Tabellenwertparameter gibt es seit SQL Server 2008 und bieten einen nützlichen Mechanismus zum Senden mehrerer Datenzeilen an SQL Server, die in einem einzelnen parametrisierten Aufruf zusammengefasst werden. Alle Zeilen sind dann in einer Tabellenvariablen verfügbar, die dann in der Standard-T-SQL-Codierung verwendet werden kann, wodurch die Notwendigkeit entfällt, eine spezialisierte Verarbeitungslogik zum erneuten Aufschlüsseln der Daten zu schreiben. Aufgrund ihrer Definition sind Tabellenwertparameter stark auf einen benutzerdefinierten Tabellentyp typisiert, der in der Datenbank vorhanden sein muss, in der der Aufruf erfolgt. Allerdings ist stark typisiert nicht wirklich streng „stark typisiert“, wie Sie erwarten würden, wie dieser Artikel demonstrieren wird, und die Leistung könnte dadurch beeinträchtigt werden.
Um die potenziellen Auswirkungen auf die Leistung von falsch typisierten Tabellenwertparametern mit SQL Server zu demonstrieren, erstellen wir einen benutzerdefinierten Beispieltabellentyp mit der folgenden Struktur:
CREATE TYPE dbo.PharmacyData AS TABLE ( Dosage int, Drug varchar(20), FirstName varchar(50), LastName varchar(50), AddressLine1 varchar(250), PhoneNumber varchar(50), CellNumber varchar(50), EmailAddress varchar(100), FillDate datetime );
Dann benötigen wir eine .NET-Anwendung, die diesen benutzerdefinierten Tabellentyp als Eingabeparameter zum Übergeben von Daten an SQL Server verwendet. Um einen Tabellenwertparameter aus unserer Anwendung zu verwenden, wird normalerweise ein DataTable-Objekt ausgefüllt und dann als Wert für den Parameter mit dem Typ SqlDbType.Structured übergeben. Die DataTable kann im .NET-Code auf mehrere Arten erstellt werden, aber eine gängige Methode zum Erstellen der Tabelle ist etwa die folgende:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData");
DefaultTable.Columns.Add("Dosage", typeof(int));
DefaultTable.Columns.Add("Drug", typeof(string));
DefaultTable.Columns.Add("FirstName", typeof(string));
DefaultTable.Columns.Add("LastName", typeof(string));
DefaultTable.Columns.Add("AddressLine1", typeof(string));
DefaultTable.Columns.Add("PhoneNumber", typeof(string));
DefaultTable.Columns.Add("CellNumber", typeof(string));
DefaultTable.Columns.Add("EmailAddress", typeof(string));
DefaultTable.Columns.Add("Date", typeof(DateTime)); Sie können die DataTable auch mithilfe der Inline-Definition wie folgt erstellen:
System.Data.DataTable DefaultTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{"Dosage", typeof(int)},
{"Drug", typeof(string)},
{"FirstName", typeof(string)},
{"LastName", typeof(string)},
{"AddressLine1", typeof(string)},
{"PhoneNumber", typeof(string)},
{"CellNumber", typeof(string)},
{"EmailAddress", typeof(string)},
{"Date", typeof(DateTime)},
},
Locale = CultureInfo.InvariantCulture
}; Jede dieser Definitionen des DataTable-Objekts in .NET kann als Tabellenwertparameter für den benutzerdefinierten Datentyp verwendet werden, der erstellt wurde, aber beachten Sie die typeof(string)-Definition für die verschiedenen Zeichenfolgenspalten; Diese können alle „richtig“ typisiert sein, aber sie sind nicht wirklich stark auf die Datentypen typisiert, die im benutzerdefinierten Datentyp implementiert sind. Wir können die Tabelle mit zufälligen Daten füllen und sie als Parameter einer sehr einfachen SELECT-Anweisung an SQL Server übergeben, die genau die gleichen Zeilen zurückgibt wie die Tabelle, die wir übergeben haben, wie folgt:
using (SqlCommand cmd = new SqlCommand("SELECT * FROM @tvp;", connection))
{
var pList = new SqlParameter("@tvp", SqlDbType.Structured);
pList.TypeName = "dbo.PharmacyData";
pList.Value = DefaultTable;
cmd.Parameters.Add(pList);
cmd.ExecuteReader().Dispose();
} Wir können dann einen Debug-Break verwenden, damit wir die Definition von DefaultTable während der Ausführung überprüfen können, wie unten gezeigt:
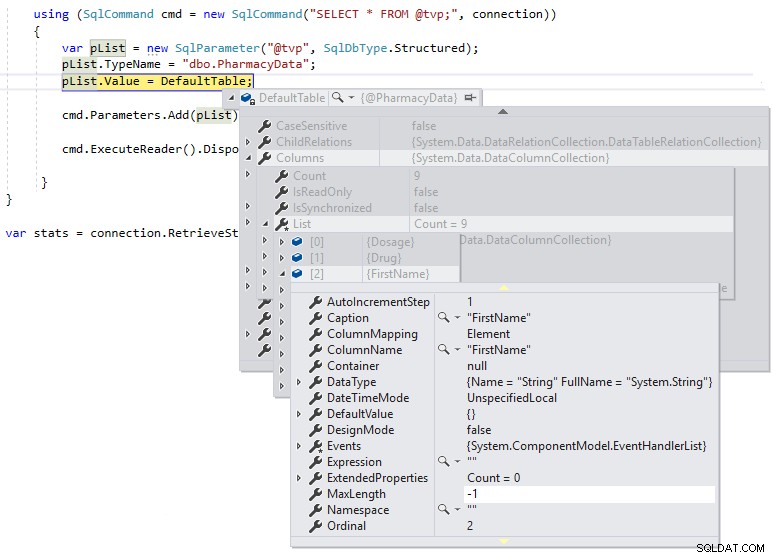
Wir können sehen, dass MaxLength für die Zeichenfolgenspalten auf -1 festgelegt ist, was bedeutet, dass sie als LOBs (Large Objects) oder im Wesentlichen als MAX-Datentyp-Spalten über TDS an SQL Server übergeben werden, was sich negativ auf die Leistung auswirken kann. Wenn wir die .NET-DataTable-Definition so ändern, dass sie wie folgt in die Schemadefinition des benutzerdefinierten Tabellentyps stark typisiert ist, und die MaxLength derselben Spalte mit einem Debug-Umbruch betrachten:
System.Data.DataTable SchemaTable = new System.Data.DataTable("@PharmacyData")
{
Columns =
{
{new DataColumn() { ColumnName = "Dosage", DataType = typeof(int)} },
{new DataColumn() { ColumnName = "Drug", DataType = typeof(string), MaxLength = 20} },
{new DataColumn() { ColumnName = "FirstName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "LastName", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "AddressLine1", DataType = typeof(string), MaxLength = 250} },
{new DataColumn() { ColumnName = "PhoneNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "CellNumber", DataType = typeof(string), MaxLength = 50} },
{new DataColumn() { ColumnName = "EmailAddress", DataType = typeof(string), MaxLength = 100} },
{new DataColumn() { ColumnName = "Date", DataType = typeof(DateTime)} },
},
Locale = CultureInfo.InvariantCulture
};
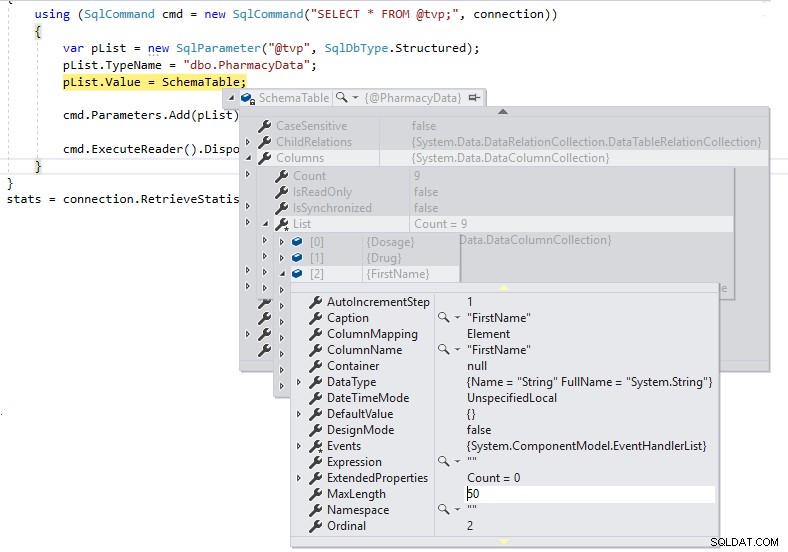
Wir haben jetzt die richtigen Längen für die Spaltendefinitionen und werden sie nicht als LOBs über TDS an SQL Server übergeben.
Wie wirkt sich das auf die Leistung aus, fragen Sie sich vielleicht? Dies wirkt sich auf die Anzahl der TDS-Puffer aus, die über das Netzwerk an SQL Server gesendet werden, und wirkt sich auch auf die Gesamtverarbeitungszeit für die Befehle aus.
Die Verwendung des exakt gleichen Datensatzes für die beiden Datentabellen und die Nutzung der RetrieveStatistics-Methode für das SqlConnection-Objekt ermöglicht es uns, die ExecutionTime- und BuffersSent-Statistikmetriken für die Aufrufe desselben SELECT-Befehls abzurufen und einfach die zwei verschiedenen DataTable-Definitionen als Parameter zu verwenden und durch Aufrufen der Methode ResetStatistics des SqlConnection-Objekts können die Ausführungsstatistiken zwischen den Tests gelöscht werden.
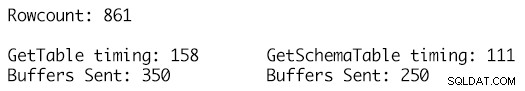
Die GetSchemaTable-Definition gibt die MaxLength für jede der Zeichenfolgenspalten korrekt an, wobei GetTable nur Spalten vom Typ Zeichenfolge hinzufügt, deren MaxLength-Wert auf -1 festgelegt ist, was dazu führt, dass 100 zusätzliche TDS-Puffer für 861 Datenzeilen in der Tabelle und eine Laufzeit von gesendet werden 158 Millisekunden im Vergleich zu nur 250 Puffern, die für die stark typisierte DataTable-Definition und einer Laufzeit von 111 Millisekunden gesendet werden. Auch wenn dies im Großen und Ganzen nicht viel erscheinen mag, handelt es sich um einen einzigen Anruf, eine einzige Ausführung, und die kumulierten Auswirkungen im Laufe der Zeit für viele Tausende oder Millionen solcher Ausführungen sind der Punkt, an dem sich die Vorteile summieren und eine spürbare Auswirkung haben auf Workload-Leistung und Durchsatz.
Wo dies wirklich einen Unterschied machen kann, sind Cloud-Implementierungen, bei denen Sie für mehr als nur Rechen- und Speicherressourcen bezahlen. Zusätzlich zu den Fixkosten für Hardwareressourcen für Azure VM, SQL-Datenbank oder AWS EC2 oder RDS fallen zusätzliche Kosten für den Netzwerkdatenverkehr zu und von der Cloud an, die der monatlichen Abrechnung hinzugefügt werden. Durch die Reduzierung der Puffer, die über die Leitung gehen, werden die Gesamtbetriebskosten für die Lösung im Laufe der Zeit gesenkt, und die Codeänderungen, die zur Implementierung dieser Einsparungen erforderlich sind, sind relativ einfach.



