Als Teil des Oracle SQL-Lernprogramms finden Sie hier gute Details zur Gruppierung nach Oracle
Gruppenfunktionen arbeiten im Gegensatz zu Einzelwertfunktionen auf dem Satz von Zeilen und geben eine Zeile pro Gruppe zurück. Der Zeilensatz kann eine ganze Tabelle oder die in Gruppen aufgeteilte Tabelle sein
Arten von Gruppenfunktionen in Oracle umfassen:
| AVG([Distinct/all] n) | Nur numerische Datentypen. Der Durchschnittswert der Spalte n, wobei Nullwerte ignoriert werden |
| COUNT({*/[Distinct/all]expr}) | Es ist nur eine Gruppenfunktion, die Nullwerte enthält. Es zählt die Anzahl der Zeilen in der select-Anweisung, die die where-Klausel erfüllt. Count(*) enthält alle Null- und Duplikatwerte |
| MAX([Distinct/all] expr) | Es kann mit jedem Datentyp verwendet werden. Es gibt den maximalen Wert von expr an, wobei Nullwerte ignoriert werden |
| MIN([Distinct/all] expr) | Es kann mit jedem Datentyp verwendet werden. . Es gibt einen Mindestwert von expr an, wobei Nullwerte ignoriert werden |
| STDDEV([Eindeutig/alle] n) | Nur numerische Datentypen. Es ergibt eine Standardabweichung von n, wobei Nullwerte ignoriert werden |
| SUMME ([Eindeutig/alle] n) | Nur numerische Datentypen und keine anderen arithmetischen Operatoren in der Funktion. Sie liefert die Summe von n, wobei Nullwerte ignoriert werden |
| VARIANCE([Eindeutig/alle] n) | Nur numerische Datentypen. Es gibt eine Varianz von n, wobei Nullwerte ignoriert werden |
Syntax:
SELECT col1, col2, … col_n, aggregate_function (aggregate_expression) FROM tables [WHERE conditions] GROUP BY col1, col2, … col_n Having group condition;
Der Oracle-Server hat die folgenden Schritte ausgeführt
- Zuerst werden die Zeilen basierend auf der Where-Klausel ausgewählt
- Zeilen werden gruppiert
- Die Gruppenfunktion wird auf jede Gruppe angewendet
- Die Gruppe, die dem Kriterium in der Having-Klausel entspricht, wird angezeigt
Daher wird zuerst die WHERE-Klausel ausgewertet (schränkt die Abfrageergebnisse ein), dann die GROUP BY-Klausel (gruppiert die Ergebnisse von WHERE), dann die HAVING-Klausel (weitere Einschränkung der Ergebnisse durch Einschränkung der zurückgegebenen Gruppen).
Einige wichtige Punkte zur Gruppierung nach Orakel
(1) GROUP BY:Zerlegt die Ergebnisse von Gruppenfunktionen aus einer großen Datentabelle in kleinere logische Gruppierungen.
(2) Die WHERE-Klausel kann eine Gruppe nicht einschränken, verwenden Sie also die HAVING-Klausel.
(3) Verwenden Sie den Spaltenalias nicht in der GROUP BY-Klausel.
(4) HAVING:Beschränkt die Anzeige von Gruppen auf diejenigen, die die angegebenen Bedingungen „haben“.
(5) Die NVL-Funktion ermöglicht es einer GROUP BY-Funktion, Nullwerte in ihre Berechnung aufzunehmen.
(6) Alle Spalten oder Ausdrücke in der Auswahlliste, die keine Aggregatfunktion sind, müssen in der group by-Klausel
enthalten seinBeispiele für Gruppenfunktionen in Oracle
Lassen Sie uns zuerst die Beispieltabellen erstellen und dann die Gruppierung nach Oracle sql
ausprobierenCREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
insert into emp values( 7698, 'Blake', 'MANAGER', 7839, to_date('1-5-2007','dd-mm-yyyy'), 2850, null, 10 );
insert into emp values( 7782, 'Clark', 'MANAGER', 7839, to_date('9-6-2008','dd-mm-yyyy'), 2450, null, 10 );
insert into emp values( 7788, 'Scott', 'ANALYST', 7566, to_date('9-6-2012','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7789, 'TPM', 'ANALYST', 7566, to_date('9-6-2017','dd-mm-yyyy'), 3000, null, null );
insert into emp values( 7560, 'T1OM', 'ANALYST', 7567, to_date('9-7-2017','dd-mm-yyyy'), 4000, null, 20 );
insert into emp values( 7790, 'TOM', 'ANALYST', 7567, to_date('9-7-2017','dd-mm-yyyy'), 4000, null, null );
commit;
Select * from emp; 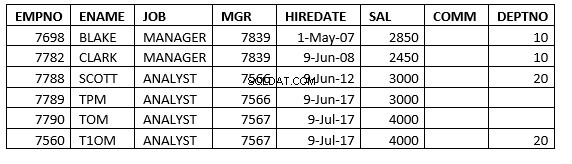
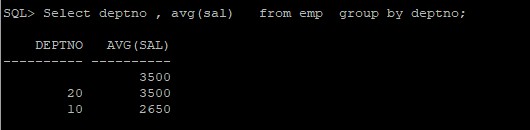
Eine Spalte
Select dept , avg(sal) from emp group by dept;
Mehrspaltig
Select deptno ,job, sum(sal) from emp group by deptno,job

Zählfunktion
SELECT dept, COUNT(*) AS "Np of employees" FROM emp WHERE sal < 15000
GROUP BY dept;
Min-Funktion
SELECT dept, MIN(sal) AS "Lowest salary" FROM emp
GROUP BY dept;
Ich hoffe, Ihnen gefällt dieser Artikel
Verwandte Artikel
Analytische Funktionen in Oracle:Oracle Analytische Funktionen berechnen einen aggregierten Wert basierend auf einer Gruppe von Zeilen, indem sie die Klausel over partition by oracle verwenden, sie unterscheiden sich von aggregierten Funktionen
Rang in Oracle:RANK, DENSE_RANK und ROW_NUMBER sind orakelanalytisch Funktion, die verwendet wird, um Zeilen in der Gruppe von Zeilen mit dem Namen Fenster zu ordnen br/>Top-N-Abfragen in Oracle:Schauen Sie sich diese Seite an, um die verschiedenen Möglichkeiten zu erkunden, Top-N-Abfragen in Oracle und Paginierung in Oracle-Abfragen und Oracle-Datenbanken zu erreichen.