Benjamin Nevarez ist ein unabhängiger Berater mit Sitz in Los Angeles, Kalifornien, der sich auf die Optimierung und Optimierung von SQL Server-Abfragen spezialisiert hat. Er ist Autor von „SQL Server 2014 Query Tuning &Optimization“ und „Inside the SQL Server Query Optimizer“ und Co-Autor von „SQL Server 2012 Internals“. Mit mehr als 20 Jahren Erfahrung in relationalen Datenbanken war Benjamin auch Redner auf vielen SQL Server-Konferenzen, darunter PASS Summit, SQL Server Connections und SQLBits. Benjamins Blog ist unter https://www.benjaminnevarez.com zu finden und er kann auch per E-Mail unter admin at benjaminnevarez dot com und auf Twitter unter @BenjaminNevarez erreicht werden.
Während sich die meisten Informationen, Blogs und Dokumentationen zu SQL Server 2014 auf Hekaton und andere neue Features konzentriert haben, wurden nicht viele Details zum neuen Kardinalitätsschätzer bereitgestellt. Derzeit spricht BOL nur indirekt im Abschnitt What’s New (Database Engine) darüber und sagt, dass SQL Server 2014 „wesentliche Verbesserungen an der Komponente enthält, die Abfragepläne erstellt und optimiert“ und ALTER DATABASE -Anweisung zeigt, wie sein Verhalten aktiviert oder deaktiviert wird. Glücklicherweise können wir einige zusätzliche Informationen erhalten, indem wir das Forschungspapier Testing Cardinality Estimation Models in SQL Server von Campbell Fraser et al. lesen. Obwohl der Schwerpunkt des Papiers auf dem Qualitätssicherungsprozess des neuen Schätzmodells liegt, bietet es auch eine grundlegende Einführung in den neuen Kardinalitätsschätzer und die Motivation für seine Neugestaltung.
Was ist also ein Kardinalitätsschätzer? Ein Kardinalitätsschätzer ist die Komponente des Abfrageprozessors, deren Aufgabe darin besteht, die Anzahl der Zeilen zu schätzen, die von relationalen Operationen in einer Abfrage zurückgegeben werden. Diese Informationen werden zusammen mit einigen anderen Daten vom Abfrageoptimierer verwendet, um einen effizienten Ausführungsplan auszuwählen. Die Kardinalitätsschätzung ist von Natur aus ungenau, da es sich um ein mathematisches Modell handelt, das auf statistischen Informationen beruht. Es basiert auch auf mehreren Annahmen, die, obwohl nicht dokumentiert, im Laufe der Jahre bekannt waren – einige von ihnen beinhalten die Annahmen zur Einheitlichkeit, Unabhängigkeit, Eindämmung und Einbeziehung. Eine kurze Beschreibung dieser Annahmen folgt.
- Einheitlichkeit . Wird verwendet, wenn die Verteilung für ein Attribut unbekannt ist, z. B. innerhalb von Bereichszeilen in einem Histogrammschritt oder wenn kein Histogramm verfügbar ist.
- Unabhängigkeit . Wird verwendet, wenn die Attribute in einer Beziehung unabhängig sind, es sei denn, eine Korrelation zwischen ihnen ist bekannt.
- Eindämmung . Wird verwendet, wenn zwei Attribute gleich sein könnten, es wird davon ausgegangen, dass sie gleich sind.
- Inklusion . Wird verwendet, wenn ein Attribut mit einer Konstante verglichen wird, es wird angenommen, dass es immer eine Übereinstimmung gibt.
Es ist interessant, dass ich erst kürzlich in meinem letzten Vortrag auf dem PASS Summit mit dem Titel „Defeating the Limitations of the Query Optimizer“ über einige der Einschränkungen dieser Annahmen gesprochen habe. Ich war jedoch überrascht, in dem Papier zu lesen, dass die Autoren einräumen, dass diese Annahmen nach ihrer Praxiserfahrung „häufig falsch“ sind.
Der aktuelle Kardinalitätsschätzer wurde zusammen mit dem gesamten Abfrageprozessor für SQL Server 7.0 geschrieben, der bereits im Dezember 1998 veröffentlicht wurde. Offensichtlich wurde diese Komponente im Laufe mehrerer Jahre und mehrerer Versionen von SQL Server mehrfach geändert, einschließlich Korrekturen, Anpassungen und Erweiterungen Anpassung der Kardinalitätsschätzung für neue T-SQL-Features. Sie fragen sich vielleicht, warum eine Komponente ersetzen, die seit etwa 15 Jahren erfolgreich im Einsatz ist?
Warum ein neuer Kardinalitätsschätzer
Das Papier erläutert einige der Gründe für die Neugestaltung, darunter:
- Um den Kardinalitätsschätzer an neue Arbeitslastmuster anzupassen.
- Im Laufe der Jahre am Kardinalitätsschätzer vorgenommene Änderungen erschwerten das „Debuggen, Vorhersagen und Verstehen“ der Komponente
- Der Versuch, das aktuelle Modell zu verbessern, war mit der aktuellen Architektur schwierig, daher wurde ein neues Design erstellt, das sich auf die Trennung der Aufgaben konzentrierte, nämlich (a) zu entscheiden, wie eine bestimmte Schätzung zu berechnen ist, und (b) die Berechnung tatsächlich durchzuführen .
Ich bin mir nicht sicher, ob weitere Details über den neuen Kardinalitätsschätzer von Microsoft veröffentlicht werden. Schließlich wurden in 15 Jahren nicht mehr so viele Details über den alten Kardinalitätsschätzer veröffentlicht; zum Beispiel, wie eine bestimmte Kardinalitätsschätzung berechnet wird. Andererseits gibt es neue erweiterte Ereignisse, mit denen wir Probleme mit der Kardinalitätsschätzung beheben oder einfach nur untersuchen können, wie sie funktioniert. Zu diesen Ereignissen gehört query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors und query_rpc_set_cardinality .
Regressionen planen
Ein großes Problem, das bei einer so großen Änderung im Abfrageoptimierer in den Sinn kommt, sind Planregressionen. Die Angst vor Planregressionen wurde als das größte Hindernis für Verbesserungen des Abfrageoptimierers angesehen. Regressionen sind Probleme, die eingeführt werden, nachdem ein Fix auf den Abfrageoptimierer angewendet wurde, und werden manchmal als das klassische „zwei Falsche ergeben ein Richtiges“ bezeichnet. Dies kann passieren, wenn sich zwei schlechte Schätzungen, zum Beispiel eine zu hohe und eine zu niedrige, gegenseitig aufheben und glücklicherweise eine gute Schätzung ergeben. Das Korrigieren nur eines dieser Werte kann nun zu einer schlechten Schätzung führen, was sich negativ auf die Wahl der Planauswahl auswirken und eine Regression verursachen kann.
Um Regressionen im Zusammenhang mit dem neuen Kardinalitätsschätzer zu vermeiden, bietet SQL Server eine Möglichkeit, ihn zu aktivieren oder zu deaktivieren, da dies vom Kompatibilitätsgrad der Datenbank abhängt. Dies kann mit ALTER DATABASE geändert werden Erklärung, wie bereits erwähnt. Wenn Sie eine Datenbank auf den Kompatibilitätsgrad 120 einstellen, wird der neue Kardinalitätsschätzer verwendet, während ein Kompatibilitätsgrad von weniger als 120 den alten Kardinalitätsschätzer verwendet. Sobald Sie einen bestimmten Kardinalitätsschätzer verwenden, gibt es außerdem zwei Ablaufverfolgungsflags, mit denen Sie zum anderen wechseln können. Obwohl ich die Trace-Flags im Moment nirgendwo dokumentiert sehe, werden sie als Teil der Beschreibung der query_optimizer_force_both_cardinality_estimation_behaviors erwähnt verlängerte Veranstaltung. Das Ablaufverfolgungsflag 2312 kann verwendet werden, um den neuen Kardinalitätsschätzer zu aktivieren, während das Ablaufverfolgungsflag 9481 verwendet werden kann, um ihn zu deaktivieren. Sie können sogar die Trace-Flags für eine bestimmte Abfrage verwenden, indem Sie QUERYTRACEON verwenden Hinweis (obwohl noch nicht dokumentiert ist, ob dies ebenfalls unterstützt wird).
Beispiele
Schließlich erwähnt das Papier auch einige getestete Szenarien wie den überfüllten Primärschlüssel, den einfachen Join oder das Problem des aufsteigenden Schlüssels. Es zeigt auch, wie die Autoren mit mehreren Szenarien (oder Modellvariationen) experimentierten und in einigen Fällen einige der Annahmen des Kardinalitätsschätzers „lockerten“, z. B. im Fall der Unabhängigkeitsannahme von vollständiger Unabhängigkeit zu vollständiger Korrelation und etwas dazwischen, bis gute Ergebnisse gefunden wurden.
Obwohl auf dem Papier keine Details angegeben sind, beschließe ich, mit dem Testen einiger dieser Szenarien zu beginnen, um zu versuchen, zu verstehen, wie der neue Kardinalitätsschätzer funktioniert. Im Moment zeige ich Ihnen ein Beispiel mit der Unabhängigkeitsannahme und aufsteigenden Schlüsseln. Ich habe auch die Annahme der Einheitlichkeit getestet, konnte aber bisher keinen Unterschied bei der Schätzung feststellen.
Beginnen wir mit dem Beispiel der Unabhängigkeitsannahme. Sehen wir uns zunächst das aktuelle Verhalten an. Stellen Sie dafür sicher, dass Sie den alten Kardinalitätsschätzer verwenden, indem Sie die folgende Anweisung in der AdventureWorks2012-Datenbank ausführen:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Führen Sie dann Folgendes aus:
SELECT * FROM Person.Address WHERE City = 'Burbank';
Wir erhalten eine Schätzung von 196 Datensätzen, wie unten gezeigt:

Auf ähnliche Weise erhält die folgende Anweisung einen Schätzwert von 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Wenn wir beide Prädikate verwenden, haben wir die folgende Abfrage, die eine geschätzte Anzahl von Zeilen von 1,93862 hat (bei Verwendung von SQL Sentry Plan Explorer aufgerundet auf 2 Zeilen):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Dieser Wert wird unter der Annahme der vollständigen Unabhängigkeit beider Prädikate berechnet, wobei die Formel (196 * 194) / 19614,0 verwendet wird (wobei 19614 die Gesamtzahl der Zeilen in der Tabelle ist). Die Verwendung einer Gesamtkorrelation sollte uns eine Schätzung von 194 geben, da alle Datensätze mit der Postleitzahl 91502 zu Burbank gehören. Der neue Kardinalitätsschätzer schätzt einen Wert, der keine vollständige Unabhängigkeit oder vollständige Korrelation voraussetzt. Wechseln Sie mit der folgenden Anweisung zum neuen Kardinalitätsschätzer:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Wenn Sie dieselbe Anweisung erneut ausführen, erhalten Sie eine Schätzung von 19,3931 Zeilen, die Sie sehen können, ist ein Wert zwischen der Annahme einer vollständigen Unabhängigkeit und einer vollständigen Korrelation (aufgerundet auf 19 Zeilen im Plan-Explorer). Die verwendete Formel ist Selektivität des selektivsten Filters * SQRT(Selektivität des nächstselektivsten Filters) oder (194/19614,0) * SQRT(196/19614,0) * 19614, was 19,393:
ergibt

Wenn Sie den neuen Kardinalitätsschätzer auf Datenbankebene aktiviert haben und ihn für eine bestimmte Abfrage deaktivieren möchten, um eine Planregression zu vermeiden, können Sie das Ablaufverfolgungsflag 9481 wie zuvor erläutert verwenden:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Hinweis:Der QUERYTRACEON-Abfragehinweis wird verwendet, um ein Ablaufverfolgungsflag auf Abfrageebene anzuwenden, und wird derzeit nur in einer begrenzten Anzahl von Szenarien unterstützt. Weitere Informationen zum Abfragehinweis QUERYTRACEON finden Sie unter https://support.microsoft.com/kb/2801413.
Schauen wir uns nun das Problem der aufsteigenden Tonart an, ein Thema, das ich in diesem Beitrag ausführlicher erläutert habe. Die traditionelle Empfehlung von Microsoft zur Behebung dieses Problems besteht darin, Statistiken nach dem Laden von Daten manuell zu aktualisieren, wie hier erläutert – was das Problem folgendermaßen beschreibt:
Statistiken zu aufsteigenden oder absteigenden Schlüsselspalten, z. B. Identitäts- oder Echtzeit-Zeitstempelspalten, erfordern möglicherweise häufigere Statistikaktualisierungen als der Abfrageoptimierer durchführt. Einfügevorgänge fügen neue Werte an aufsteigende oder absteigende Spalten an. Die Anzahl der hinzugefügten Zeilen ist möglicherweise zu gering, um eine Statistikaktualisierung auszulösen. Wenn Statistiken nicht aktuell sind und Abfragen aus den zuletzt hinzugefügten Zeilen auswählen, enthalten die aktuellen Statistiken keine Kardinalitätsschätzungen für diese neuen Werte. Dies kann zu ungenauen Kardinalitätsschätzungen und einer langsamen Abfrageleistung führen. Beispielsweise weist eine Abfrage, die aus den neuesten Verkaufsauftragsdaten auswählt, ungenaue Kardinalitätsschätzungen auf, wenn die Statistiken nicht aktualisiert werden, um Kardinalitätsschätzungen für die neuesten Verkaufsauftragsdaten einzuschließen.
Die Empfehlung in meinem Artikel lautete, die Trace-Flags 2389 und 2390 zu verwenden, die erstmals von Ian Jose in seinem Artikel Ascending Keys and Auto Quick Corrected Statistics veröffentlicht wurden. In meinem Artikel finden Sie eine Erklärung und ein Beispiel zur Verwendung dieser Ablaufverfolgungsflags, um dieses Problem zu vermeiden. Diese Ablaufverfolgungsflags funktionieren weiterhin auf SQL Server 2014 CTP2. Aber noch besser, sie werden nicht mehr benötigt, wenn Sie den neuen Kardinalitätsschätzer verwenden.
Verwenden Sie dasselbe Beispiel in meinem Beitrag:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Geben Sie einige Daten ein:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Da wir einen Index erstellt haben, haben wir nur neue Statistiken. Die Ausführung der folgenden Abfrage erstellt eine gute Schätzung von 35 Zeilen:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Wenn wir neue Daten einfügen:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Sie können die Schätzung mit dem alten Kardinalitätsschätzer wie folgt sehen:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Da die geringe Anzahl eingefügter Datensätze nicht ausreichte, um eine automatische Aktualisierung des Statistikobjekts auszulösen, kennt das aktuelle Histogramm die neu hinzugefügten Datensätze nicht und der Abfrageoptimierer verwendet eine Schätzung von 1 Zeile. Optional können Sie die Trace-Flags 2389 und 2390 verwenden, um eine bessere Schätzung zu erhalten. Aber wenn Sie dieselbe Abfrage mit dem neuen Kardinalitätsschätzer versuchen, erhalten Sie die folgende Schätzung:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
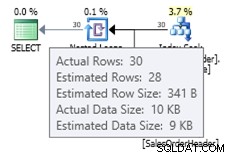
In diesem Fall erhalten wir eine bessere Schätzung als mit dem alten Kardinalitätsschätzer (oder wir erhalten die gleiche Schätzung wie bei Verwendung der Trace-Flags 2389 oder 2390). Der geschätzte Wert von 27,9631 (wieder vom Plan Explorer auf 28 gerundet) wird anhand der Dichteinformationen des Statistikobjekts multipliziert mit der Anzahl der Zeilen der Tabelle berechnet; das heißt 0,0008992806 * 31095. Der Dichtewert kann erhalten werden mit:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Denken Sie schließlich daran, dass nichts, was in diesem Artikel erwähnt wird, dokumentiert ist, und dies ist das Verhalten, das ich bisher in SQL Server 2014 CTP2 beobachtet habe. All dies könnte sich in einer späteren CTP- oder RTM-Version des Produkts ändern.