Eine meiner größten Freuden als Entwickler ist es, zu lernen, wie sich verschiedene Technologien überschneiden.
Im Laufe der Jahre hatte ich die Gelegenheit, mit verschiedenen Arten von Software und Tools zu arbeiten. Von den vielen Tools, die ich verwendet habe, sind Python und Structured Query Language (SQL) zwei meiner Favoriten.
In diesem Artikel werde ich mit Ihnen teilen, wie Python und die verschiedenen SQL-Datenbanken interagieren.
Ich werde über die beliebtesten Datenbanken sprechen, SQLite, MySQL und PostgreSQL. Ich werde die wichtigsten Unterschiede der einzelnen Datenbanken und die entsprechenden Anwendungsfälle erläutern. Und ich werde den Artikel mit etwas Python-Code beenden.
Der Code zeigt Ihnen, wie Sie eine SQL-Abfrage schreiben, um Daten aus einer PostgreSQL-Datenbank abzurufen und die Daten in einem Pandas-Datenrahmen zu speichern.
Wenn Sie mit relationalen Datenbanken (RDBMS) nicht vertraut sind, schlage ich vor, dass Sie hier Sameers Artikel über die grundlegende RDBMS-Terminologie lesen. Der Rest des Artikels verwendet Begriffe, auf die in Sameers Artikel verwiesen wird.
Beliebte SQL-Datenbanken
SQLite
SQLite ist vor allem als integrierte Datenbank bekannt. Das bedeutet, dass Sie keine zusätzliche Anwendung installieren oder einen separaten Server verwenden müssen, um die Datenbank auszuführen.
Wenn Sie ein MVP erstellen oder nicht viel Datenspeicherplatz benötigen, sollten Sie sich für eine SQLite-Datenbank entscheiden.
Die Vorteile sind, dass Sie mit einer SQLite-Datenbank im Vergleich zu MySQL und PostgreSQL schneller vorankommen. Das heißt, Sie werden mit eingeschränkter Funktionalität stecken bleiben. Sie können keine Funktionen anpassen oder eine Menge Mehrbenutzerfunktionen hinzufügen.
MySQL/PostgreSQL
Es gibt deutliche Unterschiede zwischen MySQL und PostgreSQL. Angesichts des Kontexts des Artikels fallen sie jedoch in eine ähnliche Kategorie.
Beide Datenbanktypen eignen sich hervorragend für Unternehmenslösungen. Wenn Sie schnell skalieren müssen, sind MySQL und PostgreSQL die beste Wahl. Sie stellen eine langfristige Infrastruktur bereit und stärken Ihre Sicherheit.
Ein weiterer Grund, warum sie sich hervorragend für Unternehmen eignen, ist, dass sie Hochleistungsaktivitäten bewältigen können. Längere Insert-, Update- und Select-Anweisungen benötigen viel Rechenleistung. Sie können diese Anweisungen mit geringerer Latenz schreiben, als dies bei einer SQLite-Datenbank der Fall wäre.
Warum Python und eine SQL-Datenbank verbinden?
Sie fragen sich vielleicht:„Warum sollte es mich interessieren, Python und eine SQL-Datenbank zu verbinden?“
Es gibt viele Anwendungsfälle, wenn jemand Python mit einer SQL-Datenbank verbinden möchte. Wie ich bereits erwähnt habe, arbeiten Sie möglicherweise an einer Webanwendung. In diesem Fall müssten Sie eine SQL-Datenbank verbinden, damit Sie die Daten aus der Webanwendung speichern können.
Vielleicht arbeiten Sie in der Datentechnik und müssen eine automatisierte ETL-Pipeline aufbauen. Wenn Sie Python mit einer SQL-Datenbank verbinden, können Sie Python für seine Automatisierungsfunktionen verwenden. Sie können auch zwischen verschiedenen Datenquellen kommunizieren. Sie müssen nicht zwischen verschiedenen Programmiersprachen wechseln.
Die Verbindung von Python und einer SQL-Datenbank wird auch Ihre Data-Science-Arbeit komfortabler machen. Sie können Ihre Python-Kenntnisse nutzen, um Daten aus einer SQL-Datenbank zu manipulieren. Sie benötigen keine CSV-Datei.
Wie Python- und SQL-Datenbanken verbunden werden

Python- und SQL-Datenbanken verbinden sich über benutzerdefinierte Python-Bibliotheken. Sie können diese Bibliotheken in Ihr Python-Skript importieren.
Als ergänzende Anleitung dienen datenbankspezifische Python-Bibliotheken. Diese Anweisungen zeigen Ihrem Computer, wie er mit Ihrer SQL-Datenbank interagieren kann. Andernfalls ist Ihr Python-Code eine Fremdsprache für die Datenbank, mit der Sie sich verbinden möchten.
So richten Sie das Projekt ein
Nehmen wir zum Beispiel eine PostgreSQL-Datenbank, AWS Redshift. Zuerst möchten Sie die psycopg-Bibliothek importieren. Es ist eine universelle Python-Bibliothek für PostgreSQL-Datenbanken.
#Library for connecting to AWS Redshift
import psycopg
#Library for reading the config file, which is in JSON
import json
#Data manipulation library
import pandas as pdSie werden feststellen, dass wir auch die JSON- und Pandas-Bibliotheken importiert haben. Wir haben JSON importiert, da das Erstellen einer JSON-Konfigurationsdatei eine sichere Methode zum Speichern Ihrer Datenbankanmeldeinformationen ist. Wir wollen nicht, dass jemand anderes sie ansieht!
Mit der Pandas-Bibliothek können Sie alle statistischen Funktionen von Pandas für Ihr Python-Skript verwenden. In diesem Fall ermöglicht die Bibliothek Python, die Daten, die Ihre SQL-Abfrage zurückgibt, in einem Datenrahmen zu speichern.
Als nächstes möchten Sie auf Ihre Konfigurationsdatei zugreifen. Die json.load() liest die JSON-Datei, sodass Sie im nächsten Schritt auf Ihre Datenbankanmeldeinformationen zugreifen können.
config_file = open(r"C:\Users\yourname\config.json")
config = json.load(config_file)
Da Ihr Python-Skript nun auf Ihre JSON-Konfigurationsdatei zugreifen kann, sollten Sie eine Datenbankverbindung erstellen. Sie müssen die Anmeldeinformationen aus Ihrer Konfigurationsdatei lesen und verwenden:
con = psycopg2.connect(dbname= "db_name", host=config[hostname], port = config["port"],user=config["user_id"], password=config["password_key"])
cur = con.cursor()Sie haben gerade eine Datenbankverbindung erstellt! Beim Importieren der psycopg-Bibliothek haben Sie den oben geschriebenen Python-Code übersetzt, um mit der PostgreSQL-Datenbank (AWS Redshift) zu kommunizieren.
An sich würde AWS Redshift den obigen Code nicht verstehen. Aber weil Sie die psycopg-Bibliothek importiert haben, sprechen Sie jetzt eine Sprache, die AWS Redshift verstehen kann.
Das Schöne an Python ist, dass es Bibliotheken für SQLite, MySQL und PostgreSQL hat. Sie können die Technologien problemlos integrieren.
So schreiben Sie eine SQL-Abfrage
Fühlen Sie sich frei, die europäischen Fußballdaten in Ihre PostgreSQL-Datenbank herunterzuladen. Ich werde seine Daten für dieses Beispiel verwenden.
Mit der im letzten Schritt erstellten Datenbankverbindung können Sie SQL schreiben, um die Daten dann in einer Python-freundlichen Datenstruktur zu speichern. Nachdem Sie nun eine Datenbankverbindung hergestellt haben, können Sie eine SQL-Abfrage schreiben, um mit dem Abrufen von Daten zu beginnen:
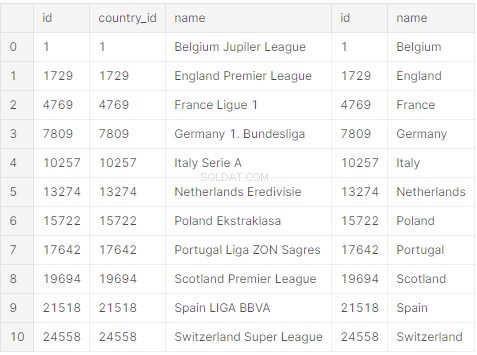
query = "SELECT *
FROM League
JOIN Country ON Country.id = League.country_id;"Die Arbeit ist aber noch nicht getan. Sie müssen zusätzlichen Python-Code schreiben, der die SQL-Abfrage ausführt:
#Runs your SQL query
execute1 = cur.execute(query)
result = cur.fetchall()Dann müssen Sie die zurückgegebenen Daten in einem Pandas-Datenrahmen speichern:
#Create initial dataframe from SQL data
raw_initial_df = pd.read_sql_query(query, con)
print(raw_initial_df)Sie sollten einen Pandas-Datenrahmen (raw_initial_df) erhalten, der etwa so aussieht:
Es gibt eine Datenbank für alle

SQLite, MySQL und PostgreSQL haben alle ihre Vor- und Nachteile. Welche Sie auswählen, sollte von den Anforderungen Ihres Projekts oder Unternehmens abhängen. Sie sollten auch überlegen, was Sie jetzt im Vergleich zu mehreren Jahren benötigen.
Es ist wichtig, sich daran zu erinnern, dass Python in jeden Datenbanktyp integriert werden kann.
Dieser Artikel kratzt an der Oberfläche dessen, was durch die Verbindung von Python mit einer SQL-Datenbank möglich ist. Ich liebe es zu sehen, wie sich Software überschneidet und kombiniert, um einen unglaublichen Mehrwert zu schaffen.
Wenn Sie mehr von dieser Art von Inhalten möchten, finden Sie mich unter Course to Hire! Ich möchte mehr Menschen dabei helfen, Programmieren zu lernen und einen Job in der Technik zu bekommen. Bitte melde dich bei Fragen oder wenn du einfach nur Hallo sagen möchtest :)