Während SQL Server unter Linux fast alle Schlagzeilen über v.Next gestohlen hat, gibt es einige andere interessante Fortschritte in der nächsten Version unserer bevorzugten Datenbankplattform. Auf der T-SQL-Front haben wir endlich eine integrierte Möglichkeit, gruppierte String-Verkettungen durchzuführen:STRING_AGG() .
Nehmen wir an, wir haben die folgende einfache Tabellenstruktur:
CREATE TABLE dbo.Objects( [object_id] int, [object_name] nvarchar(261), CONSTRAINT PK_Objects PRIMARY KEY([object_id])); CREATE TABLE dbo.Columns( [object_id] int NOT NULL FOREIGN KEY REFERENCES dbo.Objects([object_id]), column_name sysname, CONSTRAINT PK_Columns PRIMARY KEY ([object_id],column_name));
Für Leistungstests werden wir dies mit sys.all_objects füllen und sys.all_columns . Aber für eine einfache Demonstration fügen wir zunächst die folgenden Zeilen hinzu:
INSERT dbo.Objects([object_id],[object_name]) VALUES(1,N'Employees'),(2,N'Orders'); INSERT dbo.Columns([object_id],column_name) VALUES(1,N'EmployeeID'),(1,N'CurrentStatus'), (2,N'OrderID'),(2,N'OrderDate'),(2 ,N'Kundennummer');
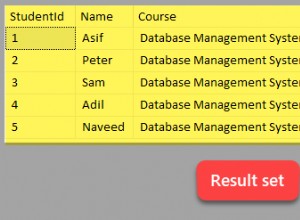
Wenn die Foren ein Hinweis sind, ist es eine sehr häufige Anforderung, eine Zeile für jedes Objekt zusammen mit einer durch Kommas getrennten Liste von Spaltennamen zurückzugeben. (Extrapolieren Sie das auf alle Entitätstypen, die Sie auf diese Weise modellieren – Produktnamen, die mit einem Auftrag verbunden sind, Teilenamen, die an der Montage eines Produkts beteiligt sind, Untergebene, die einem Manager unterstellt sind usw.) Also zum Beispiel mit den obigen Daten, die wir haben würden Ausgabe wie folgt wünschen:
Objektspalten--------- ----------------------------Employees EmployeeID,CurrentStatusOrders OrderID,OrderDate, Kundennummer
In aktuellen Versionen von SQL Server würden wir dies wahrscheinlich erreichen, indem wir FOR XML PATH verwenden , da ich in diesem früheren Beitrag gezeigt habe, dass es außerhalb von CLR am effizientesten ist. In diesem Beispiel würde es so aussehen:
SELECT [object] =o.[object_name], [columns] =STUFF( (SELECT N',' + c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Wie vorhersehbar, erhalten wir dieselbe Ausgabe, die oben gezeigt wurde. In SQL Server v.Next können wir dies einfacher ausdrücken:
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS cON o.[object_id] =c.[ Objekt-ID]GRUPPE NACH o.[Objektname];
Auch dies erzeugt genau die gleiche Ausgabe. Und wir waren in der Lage, dies mit einer nativen Funktion zu tun, wodurch sowohl der teure FOR XML PATH vermieden wurde Gerüste und STUFF() Funktion zum Entfernen des ersten Kommas (dies geschieht automatisch).
Was ist mit der Bestellung?
Eines der Probleme mit vielen der kludge-Lösungen für die gruppierte Verkettung ist, dass die Reihenfolge der durch Kommas getrennten Liste willkürlich und nicht deterministisch betrachtet werden sollte.
Für den XML PATH Lösung habe ich in einem anderen früheren Beitrag gezeigt, dass das Hinzufügen eines ORDER BY ist trivial und garantiert. In diesem Beispiel könnten wir also die Spaltenliste alphabetisch nach Spaltennamen ordnen, anstatt es SQL Server zu überlassen, sie zu sortieren (oder nicht):
SELECT [object] =[object_name], [columns] =STUFF( (SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] ORDER BY c. Spaltenname -- nur ändern FOR XML PATH, TYPE ).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;
Ausgabe:
Objektspalten--------- -----------------------Employees CurrentStatus,EmployeeIDOrder CustomerID,OrderDate, Auftrags-ID
CTP 1.1 fügt MIT GRUPPE hinzu zu STRING_AGG() , also können wir mit dem neuen Ansatz sagen:
SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) -- nur changeFROM dbo.Objects AS oINNER JOIN dbo. Spalten AS cON o.[object_id] =c.[object_id]GROUP BY o.[object_name];
Jetzt erhalten wir die gleichen Ergebnisse. Beachten Sie, dass dies genau wie bei einem normalen ORDER BY der Fall ist -Klausel können Sie innerhalb von WITHIN GROUP () mehrere Sortierspalten oder -ausdrücke hinzufügen .
In Ordnung, Leistung bereits!
Unter Verwendung von 2,6-GHz-Quad-Core-Prozessoren, 8 GB Arbeitsspeicher und SQL Server CTP1.1 (14.0.100.187) habe ich eine neue Datenbank erstellt, diese Tabellen neu erstellt und Zeilen aus sys.all_objects und sys.all_columns . Ich habe darauf geachtet, nur Objekte mit mindestens einer Spalte einzuschließen:
INSERT dbo.Objects([object_id], [object_name]) -- 656 Zeilen SELECT [object_id], QUOTENAME(s.name) + N'.' + QUOTENAME(o.name) FROM sys.all_objects AS o INNER JOIN sys.schemas AS s ON o.[schema_id] =s.[schema_id] WHERE EXISTS ( SELECT 1 FROM sys.all_columns WHERE [object_id] =o.[object_id ] ); INSERT dbo.Columns([object_id], column_name) -- 8.085 Zeilen SELECT [object_id], name FROM sys.all_columns AS c WHERE EXISTS ( SELECT 1 FROM dbo.Objects WHERE [object_id] =c.[object_id] );Auf meinem System ergab dies 656 Objekte und 8.085 Spalten (Ihr System kann leicht abweichende Zahlen ergeben).
Die Pläne
Vergleichen wir zunächst die Pläne und Tabellen-E/A-Registerkarten für unsere beiden ungeordneten Abfragen mithilfe des Plan-Explorers. Hier sind die allgemeinen Laufzeitmetriken:
Laufzeitmetriken für XML PATH (oben) und STRING_AGG() (unten)
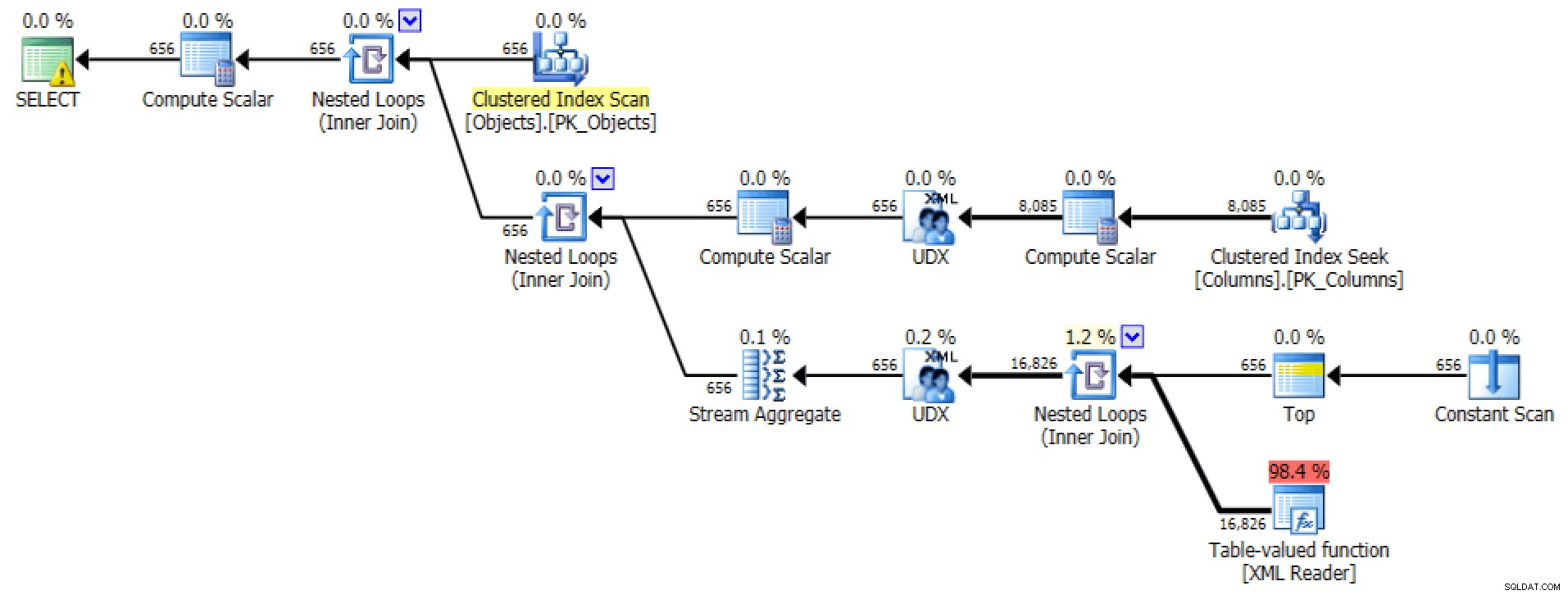
Der grafische Plan und die Tabellen-I/O aus dem
FOR XML PATHAbfrage:
Plan- und Tabellen-E/A für XML PATH, keine Reihenfolge
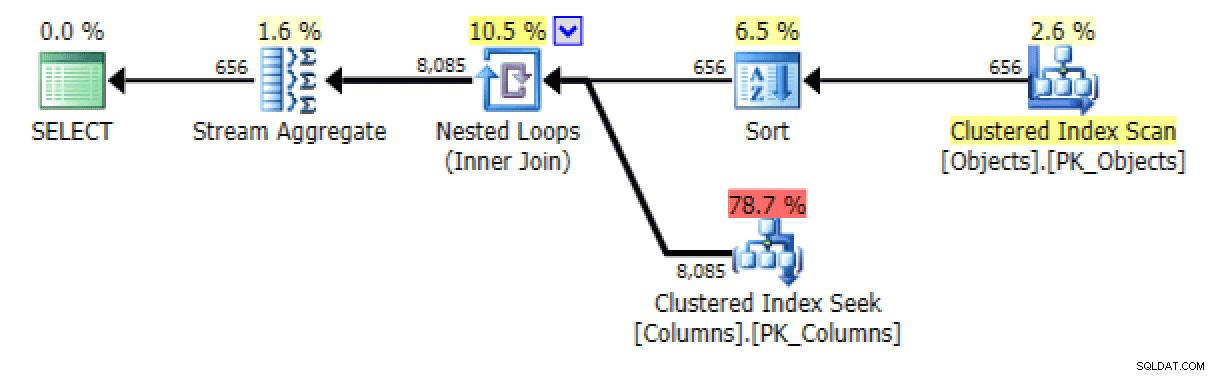
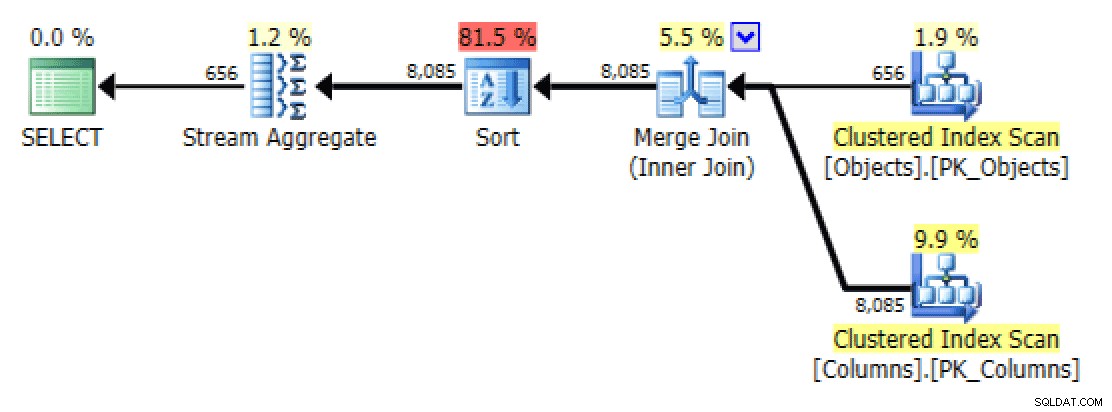
Und vom
STRING_AGGVersion:
Plan- und Tabellen-E/A für STRING_AGG, keine Bestellung
Für letzteres scheint mir die Clustered-Index-Suche ein wenig beunruhigend. Dies schien ein guter Fall zu sein, um das selten verwendete
FORCESCANauszuprobieren Hinweis (und nein, das würde demFOR XML PATHsicher nicht weiterhelfen Abfrage):SELECT [object] =o.[object_name], [columns] =STRING_AGG(c.column_name, N',')FROM dbo.Objects AS oINNER JOIN dbo.Columns AS c WITH (FORCESCAN) -- hintON o hinzugefügt .[object_id] =c.[object_id]GROUP BY o.[object_name];Jetzt sehen die Registerkarten Plan und Tabellen-E/A viel aus besser, zumindest auf den ersten Blick:
Plan- und Tabellen-E/A für STRING_AGG(), keine Reihenfolge, mit FORCESCAN
Die geordneten Versionen der Abfragen generieren ungefähr die gleichen Pläne. Für den
FOR XML PATHVersion wird eine Sortierung hinzugefügt:
Sortierung in FOR XML PATH-Version hinzugefügt
Für
STRING_AGG(), wird in diesem Fall ein Scan gewählt, auch ohneFORCESCANHinweis, und es ist keine zusätzliche Sortieroperation erforderlich – der Plan sieht also identisch mit demFORCESCANaus Version.Im Maßstab
Ein Blick auf einen Plan und einmalige Laufzeitmetriken kann uns eine Vorstellung davon geben, ob
STRING_AGG()eine bessere Leistung als der vorhandeneFOR XML PATHLösung, aber ein größerer Test könnte sinnvoller sein. Was passiert, wenn wir die gruppierte Verkettung 5.000 Mal ausführen?SELECT SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unsordered] =SYSDATETIME();GO DECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',' ) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c WITH (FORCESCAN) ON o.[object_id] =c.[object_id] GROUP BY o.[object_name];GO 5000SELECT [string_agg, unordered, forcescan] =SYSDATETIME( ); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] FOR XML PATH, TYPE).value (N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS o;GO 5000SELECT [für XML-Pfad, unsortiert] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STRING_AGG(c.column_name, N',') WITHIN GROUP (ORDER BY c.column_name) FROM dbo.Objects AS o INNER JOIN dbo.Columns AS c ON o.[object_id ] =c.[Objekt_id] GROUP BY o.[Objekt_name];GO 5000SELECT [string_agg, geordnet] =SYSDATETIME(); GODECLARE @x nvarchar(max);SELECT @x =STUFF((SELECT N',' +c.column_name FROM dbo.Columns AS c WHERE c.[object_id] =o.[object_id] ORDER BY c.column_name FOR XML PATH , TYPE).value(N'.[1]',N'nvarchar(max)'),1,1,N'')FROM dbo.Objects AS oORDER BY o.[object_name];GO 5000SELECT [for xml path , bestellt] =SYSDATETIME();Nachdem ich dieses Skript fünfmal ausgeführt hatte, habe ich die Dauerzahlen gemittelt und hier sind die Ergebnisse:
Dauer (Millisekunden) für verschiedene gruppierte Verkettungsansätze
Wir können sehen, dass unser
FORCESCANHint hat die Sache wirklich verschlimmert – während wir die Kosten von der Cluster-Index-Suche weg verschoben haben, war die Sortierung tatsächlich viel schlimmer, obwohl die geschätzten Kosten sie als relativ gleichwertig erachteten. Noch wichtiger ist, dass wir diesenSTRING_AGG()sehen können bietet einen Leistungsvorteil, unabhängig davon, ob die verketteten Zeichenfolgen auf eine bestimmte Weise geordnet werden müssen oder nicht. Wie beiSTRING_SPLIT(), die ich mir im März angesehen habe, bin ich ziemlich beeindruckt, dass diese Funktion weit vor „v1“ skaliert.Ich habe weitere Tests geplant, vielleicht für einen zukünftigen Beitrag:
- Wenn alle Daten aus einer einzigen Tabelle stammen, mit und ohne Index, der die Sortierung unterstützt
- Ähnliche Leistungstests unter Linux
Wenn Sie in der Zwischenzeit spezielle Anwendungsfälle für die gruppierte Verkettung haben, teilen Sie diese bitte unten mit (oder senden Sie mir eine E-Mail an abertrand@sentryone.com). Ich bin immer offen dafür sicherzustellen, dass meine Tests so realistisch wie möglich sind.