Hohe Verfügbarkeit ist eine Voraussetzung für viele Systeme, egal welche Technologie Sie verwenden. Dies ist besonders wichtig für Datenbanken, da sie Daten speichern, auf die sich Anwendungen verlassen. Abhängig von den Anforderungen gibt es verschiedene Möglichkeiten, eine Hochverfügbarkeitsumgebung für PostgreSQL bereitzustellen, aber es ist immer notwendig, ein ergänzendes Tool zu verwenden, da die nativen PostgreSQL-Funktionen nicht ausreichen.
In diesem Blog werden wir sehen, wie Percona Distribution für PostgreSQL für Hochverfügbarkeit bereitgestellt wird und welche Tools dafür erforderlich sind.
Percona-Distribution für PostgreSQL
Es ist eine Sammlung von Tools, die Sie bei der Verwaltung Ihres PostgreSQL-Datenbanksystems unterstützen. Es installiert PostgreSQL und ergänzt es durch eine Auswahl an Erweiterungen, die es ermöglichen, wesentliche praktische Aufgaben effizient zu lösen, darunter:
- pg_repack :Es baut PostgreSQL-Datenbankobjekte neu auf.
- pgaudit :Es bietet eine detaillierte Sitzungs- oder Objekt-Audit-Protokollierung über die standardmäßige PostgreSQL-Protokollierungsfunktion.
- pgBackRest :Es ist eine Sicherungs- und Wiederherstellungslösung für PostgreSQL.
- Patroni :Es ist eine Hochverfügbarkeitslösung für PostgreSQL.
- pg_stat_monitor :Es sammelt und aggregiert Statistiken für PostgreSQL und stellt Histogramminformationen bereit.
- Eine Sammlung zusätzlicher PostgreSQL Contrib-Erweiterungen.
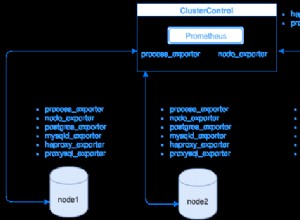
Hochverfügbarkeit auf PostgreSQL
Es gibt verschiedene Architekturen für PostgreSQL-Hochverfügbarkeit, aber die gebräuchlichste ist eine Master-Slave-Topologie (Primary-Standby). Es basiert auf einer primären Datenbank mit einem oder mehreren Standby-Knoten. Diese Standby-Datenbanken bleiben mit der Primärdatenbank synchronisiert (oder nahezu synchronisiert), je nachdem, ob die Replikation synchron oder asynchron ist. Wenn der Hauptserver ausfällt, enthält der Standby fast alle Daten des Hauptservers und kann schnell zum neuen primären Datenbankserver werden.
Aber ein Master-Slave-Setup reicht nicht aus, um eine hohe Verfügbarkeit effektiv zu gewährleisten, da Sie auch mit Ausfällen umgehen müssen. Sobald ein Fehler erkannt wird, sollten Sie in der Lage sein, einen Standby-Knoten auszuwählen und mit möglichst geringer Verzögerung auf ihn umzuschalten. PostgreSQL selbst enthält keinen automatischen Failover-Mechanismus, sodass für diese Automatisierung einige benutzerdefinierte Skripte oder Tools von Drittanbietern erforderlich sind.
Nach einem Failover müssen die Anwendung(en) entsprechend benachrichtigt werden, damit sie mit der Verwendung des neuen primären Knotens beginnen können. Außerdem müssen Sie den Zustand unserer Architektur nach einem Failover bewerten, da Sie in einer Situation laufen können, in der nur der neue primäre Knoten ausgeführt wird (d. h. Sie hatten vor dem Problem einen primären und nur einen Standby-Knoten). In diesem Fall müssen Sie irgendwie einen neuen Standby-Knoten hinzufügen, um das Master-Slave-Setup wiederherzustellen, das Sie ursprünglich für Hochverfügbarkeit hatten.
Damit es funktioniert, benötigen Sie verschiedene Tools/Dienste, die Ihnen bei dieser Aufgabe helfen.
Load Balancer
Load-Balancer sind Tools, mit denen Sie den Datenverkehr Ihrer Anwendung verwalten können, um Ihre Datenbankarchitektur optimal zu nutzen.
Es ist nicht nur nützlich, um die Last unserer Datenbanken auszugleichen, es hilft auch dabei, Anwendungen auf die verfügbaren/fehlerfreien Knoten umzuleiten und sogar Ports mit unterschiedlichen Rollen anzugeben.
HAProxy ist ein Load Balancer, der den Datenverkehr von einem Ursprung zu einem oder mehreren Zielen verteilt und für diese Aufgabe spezifische Regeln und/oder Protokolle definieren kann. Wenn eines der Ziele nicht mehr reagiert, wird es als offline markiert und der Datenverkehr wird an die restlichen verfügbaren Ziele gesendet.
Keepalived ist ein Dienst, mit dem Sie eine virtuelle IP innerhalb einer Aktiv/Passiv-Gruppe von Servern konfigurieren können. Diese virtuelle IP wird einem aktiven Server zugewiesen. Wenn dieser Server ausfällt, wird die IP automatisch auf den „sekundären“ passiven Server migriert, sodass dieser auf transparente Weise für die Systeme mit derselben IP weiterarbeiten kann.
Um all diese Dinge zu implementieren, können Sie es manuell tun, was zusätzliche Arbeit und zeitraubende Aufgaben bedeutet, oder Sie können es von nur einem System aus mit ClusterControl erledigen.
Lassen Sie uns sehen, wie Sie Ihre vorhandene Percona-Distribution für PostgreSQL in ClusterControl importieren und dann eine Hochverfügbarkeitsumgebung mit HAProxy und Keepalived um dieses Setup herum von einer benutzerfreundlichen und einfach zu bedienenden Oberfläche aus konfigurieren.
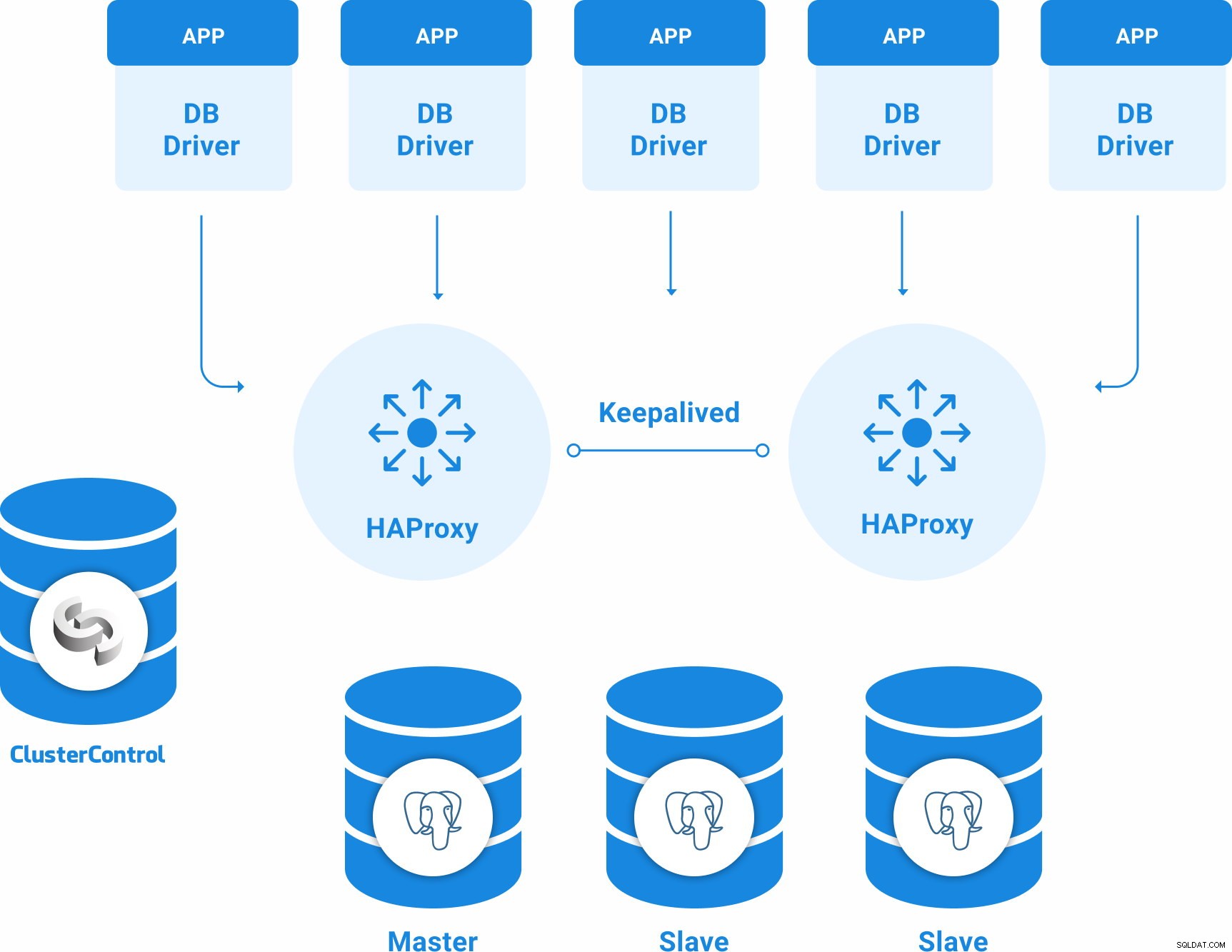
PostgreSQL-Topologie für Hochverfügbarkeit
Eine grundlegende Hochverfügbarkeitstopologie für PostgreSQL kann sein:
- 3 PostgreSQL 12-Server (ein primärer und zwei Standby-Knoten).
- 2 HAProxy Load Balancer.
- Keepalived bleibt zwischen den Load-Balancer-Servern konfiguriert.
- 1 ClusterControl-Server
Also haben Sie die folgende Topologie:
So installieren Sie die Percona-Distribution für PostgreSQL
Beginnen wir mit der Installation von Percona Distribution für PostgreSQL. Für dieses Beispiel verwenden wir CentOS 7 und PostgreSQL 12.
Wenn Sie Ihren Cluster installiert haben, fahren Sie mit dem nächsten Abschnitt fort, um Ihre vorhandene Datenbank in ClusterControl zu importieren.
Installieren Sie epel-release und percona-release
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmAktivieren Sie das PostgreSQL 12-Repository
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!Installieren Sie das Serverpaket
$ yum install percona-postgresql12-serverBeachten Sie, dass dieses Paket nicht alle Komponenten der Percona-Distribution installiert. Um diese Komponenten zu installieren, verwenden Sie die entsprechenden optionalen Pakete wie unten gezeigt:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribDatenbank initialisieren
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKStellen Sie sicher, dass Sie die richtige Konfiguration haben, um eine PostgreSQL-Replikation konfigurieren zu können, ähnlich wie:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onStarten Sie dann den Datenbankdienst
$ systemctl start postgresql-12Wenn Sie nun Standby-Knoten hinzufügen möchten, wiederholen Sie die Schritte 1, 2 und 3 in allen Knoten, die Sie dem Cluster hinzufügen möchten. Für diese Knoten müssen Sie nichts weiter konfigurieren, da ClusterControl die entsprechende Konfiguration erstellt.
Percona-Distribution für PostgreSQL in ClusterControl importieren
Mit ClusterControl können Sie verschiedene Open-Source-Datenbank-Engines aus demselben System bereitstellen oder importieren, und es ist nur ein SSH-Zugriff und ein privilegierter Benutzer erforderlich, um es zu verwenden.
Gehen Sie zum Abschnitt „Importieren“ und vervollständigen Sie die erforderlichen Informationen Ihres PostgreSQL-Servers.
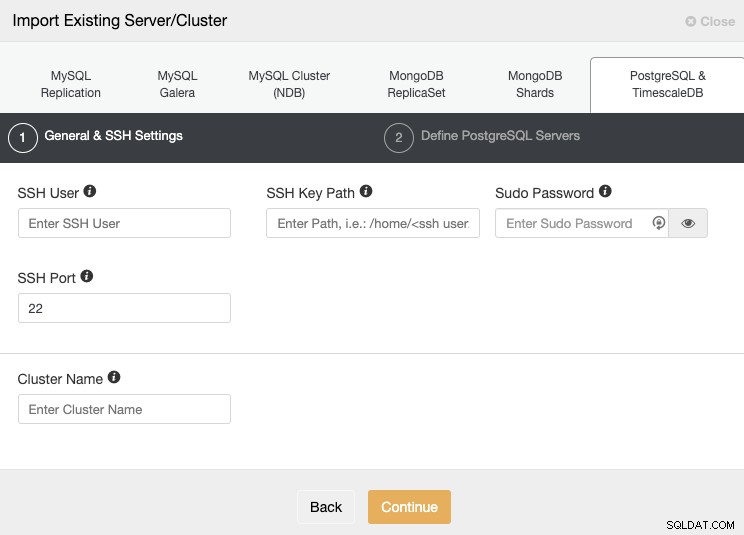
Sie müssen Benutzer, Schlüssel oder Passwort und Port angeben, um eine Verbindung über SSH herzustellen zu Ihren Servern. Außerdem benötigen Sie einen Namen für Ihren neuen Cluster, andernfalls wird ClusterControl Ihnen einen generischen zuweisen.
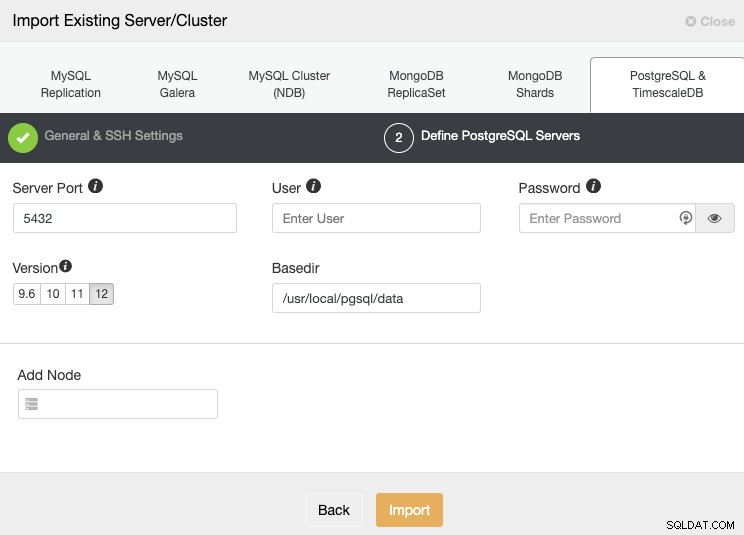
Nachdem Sie die SSH-Zugriffsinformationen eingerichtet haben, müssen Sie die Datenbankanmeldeinformationen definieren, version, basedir und die IP-Adresse oder den Hostnamen für jeden Datenbankknoten.
Wenn Sie die Replikation noch nicht konfiguriert haben, müssen Sie nur die IP-Adresse oder den Hostnamen für den primären Knoten hinzufügen, da wir Ihnen später zeigen werden, wie Sie die restlichen Knoten hinzufügen.
Stellen Sie sicher, dass Sie bei der Eingabe des Hostnamens oder der IP-Adresse das grüne Häkchen sehen, das anzeigt, dass ClusterControl mit dem Knoten kommunizieren kann. Klicken Sie dann auf die Schaltfläche Importieren und warten Sie, bis ClusterControl seine Arbeit beendet hat. Sie können den Prozess im ClusterControl-Aktivitätsabschnitt überwachen. Wenn es fertig ist, sehen Sie das neue Cluster auf dem Hauptbildschirm von ClusterControl. Um ein neues Replikat hinzuzufügen, gehen Sie zu den Cluster-Aktionen und wählen Sie die Option „Replikations-Slave hinzufügen“.
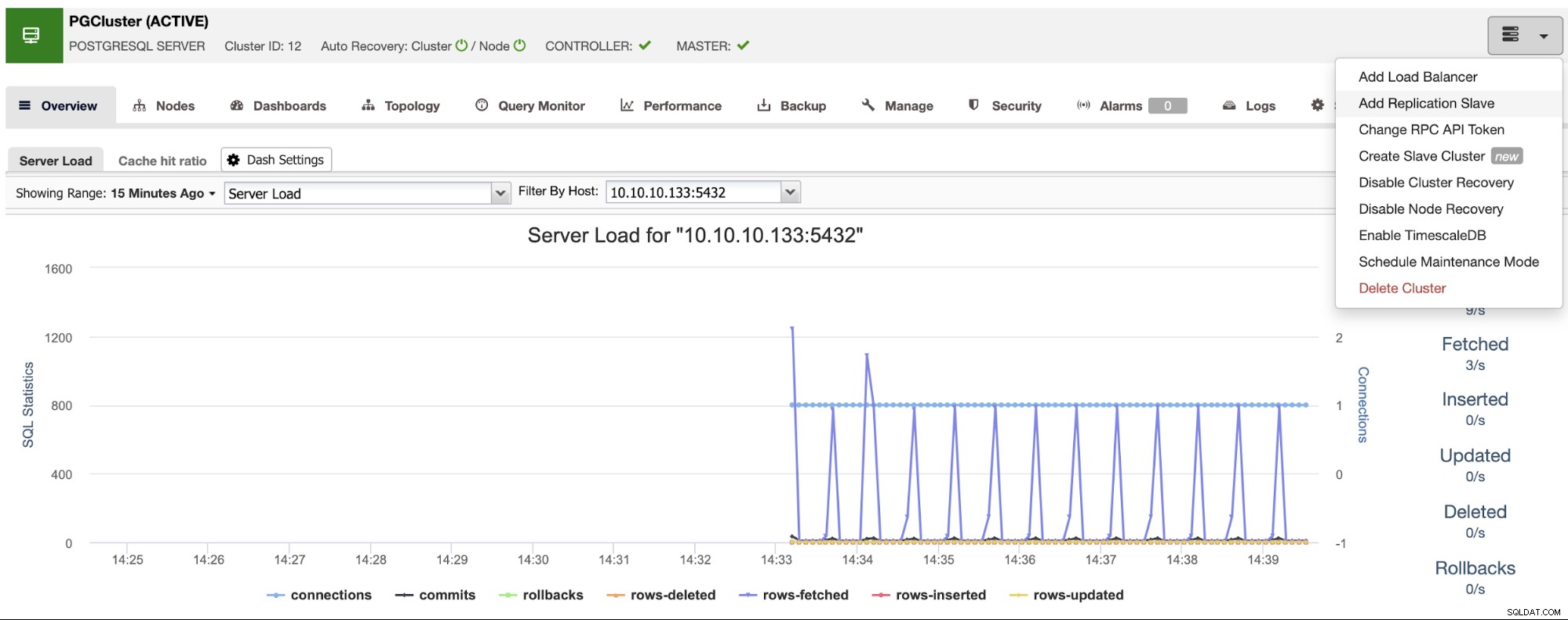
Wenn Sie die vorherigen Schritte befolgt haben, haben Sie Percona Distribution für PostgreSQL installiert in allen Standby-Knoten, daher müssen Sie die „PostgreSQL-Software installieren“ in diesem Abschnitt deaktivieren.
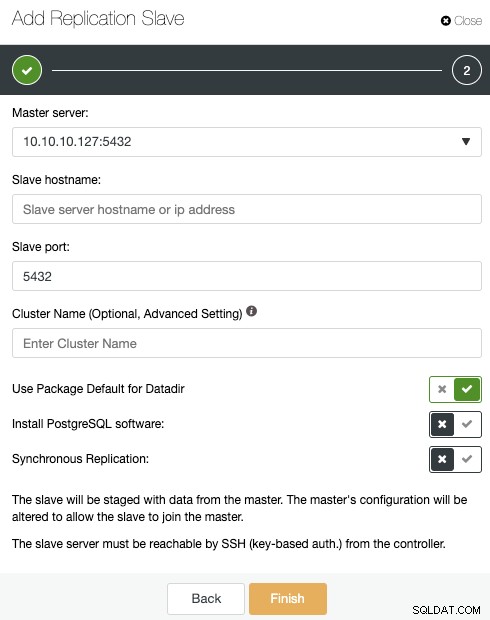
Auf diese Weise verwendet ClusterControl stattdessen die installierte Percona-Distribution für PostgreSQL-Pakete der Installation der offiziellen PostgreSQL-Pakete.
Wenn Sie damit fertig sind, sehen Sie alle Knoten im Cluster und deren Status im Übersichtsabschnitt.
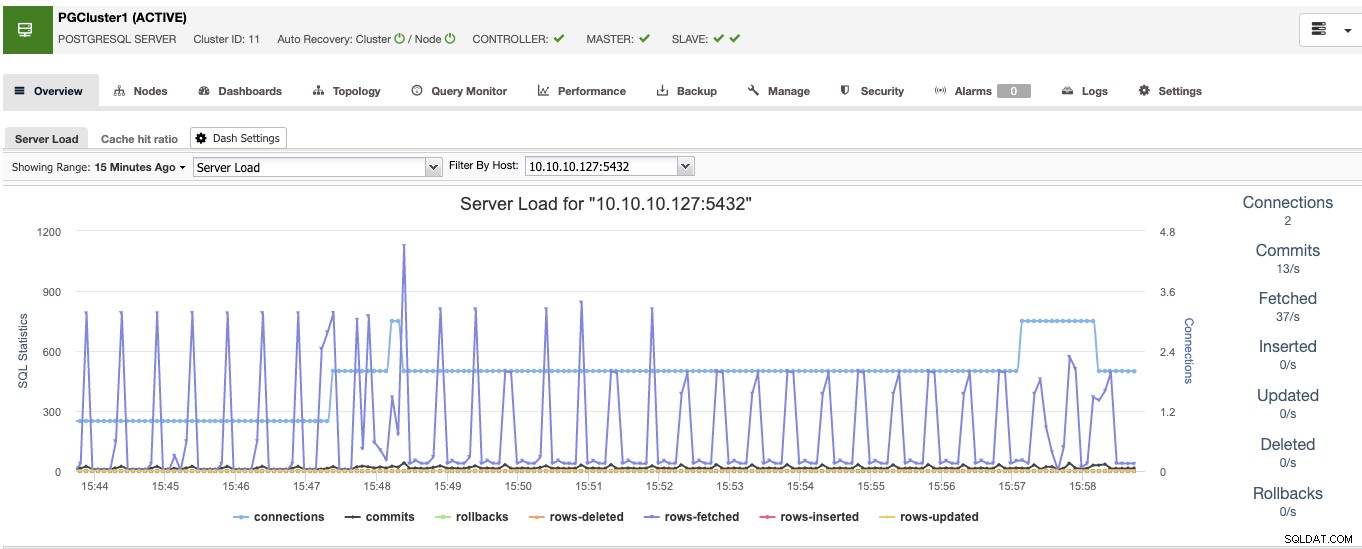
Jetzt haben Sie die Datenbankseite fertig, sehen wir uns an, wie man das High vervollständigt Verfügbarkeitsumgebung durch Hinzufügen der restlichen Tools mit ClusterControl.
Load-Balancer-Bereitstellung
Um eine Load-Balancer-Bereitstellung durchzuführen, wählen Sie die Option „Load-Balancer hinzufügen“ in den Cluster-Aktionen und füllen Sie die angeforderten Informationen aus. 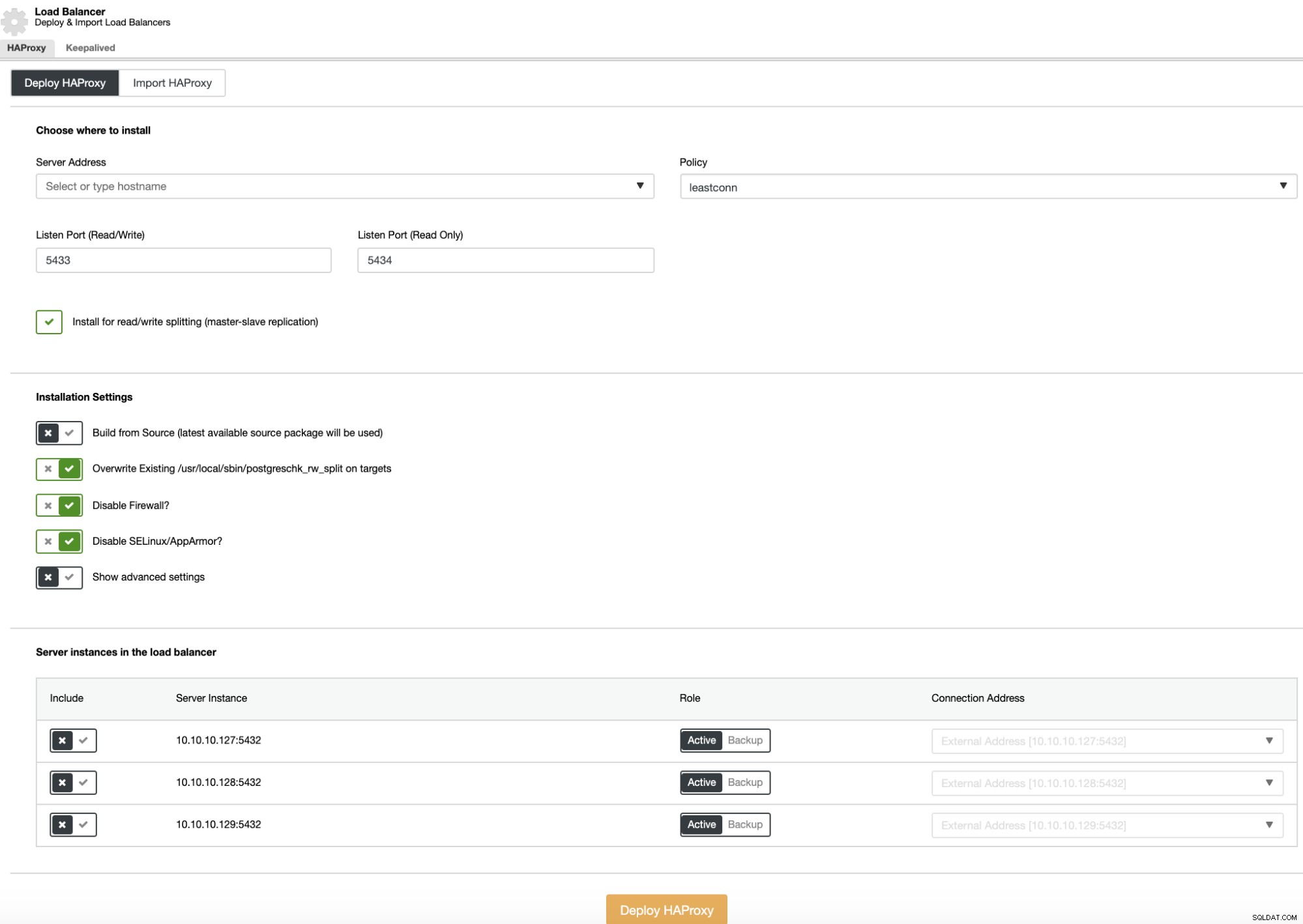
Sie müssen nur die IP-Adresse oder den Hostnamen, den Port, die Richtlinie und die Knoten hinzufügen, die Sie der Load-Balancer-Konfiguration hinzufügen werden.
Keepalived-Bereitstellung
Um eine Keepalived-Bereitstellung durchzuführen, wählen Sie den Cluster aus, gehen Sie zu Cluster-Aktionen, wählen Sie „Load Balancer hinzufügen“ und gehen Sie dann zum Abschnitt „Keepalived“.
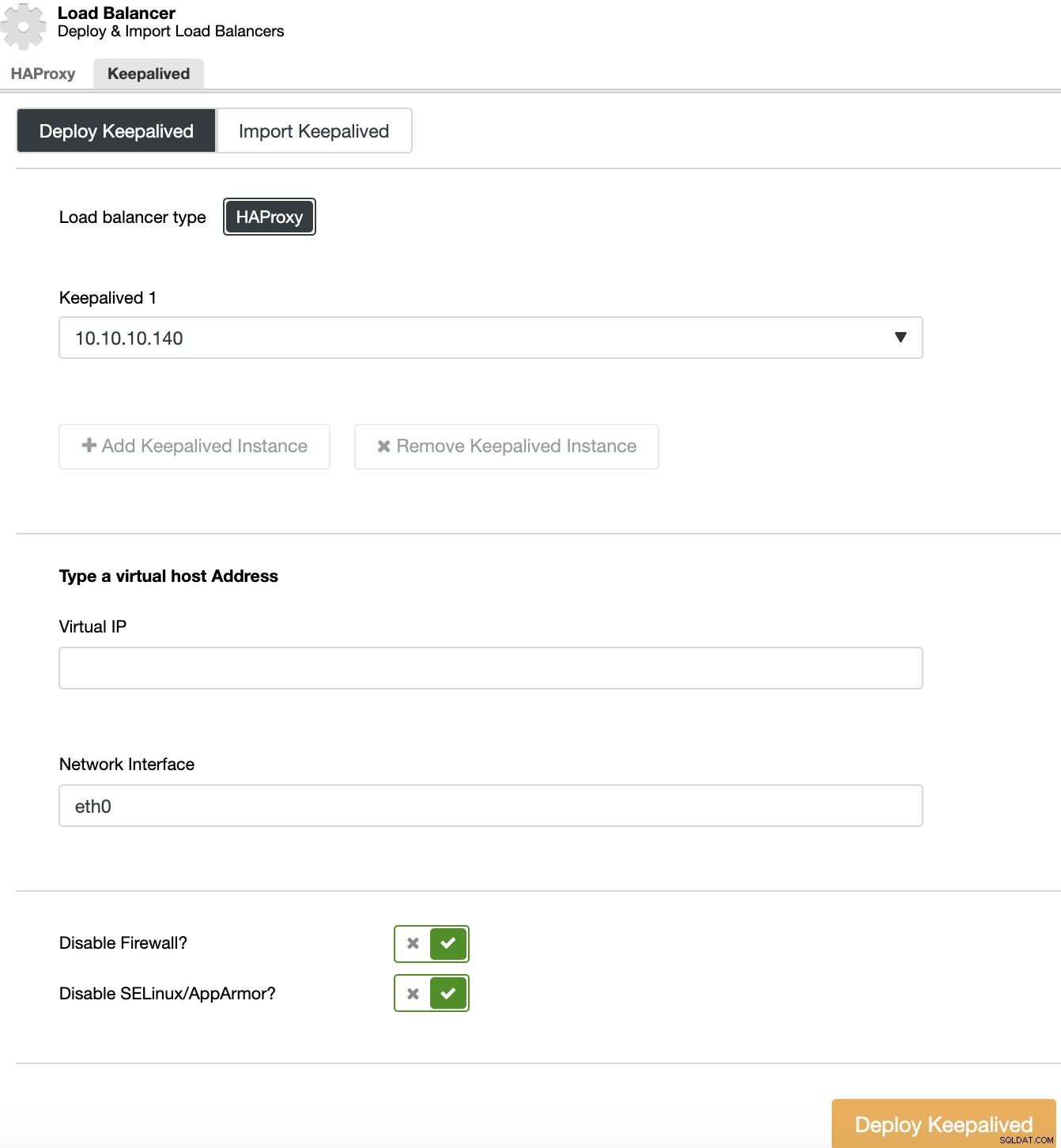
Für Ihre Hochverfügbarkeitsumgebung müssen Sie die Load Balancer-Server und die virtuelle IP-Adresse auswählen, die Sie für den Zugriff auf Ihren Cluster verwenden müssen. Keepalived konfiguriert diese virtuelle IP im aktiven Load Balancer und migriert sie im Falle eines Ausfalls von einem Load Balancer zu einem anderen, sodass Ihr Setup weiterhin normal funktionieren kann.
Fazit
Da Sie Percona Distribution for PostgreSQL noch nicht direkt von ClusterControl aus bereitstellen können, haben wir Ihnen in diesem Blog gezeigt, wie Sie es mit ClusterControl verwalten und verschiedene Tools wie HAProxy und Keepalived hinzufügen können, um eine Hochverfügbarkeitsumgebung einzurichten auf einfache Weise.