In meinem vorherigen Artikel haben wir damit begonnen, die Grundlagen des EXPLAIN-Befehls zu beschreiben und zu analysieren, was in PostgreSQL passiert, wenn eine Abfrage ausgeführt wird.
Ich werde weiter über die Grundlagen von EXPLAIN in PostgreSQL schreiben. Die Informationen sind eine kurze Rezension von Understanding EXPLAIN von Guillaume Lelarge. Ich empfehle dringend, das Original zu lesen, da einige Informationen fehlen.
Zwischenspeichern
Was passiert auf der physischen Ebene, wenn unsere Abfrage ausgeführt wird? Finden wir es heraus. Ich habe meinen Server auf Ubuntu 13.10 bereitgestellt und Festplatten-Caches auf Betriebssystemebene verwendet.
Ich stoppe PostgreSQL, übertrage Änderungen an das Dateisystem, lösche den Cache und führe PostgreSQL aus:
> sudo service postgresql-9.3 stop > sudo sync > sudo su - # echo 3 > /proc/sys/vm/drop_caches # exit > sudo service postgresql-9.3 start
Wenn der Cache geleert ist, führen Sie die Abfrage mit der Option BUFFERS aus
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Wir lesen die Tabelle blockweise. Der Cache ist leer. Wir mussten auf 8334 Blöcke zugreifen, um die gesamte Tabelle von der Platte zu lesen.
Puffer:Shared Read ist die Anzahl der Blöcke, die PostgreSQL von der Festplatte liest.
Führen Sie die vorherige Abfrage aus
EXPLAIN (ANALYZE,BUFFERS) SELECT * FROM foo;

Puffer:Shared Hit ist die Anzahl der Blöcke, die aus dem PostgreSQL-Cache abgerufen werden.
Mit jeder Abfrage entnimmt PostgreSQL mehr und mehr Daten aus dem Cache und füllt somit seinen eigenen Cache.
Cache-Lesevorgänge sind schneller als Datenträger-Lesevorgänge. Sie können diesen Trend erkennen, indem Sie den Gesamtlaufzeitwert verfolgen.
Die Größe des Cache-Speichers wird durch die Konstante shared_buffers in der Datei postgresql.conf definiert.
WO
Bedingung zur Abfrage hinzufügen
EXPLAIN SELECT * FROM foo WHERE c1 > 500;
Es gibt keine Indizes in der Tabelle. Beim Ausführen der Abfrage wird jeder Datensatz der Tabelle sequentiell gescannt (Seq Scan) und mit der Bedingung c1> 500 verglichen. Wenn die Bedingung erfüllt ist, wird der Datensatz zum Ergebnis hinzugefügt. Andernfalls wird es verworfen. Filter zeigt dieses Verhalten an, ebenso wie der Kostenwert steigt.
Die geschätzte Anzahl der Zeilen nimmt ab.
Der ursprüngliche Artikel erklärt, warum die Kosten diesen Wert annehmen und wie die geschätzte Anzahl von Zeilen berechnet wird.
Es ist an der Zeit, Indizes zu erstellen.
CREATE INDEX ON foo(c1); EXPLAIN SELECT * FROM foo WHERE c1 > 500;

Die geschätzte Anzahl der Zeilen hat sich geändert. Was ist mit dem Index?
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

Nur 510 Zeilen von mehr als 1 Million werden gefiltert. PostgreSQL musste mehr als 99,9 % der Tabelle lesen.
Wir werden die Verwendung des Index erzwingen, indem wir Seq Scan deaktivieren:
SET enable_seqscan TO off; EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c1 > 500;

In Index Scan und Index Cond wird der Index foo_c1_idx anstelle von Filter verwendet.
Wenn Sie die gesamte Tabelle auswählen, erhöht die Verwendung des Index die Kosten und die Zeit zum Ausführen der Abfrage.
Seq-Scan aktivieren:
SET enable_seqscan TO on;
Ändern Sie die Abfrage:
EXPLAIN SELECT * FROM foo WHERE c1 < 500;
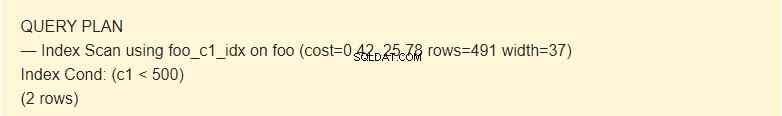
Hier verwendet der Planer den Index.
Lassen Sie uns nun den Wert komplizieren, indem Sie das Textfeld hinzufügen.
EXPLAIN SELECT * FROM foo
WHERE c1 < 500 AND c2 LIKE 'abcd%';

Wie Sie sehen können, wird der Index foo_c1_idx für c1 <500 verwendet. Um c2 auszuführen ~~ ‘abcd%’::text, verwenden Sie den Filter.
Zu beachten ist, dass bei der Ausgabe der Ergebnisse das POSIX-Format des LIKE-Operators verwendet wird. Wenn in der Bedingung nur das Textfeld steht:
EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Seq Scan wird angewendet.
Erstellen Sie den Index mit c2:
CREATE INDEX ON foo(c2); EXPLAIN (ANALYZE) SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Der Index wird nicht angewendet, da meine Datenbank für Testfelder die UTF-8-Kodierung verwendet.
Beim Erstellen des Index muss die Klasse des text_pattern_ops-Operators angegeben werden:
CREATE INDEX ON foo(c2 text_pattern_ops); EXPLAIN SELECT * FROM foo WHERE c2 LIKE 'abcd%';

Toll! Es hat funktioniert!
Bitmap Index Scan verwendet den Index foo_c2_idx1, um die benötigten Datensätze zu ermitteln. Dann geht PostgreSQL zu der Tabelle (Bitmap Heap Scan), um sicherzustellen, dass diese Datensätze tatsächlich existieren. Dieses Verhalten bezieht sich auf die Versionierung von PostgreSQL.
Wenn Sie statt der ganzen Zeile nur das Feld auswählen, auf dem der Index aufgebaut ist:
EXPLAIN SELECT c1 FROM foo WHERE c1 < 500;

Der Index-Only-Scan wird schneller ausgeführt als der Index-Scan, da es nicht notwendig ist, die Zeile der Tabelle zu lesen:width=4.
Schlussfolgerung
- Seq Scan liest die ganze Tabelle
- Index Scan verwendet den Index für die WHERE-Anweisungen und liest die Tabelle, wenn Zeilen ausgewählt werden
- Bitmap Index Scan verwendet Index Scan und Auswahlkontrolle durch die Tabelle. Effektiv für eine große Anzahl von Zeilen.
- Index Only Scan ist der schnellste Block, der nur den Index liest.
Weiterführende Literatur:
Abfrageoptimierung in PostgreSQL. ERKLÄREN Grundlagen – Teil 3