Halten Sie immer noch am Parent/Child-Design fest oder möchten Sie etwas Neues ausprobieren, wie z. B. die SQL Server-Hierarchie-ID? Nun, es ist wirklich neu, weil hierarchieID seit 2008 ein Teil von SQL Server ist. Natürlich ist die Neuheit an sich kein überzeugendes Argument. Beachten Sie jedoch, dass Microsoft diese Funktion hinzugefügt hat, um 1:n-Beziehungen mit mehreren Ebenen besser darzustellen.
Sie fragen sich vielleicht, welchen Unterschied es macht und welche Vorteile Sie durch die Verwendung vonhierarchieID anstelle der üblichen Eltern-/Kind-Beziehungen haben. Wenn Sie diese Option noch nie erkundet haben, könnte sie für Sie überraschend sein.
Die Wahrheit ist, dass ich diese Option seit ihrer Veröffentlichung nicht untersucht habe. Als ich es jedoch endlich tat, fand ich es eine großartige Innovation. Es ist ein besser aussehender Code, aber er enthält viel mehr. In diesem Artikel werden wir all diese hervorragenden Möglichkeiten kennenlernen.
Bevor wir uns jedoch mit den Besonderheiten der Verwendung von SQL ServerhierarchieID befassen, wollen wir ihre Bedeutung und ihren Umfang verdeutlichen.
Was ist die SQL Server-Hierarchie-ID?
Die SQL Server-Hierarchie-ID ist ein integrierter Datentyp, der zur Darstellung von Bäumen entwickelt wurde, die der häufigste Typ hierarchischer Daten sind. Jedes Element in einem Baum wird als Knoten bezeichnet. In einem Tabellenformat ist dies eine Zeile mit einer Spalte vom Datentyp „hierarchieID“.
Normalerweise demonstrieren wir Hierarchien anhand eines Tabellendesigns. Eine ID-Spalte stellt einen Knoten dar, und eine andere Spalte steht für den Elternknoten. Mit der SQL Server-HierarchieID benötigen wir nur eine Spalte mit dem DatentyphierarchieID.
Wenn Sie eine Tabelle mit einer Hierarchie-ID-Spalte abfragen, sehen Sie Hexadezimalwerte. Es ist eines der visuellen Bilder eines Knotens. Eine andere Möglichkeit ist ein String:
„/“ steht für den Wurzelknoten;
„/1/“, „/2/“, „/3/“ oder „/n/“ stehen für die Kinder – direkte Nachkommen 1 bis n;
„/1/1/“ oder „/1/2/“ sind die „Kinder von Kindern – „Enkel“. Die Zeichenfolge wie „/1/2/“ bedeutet, dass das erste Kind der Wurzel zwei Kinder hat, die wiederum zwei Enkel der Wurzel sind.
Hier ist ein Beispiel dafür, wie es aussieht:
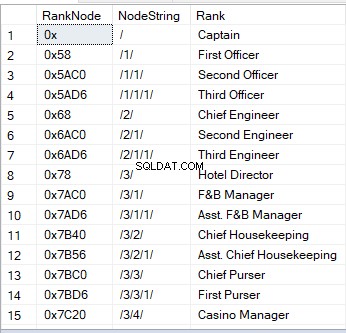
Im Gegensatz zu anderen Datentypen können hierarchieID-Spalten integrierte Methoden nutzen. Beispiel:Sie haben eine Hierarchie-ID-Spalte mit dem Namen RankNode , können Sie die folgende Syntax verwenden:
RankNode.
SQL Server HierarchyID-Methoden
Eine der verfügbaren Methoden ist IsDescendantOf . Es gibt 1 zurück, wenn der aktuelle Knoten ein Nachkomme eineshierarchieID-Werts ist.
Sie können Code mit dieser Methode ähnlich der folgenden schreiben:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Andere Methoden, die mit der Hierarchie-ID verwendet werden, sind die folgenden:
- GetRoot – die statische Methode, die die Wurzel des Baums zurückgibt.
- GetDescendant – gibt einen Kindknoten eines Elternteils zurück.
- GetAncestor – gibt eine Hierarchie-ID zurück, die den n-ten Vorfahren eines bestimmten Knotens darstellt.
- GetLevel – gibt eine Ganzzahl zurück, die die Tiefe des Knotens darstellt.
- ToString – gibt den String mit der logischen Repräsentation eines Knotens zurück. ToString wird implizit aufgerufen, wenn die Konvertierung von der Hierarchie-ID in den String-Typ erfolgt.
- GetReparentedValue – verschiebt einen Knoten vom alten Elternteil zum neuen Elternteil.
- Parse – verhält sich wie das Gegenteil von ToString . Es konvertiert die String-Ansicht einer hierarchyID Wert in Hexadezimal.
SQL Server HierarchyID Indizierungsstrategien
Um sicherzustellen, dass Abfragen für Tabellen mit der Hierarchie-ID so schnell wie möglich ausgeführt werden, müssen Sie die Spalte indizieren. Es gibt zwei Indizierungsstrategien:
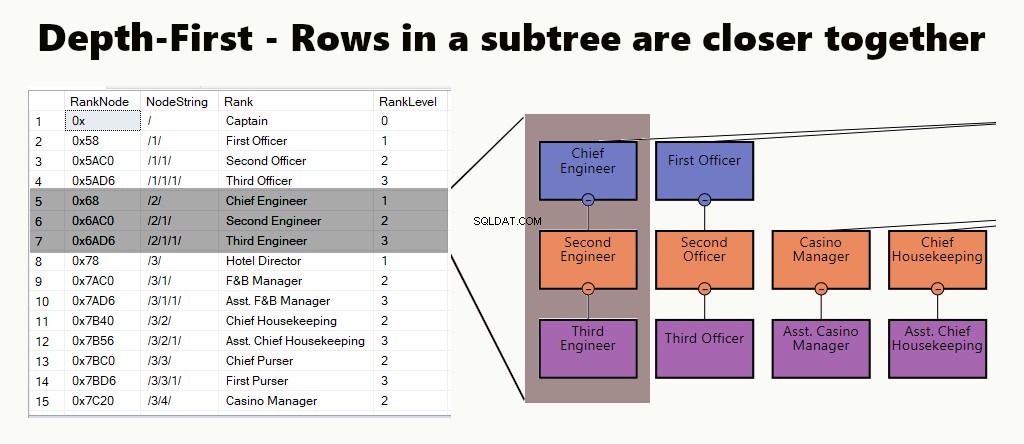
TIEFE ZUERST
Bei einem Tiefenindex liegen die Teilbaumzeilen näher beieinander. Es eignet sich für Abfragen wie die Suche nach einer Abteilung, ihren Untereinheiten und Mitarbeitern. Ein weiteres Beispiel ist ein Manager und seine Mitarbeiter, die näher beieinander gelagert sind.
In einer Tabelle können Sie einen Tiefenindex implementieren, indem Sie einen gruppierten Index für die Knoten erstellen. Außerdem führen wir eines unserer Beispiele einfach so durch.
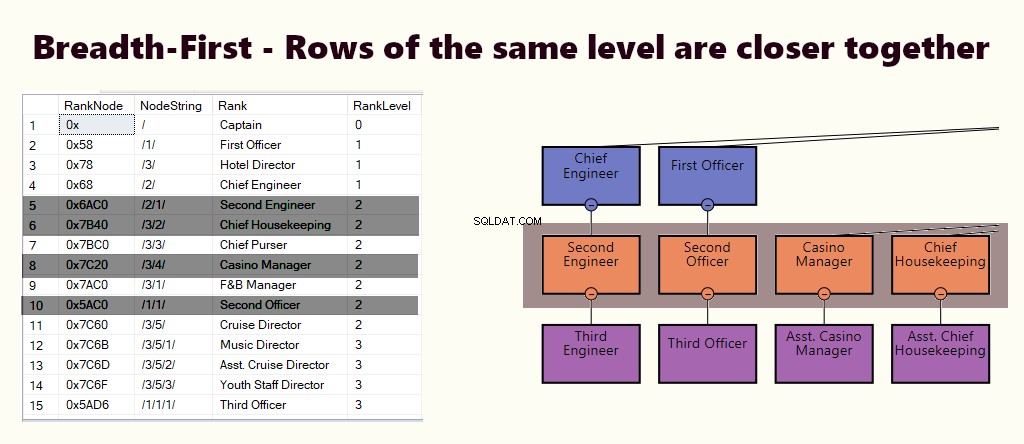
BREITE ZUERST
In einem Breitenindex liegen die Zeilen der gleichen Ebene näher beieinander. Es eignet sich für Abfragen wie die Suche nach allen direkt unterstellten Mitarbeitern des Managers. Wenn die meisten Abfragen ähnlich sind, erstellen Sie einen gruppierten Index basierend auf (1) Ebene und (2) Knoten.
Es hängt von Ihren Anforderungen ab, ob Sie einen Tiefenindex, einen Breitenindex oder beides benötigen. Sie müssen zwischen der Wichtigkeit des Abfragetyps und den DML-Anweisungen abwägen, die Sie für die Tabelle ausführen.
Einschränkungen der SQL Server-Hierarchie-ID
Leider kann die Verwendung vonhierarchieID nicht alle Probleme lösen:
- SQL Server kann nicht erraten, was das Kind eines Elternteils ist. Sie müssen den Baum in der Tabelle definieren.
- Wenn Sie keine Eindeutigkeitsbeschränkung verwenden, ist der generierte Hierarchie-ID-Wert nicht eindeutig. Die Behandlung dieses Problems liegt in der Verantwortung des Entwicklers.
- Beziehungen zwischen übergeordneten und untergeordneten Knoten werden nicht wie eine Fremdschlüsselbeziehung erzwungen. Fragen Sie daher vor dem Löschen eines Knotens nach vorhandenen Nachkommen.
Hierarchien visualisieren
Bevor wir fortfahren, bedenken Sie eine weitere Frage. Wenn Sie sich die Ergebnismenge mit Knotenzeichenfolgen ansehen, finden Sie die Visualisierung der Hierarchie schwierig für Ihre Augen?
Für mich ist es ein großes Ja, weil ich nicht jünger werde.
Aus diesem Grund werden wir Power BI und Hierarchy Chart von Akvelon zusammen mit unseren Datenbanktabellen verwenden. Sie helfen, die Hierarchie in einem Organigramm darzustellen. Ich hoffe, es wird die Arbeit erleichtern.
Kommen wir nun zur Sache.
Verwendungen von SQL Server HierarchyID
Sie können HierarchyID mit den folgenden Geschäftsszenarien verwenden:
- Organisationsstruktur
- Ordner, Unterordner und Dateien
- Aufgaben und Unteraufgaben in einem Projekt
- Seiten und Unterseiten einer Website
- Geografische Daten mit Ländern, Regionen und Städten
Auch wenn Ihr Geschäftsszenario dem obigen ähnlich ist und Sie nur selten Abfragen über die Hierarchieabschnitte hinweg durchführen, benötigen Sie hierarchyID nicht.
Beispielsweise verarbeitet Ihre Organisation Gehaltsabrechnungen für Mitarbeiter. Müssen Sie auf den Teilbaum zugreifen, um die Gehaltsabrechnung einer anderen Person zu bearbeiten? Gar nicht. Wenn Sie jedoch Provisionen von Personen in einem mehrstufigen Marketingsystem verarbeiten, kann es anders sein.
In diesem Beitrag verwenden wir den Teil der Organisationsstruktur und der Befehlskette auf einem Kreuzfahrtschiff. Die Struktur wurde von hier aus dem Organigramm übernommen. Sehen Sie sich das in Abbildung 4 unten an:

Jetzt können Sie die betreffende Hierarchie visualisieren. Wir verwenden in diesem Beitrag die folgenden Tabellen:
- Schiffe – ist der Tisch, der für die Liste der Kreuzfahrtschiffe steht.
- Ränge – ist die Tabelle der Mannschaftsränge. Dort bauen wir Hierarchien anhand derhierarchieID auf.
- Besatzung – ist die Liste der Besatzung jedes Schiffes und ihrer Ränge.
Die Tabellenstruktur ist jeweils wie folgt:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOEinfügen von Tabellendaten mit SQL Server-Hierarchie-ID
Die erste Aufgabe bei der gründlichen Verwendung von "hierarchieID" besteht darin, Datensätze mit einerhierarchieID zur Tabelle hinzuzufügen Säule. Dafür gibt es zwei Möglichkeiten.
Strings verwenden
Der schnellste Weg, Daten mit der Hierarchie-ID einzufügen, ist die Verwendung von Zeichenfolgen. Um dies in Aktion zu sehen, fügen wir den Rängen einige Datensätze hinzu Tabelle.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)Der obige Code fügt der Rangtabelle 20 Datensätze hinzu.
Wie Sie sehen können, wurde die Baumstruktur im INSERT definiert Aussage oben. Es ist leicht erkennbar, wenn wir Strings verwenden. Außerdem wandelt SQL Server sie in die entsprechenden Hexadezimalwerte um.
Mit Max(), GetAncestor() und GetDescendant()
Die Verwendung von Zeichenfolgen eignet sich für die Aufgabe, die Anfangsdaten zu füllen. Auf lange Sicht benötigen Sie den Code, um das Einfügen ohne die Bereitstellung von Zeichenfolgen zu verarbeiten.
Rufen Sie für diese Aufgabe den letzten von einem übergeordneten oder übergeordneten Knoten verwendeten Knoten ab. Wir erreichen dies, indem wir die Funktionen MAX() verwenden und GetAncestor() . Sehen Sie sich den Beispielcode unten an:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())Unten sind die Punkte aus dem obigen Code:
- Zuerst benötigen Sie eine Variable für den letzten Knoten und den unmittelbaren Vorgesetzten.
- Der letzte Knoten kann mit MAX() erfasst werden gegen RankNode für den angegebenen Elternteil oder unmittelbaren Vorgesetzten. In unserem Fall ist es der Assistant F&B Manager mit einem Knotenwert von 0x7AD6.
- Um sicherzustellen, dass kein doppeltes Kind erscheint, verwenden Sie als Nächstes @ImmediateSuperior.GetDescendant(@MaxNode, NULL) . Der Wert in @MaxNode ist das letzte Kind. Wenn es nicht NULL ist , GetDescendant() gibt den nächstmöglichen Knotenwert zurück.
- Zuletzt GetLevel() gibt die Ebene des neu erstellten Knotens zurück.
Daten abfragen
Nachdem Sie Datensätze zu unserer Tabelle hinzugefügt haben, ist es an der Zeit, sie abzufragen. Es stehen zwei Möglichkeiten zur Datenabfrage zur Verfügung:
Die Abfrage für direkte Nachkommen
Wenn wir nach Mitarbeitern suchen, die direkt dem Manager unterstellt sind, müssen wir zwei Dinge wissen:
- Der Knotenwert des Managers oder übergeordneten Knotens
- Die Ebene des Mitarbeiters unter dem Vorgesetzten
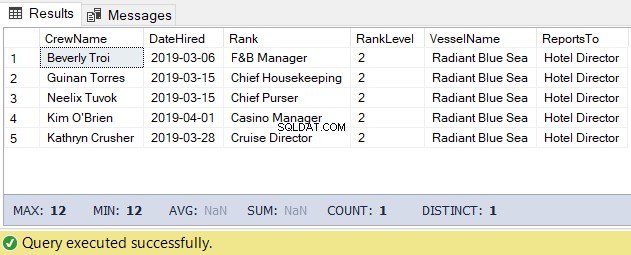
Für diese Aufgabe können wir den folgenden Code verwenden. Die Ausgabe ist die Liste der Crew unter dem Hoteldirektor.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorDas Ergebnis des obigen Codes sieht in Abbildung 5 wie folgt aus:
Suche nach Teilbäumen
Manchmal müssen Sie auch die Kinder und Kindeskinder ganz unten auflisten. Dazu benötigen Sie die Hierarchie-ID des übergeordneten Elements.
Die Abfrage ähnelt dem vorherigen Code, es muss jedoch kein Level abgerufen werden. Siehe Codebeispiel:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Das Ergebnis des obigen Codes:
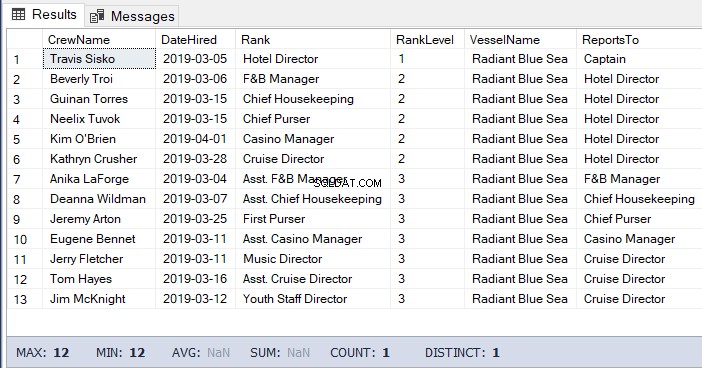
Knoten mit SQL Server-Hierarchie-ID verschieben
Eine weitere Standardoperation mit hierarchischen Daten ist das Verschieben eines untergeordneten Baums oder eines ganzen Unterbaums zu einem anderen übergeordneten Baum. Bevor wir jedoch fortfahren, beachten Sie bitte ein mögliches Problem:
Mögliches Problem
- Erstens beinhaltet das Verschieben von Knoten I/O. Wie oft Sie Knoten verschieben, kann der entscheidende Faktor sein, wenn Sie die Hierarchie-ID oder das übliche Parent/Child verwenden.
- Zweitens aktualisiert das Verschieben eines Knotens in einem übergeordneten/untergeordneten Design eine Zeile. Wenn Sie gleichzeitig einen Knoten mit der Hierarchie-ID verschieben, aktualisiert er eine oder mehrere Zeilen. Die Anzahl der betroffenen Zeilen hängt von der Tiefe der Hierarchieebene ab. Dies kann zu einem erheblichen Leistungsproblem werden.
Lösung
Sie können dieses Problem mit Ihrem Datenbankdesign lösen.
Betrachten wir das Design, das wir hier verwendet haben.
Anstatt die Hierarchie auf der Crew zu definieren Tabelle, wir haben sie in den Rängen definiert Tisch. Dieser Ansatz unterscheidet sich vom Mitarbeiter Tabelle in AdventureWorks Beispieldatenbank und bietet folgende Vorteile:
- Die Besatzungsmitglieder wechseln häufiger als die Reihen in einem Schiff. Dieses Design reduziert die Bewegungen von Knoten in der Hierarchie. Dadurch wird das oben definierte Problem minimiert.
- Definieren von mehr als einer Hierarchie in der Crew Die Tabelle ist komplizierter, da zwei Schiffe zwei Kapitäne benötigen. Das Ergebnis sind zwei Wurzelknoten.
- Wenn Sie alle Ränge mit dem entsprechenden Besatzungsmitglied anzeigen müssen, können Sie einen LEFT JOIN. verwenden Wenn für diesen Rang niemand an Bord ist, wird für die Position ein leerer Platz angezeigt.
Kommen wir nun zum Ziel dieses Abschnitts. Fügen Sie untergeordnete Knoten unter den falschen Eltern hinzu.
Um sich vorzustellen, was wir tun werden, stellen Sie sich eine Hierarchie wie die folgende vor. Beachten Sie die gelben Knoten.

Einen Knoten ohne untergeordnete Elemente verschieben
Das Verschieben eines untergeordneten Knotens erfordert Folgendes:
- Definieren Sie die Hierarchie-ID des zu verschiebenden untergeordneten Knotens.
- Definieren Sie die Hierarchie-ID des alten übergeordneten Elements.
- Definieren Sie die Hierarchie-ID des neuen übergeordneten Elements.
- Verwenden Sie AKTUALISIEREN mit GetReparentedValue() um den Knoten physisch zu verschieben.
Beginnen Sie mit dem Verschieben eines Knotens ohne Kinder. Im folgenden Beispiel verschieben wir das Cruise Staff von unter dem Cruise Director zu unter dem Asst. Kreuzfahrtdirektor.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
WHERE RankNode = @NodeToMoveSobald der Knoten aktualisiert ist, wird ein neuer Hexadezimalwert für den Knoten verwendet. Aktualisieren meiner Power BI-Verbindung zu SQL Server – dadurch wird das Hierarchiediagramm wie unten gezeigt geändert:
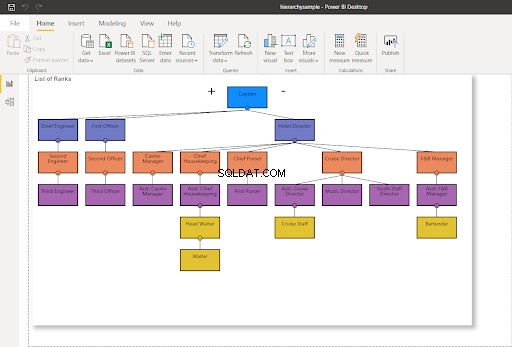
In Abbildung 8 untersteht das Cruise-Personal nicht mehr dem Cruise Director – es wurde geändert, um dem Assistant Cruise Director zu unterstehen. Vergleichen Sie es mit Abbildung 7 oben.
Lassen Sie uns nun mit der nächsten Phase fortfahren und den Oberkellner zum stellvertretenden F&B-Manager versetzen.
Verschieben Sie einen Knoten mit untergeordneten Elementen
In diesem Teil gibt es eine Herausforderung.
Die Sache ist, dass der vorherige Code nicht mit einem Knoten mit nur einem Kind funktioniert. Wir erinnern uns, dass das Verschieben eines Knotens das Aktualisieren eines oder mehrerer untergeordneter Knoten erfordert.
Außerdem endet es nicht dort. Wenn das neue übergeordnete Element ein vorhandenes untergeordnetes Element hat, stoßen wir möglicherweise auf doppelte Knotenwerte.
In diesem Beispiel müssen wir uns diesem Problem stellen:Der Asst. F&B Manager hat einen untergeordneten Barkeeper-Knoten.
Bereit? Hier ist der Code:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;Im obigen Codebeispiel beginnt die Iteration mit der Notwendigkeit, den Knoten auf der letzten Ebene an das untergeordnete Element zu übertragen.
Nachdem Sie es ausgeführt haben, werden die Ränge Tabelle wird aktualisiert. Wenn Sie die Änderungen auch visuell sehen möchten, aktualisieren Sie den Power BI-Bericht. Sie werden die Änderungen sehen, die der folgenden ähneln:
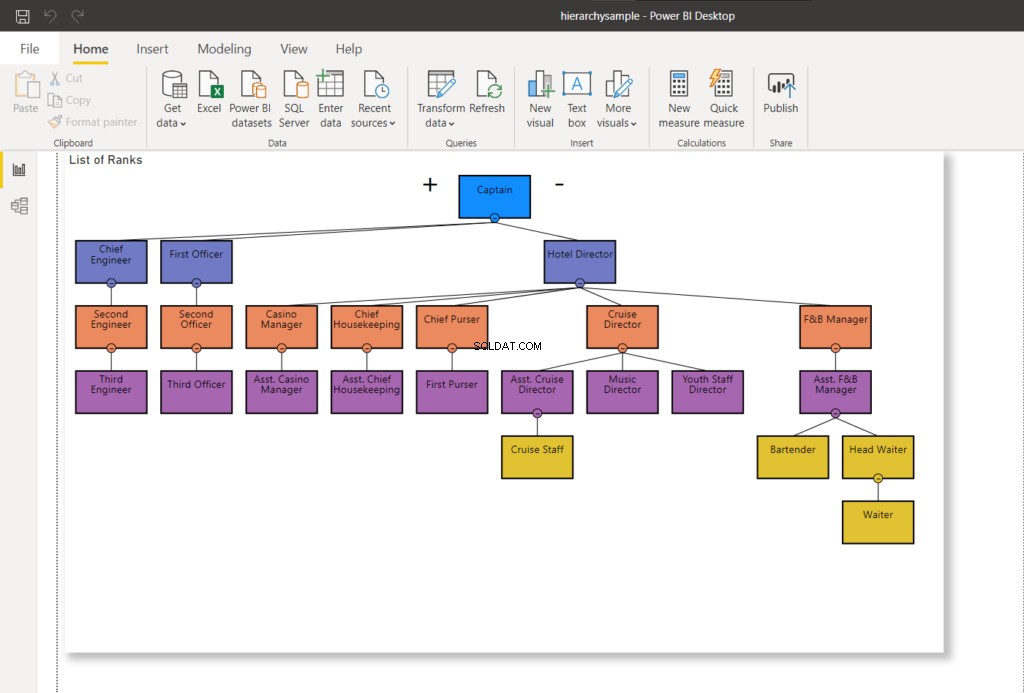
Vorteile der Verwendung von SQL Server HierarchyID gegenüber Parent/Child
Um jemanden davon zu überzeugen, eine Funktion zu verwenden, müssen wir die Vorteile kennen.
Daher werden wir in diesem Abschnitt Aussagen vergleichen, die dieselben Tabellen wie die von Anfang verwenden. Einer verwendet die Hierarchie-ID und der andere den Eltern/Kind-Ansatz. Die Ergebnismenge ist für beide Ansätze gleich. Wir erwarten es für diese Übung wie in Abbildung 6 oben.
Nun, da die Anforderungen genau sind, lassen Sie uns die Vorteile gründlich untersuchen.
Einfacher zu programmieren
Siehe folgenden Code:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Dieses Beispiel benötigt nur einenhierarchieID-Wert. Sie können den Wert beliebig ändern, ohne die Abfrage zu ändern.
Vergleichen Sie nun die Anweisung für den Parent/Child-Ansatz, der dieselbe Ergebnismenge erzeugt:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Was denkst du? Die Codebeispiele sind bis auf einen Punkt fast gleich.
Das WO -Klausel in der zweiten Abfrage kann nicht flexibel angepasst werden, wenn ein anderer Teilbaum erforderlich ist.
Machen Sie die zweite Abfrage generisch genug, und der Code wird länger. Huch!
Schnellere Ausführung
Laut Microsoft sind „Subtree-Abfragen mit der Hierarchie-ID deutlich schneller“ im Vergleich zu Parent/Child. Mal sehen, ob es stimmt.
Wir verwenden die gleichen Abfragen wie zuvor. Ein wichtiger Messwert für die Leistung sind die logischen Lesevorgänge aus dem SET STATISTICS IO . Es gibt an, wie viele 8-KB-Seiten SQL Server benötigt, um die gewünschte Ergebnismenge zu erhalten. Je höher der Wert, desto größer die Anzahl der Seiten, auf die SQL Server zugreift und die er liest, und desto langsamer wird die Abfrage ausgeführt. Führen Sie SET STATISTICS IO ON aus und führen Sie die beiden obigen Abfragen erneut aus. Der niedrigere Wert der logischen Lesevorgänge gewinnt.
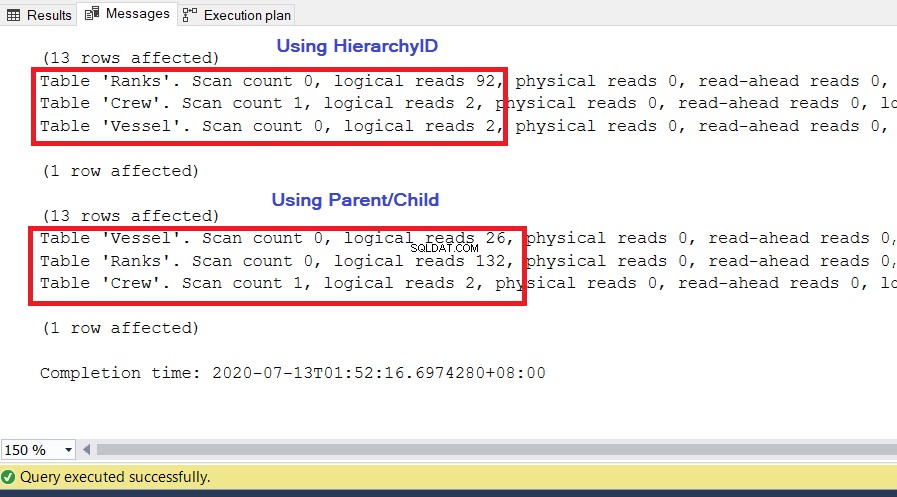
ANALYSE
Wie Sie in Abbildung 10 sehen können, weisen die E/A-Statistiken für die Abfrage mit der Hierarchie-ID weniger logische Lesevorgänge auf als ihre übergeordneten/untergeordneten Gegenstücke. Beachten Sie die folgenden Punkte in diesem Ergebnis:
- Das Schiff Tabelle ist die bemerkenswerteste der drei Tabellen. Bei Verwendung vonhierarchieID müssen nur 2 * 8 KB =16 KB Seiten von SQL Server aus dem Cache (Speicher) gelesen werden. Unterdessen erfordert die Verwendung von Parent/Child 26 * 8 KB =208 KB Seiten – deutlich mehr als die Verwendung vonhierarchieID.
- Die Ränge Tabelle, die unsere Definition von Hierarchien enthält, benötigt 92 * 8 KB =736 KB. Andererseits erfordert die Verwendung von Eltern/Kind 132 * 8 KB =1056 KB.
- Die Crew Tabelle benötigt 2 * 8KB =16KB, was für beide Ansätze gleich ist.
Kilobytes an Seiten mögen vorerst ein kleiner Wert sein, aber wir haben nur wenige Aufzeichnungen. Es gibt uns jedoch eine Vorstellung davon, wie belastend unsere Abfrage auf jedem Server sein wird. Um die Leistung zu verbessern, können Sie eine oder mehrere der folgenden Aktionen ausführen:
- Geeignete(n) Index(e) hinzufügen
- Strukturieren Sie die Abfrage neu
- Statistiken aktualisieren
Wenn Sie das oben Gesagte tun und die logischen Lesevorgänge abnehmen, ohne weitere Datensätze hinzuzufügen, würde die Leistung steigen. Solange Sie die logischen Lesevorgänge niedriger machen als für den, der die Hierarchie-ID verwendet, sind das gute Neuigkeiten.
Aber warum auf logische Lesevorgänge statt auf verstrichene Zeit verweisen?
Überprüfung der verstrichenen Zeit für beide Abfragen mit SET STATISTICS TIME ON zeigt eine kleine Anzahl von Millisekunden-Unterschieden für unseren kleinen Datensatz. Außerdem kann Ihr Entwicklungsserver eine andere Hardwarekonfiguration, SQL Server-Einstellungen und Arbeitslast aufweisen. Eine verstrichene Zeit von weniger als einer Millisekunde kann Sie täuschen, ob Ihre Abfrage so schnell wie erwartet ausgeführt wird oder nicht.
WEITER GRABEN
SET STATISTICS IO ON enthüllt nicht die Dinge, die „hinter den Kulissen“ passieren. In diesem Abschnitt finden wir heraus, warum SQL Server mit diesen Zahlen ankommt, indem wir uns den Ausführungsplan ansehen.
Beginnen wir mit dem Ausführungsplan der ersten Abfrage.
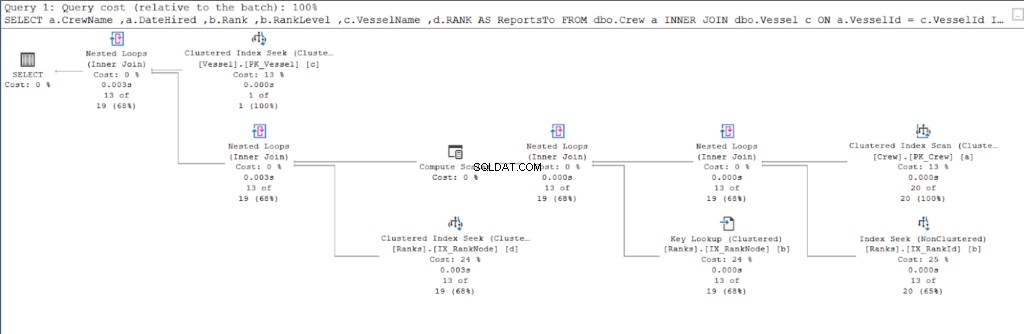
Sehen Sie sich nun den Ausführungsplan der zweiten Abfrage an.
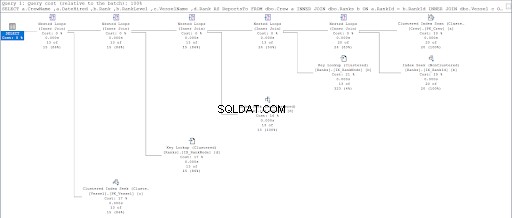
Beim Vergleich der Abbildungen 11 und 12 sehen wir, dass SQL Server zusätzlichen Aufwand erfordert, um die Ergebnismenge zu erzeugen, wenn Sie den Parent/Child-Ansatz verwenden. Das WO Klausel ist für diese Komplikation verantwortlich.
Der Fehler kann aber auch am Tischdesign liegen. Wir haben für beide Ansätze dieselbe Tabelle verwendet:die Ränge Tisch. Also habe ich versucht, die Ränge zu duplizieren Tabelle, aber verwenden Sie unterschiedliche gruppierte Indizes, die für jede Prozedur geeignet sind.
Im Ergebnis hatte die Verwendung vonhierarchieID immer noch weniger logische Lesevorgänge im Vergleich zum Eltern-/Kind-Pendant. Schließlich haben wir bewiesen, dass Microsoft Recht hatte, dies zu behaupten.
Schlussfolgerung
Hier sind die zentralen Aha-Momente für die Hierarchie-ID:
- HierarchyID ist ein integrierter Datentyp, der für eine optimiertere Darstellung von Bäumen entwickelt wurde, die der häufigste Typ hierarchischer Daten sind.
- Jedes Element im Baum ist ein Knoten, und die Werte für diehierarchieID können im Hexadezimal- oder Zeichenfolgenformat vorliegen.
- HierarchyID ist anwendbar für Daten von Organisationsstrukturen, Projektaufgaben, geografische Daten und dergleichen.
- Es gibt Methoden zum Durchlaufen und Manipulieren hierarchischer Daten, wie z. B. GetAncestor (), GetDescendant (). GetLevel (), GetReparentedValue () und mehr.
- Der herkömmliche Weg, um hierarchische Daten abzufragen, besteht darin, die direkten Nachkommen eines Knotens oder die Teilbäume unter einem Knoten abzurufen.
- Die Verwendung vonhierarchieID zum Abfragen von Teilbäumen ist nicht nur einfacher zu programmieren. Es schneidet auch besser ab als Eltern/Kind.
Das Eltern-Kind-Design ist überhaupt nicht schlecht, und dieser Beitrag soll es nicht schmälern. Die Erweiterung der Optionen und die Einführung neuer Ideen ist jedoch immer ein großer Vorteil für einen Entwickler.
Sie können die hier angebotenen Beispiele selbst ausprobieren. Erhalten Sie die Effekte und sehen Sie, wie Sie sie für Ihr nächstes Projekt mit Hierarchien anwenden können.
Wenn Ihnen der Beitrag und seine Ideen gefallen, können Sie ihn verbreiten, indem Sie auf die Teilen-Schaltflächen für die bevorzugten sozialen Medien klicken.



