Um die Liste der Felder zu erhalten, für die es mehrere Datensätze gibt, können Sie verwenden..
select field1,field2,field3, count(*)
from table_name
group by field1,field2,field3
having count(*) > 1
Unter diesem Link finden Sie weitere Informationen zum Löschen der Zeilen.
https://support.microsoft.com/kb/139444
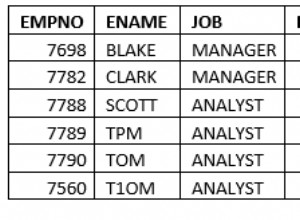
Es sollte ein Entscheidungskriterium geben, wie Sie "erste Zeilen" definieren, bevor Sie den Ansatz im obigen Link verwenden. Auf dieser Grundlage müssen Sie bei Bedarf eine order by-Klausel und eine Unterabfrage verwenden. Wenn Sie einige Beispieldaten posten könnten, wäre das wirklich hilfreich.