Über alle wichtigen RDBMS-Produkte hinweg Primary Key in SQL Constraints hat eine entscheidende Rolle. Sie identifizieren die in einer Tabelle vorhandenen Datensätze eindeutig. Daher sollten wir den Primärschlüsselserver während des Tabellenentwurfs sorgfältig auswählen, um die Leistung zu verbessern.
In diesem Artikel erfahren wir, was eine Primärschlüssel-Einschränkung ist. Außerdem erfahren Sie, wie Sie Einschränkungen für Primärschlüssel erstellen, ändern oder löschen.
SQL Server-Einschränkungen
In SQL Server Einschränkungen sind Regeln, die die Eingabe der Daten in die notwendigen Spalten regeln. Einschränkungen erzwingen die Genauigkeit von Daten und wie diese Daten den Geschäftsanforderungen entsprechen. Außerdem machen sie die Daten für Endbenutzer zuverlässig. Aus diesem Grund ist es wichtig, während der Designphase die richtigen Einschränkungen zu identifizieren des Datenbank- oder Tabellenschemas.
SQL Server unterstützt die folgenden Einschränkungstypen um die Datenintegrität zu erzwingen:
Primärschlüsseleinschränkungen werden für eine einzelne Spalte oder eine Kombination von Spalten erstellt, um die Eindeutigkeit von Datensätzen zu erzwingen und die Datensätze schneller zu identifizieren. Die beteiligten Spalten sollten keine NULL-Werte enthalten. Daher sollte die Eigenschaft NOT NULL für die Spalten definiert werden.
Fremdschlüsselbeschränkungen werden für eine einzelne Spalte oder eine Kombination von Spalten erstellt, um eine Beziehung zwischen zwei Tabellen herzustellen und die in einer Tabelle vorhandenen Daten für eine andere zu erzwingen. Idealerweise verweisen Tabellenspalten, in denen wir die Daten mit Fremdschlüsseleinschränkungen erzwingen müssen, auf die Quelltabelle mit einem Primärschlüssel in SQL oder einer eindeutigen Schlüsseleinschränkung. Mit anderen Worten, nur die Datensätze, die in den Primär- oder eindeutigen Schlüsselbeschränkungen der Quelltabelle verfügbar sind, können in die Zieltabelle eingefügt oder aktualisiert werden.
Eindeutige Schlüsselbeschränkungen werden für eine einzelne Spalte oder eine Kombination von Spalten erstellt, um die Eindeutigkeit der Spaltendaten zu erzwingen. Sie ähneln den Primärschlüsseleinschränkungen mit einer einzigen Änderung. Der Unterschied zwischen Primary Key und Unique Key Constraints besteht darin, dass letztere auf Nullable erstellt werden können Spalten und erlaubt einen NULL-Wert-Datensatz in seiner Spalte.
Beschränkungen prüfen werden für eine einzelne Spalte oder eine Kombination von Spalten erstellt, indem die akzeptierten Datenwerte für die beteiligten Spalten über einen logischen Ausdruck eingeschränkt werden. Es gibt einen Unterschied zwischen Foreign Key und Check Constraints. Der Fremdschlüssel erzwingt die Datenintegrität, indem er Daten aus dem Primär- oder eindeutigen Schlüssel einer anderen Tabelle überprüft. Der Check Constraint tut dies jedoch mithilfe eines logischen Ausdrucks.
Lassen Sie uns nun die Primärschlüsseleinschränkungen durchgehen.
Primärschlüsseleinschränkung
Die Primärschlüsselbeschränkung erzwingt die Eindeutigkeit einer einzelnen Spalte oder einer Kombination von Spalten ohne NULL-Werte in den beteiligten Spalten.
Um Eindeutigkeit zu erzwingen, erstellt SQL Server einen eindeutigen gruppierten Index für die Spalten, aus denen Primärschlüssel erstellt wurden. Wenn Clustered-Indizes vorhanden sind, erstellt SQL Server einen Unique Non-Clustered-Index für die Tabelle für den Primärschlüssel.
Sehen wir uns an, wie wir mithilfe von T-SQL-Skripts Primärschlüssel für eine Tabelle erstellen, ändern, löschen, deaktivieren oder aktivieren.
Erstellen Sie einen Primärschlüssel
Wir können Primärschlüssel für eine Tabelle entweder während der Tabellenerstellung oder danach erstellen. Die Syntax variiert für diese Szenarien leicht.
Erstellung des Primärschlüssels während der Tabellenerstellung
Die Syntax ist unten:
CREATE TABLE SCHEMA_NAME.TABLE_NAME
(
COLUMN1 datatype [ NULL | NOT NULL ] PRIMARY KEY,
COLUMN2 datatype [ NULL | NOT NULL ],
...
);
Lassen Sie uns eine Tabelle mit dem Namen Employees erstellen in der Personalabteilung Schema zu Testzwecken mit dem folgenden Skript:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL PRIMARY KEY,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
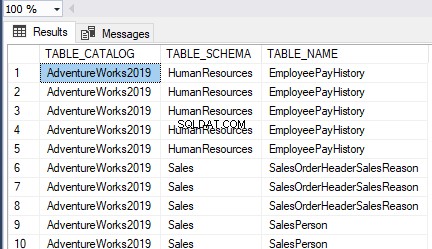
Wir haben die HumanResources.Employees erfolgreich erstellt Tabelle auf AdventureWorks Datenbank:
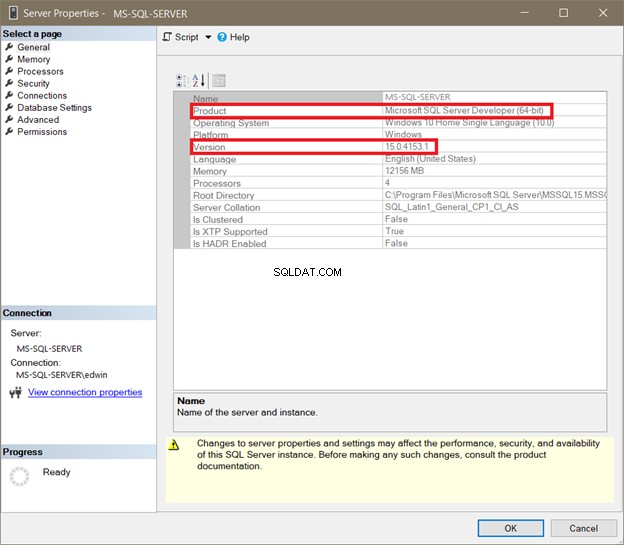
Wir können sehen, dass der gruppierte Index für die Tabelle erstellt wurde, die mit dem Primärschlüsselnamen übereinstimmt, wie oben hervorgehoben.
Lassen Sie uns die Tabelle mit dem folgenden Skript löschen und es erneut mit der neuen Syntax versuchen.
DROP TABLE HumanResources.EmployeesSo erstellen Sie den Primärschlüssel in SQL für eine Tabelle mit dem benutzerdefinierten Primärschlüsselnamen PK_Employees , verwenden Sie die folgende Syntax:
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (Employee_Id)
);
Wir haben die HumanResources.Employees erstellt Tabelle mit dem Primärschlüsselnamen PK_Employees :
Erstellung des Primärschlüssels nach der Tabellenerstellung
Manchmal vergessen Entwickler oder DBAs die Primärschlüssel und erstellen Tabellen ohne sie. Es ist jedoch möglich, einen Primärschlüssel für vorhandene Tabellen zu erstellen.
Lassen wir HumanResources.Employees fallen Tabelle und erstellen Sie sie mit dem folgenden Skript neu:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
Wenn Sie dieses Skript erfolgreich ausführen, können wir HumanResources.Employees sehen ohne Primärschlüssel oder Indizes erstellte Tabelle:

So erstellen Sie einen Primärschlüssel mit dem Namen PK_Employees Verwenden Sie in dieser Tabelle die folgende Syntax:
ALTER TABLE <schema_name>.<table_name>
ADD CONSTRAINT <constraint_name> PRIMARY KEY ( <column_name> );
Die Ausführung dieses Skripts erstellt den Primärschlüssel für unsere Tabelle:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
Primärschlüsselerstellung für mehrere Spalten
In unseren Beispielen haben wir Primärschlüssel für einzelne Spalten erstellt. Wenn wir Primärschlüssel für mehrere Spalten erstellen möchten, benötigen wir eine andere Syntax.
Um mehrere Spalten als Teil des Primärschlüssels hinzuzufügen, müssen wir einfach durch Kommas getrennte Werte der Spaltennamen hinzufügen, die Teil des Primärschlüssels sein sollen.
Primärschlüssel während der Tabellenerstellung
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name)
);
GO
Primärschlüssel nach der Tabellenerstellung
CREATE TABLE HumanResources.Employees
( First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (First_Name, Last_Name);
GO
Den Primärschlüssel löschen
Um den Primärschlüssel zu löschen, verwenden wir die folgende Syntax. Dabei spielt es keine Rolle, ob sich der Primärschlüssel auf einer oder mehreren Spalten befand.
ALTER TABLE <schema_name>.<table_name>
DROP CONSTRAINT <constraint_name> ;
Zum Löschen der Primärschlüsseleinschränkung für HumanResources.Employees verwenden Sie das folgende Skript:
ALTER TABLE HumanResources.Employees
DROP CONSTRAINT PK_Employees;
Durch das Löschen des Primärschlüssels werden sowohl die Primärschlüssel als auch die geclusterten oder nicht geclusterten Indizes entfernt, die zusammen mit der Primärschlüsselerstellung erstellt wurden:
Ändern Sie den Primärschlüssel
In SQL Server gibt es keine direkten Befehle zum Ändern von Primärschlüsseln. Wir müssen einen vorhandenen Primärschlüssel löschen und mit den erforderlichen Änderungen neu erstellen. Daher sind die Schritte zum Ändern des Primärschlüssels:
- Löschen Sie einen vorhandenen Primärschlüssel.
- Erstellen Sie neue Primärschlüssel mit den erforderlichen Änderungen.
Primärschlüssel deaktivieren/aktivieren
Deaktivieren Sie beim Massenladen einer Tabelle mit vielen Datensätzen den Primärschlüssel und aktivieren Sie ihn für eine bessere Leistung wieder. Die Schritte sind unten:
Deaktivieren Sie den vorhandenen Primärschlüssel mit der folgenden Syntax:
ALTER INDEX <index_name> ON <schema_name>.<table_name> DISABLE;Zum Deaktivieren des Primärschlüssels auf HumanResources.Employees Tabelle lautet das Skript:
ALTER INDEX PK_Employees ON HumanResources.Employees
DISABLE;
Aktivieren Sie vorhandene Primärschlüssel, die sich im deaktivierten Zustand befinden. Wir müssen den Index mit der folgenden Syntax NEU ERSTELLEN:
ALTER INDEX <index_name> ON <schema_name>.<table_name> REBUILD;Zum Aktivieren des Primärschlüssels auf HumanResources.Employees verwenden Sie das folgende Skript:
ALTER INDEX PK_Employees ON HumanResources.Employees
REBUILD;
Die Mythen über den Primärschlüssel
Viele Leute sind verwirrt über die folgenden Mythen im Zusammenhang mit Primärschlüsseln in SQL Server.
- Tabelle mit Primärschlüssel ist keine Heap-Tabelle
- Primärschlüssel haben den gruppierten Index und die Daten in physischer Reihenfolge sortiert
Lassen Sie uns sie klären.
Tabelle mit Primärschlüssel ist keine Heap-Tabelle
Bevor wir tiefer eintauchen, lassen Sie uns die Definition des Primärschlüssels und der Heap-Tabelle überarbeiten.
Der Primärschlüssel erstellt einen Clustered-Index für eine Tabelle, wenn dort keine anderen Clustered-Indizes verfügbar sind. Eine Tabelle ohne Clustered Index ist eine Heap-Tabelle.
Basierend auf diesen Definitionen können wir verstehen, dass der Primärschlüssel nur dann einen Clustered-Index erstellt, wenn es keine anderen Clustered-Indizes in der Tabelle gibt. Wenn Cluster-Indizes vorhanden sind, erstellt die Primärschlüsselerstellung einen Non-Clustered-Index für die Tabelle, die dem Primärschlüssel entspricht.
Überprüfen wir dies, indem wir HumanResources.Employees löschen Tabelle und Neuerstellung:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money,
CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (Employee_Id)
);
GO
Wir können die NONCLUSTERED-Indexoption für den Primärschlüssel angeben (siehe oben). Es wurde eine Tabelle mit einem eindeutigen, nicht geclusterten Index für den primären Schlüssel PK_Employees erstellt .
Daher ist diese Tabelle eine Heap-Tabelle, obwohl sie einen Primärschlüssel hat.
Sehen wir uns an, ob SQL Server einen nicht gruppierten Index für den Primärschlüssel erstellen kann, wenn wir das Schlüsselwort Non-clustered nicht angeben während der Erstellung des Primärschlüssels. Verwenden Sie das folgende Skript:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT IDENTITY NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL,
DOB DATETIME,
Dept varchar(100),
Salary Money
);
GO
-- Create Clustered Index on Employee_Id column before creating Primary Key
CREATE CLUSTERED INDEX IX_Employee_ID ON HumanResources.Employees(First_Name, Last_Name);
GO
-- Create Primary Key on Employee_Id column
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
Hier haben wir vor der Erstellung des Primärschlüssels separat einen Clustered-Index erstellt. Und eine Tabelle kann nur einen gruppierten Index haben. Daher hat SQL Server den Primärschlüssel als eindeutigen, nicht gruppierten Index erstellt. Im Moment ist die Tabelle keine Heap-Tabelle, da sie einen geclusterten Index hat.
Wenn ich meine Meinung geändert und den gruppierten Index auf First_Name gelöscht hätte und Nachname Spalten mit dem folgenden Skript:
DROP INDEX IX_Employee_ID ON HumanResources.Employees;
GO
Wir haben den gruppierten Index erfolgreich gelöscht. Die HumanResources.Employees table ist eine Heap-Tabelle, obwohl in der Tabelle ein Primärschlüssel verfügbar ist:
Dies räumt mit dem Mythos auf, dass eine Tabelle mit einem Primärschlüssel eine Heap-Tabelle sein kann, wenn für die Tabelle keine Clustered-Indizes verfügbar sind.
Der Primärschlüssel wird einen Clustered-Index und Daten haben, die in physischer Reihenfolge sortiert sind
Wie wir aus dem vorherigen Beispiel gelernt haben, kann ein Primärschlüssel in SQL einen nicht gruppierten Index haben. In diesem Fall würden die Datensätze nicht in physischer Reihenfolge sortiert.
Lassen Sie uns die Tabelle mit dem gruppierten Index auf einem Primärschlüssel überprüfen. Wir werden prüfen, ob die Datensätze in physischer Reihenfolge sortiert werden.
Erstellen Sie HumanResources.Employees neu Tabelle mit minimalen Spalten und entfernter IDENTITY-Eigenschaft für die Employee_ID Spalte:
DROP TABLE HumanResources.Employees
GO
CREATE TABLE HumanResources.Employees
( Employee_Id INT NOT NULL,
First_Name VARCHAR(100) NOT NULL,
Last_Name VARCHAR(100) NOT NULL
);
GO
Nachdem wir die Tabelle nun ohne den Primärschlüssel oder einen gruppierten Index erstellt haben, können wir 3 Datensätze in unsortierter Reihenfolge für die Employee_Id einfügen Spalte:
INSERT INTO HumanResources.Employees ( Employee_Id, First_Name, Last_Name)
VALUES
(3, 'Antony', 'Mark'),
(1, 'James', 'Cameroon'),
(2, 'Jackie', 'Chan')

Wählen wir aus HumanResources.Employees aus Tabelle:
SELECT *
FROM HumanResources.Employees
Wir können die abgerufenen Datensätze in diesem Moment in derselben Reihenfolge wie die aus der Heap-Tabelle eingefügten Datensätze sehen.
Lassen Sie uns einen Primärschlüssel für diese Heap-Tabelle erstellen und sehen, ob er Auswirkungen auf die SELECT-Anweisung hat:
ALTER TABLE HumanResources.Employees
ADD CONSTRAINT PK_Employees PRIMARY KEY (Employee_ID);
GO
SELECT *
FROM HumanResources.Employees

Nach der Erstellung des Primärschlüssels können wir sehen, dass die SELECT-Anweisung Datensätze in aufsteigender Reihenfolge der Employee_Id abgerufen hat (Spalte Primärschlüssel). Dies liegt am geclusterten Index auf Employee_Id .
Wenn ein Primärschlüssel mit der nicht geclusterten Option erstellt wird, werden die Tabellendaten nicht basierend auf der Primärschlüsselspalte sortiert.
Wenn die Länge eines einzelnen Datensatzes in einer Tabelle 4030 Bytes überschreitet, passt nur ein Datensatz auf eine Seite. Der gruppierte Index stellt sicher, dass die Seiten in physischer Reihenfolge sind.
Eine Seite ist eine grundlegende Speichereinheit in SQL Server-Datendateien mit einer Größe von 8 KB (8192 Bytes). Nur 8060 Byte dieser Einheit sind für die Datenspeicherung verwendbar. Der Restbetrag ist für Seitenkopfzeilen und andere Interna.
Tipps zur Auswahl von Primärschlüsselspalten
- Ganzzahlige Datentypspalten eignen sich am besten für Primärschlüsselspalten, da sie kleinere Speichergrößen belegen und dabei helfen können, die Daten schneller abzurufen.
- Da Primärschlüsselspalten standardmäßig einen gruppierten Index haben, verwenden Sie die IDENTITY-Option für Spalten vom Datentyp Integer, um neue Werte in inkrementeller Reihenfolge generieren zu lassen.
- Anstatt einen Primärschlüssel für mehrere Spalten zu erstellen, erstellen Sie eine neue Integer-Spalte mit definierter IDENTITY-Eigenschaft. Erstellen Sie außerdem einen eindeutigen Index für mehrere Spalten, die ursprünglich für eine bessere Leistung identifiziert wurden.
- Vermeiden Sie Spalten mit String-Datentypen wie varchar, nvarchar usw. Wir können die sequentielle Inkrementierung von Daten bei diesen Datentypen nicht garantieren. Dies kann sich auf die INSERT-Leistung dieser Spalten auswirken.
- Wählen Sie Spalten aus, in denen Werte nicht als Primärschlüssel aktualisiert werden. Wenn sich beispielsweise der Wert des Primärschlüssels von 5 auf 1000 ändern kann, muss der mit dem Clustered-Index verknüpfte B-Tree aktualisiert werden, was zu leichten Leistungseinbußen führt.
- Wenn Spalten vom Datentyp "String" als Primärschlüsselspalten ausgewählt werden müssen, stellen Sie sicher, dass die Länge der Spalten vom Datentyp "varchar" oder "nvarchar" klein bleibt, um eine bessere Leistung zu erzielen.
Schlussfolgerung
Wir haben die Grundlagen der in SQL Server verfügbaren Einschränkungen durchgegangen. Wir haben die Primärschlüsseleinschränkungen im Detail untersucht und gelernt, wie Primärschlüssel erstellt, gelöscht, geändert, deaktiviert und neu erstellt werden. Darüber hinaus haben wir einige populäre Mythen rund um Primärschlüssel anhand von Beispielen aufgeklärt.
Bleiben Sie dran für den nächsten Artikel!