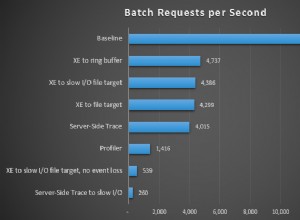
Wenn Server ausfallen, kann dies zu Unterbrechungen Ihrer Geschäftsziele und zu Umsatzeinbußen führen. Beispielsweise kann eine Fluggesellschaft möglicherweise keine Flüge für Kunden buchen, wenn Instanzen und Datenbanken nicht verfügbar sind. Systeme können aus einer Vielzahl von Gründen ausfallen, z. B. Feuer, menschliche Fehler, Computerausfälle, Festplattenausfälle und Programmierfehler.
Um Unterbrechungen zu vermeiden und die Kontinuität der Geschäftsdienste sicherzustellen, ist es äußerst wichtig, Strategien für Hochverfügbarkeit (HA) und Notfallwiederherstellung (DR) zu haben. HA und DR werden oft zusammen diskutiert. HA kümmert sich darum, Serverausfallzeiten so weit wie möglich zu reduzieren, aber da kein System perfekt ist, konzentriert sich DR auf den Prozess der Verwendung der Sicherungsmedien zur Wiederherstellung verlorener Daten, falls das Datenbanksystem ausfällt.
AlwaysOn ist ein Marken-/Marketingbegriff, der seit SQL Server 2012 verwendet wird, um die erweiterten HADR-Funktionen von Microsoft zu beschreiben. Vor AlwaysOn unterstützte die Datenbank-Engine andere integrierte proprietäre Lösungen wie Datenbankspiegelung, Failover-Cluster und Protokollversand. Jede dieser Techniken hatte jedoch Vor- und Nachteile. Abhängig von ihren Zielen musste eine Organisation oft mehrere Methoden miteinander kombinieren, um eine wünschenswerte HADR-Strategie zu erreichen.
AlwaysOn-Funktionen wurden eingeführt, damit Sie keine zusätzliche Zeit und Ressourcen für die Implementierung und Komplexität der Bereitstellung aufwenden müssen, um sowohl Server- als auch Datenbankredundanz zu berücksichtigen, auf Probleme mit der Skalierung zu stoßen oder über Standby-Hardware zu verfügen, die nicht effizient genutzt wird. Diese Funktionen vereinen bequem viele der alten Praktiken und verbessern Bereiche, in denen sie zu kurz gekommen sind. Um den Wert von AlwaysOn-Angeboten wirklich zu verstehen, ist es wichtig, die anfänglichen grundlegenden Konzepte zu überdenken, wie die Datenbank-Engine System-HADR in der Vergangenheit sichergestellt hat.
Datenbankspiegelung
Datenbankredundanz kann durch Spiegelung erreicht werden. Beispielsweise können Sie eine umsatzgenerierende Front-End-Client-App haben, mit der Schüler Lehrbücher online bestellen können. Ein Kunde wählt seinen Kauf aus und Anfragen werden an die PsychologyBooks-Datenbank im Back-End gestellt. Im Falle einer Katastrophe, die dazu führt, dass die PsychologyBooks-Datenbank nicht verfügbar ist, kann der Schüler seine Bestellung nicht abschließen.
Um diese Unterbrechung zu vermeiden, können Sie eine Hauptinstanz in der Produktion bereitstellen, die die PsychologyBooks-Datenbank enthält, und eine zusätzliche Kopie dieser PsychologyBooks-Datenbank auf einem gespiegelten Server im Standby-Modus haben. Client-Apps können sich wieder mit der gespiegelten Kopie verbinden, anstatt eine Unterbrechung zu erfahren und warten zu müssen, bis die Wiederherstellung auf der primären Kopie abgeschlossen ist. Die Kopie hält mit den am Original vorgenommenen Änderungen Schritt, indem sie Transaktionsprotokolle empfängt und diese aufgezeichneten Änderungen dann wiederholt.
Spiegelungssitzungen können je nach Leistung oder hohen Sicherheitsgründen in verschiedenen Modi betrieben werden. Praktischerweise wird ein automatisches Failover unterstützt, wenn die Spiegelungssitzung im hochsicheren synchronen Modus betrieben wird und ein Quorum-Konsens mit dem Vorhandensein eines optionalen Zeugenservers hergestellt wird.
Trotz der Vorteile der Spiegelung greift sie zu kurz, da sie nur Datenbankredundanz bietet, keine Serverredundanz. Das heißt, wenn die primäre Serverinstanz ausfällt, fallen beide Instanzen aus, und es spielt keine Rolle, dass es eine Ersatzkopie der Daten auf Datenbankebene gibt. Die Standby-Instanz unterstützt keine Benutzervorgänge, und Snapshots wären erforderlich, um eine schreibgeschützte Kopie der Daten auf der gespiegelten Instanz zu erhalten. Die Datenbank ist geschützt, die Objekte auf Serverebene, wie z. B. Serverrollenmitgliedschaft, Anmeldeinformationen und Agentenjobs, jedoch nicht.
Wenn es beispielsweise ein großes Marketingteam gäbe und jedes Mitglied sein eigenes Login hätte, müssten sie den Prozess der Neuerstellung der Logins für jede Person noch einmal durchlaufen. Wenn ein Failover auftritt, erfolgt es auf einer unabhängigen Datenbankbasis und nicht als Gruppe.
Failover-Clustering
Failover-Clustering bietet Redundanz auf Instanzebene und bietet Schutz vor Hardware- und Betriebssystemausfällen. Angenommen, ein Knoten in Queen Anne fängt Feuer und verursacht einen Geräteausfall. Die gesamte Instanz – die Objekte auf Instanzebene umfasst, wie z. B. Anmeldungen oder bestimmte Jobs, die zur Ausführung bestimmter Aufgaben erstellt wurden – wird geschützt und kann automatisch auf einem anderen zum Cluster gehörenden Knoten neu gestartet werden. Client-Apps und -Dienste werden den Kunden weiterhin zur Verfügung stehen.
Das obige Szenario funktioniert, da der Speicher von redundanten physischen Servern in einer Windows Server-Failoverclustergruppe (WSFC) gemeinsam genutzt wird. Sowohl das Betriebssystem als auch SQL Server arbeiten zusammen, sodass jeweils nur ein Knoten die WSFC-Ressourcengruppe besitzt.
Leider bietet diese Lösung mit einem gemeinsamen Speicher nicht die Datenbankredundanz, die die frühere Spiegelungsstrategie bot. Ein gemeinsam genutzter Speicher birgt Risiken, da er zu einem Single Point of Failure führt. Die externen Festplatten können beispielsweise die einzige Kopie der wichtigen PsychologyBooks-Datenbank enthalten, und obwohl die Instanz erfolgreich auf den Ballard-Knoten umgeschaltet wurde, würde es immer noch zu einer Unterbrechung der Geschäftsziele kommen, wenn die einzige Speicherkomponente kompromittiert würde. Failover-Clustering schlägt auch Einschränkungen in Bezug auf die Skalierbarkeit vor, da Client-Apps nicht in der Lage sind, eine wachsende Arbeitsmenge zu bewältigen, die sich über den Cluster hinaus ausdehnt.
Protokollversand
Eine weitere Methode zum Erzielen von Datenbankredundanz ist der Protokollversand. Transaktionsprotokolle werden auf dem primären Server gesichert und zur Wiederherstellung an einen oder mehrere sekundäre Server gesendet. Im Gegensatz zur Spiegelung können die sekundären Datenbanken für schreibgeschützte Aktivitäten geeignet sein, und die Häufigkeit des Protokollversands kann für unterschiedliche Intervalle konfiguriert werden. In Szenarien, in denen sekundäre Datenbanken nicht unbedingt in Echtzeit mit der primären Datenbank synchronisiert werden müssen, ergibt sich ein Leistungsvorteil.
Wenn Sie beispielsweise am Ende der Nacht einen statistischen Zusammenfassungsbericht ausführen, um zu sehen, welche Psychologiebücher den ganzen Tag über verkauft werden, muss die Kopiedatenbank nicht genau mit der Primärdatenbank synchronisiert sein. Leseintensive Aktivitäten sperren Datenbankobjekte und können Wartezeiten in die Höhe treiben. Daher würde die Ausführung der Berichterstellung auf einem sekundären Server die Arbeitsbelastung auf dem primären umsatzgenerierenden Server verringern.
Der Nachteil besteht darin, dass der Protokollversand kein automatisches Failover unterstützt. Wenn der Quellserver ausfällt, muss die Datenbank daher manuell wiederhergestellt werden. Wie die Spiegelung bietet auch der Protokollversand keine Serverredundanz und ist eine Lösung auf Datenbankebene.
AlwaysOn verstehen
Alte Technologien haben jeweils ihre Vorteile und Kompromisse. Die Implementierung einer angepassten HADR-Lösung kann jedoch schnell kompliziert werden und mehr Management erfordern, da diese verschiedenen Strategien willkürlich gemischt und aufeinander abgestimmt werden, um die Geschäftsanforderungen zu erfüllen. Daher wurden die AlwaysOn-Features eingeführt und bieten eine erweiterte, bereits kombinierte Version bisheriger Strategien.
SQL Server bietet zwei Funktionen:AlwaysOn-Verfügbarkeitsgruppen (AG) und AlwaysOn-Failoverclusterinstanzen (FCI). Beide erfordern die Implementierung von Windows Server Failover Clustering (WSFC).

Eine AG ist eine Gruppe von Datenbanken, für die ein gemeinsames Failover durchgeführt wird. Sie benötigen mehrere redundante physische Knoten, auf denen jeweils eine SQL Server-Instanz installiert ist, um die Verfügbarkeitsreplikate zu hosten. Jedes Replikat muss sich auf einem anderen Knoten desselben WSFC befinden. Im obigen Schema wird das primäre Replikat auf Knoten 01 gehostet, und alle anderen sekundären Replikate sind für ein Failover geeignet, wenn WSFC erkennt, dass ein Problem vorliegt.
Die Art und Weise, wie die sekundären Replikate mit den primären Replikaten synchron bleiben, besteht darin, Transaktionsprotokolle zu senden und die Änderungen zu wiederholen. AG unterstützt sowohl den asynchronen als auch den synchronen Commit-Modus. Das primäre Replikat ist zum Lesen und Schreiben berechtigt, während die sekundären Replikate nur zum Lesen berechtigt sind. Sicherungen können am sekundären Standort durchgeführt werden.
Ab sofort gibt es Vorteile bei der AlwaysOn AG. Erinnern Sie sich an früher, dass einige der Mängel bei der Datenbankspiegelung darin bestehen, dass eine Datenbank nur auf einen sekundären Server gespiegelt werden kann und dass bei einem Failover jede Datenbank unabhängig gespiegelt wird. Mit AG werden an vielen Stellen Datenbanken redundant gemacht, wie im obigen Beispiel Node 02, Node 03, Node 04 und Node 05. Die Unterstützung der Datenbankverfügbarkeit ermöglicht bis zu neun Verfügbarkeitsreplikate.
Darüber hinaus wäre ein Protokollversand erforderlich, um schreibgeschützte Daten auf dem sekundären Server zu erreichen. Aber mit AG werden schreibgeschützte Daten bereits berücksichtigt. Leseintensive Aktivitäten wie die Berichterstellung können auf allen sekundären Replikaten ausgeführt werden. Beachten Sie auch, dass es keine Einschränkung für gemeinsam genutzten Speicher gibt.
AG kann jedoch mit AlwaysOn FCI kombiniert werden, um Serverredundanz zu ermöglichen. Eine FCI-Instanz kann verwendet werden, um die Verfügbarkeitsrepliken zu hosten, sodass Objekte auf Serverebene wie Anmeldungen und Agentenjobs ebenfalls geschützt werden können. Dieser Ansatz erfordert gemeinsam genutzten Speicher. Unannehmlichkeiten wie die Notwendigkeit, Neukonfigurationen für die Client-Apps durchzuführen, werden jedoch eliminiert.