Angenommen, Sie entwerfen eine SQL Server-Datenbankanwendung für den CEO eines Unternehmens und müssen den fünfthöchsten bezahlten Mitarbeiter des Unternehmens anzeigen.
Was würdest du tun? Eine Lösung besteht darin, eine Abfrage wie diese zu schreiben:
SELECT EmployeeName FROM Employees ORDER BY Salary DESC OFFSET 4 ROWS FETCH FIRST 1 ROWS ONLY;
Die obige Abfrage sieht umständlich aus, insbesondere wenn Sie alle Mitarbeiter in eine Rangfolge bringen müssen. In diesem Fall besteht eine Lösung darin, die Mitarbeiter nach absteigendem Gehalt aufzulisten und dann den Index des Mitarbeiters als Rang zu verwenden. Kompliziert wird es jedoch, wenn mehrere Mitarbeiter das gleiche Gehalt haben. Wie würdest du sie einordnen?
Glücklicherweise verfügt SQL Server über integrierte Ranking-Funktionen, die verwendet werden können, um Datensätze auf verschiedene Weise zu ranken. In diesem Artikel stellen wir die SQL-Server-Ranking-Funktionen im Detail vor und veranschaulichen sie anhand von Beispielen.
Es gibt vier verschiedene Arten von Ranking-Funktionen in SQL Server:
- Rang()
- Dense_Rank()
- Zeilennummer()
- Ntile()
Es ist wichtig zu erwähnen, dass alle Ranking-Funktionen in SQL Server die ORDER BY-Klausel erfordern.
Bevor wir uns jede der Ranking-Funktionen im Detail ansehen, lassen Sie uns zunächst Dummy-Daten erstellen, die wir in diesem Artikel verwenden werden, um die Ranking-Funktion zu erklären. Führen Sie das folgende Skript aus:
CREATE DATABASE Showroom
Use Showroom
CREATE TABLE Car
(
CarId int identity(1,1) primary key,
Name varchar(100),
Make varchar(100),
Model int ,
Price int ,
Type varchar(20)
)
insert into Car( Name, Make, Model , Price, Type)
VALUES ('Corrolla','Toyota',2015, 20000,'Sedan'),
('Civic','Honda',2018, 25000,'Sedan'),
('Passo','Toyota',2012, 18000,'Hatchback'),
('Land Cruiser','Toyota',2017, 40000,'SUV'),
('Corrolla','Toyota',2011, 17000,'Sedan'),
('Vitz','Toyota',2014, 15000,'Hatchback'),
('Accord','Honda',2018, 28000,'Sedan'),
('7500','BMW',2015, 50000,'Sedan'),
('Parado','Toyota',2011, 25000,'SUV'),
('C200','Mercedez',2010, 26000,'Sedan'),
('Corrolla','Toyota',2014, 19000,'Sedan'),
('Civic','Honda',2015, 20000,'Sedan') Im obigen Skript erstellen wir eine Showroom-Datenbank mit einem Tischauto. Die Car-Tabelle hat fünf Attribute:CarId, Name, Make, Model, Price und Type.
Als Nächstes haben wir 12 Dummy-Datensätze in der Car-Tabelle hinzugefügt.
Jetzt sehen Sie jede der Ranking-Funktionen.
1. Rangfunktion
Die Rank-Funktion in SQL Server weist jedem durch die ORDER BY-Klausel geordneten Datensatz einen Rang zu. Wenn Sie beispielsweise das fünftteuerste Auto in der Autotabelle sehen möchten, können Sie die Rangfunktion wie folgt verwenden:
Use Showroom SELECT Name,Make,Model, Price, Type, RANK() OVER(ORDER BY Price DESC) as PriceRank FROM Car
Wählen Sie im obigen Skript Name, Marke, Modell, Preis, Typ und den Rang jedes Autos, sortiert nach Preis, als Spalte „PriceRank“ aus. Die Syntax für die Rank-Funktion ist einfach. Sie müssen die Funktion RANK schreiben, gefolgt vom OVER-Operator. Innerhalb des OVER-Operators müssen Sie die ORDER BY-Klausel übergeben, die die Daten sortiert. Die Ausgabe des obigen Skripts sieht so aus:
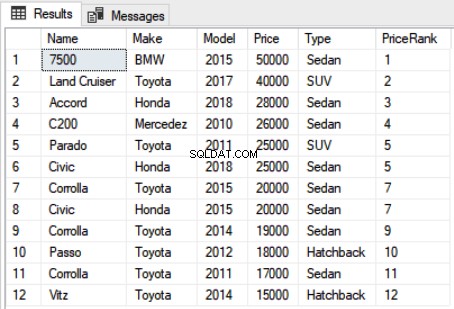
Sie können den Rang für jedes Auto sehen. Es ist wichtig zu erwähnen, dass bei einem Gleichstand zwischen den Rängen zweier Rekorde der nächste Rangplatz übersprungen wird. Beispielsweise gibt es in der Ausgabe ein Unentschieden zwischen Datensatz 5 und 6. Sowohl Parado als auch Civic haben den gleichen Preis und wurden daher auf Platz 5 eingestuft. Der nächste Rang, insbesondere Rang 6, wird jedoch übersprungen, und die nächsten beiden Autos in der Liste wurden auf Rang 7 eingestuft, da sie auch den gleichen Preis haben. Nach dem 7. Rang wird der Rang 8 wieder übersprungen und der nächste zugewiesene Rang ist 9.
Sie können die Daten in Partitionen aufteilen und dann eine Rangfolge auf einzelne Partitionen anwenden. Im folgenden Skript gibt es die Aufteilung der Datensätze nach Typ. Wir ordnen die Autos in jeder Partition.
SELECT Name,Make,Model, Price, Type, RANK() OVER(PARTITION BY Type ORDER BY Price DESC) as PriceRank FROM Car
Die Ausgabe des obigen Skripts sieht so aus:
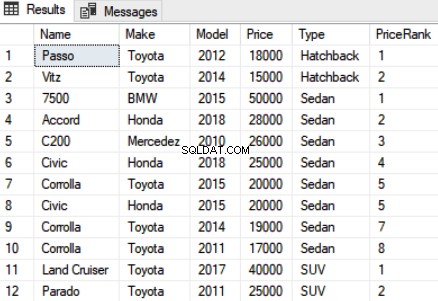
Aus der Ausgabe ist ersichtlich, dass die Datensätze nach Fahrzeugtypen partitioniert wurden und der Rang lokal innerhalb der Partition zugewiesen wurde. Beispielsweise gehören die ersten beiden Datensätze zur Partition „Fließheck“ und wurden auf Rang 1 und 2 gesetzt. Für die nächste Partition, d. h. „Limousine“, wird der Rang auf 1 zurückgesetzt.
2. Dense_Rank-Funktion
Die dense_rank-Funktion ähnelt der rank-Funktion. Im Fall von dense_rank wird jedoch, wenn es einen Gleichstand zwischen zwei Datensätzen hinsichtlich des Rangs gibt, der nächste Rang nicht übersprungen. Lassen Sie es uns anhand des Beispiels demonstrieren. Führen Sie das folgende Skript aus:
Use Showroom SELECT Name,Make,Model, Price, Type, DENSE_RANK() OVER(ORDER BY Price DESC) as DensePriceRank FROM Car
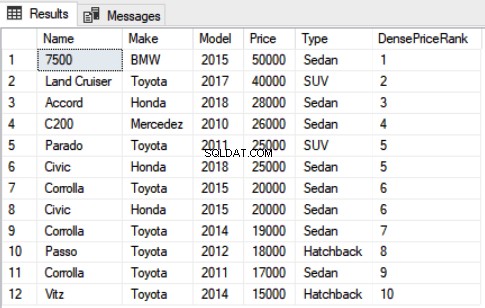
Auch hier können Sie sehen, dass der 5. und 6. Datensatz den gleichen Wert für Price haben und beiden Rang 5 zugewiesen wurde. Anders als die rank-Funktion, die den nächsten Rang übersprungen hat, überspringt die dense_rank-Funktion jedoch nicht den nächsten Rang und den Rang 6 wurde dem nächsten Datensatz zugewiesen.
Wie die rank-Funktion kann auch die dense_rank-Funktion auf die partition by-Klausel angewendet werden. Sehen Sie sich das folgende Skript an:
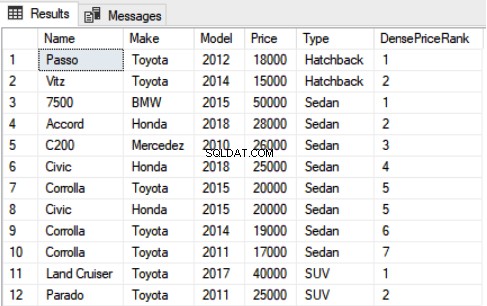
SELECT Name,Make,Model, Price, Type, DENSE_RANK() OVER(PARTITION BY Type ORDER BY Price DESC) as DensePriceRank FROM Car
Die Ausgabe des obigen Skripts sieht so aus:
3. Row_Number-Funktion
Die row_number-Funktion ordnet die Datensätze auch gemäß den Bedingungen, die durch die ORDER BY-Klausel angegeben sind. Im Gegensatz zu den Funktionen rank und dense_rank weist die Funktion row_number jedoch nicht denselben Rang zu, wenn es doppelte Werte für die Spalte gibt, die durch die ORDER BY-Klausel angegeben ist. Sehen Sie sich das folgende Skript an:
SELECT Name,Make,Model, Price, Type, DENSE_RANK() OVER(PARTITION BY Type ORDER BY Price DESC) as DensePriceRank FROM Car
Die Ausgabe des obigen Skripts sieht so aus:
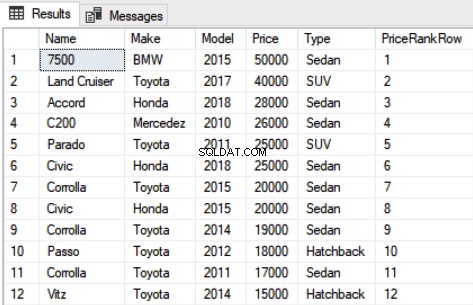
Aus dem obigen Skript können Sie ersehen, dass sowohl der fünfte als auch der sechste Datensatz denselben Wert für die Preisspalte haben, aber der ihnen zugewiesene Rang ist unterschiedlich.
In ähnlicher Weise kann die row_number-Funktion auf die partitionierten Daten angewendet werden. Sehen Sie sich zum Beispiel das folgende Skript an.
SELECT Name,Make,Model, Price, Type, ROW_NUMBER() OVER(PARTITION BY Type ORDER BY Price DESC) AS PriceRankRow FROM Car
Die Ausgabe des obigen Skripts sieht so aus:
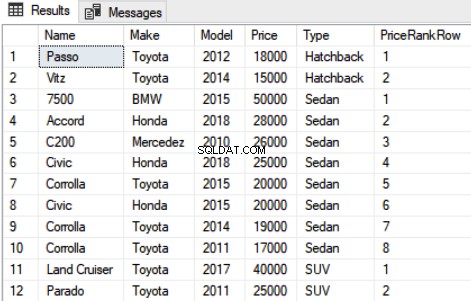
4. NTILE-Funktion
NTILE-Funktion gruppiert das Ranking. Angenommen, Sie haben 12 Datensätze in einer Tabelle und möchten sie in Vierergruppen einordnen. Die ersten drei Datensätze haben Rang 1, die nächsten drei Datensätze haben Rang 2 und so weiter.
Schauen wir uns ein Beispiel der NTILE-Funktion an.
Use Showroom SELECT Name,Make,Model, Price, Type, NTILE(4) OVER(ORDER BY Price DESC) as NtilePrice FROM Car
Im obigen Skript haben wir 4 als Parameter an die NTILE-Funktion übergeben. Da wir 12 Datensätze haben, sehen Sie insgesamt 4 verschiedene Ränge, wobei 1 Rang drei Datensätzen zugeordnet wird. Die Ausgabe sieht so aus:
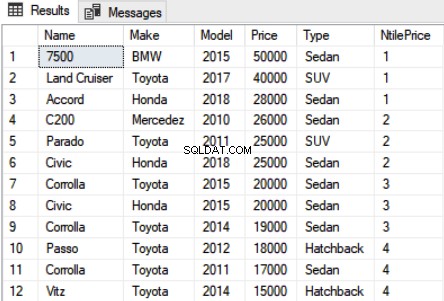
Sie können sehen, dass die ersten drei teuersten Autos auf Platz 1 eingestuft wurden, die nächsten drei auf Platz 2 und so weiter.
Die NTILE-Funktion kann auch auf die partitionierten Daten angewendet werden. Sehen Sie sich das folgende Skript an:
SELECT Name,Make,Model, Price, Type, NTILE(4) OVER(PARTITION BY Type ORDER BY Price DESC) as NtilePrice FROM Car
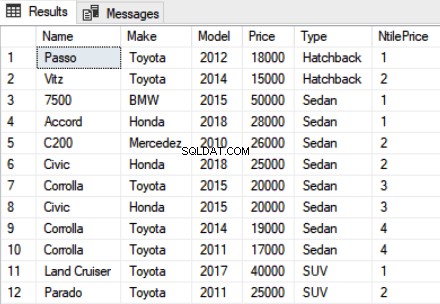
Schlussfolgerung
Rangfolgefunktionen in SQL Server werden verwendet, um Daten auf unterschiedliche Weise zu ordnen. In dieser Lektüre haben wir anhand der Beispiele verschiedene Arten von Ranking-Funktionen vorgestellt. Die rank- und dense_rank-Funktionen geben den Daten mit denselben Werten in der ORDER BY-Klausel denselben Rang, während die row_number-Funktion den Datensatz inkrementell einordnet, selbst wenn es einen Gleichstand gibt.
Falls keine doppelten Datensätze in der angegebenen Spalte vorhanden sind Durch die ORDER BY-Klausel verhalten sich die Funktionen rank, dense_rank und row_number auf ähnliche Weise.



