Ich habe dieselben Empfehlungen zu tempdb ausgesprochen, seit ich vor über 15 Jahren anfing, mit SQL Server zu arbeiten, als ich mit Kunden zusammenarbeitete, die Version 2000 ausführten. Das Wesentliche:Erstellen Sie mehrere Datendateien mit derselben Größe und demselben Auto -Wachstumseinstellungen, aktivieren Sie das Ablaufverfolgungsflag 1118 (und möglicherweise 1117) und reduzieren Sie die Verwendung von tempdb. Auf Kundenseite war dies bis SQL Server 2019 die Grenze dessen, was getan werden kann*.
*Es gibt ein paar zusätzliche Codierungsempfehlungen, die Pam Lahoud in ihrem sehr informativen Beitrag TEMPDB – Files and Trace Flags and Updates, Oh My! bespricht.
Was ich interessant finde, ist, dass tempdb nach all dieser Zeit immer noch ein Problem darstellt. Das SQL Server-Team hat im Laufe der Jahre viele Änderungen vorgenommen, um Probleme zu beheben, aber der Missbrauch geht weiter. Die neueste Anpassung des SQL Server-Teams verschiebt die Systemtabellen (Metadaten) für tempdb nach In-Memory OLTP (auch bekannt als speicheroptimiert). Einige Informationen sind in den Versionshinweisen zu SQL Server 2019 verfügbar, und am ersten Tag der PASS Summit-Keynote gab es eine Demo von Bob Ward und Conor Cunningham. Pam Lahoud hat auch eine kurze Demo in ihrer PASS Summit General Session gemacht. Jetzt, da 2019 CTP 3.2 herausgekommen ist, dachte ich, es wäre an der Zeit, selbst ein bisschen zu testen.
Einrichtung
Ich habe SQL Server 2019 CTP 3.2 auf meiner virtuellen Maschine installiert, die über 8 GB Arbeitsspeicher (maximaler Serverspeicher auf 6 GB eingestellt) und 4 vCPUs verfügt. Ich habe vier (4) tempdb-Datendateien mit einer Größe von jeweils 1 GB erstellt.
Ich habe eine Kopie von WideWorldImporters wiederhergestellt und dann drei gespeicherte Prozeduren erstellt (Definitionen unten). Jede gespeicherte Prozedur akzeptiert eine Datumseingabe und überträgt alle Zeilen aus Sales.Order und Sales.OrderLines für dieses Datum in das temporäre Objekt. In Sales.usp_OrderInfoTV ist das Objekt eine Tabellenvariable, in Sales.usp_OrderInfoTT ist das Objekt eine temporäre Tabelle, die über SELECT … INTO mit einem nachträglich hinzugefügten Nonclustered definiert wird, und in Sales.usp_OrderInfoTTALT ist das Objekt eine vordefinierte temporäre Tabelle, die dann geändert wird eine zusätzliche Spalte haben. Nachdem die Daten zum temporären Objekt hinzugefügt wurden, gibt es eine SELECT-Anweisung für das Objekt, das mit der Sales.Customers-Tabelle verknüpft wird.
/*
Create the stored procedures
*/
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTV
GO
CREATE PROCEDURE Sales.usp_OrderInfoTV @OrderDate DATE
AS
BEGIN
DECLARE @OrdersInfo TABLE (
OrderID INT,
OrderLineID INT,
CustomerID INT,
StockItemID INT,
Quantity INT,
UnitPrice DECIMAL(18,2),
OrderDate DATE);
INSERT INTO @OrdersInfo (
OrderID,
OrderLineID,
CustomerID,
StockItemID,
Quantity,
UnitPrice,
OrderDate)
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice,
OrderDate
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM @OrdersInfo o
JOIN Sales.Customers c
ON o.CustomerID = c.CustomerID
GROUP BY o.OrderID, c.CustomerName;
END
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTT
GO
CREATE PROCEDURE Sales.usp_OrderInfoTT @OrderDate DATE
AS
BEGIN
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice,
OrderDate
INTO #temporderinfo
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM #temporderinfo o
JOIN Sales.Customers c
ON o.CustomerID = c.CustomerID
GROUP BY o.OrderID, c.CustomerName
END
GO
DROP PROCEDURE IF EXISTS Sales.usp_OrderInfoTTALT
GO
CREATE PROCEDURE Sales.usp_OrderInfoTTALT @OrderDate DATE
AS
BEGIN
CREATE TABLE #temporderinfo (
OrderID INT,
OrderLineID INT,
CustomerID INT,
StockItemID INT,
Quantity INT,
UnitPrice DECIMAL(18,2));
INSERT INTO #temporderinfo (
OrderID,
OrderLineID,
CustomerID,
StockItemID,
Quantity,
UnitPrice)
SELECT
o.OrderID,
ol.OrderLineID,
o.CustomerID,
ol.StockItemID,
ol.Quantity,
ol.UnitPrice
FROM Sales.Orders o
INNER JOIN Sales.OrderLines ol
ON o.OrderID = ol.OrderID
WHERE o.OrderDate = @OrderDate;
SELECT o.OrderID,
c.CustomerName,
SUM (o.Quantity),
SUM (o.UnitPrice)
FROM #temporderinfo o
JOIN Sales.Customers c
ON o.CustomerID c.CustomerID
GROUP BY o.OrderID, c.CustomerName
END
GO
/*
Create tables to hold testing data
*/
USE [WideWorldImporters];
GO
CREATE TABLE [dbo].[PerfTesting_Tests] (
[TestID] INT IDENTITY(1,1),
[TestName] VARCHAR (200),
[TestStartTime] DATETIME2,
[TestEndTime] DATETIME2
) ON [PRIMARY];
GO
CREATE TABLE [dbo].[PerfTesting_WaitStats] (
[TestID] [int] NOT NULL,
[CaptureDate] [datetime] NOT NULL DEFAULT (sysdatetime()),
[WaitType] [nvarchar](60) NOT NULL,
[Wait_S] [decimal](16, 2) NULL,
[Resource_S] [decimal](16, 2) NULL,
[Signal_S] [decimal](16, 2) NULL,
[WaitCount] [bigint] NULL,
[Percentage] [decimal](5, 2) NULL,
[AvgWait_S] [decimal](16, 4) NULL,
[AvgRes_S] [decimal](16, 4) NULL,
[AvgSig_S] [decimal](16, 4) NULL
) ON [PRIMARY];
GO
/*
Enable Query Store
(testing settings, not exactly what
I would recommend for production)
*/
USE [master];
GO
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON;
GO
ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30),
DATA_FLUSH_INTERVAL_SECONDS = 600,
INTERVAL_LENGTH_MINUTES = 10,
MAX_STORAGE_SIZE_MB = 1024,
QUERY_CAPTURE_MODE = AUTO,
SIZE_BASED_CLEANUP_MODE = AUTO);
GO Testen
Das Standardverhalten für SQL Server 2019 ist, dass die tempdb-Metadaten nicht speicheroptimiert sind, und wir können dies bestätigen, indem wir sys.configurations:
überprüfenSELECT * FROM sys.configurations WHERE configuration_id = 1589;

Für alle drei gespeicherten Prozeduren verwenden wir sqlcmd, um 20 gleichzeitige Threads zu generieren, die eine von zwei verschiedenen .sql-Dateien ausführen. Die erste .sql-Datei, die von 19 Threads verwendet wird, führt die Prozedur 1000 Mal in einer Schleife aus. Die zweite .sql-Datei, die nur einen (1) Thread enthält, führt die Prozedur 3000 Mal in einer Schleife aus. Die Datei enthält auch TSQL, um zwei interessante Metriken zu erfassen:Gesamtdauer und Wartestatistik. Wir verwenden den Abfragespeicher, um die durchschnittliche Dauer des Verfahrens zu erfassen.
/*
Example of first .sql file
which calls the SP 1000 times
*/
SET NOCOUNT ON;
GO
USE [WideWorldImporters];
GO
DECLARE @StartDate DATE;
DECLARE @MaxDate DATE;
DECLARE @Date DATE;
DECLARE @Counter INT = 1;
SELECT @StartDATE = MIN(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SELECT @MaxDATE = MAX(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SET @Date = @StartDate;
WHILE @Counter <= 1000
BEGIN
EXEC [Sales].[usp_OrderInfoTT] @Date;
IF @Date <= @MaxDate
BEGIN
SET @Date = DATEADD(DAY, 1, @Date);
END
ELSE
BEGIN
SET @Date = @StartDate;
END
SET @Counter = @Counter + 1;
END
GO
/*
Example of second .sql file
which calls the SP 3000 times
and captures total duration and
wait statisics
*/
SET NOCOUNT ON;
GO
USE [WideWorldImporters];
GO
DECLARE @StartDate DATE;
DECLARE @MaxDate DATE;
DECLARE @DATE DATE;
DECLARE @Counter INT = 1;
DECLARE @TestID INT;
DECLARE @TestName VARCHAR(200) = 'Execution of usp_OrderInfoTT - Disk Based System Tables';
INSERT INTO [WideWorldImporters].[dbo].[PerfTesting_Tests] ([TestName]) VALUES (@TestName);
SELECT @TestID = MAX(TestID) FROM [WideWorldImporters].[dbo].[PerfTesting_Tests];
SELECT @StartDATE = MIN(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SELECT @MaxDATE = MAX(OrderDate) FROM [WideWorldImporters].[Sales].[Orders];
SET @Date = @StartDate;
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats1
FROM sys.dm_os_wait_stats;
/*
set start time
*/
UPDATE [WideWorldImporters].[dbo].[PerfTesting_Tests]
SET [TestStartTime] = SYSDATETIME()
WHERE [TestID] = @TestID;
WHILE @Counter <= 3000
BEGIN
EXEC [Sales].[usp_OrderInfoTT] @Date;
IF @Date <= @MaxDate
BEGIN
SET @Date = DATEADD(DAY, 1, @Date);
END
ELSE
BEGIN
SET @Date = @StartDate;
END
SET @Counter = @Counter + 1
END
/*
set end time
*/
UPDATE [WideWorldImporters].[dbo].[PerfTesting_Tests]
SET [TestEndTime] = SYSDATETIME()
WHERE [TestID] = @TestID;
SELECT [wait_type], [waiting_tasks_count], [wait_time_ms],
[max_wait_time_ms], [signal_wait_time_ms]
INTO ##SQLskillsStats2
FROM sys.dm_os_wait_stats;
WITH [DiffWaits] AS
(SELECT
-- Waits that weren't in the first snapshot
[ts2].[wait_type],
[ts2].[wait_time_ms],
[ts2].[signal_wait_time_ms],
[ts2].[waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NULL
AND [ts2].[wait_time_ms] > 0
UNION
SELECT
-- Diff of waits in both snapshots
[ts2].[wait_type],
[ts2].[wait_time_ms] - [ts1].[wait_time_ms] AS [wait_time_ms],
[ts2].[signal_wait_time_ms] - [ts1].[signal_wait_time_ms] AS [signal_wait_time_ms],
[ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] AS [waiting_tasks_count]
FROM [##SQLskillsStats2] AS [ts2]
LEFT OUTER JOIN [##SQLskillsStats1] AS [ts1]
ON [ts2].[wait_type] = [ts1].[wait_type]
WHERE [ts1].[wait_type] IS NOT NULL
AND [ts2].[waiting_tasks_count] - [ts1].[waiting_tasks_count] > 0
AND [ts2].[wait_time_ms] - [ts1].[wait_time_ms] > 0),
[Waits] AS
(SELECT
[wait_type],
[wait_time_ms] / 1000.0 AS [WaitS],
([wait_time_ms] - [signal_wait_time_ms]) / 1000.0 AS [ResourceS],
[signal_wait_time_ms] / 1000.0 AS [SignalS],
[waiting_tasks_count] AS [WaitCount],
100.0 * [wait_time_ms] / SUM ([wait_time_ms]) OVER() AS [Percentage],
ROW_NUMBER() OVER(ORDER BY [wait_time_ms] DESC) AS [RowNum]
FROM [DiffWaits]
WHERE [wait_type] NOT IN (
-- These wait types are almost 100% never a problem and so they are
-- filtered out to avoid them skewing the results.
N'BROKER_EVENTHANDLER', N'BROKER_RECEIVE_WAITFOR', N'BROKER_TASK_STOP',
N'BROKER_TO_FLUSH', N'BROKER_TRANSMITTER', N'CHECKPOINT_QUEUE',
N'CHKPT', N'CLR_AUTO_EVENT', N'CLR_MANUAL_EVENT',
N'CLR_SEMAPHORE', N'CXCONSUMER', N'DBMIRROR_DBM_EVENT',
N'DBMIRROR_EVENTS_QUEUE', N'DBMIRROR_WORKER_QUEUE', N'DBMIRRORING_CMD',
N'DIRTY_PAGE_POLL', N'DISPATCHER_QUEUE_SEMAPHORE', N'EXECSYNC',
N'FSAGENT', N'FT_IFTS_SCHEDULER_IDLE_WAIT', N'FT_IFTSHC_MUTEX',
N'HADR_CLUSAPI_CALL', N'HADR_FILESTREAM_IOMGR_IOCOMPLETION', N'HADR_LOGCAPTURE_WAIT',
N'HADR_NOTIFICATION_DEQUEUE', N'HADR_TIMER_TASK', N'HADR_WORK_QUEUE',
N'KSOURCE_WAKEUP', N'LAZYWRITER_SLEEP', N'LOGMGR_QUEUE',
N'MEMORY_ALLOCATION_EXT', N'ONDEMAND_TASK_QUEUE', N'PARALLEL_REDO_DRAIN_WORKER',
N'PARALLEL_REDO_LOG_CACHE', N'PARALLEL_REDO_TRAN_LIST', N'PARALLEL_REDO_WORKER_SYNC',
N'PARALLEL_REDO_WORKER_WAIT_WORK', N'PREEMPTIVE_XE_GETTARGETSTATE',
N'PWAIT_ALL_COMPONENTS_INITIALIZED', N'PWAIT_DIRECTLOGCONSUMER_GETNEXT',
N'QDS_PERSIST_TASK_MAIN_LOOP_SLEEP', N'QDS_ASYNC_QUEUE',
N'QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP',
N'QDS_SHUTDOWN_QUEUE', N'REDO_THREAD_PENDING_WORK', N'REQUEST_FOR_DEADLOCK_SEARCH',
N'RESOURCE_QUEUE', N'SERVER_IDLE_CHECK', N'SLEEP_BPOOL_FLUSH',
N'SLEEP_DBSTARTUP', N'SLEEP_DCOMSTARTUP', N'SLEEP_MASTERDBREADY',
N'SLEEP_MASTERMDREADY', N'SLEEP_MASTERUPGRADED', N'SLEEP_MSDBSTARTUP',
N'SLEEP_SYSTEMTASK', N'SLEEP_TASK', N'SLEEP_TEMPDBSTARTUP',
N'SNI_HTTP_ACCEPT', N'SOS_WORK_DISPATCHER', N'SP_SERVER_DIAGNOSTICS_SLEEP',
N'SQLTRACE_BUFFER_FLUSH', N'SQLTRACE_INCREMENTAL_FLUSH_SLEEP',
N'SQLTRACE_WAIT_ENTRIES', N'WAIT_FOR_RESULTS', N'WAITFOR',
N'WAITFOR_TASKSHUTDOWN', N'WAIT_XTP_RECOVERY', N'WAIT_XTP_HOST_WAIT',
N'WAIT_XTP_OFFLINE_CKPT_NEW_LOG', N'WAIT_XTP_CKPT_CLOSE',
N'XE_DISPATCHER_JOIN', N'XE_DISPATCHER_WAIT', N'XE_TIMER_EVENT'
)
)
INSERT INTO [WideWorldImporters].[dbo].[PerfTesting_WaitStats] (
[TestID],
[WaitType] ,
[Wait_S] ,
[Resource_S] ,
[Signal_S] ,
[WaitCount] ,
[Percentage] ,
[AvgWait_S] ,
[AvgRes_S] ,
[AvgSig_S]
)
SELECT
@TestID,
[W1].[wait_type] AS [WaitType],
CAST ([W1].[WaitS] AS DECIMAL (16, 2)) AS [Wait_S],
CAST ([W1].[ResourceS] AS DECIMAL (16, 2)) AS [Resource_S],
CAST ([W1].[SignalS] AS DECIMAL (16, 2)) AS [Signal_S],
[W1].[WaitCount] AS [WaitCount],
CAST ([W1].[Percentage] AS DECIMAL (5, 2)) AS [Percentage],
CAST (([W1].[WaitS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgWait_S],
CAST (([W1].[ResourceS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgRes_S],
CAST (([W1].[SignalS] / [W1].[WaitCount]) AS DECIMAL (16, 4)) AS [AvgSig_S]
FROM [Waits] AS [W1]
INNER JOIN [Waits] AS [W2]
ON [W2].[RowNum] <= [W1].[RowNum]
GROUP BY [W1].[RowNum], [W1].[wait_type], [W1].[WaitS],
[W1].[ResourceS], [W1].[SignalS], [W1].[WaitCount], [W1].[Percentage]
HAVING SUM ([W2].[Percentage]) - [W1].[Percentage] < 95; -- percentage threshold
GO
-- Cleanup
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats1')
DROP TABLE [##SQLskillsStats1];
IF EXISTS (SELECT * FROM [tempdb].[sys].[objects]
WHERE [name] = N'##SQLskillsStats2')
DROP TABLE [##SQLskillsStats2];
GO Beispiel einer Befehlszeilendatei:
Ergebnisse
Nach dem Ausführen der Befehlszeilendateien, die 20 Threads für jede gespeicherte Prozedur generieren, zeigt die Überprüfung der Gesamtdauer für die 12.000 Ausführungen jeder Prozedur Folgendes:
SELECT *, DATEDIFF(SECOND, TestStartTime, TestEndTime) AS [TotalDuration] FROM [dbo].[PerfTesting_Tests] ORDER BY [TestID];

Die gespeicherten Prozeduren mit den temporären Tabellen (usp_OrderInfoTT und usp_OrderInfoTTC) dauerten länger. Wenn wir uns die individuelle Abfrageleistung ansehen:
SELECT
[qsq].[query_id],
[qsp].[plan_id],
OBJECT_NAME([qsq].[object_id]) AS [ObjectName],
[rs].[count_executions],
[rs].[last_execution_time],
[rs].[avg_duration],
[rs].[avg_logical_io_reads],
[qst].[query_sql_text]
FROM [sys].[query_store_query] [qsq]
JOIN [sys].[query_store_query_text] [qst]
ON [qsq].[query_text_id] = [qst].[query_text_id]
JOIN [sys].[query_store_plan] [qsp]
ON [qsq].[query_id] = [qsp].[query_id]
JOIN [sys].[query_store_runtime_stats] [rs]
ON [qsp].[plan_id] = [rs].[plan_id]
WHERE ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTT'))
OR ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTV'))
OR ([qsq].[object_id] = OBJECT_ID('Sales.usp_OrderInfoTTALT'))
ORDER BY [qsq].[query_id], [rs].[last_execution_time];

Wir können sehen, dass das SELECT … INTO für usp_OrderInfoTT im Durchschnitt etwa 28 ms dauerte (die Dauer im Abfragespeicher wird in Mikrosekunden gespeichert) und nur 9 ms dauerte, als die temporäre Tabelle vorab erstellt wurde. Für die Tabellenvariable dauerte das INSERT im Durchschnitt etwas mehr als 22 ms. Interessanterweise dauerte die SELECT-Abfrage für die temporären Tabellen etwas mehr als 1 ms und ungefähr 2,7 ms für die Tabellenvariable.
Eine Überprüfung der Wartestatistikdaten findet einen bekannten Wartetyp, PAGELATCH*:
SELECT * FROM [dbo].[PerfTesting_WaitStats] ORDER BY [TestID], [Percentage] DESC;

Beachten Sie, dass wir nur sehen, dass PAGELATCH* auf die Tests 1 und 2 wartet, die die Prozeduren mit den temporären Tabellen waren. Für usp_OrderInfoTV, das eine Tabellenvariable verwendet, sehen wir nur SOS_SCHEDULER_YIELD-Wartezeiten. Bitte beachten: Dies bedeutet keineswegs, dass Sie Tabellenvariablen anstelle von temporären Tabellen verwenden sollten , und es bedeutet auch nicht, dass Sie dies nicht tun werden haben PAGELATCH wartet mit Tabellenvariablen. Dies ist ein erfundenes Szenario; Ich sehr empfehlen Ihnen, mit IHREM Code zu testen, um zu sehen, welche Wait_types angezeigt werden.
Jetzt ändern wir die Instanz so, dass speicheroptimierte Tabellen für die tempdb-Metadaten verwendet werden. Dies kann auf zwei Arten erfolgen, über den Befehl ALTER SERVER CONFIGURATION oder durch Verwendung von sp_configure. Da es sich bei dieser Einstellung um eine erweiterte Option handelt, müssen Sie bei Verwendung von sp_configure zuerst die erweiterten Optionen aktivieren.
ALTER SERVER CONFIGURATION SET MEMORY_OPTIMIZED TEMPDB_METADATA = ON; GO
Nach dieser Änderung ist ein Neustart der Instanz erforderlich. (HINWEIS:Sie können dies wieder ändern, um KEINE speicheroptimierten Tabellen zu verwenden, Sie müssen die Instanz nur erneut neu starten.) Wenn wir nach dem Neustart erneut sys.configurations überprüfen, können wir sehen, dass die Metadatentabellen speicheroptimiert sind:

Nach dem erneuten Ausführen der Befehlszeilendateien zeigt die Gesamtdauer für die 21.000 Ausführungen jeder Prozedur Folgendes (beachten Sie, dass die Ergebnisse zum leichteren Vergleich nach gespeicherter Prozedur geordnet sind):

Es gab definitiv eine Leistungsverbesserung für usp_OrderInfoTT und usp_OrderInfoTTC und eine leichte Leistungssteigerung für usp_OrderInfoTV. Lassen Sie uns die Abfragedauer überprüfen:
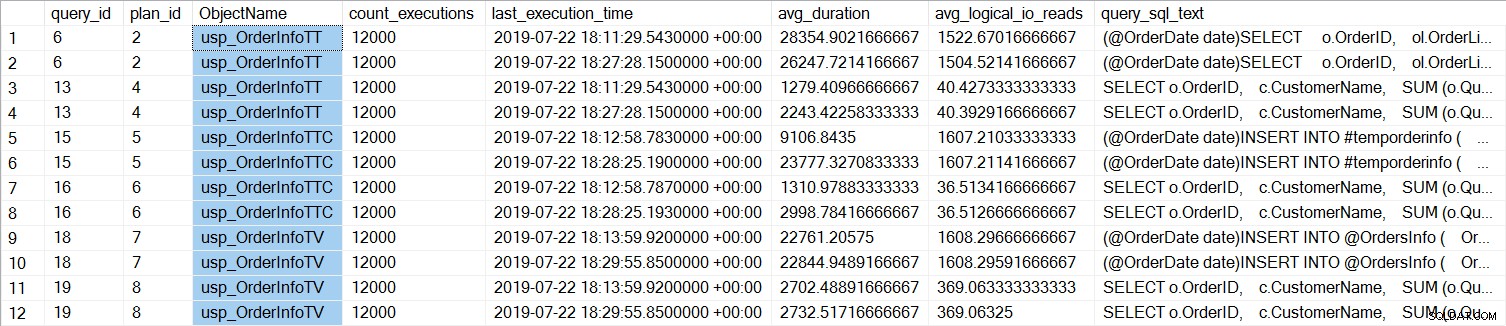
Die Abfragedauer ist für alle Abfragen nahezu gleich, mit Ausnahme der Verlängerung der INSERT-Dauer, wenn die Tabelle vorab erstellt wird, was völlig unerwartet ist. Wir sehen eine interessante Änderung in den Wartestatistiken:
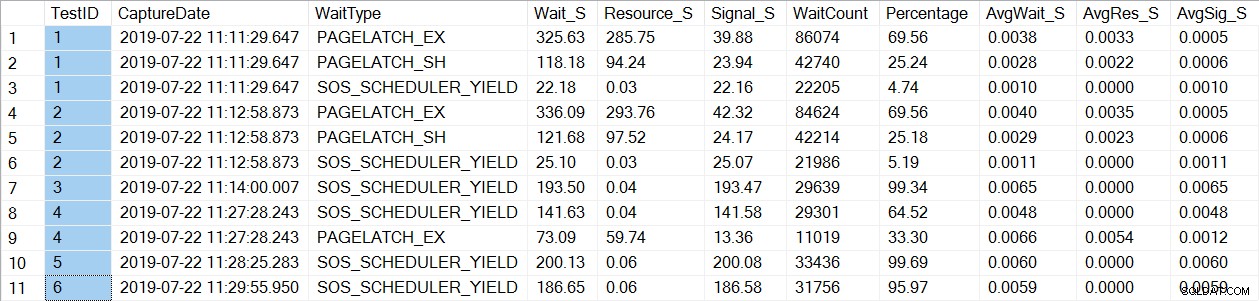
Für usp_OrderInfoTT wird ein SELECT … INTO ausgeführt, um die temporäre Tabelle zu erstellen. Die Wartezeiten ändern sich von PAGELATCH_EX und PAGELATCH_SH zu nur PAGEATCH_EX und SOS_SCHEDULER_YIELD. Wir sehen die PAGELATCH_SH-Wartezeiten nicht mehr.
Für usp_OrderInfoTTC, das die temporäre Tabelle erstellt und dann einfügt, werden die Wartezeiten PAGELATCH_EX und PAGELATCH_SH nicht mehr angezeigt, und wir sehen nur die Wartezeiten SOS_SCHEDULER_YIELD.
Schließlich sind die Wartezeiten für OrderInfoTV konsistent – nur SOS_SCHEDULER_YIELD, mit fast der gleichen Gesamtwartezeit.
Zusammenfassung
Basierend auf diesen Tests sehen wir in allen Fällen eine Verbesserung, insbesondere bei den gespeicherten Prozeduren mit temporären Tabellen. Für das Tabellenvariablenverfahren gibt es eine kleine Änderung. Es ist äußerst wichtig, sich daran zu erinnern, dass dies ein Szenario mit einem kleinen Lasttest ist. Ich war sehr daran interessiert, diese drei sehr einfachen Szenarien auszuprobieren, um zu versuchen und zu verstehen, was am meisten davon profitieren könnte, die tempdb-Metadaten speicheroptimiert zu machen. Diese Arbeitslast war klein und lief nur für eine sehr begrenzte Zeit – tatsächlich hatte ich vielfältigere Ergebnisse mit mehr Threads, was es wert ist, in einem anderen Beitrag näher untersucht zu werden. Der größte Vorteil ist, dass, wie bei allen neuen Features und Funktionen, das Testen wichtig ist. Für diese Funktion möchten Sie eine Basislinie der aktuellen Leistung haben, mit der Sie Metriken wie Batch-Anforderungen/Sek. und Wartestatistiken vergleichen können, nachdem Sie die Metadaten speicheroptimiert gemacht haben.
Zusätzliche Überlegungen
Die Verwendung von In-Memory OLTP erfordert eine Dateigruppe vom Typ MEMORY OPTIMIZED DATA. Nach dem Aktivieren von MEMORY_OPTIMIZED TEMPDB_METADATA wird jedoch keine zusätzliche Dateigruppe für tempdb erstellt. Außerdem ist nicht bekannt, ob die speicheroptimierten Tabellen dauerhaft sind (SCHEMA_AND_DATA) oder nicht (SCHEMA_ONLY). Typischerweise kann dies über sys.tables (durability_desc) ermittelt werden, aber für die beteiligten Systemtabellen wird nichts zurückgegeben, wenn dies in tempdb abgefragt wird, selbst wenn die dedizierte Administratorverbindung verwendet wird. Sie haben die Möglichkeit, nicht gruppierte Indizes für die speicheroptimierten Tabellen anzuzeigen. Sie können die folgende Abfrage verwenden, um zu sehen, welche Tabellen in tempdb speicheroptimiert sind:
SELECT * FROM tempdb.sys.dm_db_xtp_object_stats x JOIN tempdb.sys.objects o ON x.object_id = o.object_id JOIN tempdb.sys.schemas s ON o.schema_id = s.schema_id;
Führen Sie dann für jede der Tabellen sp_helpindex aus, zum Beispiel:
EXEC sys.sp_helpindex N'sys.sysobjvalues';

Beachten Sie, dass, wenn es sich um einen Hash-Index handelt (der die Schätzung von BUCKET_COUNT als Teil der Erstellung erfordert), die Beschreibung „nicht gruppierter Hash“ enthalten würde.