In diesem Artikel werden wir über SQL Server-Prüfpunkte sprechen.
Um die Leistung zu verbessern, wendet SQL Server Änderungen an Datenbankseiten im Arbeitsspeicher an. Dieser Speicher wird häufig als Buffer-Cache oder Buffer-Pool bezeichnet. SQL Server schreibt diese Seiten nicht nach jeder Änderung auf die Festplatte. Stattdessen führt die Datenbank-Engine von Zeit zu Zeit Checkpoint-Operationen für jede Datenbank durch. Der CHECKPOINT Die Operation schreibt die Dirty Pages (aktuell im Arbeitsspeicher modifizierte Seiten) und schreibt auch Details über das Transaktionsprotokoll.
SQL Server unterstützt vier Arten von Prüfpunkten:
1. Automatisch – Diese Art von Prüfpunkten tritt hinter den Kulissen auf und hängt von den Serverkonfigurationen für das Wiederherstellungsintervall ab. Der Wert wird in Minuten gemessen und der Standardwert ist 1 Minute (kann nicht niedriger eingestellt werden). Der Prüfpunkt wird in der Zeit abgeschlossen, die die Auswirkungen auf die Leistung minimiert.
EXEC sp_configure 'recovery interval', 'seconds'
Beim SIMPLE-Wiederherstellungsmodell wird auch ein automatischer Prüfpunkt ausgelöst, wenn das Transaktionsprotokoll zu 70 % voll ist.
2. Indirekt – Diese Art von Prüfpunkten tritt auch hinter den Kulissen gemäß den benutzerdefinierten Einstellungen für die Wiederherstellungszeit der Datenbank auf. Ab SQL Server 2016 CTP2 beträgt der Standardwert für diesen Prüfpunkttyp 1 Minute. Dies bedeutet, dass eine Datenbank indirekte Prüfpunkte verwendet. Für ältere SQL Server-Versionen ist der Standardwert 0. Dies bedeutet, dass eine Datenbank automatische Prüfpunkte verwendet, deren Häufigkeit von der Einstellung des Wiederherstellungsintervalls der SQL Server-Instanz abhängt. Microsoft empfiehlt für die meisten Systeme 1 Minute.
ALTER DATABASE … SET TARGET_RECOVERY_TIME =
target_recovery_time { SECONDS | MINUTES }
Berücksichtigen Sie bei der Einstellung die Fähigkeiten des zugrunde liegenden I/O-Subsystems. Für schnellere E/A-Subsysteme (z. B. SSDs) kann es sinnvoll sein, diese niedriger einzustellen. Seien Sie vorsichtig, diese Einstellung bleibt während der Sicherung und Wiederherstellung erhalten, sodass die Wiederherstellung auf langsamerer Hardware zu Leistungsproblemen führen kann, da zu viel E/A-Last verursacht wird.
3. Manuell – Tritt beim Ausführen des T-SQL CHECKPOINT-Befehls auf.
CHECKPOINT [ checkpoint_duration ]
checkpoint_duration ist eine ganze Zahl, die verwendet wird, um die Zeitspanne zu definieren, in der ein Checkpoint abgeschlossen werden soll. Dieser Parameter bestimmt auch, wie viele Ressourcen der Checkpoint-Operation zugewiesen werden. Wenn der Parameter nicht angegeben wird, wird der Prüfpunkt in der Zeit abgeschlossen, die die Auswirkungen auf die Leistung minimiert.
4. Intern — Einige SQL Server-Vorgänge geben diese Art von Prüfpunkten aus, um sicherzustellen, dass Datenträgerabbilder mit dem aktuellen Status des Transaktionsprotokolls übereinstimmen. Dies sind Prüfpunkte, die ausgeführt werden, wenn eine bestimmte Operation stattfindet:
- Eine Datendatei wird hinzugefügt oder entfernt
- Die Datenbank wird heruntergefahren (aus welchen Gründen auch immer)
- Eine Sicherung oder ein Datenbank-Snapshot wird erstellt
- Ein DBCC-Befehl wird ausgeführt, der einen versteckten Datenbank-Snapshot erstellt (oder z. B. DBCC_CHECKDB, DBCC_CHECKTABLE).
Warum sind Checkpoints nützlich?
Checkpoints verkürzen die Wiederherstellungszeit nach einem Absturz. Dies liegt daran, dass Datendateiseiten nicht gleichzeitig mit den Protokolldatensätzen auf die Festplatte geschrieben werden. Es gibt Datendateiseiten im Arbeitsspeicher, die aktueller sind als Datendateiseiten auf der Festplatte.
Checkpoints reduzieren die E/A auf die Festplatte und verbessern die Leistung. Der Grund dafür, dass Datendateiseiten zum Zeitpunkt der Transaktionsfestschreibung nicht auf die Festplatte geschrieben werden, besteht darin, die Anzahl der E/A-Operationen zu reduzieren. Stellen Sie sich die mehreren tausend UPDATE-Transaktionen auf einer einzigen Datenseite vor. Es ist effizienter, eine Datenseite nur einmal während eines Prüfpunkts auf die Festplatte zu schreiben, als nach jeder Änderung.
Saubere und schmutzige Seiten
Der Pufferpool verwaltet eine Reihe von Datenseiten im Speicher. Es gibt zwei Arten von Datenseiten:sauber und schmutzig . Eine saubere Seite ist eine Seite, die seit dem letzten Lesen von der Festplatte oder dem letzten Schreiben auf die Festplatte nicht geändert wurde. Eine Dirty Page ist eine Seite, die geändert wurde und die Änderungen nicht auf die Festplatte geschrieben wurden. Checkpoints beziehen sich auf „schmutzige Seiten“.
Die Informationen über die Seite können mit sys.dm_os_buffer_descriptors eingesehen werden . Mal sehen, was diese Funktion zurückgibt:
SELECT * FROM sys.dm_os_buffer_descriptors dobd; GO
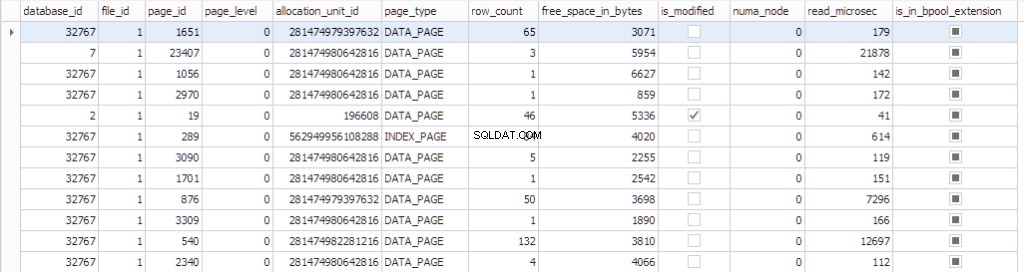
Jeder Seite ist eine Kontrollstruktur zugeordnet, die den Seitenstatus verfolgt:
- Eine Datenbank mit der datdabase_id 32767 ist eine schreibgeschützte Ressourcendatenbank, die alle Systemobjekte enthält.
- Datei-ID , page_id , allocation_unit_id zu der diese Seite gehört.
- Um welche Art von Seite es sich handelt:entweder Datenseite oder Indexseite.
- Die Anzahl der Zeilen auf der Seite.
- Der freie Platz auf der Seite
- Ob die Seite schmutzig ist oder nicht
- Der numa_node, zu dem die bestimmte Seite gehört
- Einige Informationen zum Last-Recently-Used-Algorithmus
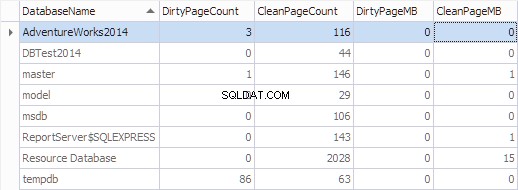
Lassen Sie uns diese Informationen mithilfe des folgenden Codes nach Datenbank aggregieren:
SELECT
*,
[DirtyPageCount] * 8 / 1024 AS [DirtyPageMB],
[CleanPageCount] * 8 / 1024 AS [CleanPageMB]
FROM (SELECT
(CASE
WHEN ([database_id] = 32767) THEN N'Resource Database'
ELSE DB_NAME([database_id])
END) AS [DatabaseName],
SUM(CASE
WHEN ([is_modified] = 1) THEN 1
ELSE 0
END) AS [DirtyPageCount],
SUM(CASE
WHEN ([is_modified] = 1) THEN 0
ELSE 1
END) AS [CleanPageCount]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]) AS [buffers]
ORDER BY [DatabaseName]
GO
Checkpoint-Mechanismus
Wenn der Prüfpunkt auftritt, werden alle Dirty Pages auf die Festplatte geschrieben. Seiten, die als schmutzig markiert sind, sobald sie einige Änderungen aufweisen. Es spielt keine Rolle, ob die Transaktion, die die Änderung vorgenommen hat, zum Zeitpunkt des Checkpoints festgeschrieben oder nicht festgeschrieben ist. Nachdem die Seiten auf die Festplatte geschrieben wurden, wird das „Dirty“-Bit gelöscht. Wenn der Prüfpunkt eintritt, finden die folgenden Aktionen statt:
- Ein neuer Protokolleintrag weist auf den Beginn eines Kontrollpunkts hin
- Zusätzliche Protokolldatensätze erscheinen mit Checkpoint-Informationen (wie dem Status des Transaktionsprotokolls zum Zeitpunkt des Starts des Checkpoints)
- Alle schmutzigen Seiten werden auf die Festplatte geschrieben
- Markieren Sie die LSN des Checkpoints in der Datenbank-Startseite (in der dbi_checkptLSN), dies ist entscheidend für die Wiederherstellung nach einem Absturz
- Wenn das SIMPLE-Wiederherstellungsmodell verwendet wird, versuchen Sie, das Protokoll zu löschen
- Ein abschließender Protokolleintrag zeigt an, dass der Prüfpunkt abgeschlossen ist
Es ist möglich, dass Checkpoints mehrerer Datenbanken parallel auftreten. Der SQL Server 2000 war auf jeweils einen Prüfpunkt beschränkt. Wenn der Puffermanager eine Seite schreibt, sucht er nach benachbarten schmutzigen Seiten, die in einer einzigen Sammel-Schreib-Operation enthalten sein können. Außerdem versucht der Pufferpool sicherzustellen, dass das I/O-Subsystem nicht überlastet wird. Es verfolgt, wie lange es dauert, bis die E/A abgeschlossen ist. Wenn die Schreiblatenz während des Checkpoints 20 ms überschreitet, drosselt es sich selbst. Während des Herunterfahrens steigt die Throttling-Schwelle auf 100 ms an. Eine genauere Erklärung finden Sie hier. Sie können die undokumentierte Startoption „-kXX“ verwenden, um die Prüfpunkt-E/A-Rate auf XX MB/s einzustellen.
Wenn die Datendateiseite von einem Prüfpunkt auf die Festplatte geschrieben wird, garantiert die Write-Ahead-Protokollierung, dass alle Protokolldatensätze, die diese Seite betreffen, zuerst in das Transaktionsprotokoll auf der Festplatte geschrieben werden müssen. Alle Protokolleinträge bis einschließlich des letzten, der die Seite betraf, werden ausgeschrieben, unabhängig davon, zu welcher Transaktion sie gehören. Protokolldatensätze werden auf drei Arten ausgeschrieben:
- Wenn eine Transaktion festgeschrieben oder abgebrochen wird
- Wenn die Seite der Datendatei auf die Festplatte geschrieben wird
- Wenn ein Protokollblock die maximale Größe von 60 KB erreicht und zwangsweise beendet wird
Checkpoint-Protokollaufzeichnung
Prüfpunkte schreiben mehrere Protokolldatensätze in das Transaktionsprotokoll:
- LOP_BEGIN_CKPT — zeigt an, dass der Prüfpunkt gestartet wurde
- LOP_XACT_CKPT mit NULL-Kontext (nur wenn zum Zeitpunkt des Starts des Prüfpunkts nicht festgeschriebene Transaktionen vorhanden sind) – enthält eine Anzahl der nicht festgeschriebenen Transaktionen. Es listet auch die LSNs der LOP_BEGIN_XACT-Protokolldatensätze der nicht festgeschriebenen Transaktionen auf.
- LOP_BEGIN_CKPT mit einem Kontext von LOP_BOOT_PAGE_CKPT (nur SQL Server 2012) – bedeutet, dass die Startseite aktualisiert wurde.
- LOP_END_CKPT — bedeutet das Ende des Checkpoints.
Checkpoint-Überwachung
Es kann nützlich sein, Prüfpunkte zu korrelieren, die mit I/O-Spitzen auftreten, damit Änderungen an der spezifischen Datenbank (für das I/O-Subsystem) vorgenommen werden können, um die I/O-Spitze zu verringern, wenn sie das I/O-Subsystem überlastet. Führen Sie beispielsweise häufigere manuelle Prüfpunkte durch oder konfigurieren Sie ein kürzeres Wiederherstellungsintervall auf SQL Server 2012 mit indirekten Prüfpunkten. Dadurch wird eine konstantere E/A-Last ohne hohe Spitzen erzeugt, die das E/A-Subsystem überlasten. Die Hauptursache kann jedoch darin bestehen, dass aufgrund einer Änderung irgendwo mehr E/A-Vorgänge ausgeführt werden. Akzeptieren Sie also nicht einfach einen plötzlichen Anstieg der Checkpoint-Aktivität, ohne zu untersuchen, warum dies aufgetreten ist.
Der Seiten-/Sek.-Zähler von Buffer Manager/Checkpoint ist nicht datenbankspezifisch, daher sind Ablaufverfolgungsflags oder erweiterte Ereignisse erforderlich, um zu ermitteln, welche Datenbank beteiligt ist.
Trace-Flag 3502 schreibt Meldungen in das Fehlerprotokoll darüber, für welchen Datenbank-Checkpoint aufgetreten ist.
Trace-Flag 3504 schreibt detailliertere Informationen darüber, wie viele Seiten ausgeschrieben wurden und die durchschnittliche Schreiblatenz.
Diese Trace Flags können für eine begrenzte Zeit sicher in der Produktion verwendet werden. Sie drucken lediglich Meldungen in das Fehlerprotokoll.
Wenn Sie erweiterte Ereignisse verwenden möchten, können Sie zwei Ereignisse verwenden:checkpoint_begin und checkpoint_end.
Zusammenfassung
In diesem Artikel haben wir über Prüfpunkte in SQL Server gesprochen – den Hauptmechanismus zum Schreiben von Datendateiseiten auf die Festplatte, nachdem sie geändert wurden.