANTICKEYPHRASETABLE Funktion zur namensbasierten Analyse der Dokumente, die in dem von der Dateitabelle verwalteten Windows-Ordner gespeichert sind.
Führen Sie das folgende T-SQL-Skript aus:
USE EmployeesFilestreamSample
-- View key phrases and their score for the name column
SELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)
order by score desc
Die Ausgabe:
Wir haben eine Liste aller Schlüsselphrasen, die allen Dokumenten und ihren Bewertungen beigefügt sind. Die column_id 3 in der obersten Zeile steht der Name Säule. Außerdem haben wir die Funktion auch aufgerufen, indem wir diese Spalte (Name) angegeben haben:
Sie finden den document_key : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260, wobei das folgende Skript ausgeführt wird (obwohl klar ist, dass dieses Dokument dasjenige ist, dessen Name den Schlüsselsatz sadaf enthält ):
USE EmployeesFilestreamSample
-- Finding document name by its key (path_locator)
SELECT name,path_locator FROM dbo.EmployeesDocumentStore
WHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260
Die Ausgabe:
Der Schlüsselsatz Sadaf hat die beste Punktzahl erhalten :1.0 .
So ist im Falle der Standard-Dokumentbenennung mit ausreichenden Informationen für die semantische Suchanalyse unser Schlüsselwort sadaf ist die beste Übereinstimmung für diesen bestimmten Dokumentnamen.
Analysieren eines bestimmten Dokuments mit der SEMANTICKEYPHRASETABLE-Funktion
Wir können unsere Analyse der semantischen Suche anhand des Namens eingrenzen Säule. Beispielsweise müssen wir nur die Namensspalte- anzeigen basierte Schlüsselphrasen eines bestimmten Dokuments. Wir können den Dokumentenschlüssel in der SEMANTICKEYPHRASETABLE angeben Funktion.
Zuerst identifizieren wir den Dokumentschlüssel für das Dokument, in dem wir alle Schlüsselphrasen sehen möchten. Führen Sie das folgende T-SQL-Skript aus:
-- Find document_key of the document where the name contains Peter
SELECT name,path_locator as document_key From EmployeesDocumentStore
WHERE name like '%Peter%'
Der Dokumentenschlüssel ist 0xFF6A92952500812FF013376870181CFA6D7C070220
Sehen wir uns nun dieses Dokument bezüglich aller Schlüsselphrasen an, die den Dokumentnamen definieren können:
-- View all the key phrases and their score for a document related to Peter permanent employee
SELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)
INNER JOIN dbo.EmployeesDocumentStore on path_locator=document_key
order by score desc
Die Ergebnisse:
Der Schlüsselbegriff Mitarbeiter erhält die höchste Punktzahl in diesem Dokument. Wir können sehen, dass alle Wörter der Spalte Schlüsselphrasen sind, die die Bedeutung des Dokuments bestimmen.
Verstehen der SEMANTICSSIMILARITYTABLE-Funktion
Diese Funktion hilft uns, ein Dokument anhand von Schlüsselbegriffen mit allen anderen Dokumenten zu vergleichen. Die Syntax dieser Funktion lautet wie folgt:
SEMANTICSIMILARITYTABLE
(
table,
{ column | (column_list) | * },
source_key
)
Es erfordert den Namen der Tabelle, der Spalte und des Dokumentschlüssels, um mit anderen Dokumenten übereinzustimmen. Zum Beispiel können wir feststellen, dass zwei Dokumente ähnlich sind, wenn sie eine gute Keyword-Matching-Punktzahl haben.
Dokumente mit der SEMANTICSSIMILARITYTABLE-Funktion vergleichen
Vergleichen wir ein Dokument mithilfe der SEMANTIKÄHNLICHKEITSTABELLE mit anderen Dokumenten Funktion.
Vergleich der Dokumente aller Projektmanager
Wir müssen alle Dokumente sehen, die sich auf Projektmanager beziehen. Aus den obigen Beispielen wissen wir, dass der Dokumentenschlüssel für das angegebene Dokument ist 0xFF6A92952500812FF013376870181CFA6D7C070220 . Daher können wir diesen Schlüssel verwenden, um andere Übereinstimmungen zu finden, einschließlich Projektmanager:
USE EmployeesFilestreamSample
-- View all the documents closely related to Peter project manager
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
Die Ausgabe:
Das am engsten verwandte Dokument ist Asif Permanent Employee – Experienced Project Manager.docx
Vergleich der Dokumente erfahrener Business-Analysten
Jetzt werden wir die Dokumente zum erfahrenen Business Analysten vergleichen s und finden Sie die beste Übereinstimmung mit der semantischen Suche. Wir beschränken uns auf die dokumentennamenbasierte Analyse:
USE EmployeesFilestreamSample
-- Finding document_key for experienced business analyst
select name,path_locator as document_key from EmployeesDocumentStore
where name like '%experienced business analyst%'
-- View all the documents closely related to experienced business analyst
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
Die Ausgabe:
Wie wir aus den obigen Ergebnissen ersehen können, bezog sich die beste Übereinstimmung für das Dokument auf den erfahrenen Business-Analysten ist das Dokument des erfahrenen Projektleiters weil sie beide erfahren sind . Dennoch weist die Punktzahl von 0,3 darauf hin, dass zwischen diesen beiden Dokumenten nicht viel gemeinsam ist.
Schlussfolgerung
Herzliche Glückwünsche! Wir haben erfolgreich gelernt, wie man Dokumente in Windows-Ordnern ablegt und diese mit Hilfe der semantischen Suche analysiert. Wir haben auch die Funktionen untersucht, die in der Praxis verwendet werden können. Jetzt können Sie das neue Wissen anwenden und die folgenden Übungen ausprobieren
Bleiben Sie dran für weitere Materialien!