Die Tabellenindizierungsstrategie ist einer der wichtigsten Schlüssel zur Leistungsoptimierung und -optimierung. In SQL Server werden die Indizes (sowohl geclusterte als auch nicht geclusterte) mithilfe einer B-Baumstruktur erstellt, in der jede Seite als doppelt verknüpfter Listenknoten fungiert und Informationen über die vorherige und die nächste Seite enthält. Diese als Forward Scan bezeichnete B-Baumstruktur erleichtert das Lesen der Zeilen aus dem Index, indem die Seiten von Anfang bis Ende gescannt oder durchsucht werden. Obwohl der Vorwärtsscan die standardmäßige und bekannte Methode zum Scannen von Indizes ist, bietet uns SQL Server die Möglichkeit, die Indexzeilen innerhalb der B-Baumstruktur vom Ende bis zum Anfang zu scannen. Diese Fähigkeit wird als Rückwärtsscan bezeichnet. In diesem Artikel werden wir sehen, wie dies geschieht und welche Vor- und Nachteile die Methode des Rückwärtsscannens hat.
SQL Server bietet uns die Möglichkeit, Daten aus dem Tabellenindex zu lesen, indem die Index-B-Baumstruktur-Knoten von Anfang bis Ende mit der Forward-Scan-Methode gescannt werden oder die B-Baumstruktur-Knoten von Ende bis Anfang mit der Rückwärts-Scan-Methode. Wie der Name schon sagt, wird der Rückwärtsscan beim Lesen entgegengesetzt zur Reihenfolge der im Index enthaltenen Spalte durchgeführt, was mit der Option DESC in der T-SQL-Sortieranweisung ORDER BY ausgeführt wird, die die Richtung des Scanvorgangs angibt.
In bestimmten Situationen stellt SQL Server Engine fest, dass das Lesen der Indexdaten vom Ende bis zum Anfang mit der Rückwärts-Scanmethode schneller ist als das Lesen in ihrer normalen Reihenfolge mit der Vorwärts-Scanmethode, die einen teuren Sortierprozess durch SQL erfordern kann Motor. Zu diesen Fällen gehören die Verwendung der Aggregatfunktion MAX() und Situationen, in denen die Sortierung des Abfrageergebnisses der Indexreihenfolge entgegengesetzt ist. Der Hauptnachteil der Backward-Scan-Methode besteht darin, dass der SQL Server-Abfrageoptimierer sich immer dafür entscheidet, sie mit serieller Planausführung auszuführen, ohne in der Lage zu sein, die Vorteile der parallelen Ausführungspläne zu nutzen.
Angenommen, wir haben die folgende Tabelle, die Informationen über die Mitarbeiter des Unternehmens enthält. Die Tabelle kann mit der folgenden T-SQL-Anweisung CREATE TABLE erstellt werden:
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
Nachdem wir die Tabelle erstellt haben, werden wir sie mit 10.000 Dummy-Datensätzen füllen, indem wir die folgende INSERT-Anweisung verwenden:
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 Wenn wir die folgende SELECT-Anweisung ausführen, um Daten aus der zuvor erstellten Tabelle abzurufen, werden die Zeilen nach den Werten der ID-Spalte in aufsteigender Reihenfolge sortiert, das entspricht der Reihenfolge des Clustered-Index:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
Anschließend wird der Ausführungsplan für diese Abfrage überprüft und der gruppierte Index wird gescannt, um die sortierten Daten aus dem Index abzurufen, wie im folgenden Ausführungsplan gezeigt:
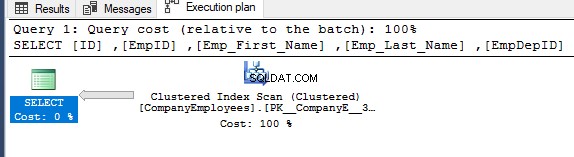
Um die Richtung des Scans abzurufen, der für den gruppierten Index ausgeführt wird, klicken Sie mit der rechten Maustaste auf den Index-Scan-Knoten, um die Knoteneigenschaften zu durchsuchen. In den Eigenschaften des Clustered-Index-Scan-Knotens zeigt die Eigenschaft Scan-Richtung die Richtung des Scans an, der für den Index innerhalb dieser Abfrage ausgeführt wird, was ein Vorwärts-Scan ist, wie im folgenden Schnappschuss gezeigt:
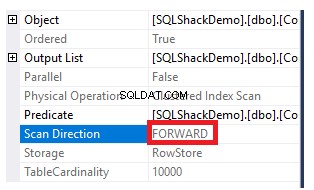
Die Richtung des Index-Scannens kann auch aus dem XML-Ausführungsplan über die ScanDirection-Eigenschaft unter dem IndexScan-Knoten abgerufen werden, wie unten gezeigt:

Angenommen, wir müssen den maximalen ID-Wert aus der zuvor erstellten CompanyEmployees-Tabelle abrufen, indem wir die folgende T-SQL-Abfrage verwenden:
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Überprüfen Sie dann den Ausführungsplan, der aus der Ausführung dieser Abfrage generiert wird. Sie werden sehen, dass ein Scan für den gruppierten Index durchgeführt wird, wie im folgenden Ausführungsplan gezeigt:
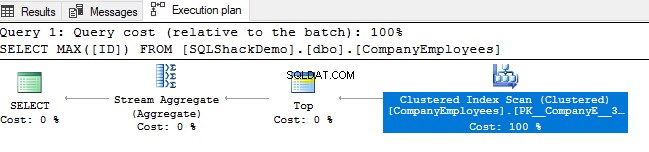
Um die Richtung des Indexscans zu überprüfen, durchsuchen wir die Eigenschaften des Clustered Index Scan-Knotens. Das Ergebnis zeigt uns, dass die SQL Server-Engine es vorzieht, den gruppierten Index vom Ende bis zum Anfang zu scannen, was in diesem Fall schneller ist, um den maximalen Wert der ID-Spalte zu erhalten, da die index ist bereits nach der ID-Spalte sortiert, wie unten gezeigt:
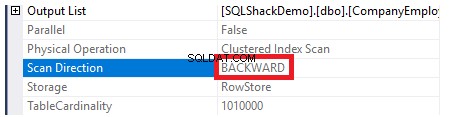
Auch wenn wir versuchen, die zuvor erstellten Tabellendaten mit der folgenden SELECT-Anweisung abzurufen, werden die Datensätze nach den Werten der ID-Spalte sortiert, diesmal jedoch im Gegensatz zur Clustered-Index-Reihenfolge, indem die Sortieroption DESC in der ORDER angegeben wird Die unten gezeigte BY-Klausel:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
Wenn Sie den Ausführungsplan überprüfen, der nach der Ausführung der vorherigen SELECT-Abfrage generiert wurde, werden Sie sehen, dass ein Scan auf dem Clustered-Index durchgeführt wird, um die angeforderten Datensätze der Tabelle zu erhalten, wie unten gezeigt:
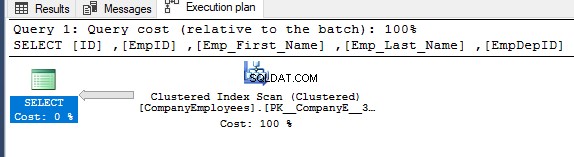
Die Eigenschaften des Clustered Index Scan-Knotens zeigen, dass die Richtung des Scans, die die SQL Server-Engine bevorzugt, die Rückwärts-Scan-Richtung ist, die in diesem Fall schneller ist, da die Daten entgegengesetzt zur tatsächlichen Sortierung des Clustered-Index sortiert werden. unter Berücksichtigung, dass der Index bereits in aufsteigender Reihenfolge nach der ID-Spalte sortiert ist, wie unten gezeigt:
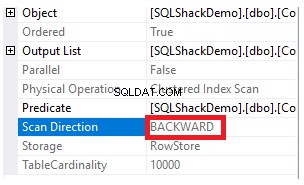
Leistungsvergleich
Angenommen, wir haben die folgenden SELECT-Anweisungen, die Informationen über alle Mitarbeiter abrufen, die ab 2010 eingestellt wurden, zweimal; Beim ersten Mal wird die zurückgegebene Ergebnismenge in aufsteigender Reihenfolge nach den Werten der ID-Spalte sortiert, und beim zweiten Mal wird die zurückgegebene Ergebnismenge in absteigender Reihenfolge nach den Werten der ID-Spalte sortiert, wobei die folgenden T-SQL-Anweisungen verwendet werden:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
Beim Überprüfen der Ausführungspläne, die durch Ausführen der beiden SELECT-Abfragen generiert werden, zeigt das Ergebnis, dass ein Scan auf dem gruppierten Index in den beiden Abfragen durchgeführt wird, um die Daten abzurufen, aber die Richtung des Scans in der ersten Abfrage ist Vorwärts Scan aufgrund der ASC-Datensortierung und Rückwärts-Scan in der zweiten Abfrage aufgrund der Verwendung der DESC-Datensortierung, um die Notwendigkeit zu ersetzen, die Daten erneut neu zu ordnen, wie unten gezeigt:
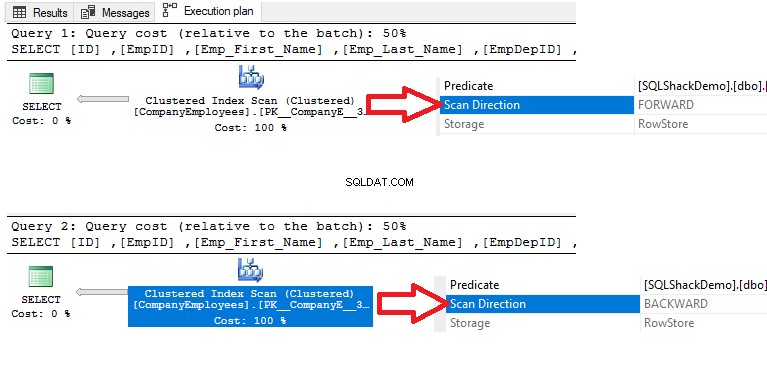
Wenn wir außerdem die IO- und TIME-Ausführungsstatistiken der beiden Abfragen überprüfen, sehen wir, dass beide Abfragen die gleichen IO-Operationen ausführen und annähernd Werte der Ausführungs- und CPU-Zeit verbrauchen.
Diese Werte zeigen uns, wie schlau die SQL Server Engine bei der Auswahl der am besten geeigneten und schnellsten Index-Scan-Richtung ist, um Daten für den Benutzer abzurufen, was im ersten Fall der Vorwärts-Scan und im zweiten Fall der Rückwärts-Scan ist, wie aus den folgenden Statistiken hervorgeht :

Besuchen wir noch einmal das vorherige MAX-Beispiel. Angenommen, wir müssen die maximale ID der Mitarbeiter abrufen, die 2010 und später eingestellt wurden. Dazu verwenden wir die folgenden SELECT-Anweisungen, die die gelesenen Daten nach dem ID-Spaltenwert mit der ASC-Sortierung in der ersten Abfrage und mit der DESC-Sortierung in der zweiten Abfrage sortieren:
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Aus den Ausführungsplänen, die durch die Ausführung der beiden SELECT-Anweisungen generiert wurden, sehen Sie, dass beide Abfragen einen Scan-Vorgang für den gruppierten Index ausführen, um den maximalen ID-Wert abzurufen, jedoch in unterschiedlichen Scan-Richtungen; Forward Scan in der ersten Abfrage und Backward Scan in der zweiten Abfrage aufgrund der ASC- und DESC-Sortieroptionen, wie unten gezeigt:
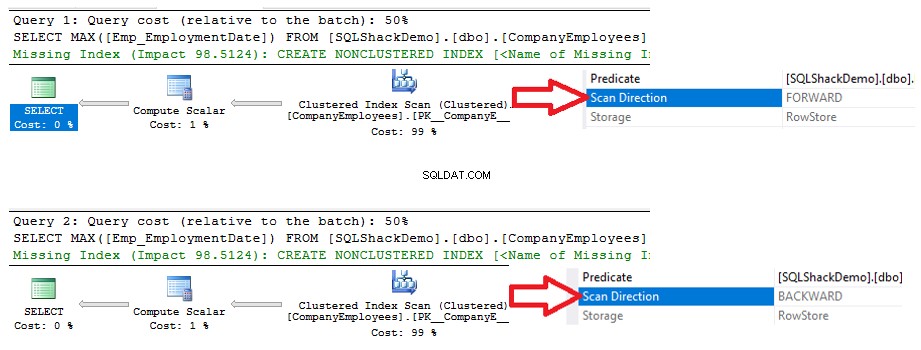
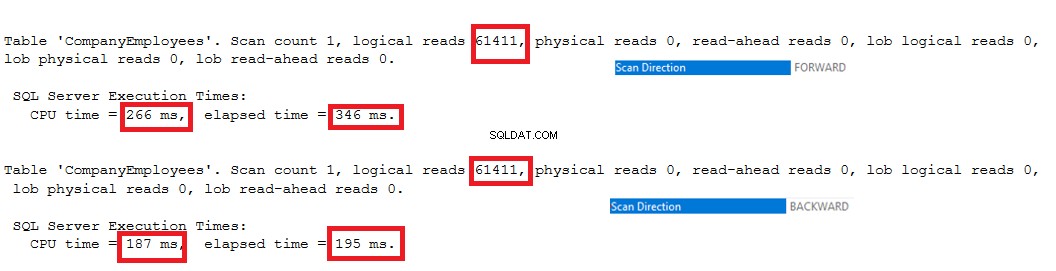
Die von den beiden Abfragen generierten E/A-Statistiken zeigen keinen Unterschied zwischen den beiden Scanrichtungen. Die TIME-Statistik zeigt jedoch einen großen Unterschied zwischen der Berechnung der maximalen ID der Zeilen, wenn diese Zeilen von Anfang bis Ende mit der Forward-Scan-Methode gescannt werden, und dem Scannen von Ende bis Anfang mit der Backward-Scan-Methode. Aus dem nachstehenden Ergebnis geht hervor, dass die Rückwärts-Scan-Methode die optimale Scan-Methode ist, um den maximalen ID-Wert zu erhalten:
Leistungsoptimierung
Wie ich am Anfang dieses Artikels erwähnt habe, ist die Abfrageindizierung der wichtigste Schlüssel im Performance-Tuning- und -Optimierungsprozess. Wenn wir in der vorherigen Abfrage mithilfe der folgenden T-SQL-Anweisung CREATE INDEX einen nicht gruppierten Index zur Spalte „EmploymentDate“ der Tabelle „CompanyEmployees“ hinzufügen:
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
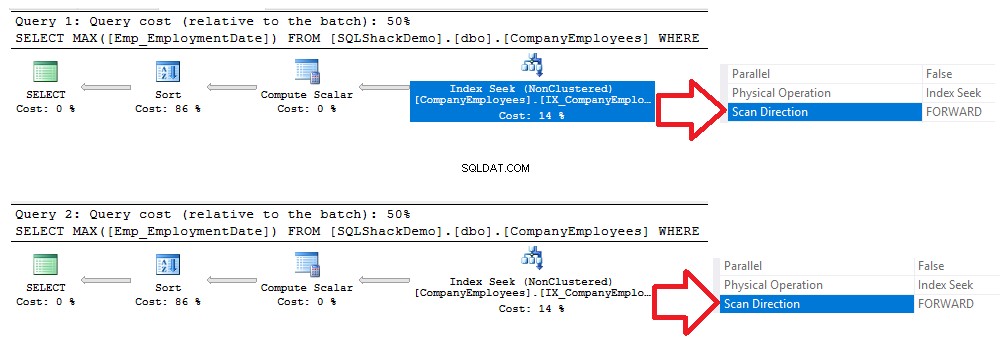
Wenn Sie die nach der Ausführung der beiden Abfragen generierten Ausführungspläne überprüfen, werden Sie feststellen, dass eine Suche auf dem neu erstellten Nonclustered-Index durchgeführt wird und beide Abfragen den Index von Anfang bis Ende mit der Forward-Scan-Methode scannen, ohne dass dies erforderlich ist um einen Rückwärtsscan durchzuführen, um den Datenabruf zu beschleunigen, obwohl wir in der zweiten Abfrage die Sortieroption DESC verwendet haben. Dies geschah, weil der Index direkt gesucht wurde, ohne dass ein vollständiger Index-Scan durchgeführt werden musste, wie im Vergleich der Ausführungspläne unten gezeigt:
Das gleiche Ergebnis kann aus den IO- und TIME-Statistiken abgeleitet werden, die aus den vorherigen zwei Abfragen generiert wurden, wobei die beiden Abfragen die gleiche Menge an Ausführungszeit, CPU- und IO-Vorgängen verbrauchen, mit einem sehr kleinen Unterschied, wie im folgenden Statistik-Snapshot gezeigt :

Nützliche Links:
- Clustered und Nonclustered-Indizes beschrieben
- Erstellen Sie Nonclustered-Indizes
- Leistungsoptimierung von SQL Server:Rückwärtsscannen eines Index
Nützliches Tool:
dbForge Index Manager – praktisches SSMS-Add-in zum Analysieren des Status von SQL-Indizes und Beheben von Problemen mit der Indexfragmentierung.