Wenn Benutzer Daten von einem System anfordern, möchten sie diese normalerweise in einer bestimmten Reihenfolge sehen … selbst wenn sie Tausende von Zeilen zurückgeben. Wie viele DBAs und Entwickler wissen, kann ORDER BY einen Abfrageplan durcheinanderbringen, da die Daten sortiert werden müssen. Dies kann manchmal einen SORT-Operator als Teil der Abfrageausführung erfordern, was ein kostspieliger Vorgang sein kann, insbesondere wenn Schätzungen deaktiviert sind und auf die Festplatte überlaufen. In einer idealen Welt sind die Daten dank eines Indexes bereits sortiert (Indizes und Sortierungen sind sehr komplementär). Wir sprechen oft davon, einen abdeckenden Index zu erstellen, um eine Abfrage zu erfüllen – damit der Optimierer nicht zur Basistabelle oder zum Clustered-Index zurückkehren muss, um zusätzliche Spalten zu erhalten. Und Sie haben vielleicht gehört, dass Leute sagen, dass die Reihenfolge der Spalten im Index wichtig ist. Haben Sie jemals darüber nachgedacht, wie sich dies auf Ihre SORT-Operationen auswirkt?
Untersuchen von ORDER BY und Sorts
Wir beginnen mit einer neuen Kopie der AdventureWorks2014-Datenbank auf einer SQL Server 2014-Instanz (Version 12.0.2000). Wenn wir eine einfache SELECT-Abfrage für Sales.SalesOrderHeader ohne ORDER BY ausführen, sehen wir einen einfachen alten Clustered Index Scan (mit SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Abfrage ohne ORDER BY, Clustered-Index-Scan
Abfrage ohne ORDER BY, Clustered-Index-Scan
Lassen Sie uns nun ein ORDER BY hinzufügen, um zu sehen, wie sich der Plan ändert:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
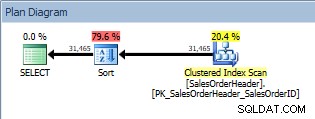 Abfrage mit ORDER BY, Clustered-Index-Scan und Sortierung
Abfrage mit ORDER BY, Clustered-Index-Scan und Sortierung
Zusätzlich zum Clustered Index Scan haben wir jetzt eine vom Optimierer eingeführte Sortierung, deren geschätzte Kosten erheblich höher sind als die des Scans. Nun, die geschätzten Kosten sind nur geschätzt, und wir können hier nicht mit absoluter Sicherheit sagen, dass die Sortierung 79,6 % der Kosten der Abfrage gekostet hat. Um wirklich zu verstehen, wie teuer die Sortierung ist, müssten wir uns auch die IO-STATISTIK ansehen, was über das heutige Ziel hinausgeht.
Wenn dies nun eine Abfrage wäre, die in Ihrer Umgebung häufig ausgeführt wird, würden Sie wahrscheinlich erwägen, einen Index hinzuzufügen, um sie zu unterstützen. In diesem Fall gibt es keine WHERE-Klausel, wir rufen nur vier Spalten ab und sortieren nach einer davon. Ein logischer erster Versuch eines Index wäre:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Wir führen unsere Abfrage erneut aus, nachdem wir den Index hinzugefügt haben, der alle gewünschten Spalten enthält, und denken daran, dass der Index die Arbeit zum Sortieren der Daten erledigt hat. Wir sehen jetzt einen Index-Scan gegen unseren neuen Nonclustered-Index:
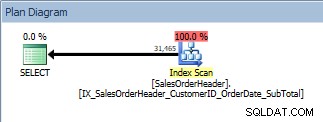 Abfrage mit ORDER BY, der neue, nicht gruppierte Index wird gescannt
Abfrage mit ORDER BY, der neue, nicht gruppierte Index wird gescannt
Das sind gute Neuigkeiten. Aber was passiert, wenn jemand diese Abfrage ändert – entweder weil Benutzer angeben können, nach welchen Spalten sie sortieren möchten, oder weil ein Entwickler eine Änderung angefordert hat? Vielleicht möchten Benutzer beispielsweise die CustomerIDs und SalesOrderIDs in absteigender Reihenfolge sehen:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
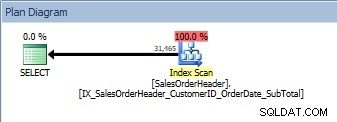 Abfrage mit zwei Spalten in ORDER BY, der neue, nicht gruppierte Index wird gescannt
Abfrage mit zwei Spalten in ORDER BY, der neue, nicht gruppierte Index wird gescannt
Wir haben den gleichen Plan; Es wurde kein Sort-Operator hinzugefügt. Wenn wir uns den Index mit Kimberly Tripps sp_helpindex ansehen (einige Spalten wurden aus Platzgründen zusammengeklappt), können wir sehen, warum sich der Plan nicht geändert hat:
 Ausgabe von sp_helpindex
Ausgabe von sp_helpindex
Die Schlüsselspalte für den Index ist CustomerID, aber da SalesOrderID die Schlüsselspalte für den gruppierten Index ist, ist sie auch Teil des Indexschlüssels, sodass die Daten nach CustomerID und dann SalesOrderID sortiert werden. Die Abfrage hat die nach diesen beiden Spalten sortierten Daten in absteigender Reihenfolge angefordert. Der Index wurde mit aufsteigenden Spalten erstellt, aber da es sich um eine doppelt verknüpfte Liste handelt, kann der Index rückwärts gelesen werden. Sie können dies im Eigenschaftenbereich in Management Studio für den Nonclustered-Index-Scan-Operator sehen:
 Eigenschaftenbereich des Nonclustered-Index-Scans, der anzeigt, dass er rückwärts war
Eigenschaftenbereich des Nonclustered-Index-Scans, der anzeigt, dass er rückwärts war
Großartig, keine Probleme mit dieser Abfrage ... aber was ist mit dieser hier:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
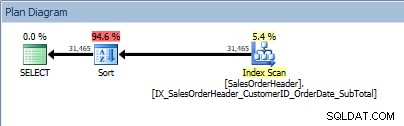 Abfrage mit zwei Spalten in ORDER BY, und eine Sortierung wird hinzugefügt
Abfrage mit zwei Spalten in ORDER BY, und eine Sortierung wird hinzugefügt
Unser SORT-Operator taucht wieder auf, weil die aus dem Index kommenden Daten nicht in der angeforderten Reihenfolge sortiert sind. Dasselbe Verhalten sehen wir, wenn wir nach einer der enthaltenen Spalten sortieren:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
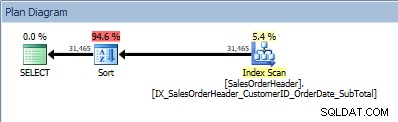 Abfrage mit zwei Spalten in ORDER BY, und eine Sortierung wird hinzugefügt
Abfrage mit zwei Spalten in ORDER BY, und eine Sortierung wird hinzugefügt
Was passiert, wenn wir (endlich) ein Prädikat hinzufügen und unsere ORDER BY leicht ändern?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
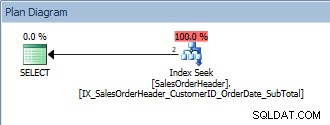 Abfrage mit einem einzelnen Prädikat und einem ORDER BY
Abfrage mit einem einzelnen Prädikat und einem ORDER BY
Diese Abfrage ist in Ordnung, da die SalesOrderID wiederum Teil des Indexschlüssels ist. Für diese eine CustomerID sind die Daten bereits nach SalesOrderID geordnet. Was passiert, wenn wir eine Reihe von CustomerIDs abfragen, sortiert nach SalesOrderIDs?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
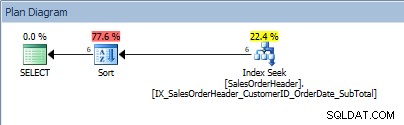 Abfrage mit einem Wertebereich im Prädikat und einem ORDER BY
Abfrage mit einem Wertebereich im Prädikat und einem ORDER BY
Ratten, unser SORT ist zurück. Die Tatsache, dass die Daten nach Kunden-ID geordnet sind, hilft nur bei der Suche nach dem Index, um diesen Wertebereich zu finden; für ORDER BY SalesOrderID muss der Optimierer Sort einfügen, um die Daten in die angeforderte Reihenfolge zu bringen.
An diesem Punkt fragen Sie sich vielleicht, warum ich auf den Sort-Operator fixiert bin, der in Abfrageplänen erscheint. Es ist, weil es teuer ist. Es kann in Bezug auf Ressourcen (Speicher, IO) und/oder Dauer teuer werden.
Die Abfragedauer kann durch eine Sortierung beeinflusst werden, da es sich um eine Stop-and-Go-Operation handelt. Der gesamte Datensatz muss sortiert werden, bevor die nächste Operation im Plan erfolgen kann. Wenn nur wenige Datenzeilen bestellt werden müssen, ist das nicht so schlimm. Wenn es Tausende oder Millionen Zeilen sind? Jetzt warten wir.
Neben der gesamten Abfragedauer müssen wir auch über die Ressourcennutzung nachdenken. Nehmen wir die 31.465 Zeilen, mit denen wir gearbeitet haben, und verschieben sie in eine Tabellenvariable. Führen Sie dann diese erste Abfrage mit ORDER BY auf CustomerID:
ausDECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
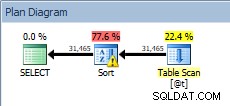 Fragen Sie die Tabellenvariable mit der Sortierung ab
Fragen Sie die Tabellenvariable mit der Sortierung ab
Unser SORT ist zurück, und dieses Mal hat es eine Warnung (beachten Sie das gelbe Dreieck mit dem Ausrufezeichen). Warnungen sind nicht gut. Wenn wir uns die Eigenschaften der Sorte ansehen, sehen wir die Warnung „Operator used tempdb to spill data during execute with spill level 1“:
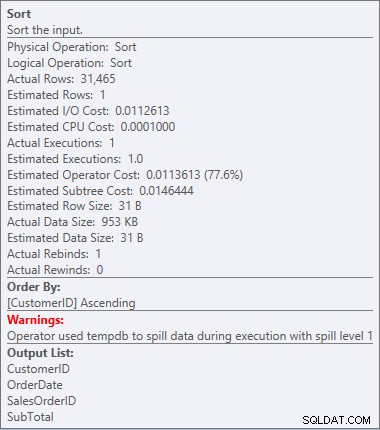 Sortierwarnung
Sortierwarnung
Das ist etwas, was ich nicht in einem Plan sehen möchte. Der Optimierer schätzte, wie viel Speicherplatz er zum Sortieren der Daten benötigen würde, und forderte diesen Speicher an. Aber als es tatsächlich alle Daten hatte und sie sortieren wollte, stellte die Engine fest, dass nicht genügend Speicher vorhanden war (der Optimierer verlangte zu wenig!), sodass die Sort-Operation verschüttet wurde. In einigen Fällen kann dies auf die Festplatte übergreifen, was Lese- und Schreibvorgänge bedeutet – die langsam sind. Wir warten nicht nur darauf, die Daten in Ordnung zu bringen, es ist sogar noch langsamer, weil wir nicht alles im Speicher erledigen können. Warum hat der Optimierer nicht nach genügend Speicher gefragt? Es hatte eine schlechte Schätzung bezüglich der Daten, die es zum Sortieren benötigte:
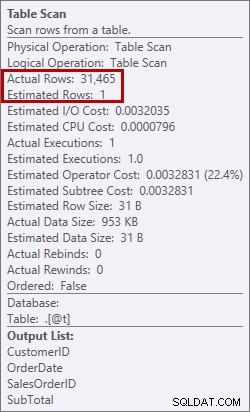 Schätzung von 1 Zeile im Vergleich zu tatsächlichen 31.465 Zeilen
Schätzung von 1 Zeile im Vergleich zu tatsächlichen 31.465 Zeilen
In diesem Fall habe ich eine schlechte Schätzung erzwungen, indem ich eine Tabellenvariable verwendet habe. Es gibt bekannte Probleme mit statistischen Schätzungen und Tabellenvariablen (Aaron Bertrand hat einen großartigen Beitrag zu Optionen veröffentlicht, um dies zu beheben), und hier glaubte der Optimierer, dass nur eine Zeile vom Tabellenscan zurückgegeben würde, nicht 31.465.
Optionen
Was können Sie also als DBA oder Entwickler tun, um SORTs in Ihren Abfrageplänen zu vermeiden? Die schnelle Antwort lautet:"Ordnen Sie Ihre Daten nicht." Aber das ist nicht immer realistisch. In einigen Fällen können Sie diese Sortierung auf den Client oder auf eine Anwendungsschicht auslagern – aber Benutzer müssen immer noch warten, um die Daten dort zu sortieren Schicht. In den Situationen, in denen Sie die Funktionsweise der Anwendung nicht ändern können, können Sie damit beginnen, sich Ihre Indizes anzusehen.
Wenn Sie eine Anwendung unterstützen, die es Benutzern ermöglicht, Ad-hoc-Abfragen auszuführen oder die Sortierreihenfolge zu ändern, damit sie die Daten in der gewünschten Reihenfolge sehen können, werden Sie es am schwersten haben (aber es ist keine verlorene Sache). hören Sie noch nicht auf zu lesen!). Sie können nicht für jede Option indexieren. Es ist ineffizient und Sie werden mehr Probleme schaffen als lösen. Am besten sprechen Sie hier mit den Benutzern (ich weiß, manchmal ist es beängstigend, Ihre Ecke des Waldes zu verlassen, aber versuchen Sie es). Finden Sie für die Abfragen, die die Benutzer am häufigsten ausführen, heraus, wie sie die Daten normalerweise sehen möchten. Ja, Sie können dies auch aus dem Plan-Cache abrufen – Sie können nach Herzenslust Abfragen und Pläne abrufen, um zu sehen, was sie tun. Aber es ist schneller, mit den Benutzern zu sprechen. Der zusätzliche Vorteil ist, dass Sie erklären können, warum Sie fragen, und warum diese Idee, „alle Spalten zu sortieren, weil ich kann“, nicht so gut ist. Wissen ist die halbe Miete. Wenn Sie einige Zeit damit verbringen können, Ihre Hauptbenutzer und die Benutzer, die neue Leute schulen, zu schulen, können Sie vielleicht etwas Gutes tun.
Wenn Sie eine Anwendung mit eingeschränkten ORDER BY-Optionen unterstützen, können Sie eine echte Analyse durchführen. Überprüfen Sie, welche ORDER BY-Variationen vorhanden sind, bestimmen Sie, welche Kombinationen am häufigsten ausgeführt werden, und indizieren Sie, um diese Abfragen zu unterstützen. Sie werden wahrscheinlich nicht jeden treffen, aber Sie können immer noch etwas bewirken. Sie können noch einen Schritt weiter gehen, indem Sie mit Ihren Entwicklern sprechen und sie über das Problem und dessen Lösung informieren.
Wenn Sie sich schließlich Abfragepläne mit SORT-Vorgängen ansehen, konzentrieren Sie sich nicht nur darauf, die Sortierung zu entfernen. Sehen Sie sich wo an die Sortierung erfolgt im Plan. Wenn es ganz links im Plan passiert und typisch ist ein paar Reihen, kann es andere Bereiche mit einem größeren Verbesserungsfaktor geben, auf die man sich konzentrieren sollte. Das Sortieren auf der linken Seite ist das Muster, auf das wir uns heute konzentriert haben, aber ein Sortieren erfolgt nicht immer aufgrund eines ORDER BY. Wenn Sie ganz rechts im Plan eine Sortierung sehen und sich viele Zeilen durch diesen Teil des Plans bewegen, wissen Sie, dass Sie einen guten Ort gefunden haben, um mit der Optimierung zu beginnen.