Einführung
Spult zurück sind spezifisch für Operatoren auf der Innenseite einer verschachtelten Schleife Join oder gelten. Die Idee ist, zuvor berechnete Ergebnisse aus einem Teil eines Ausführungsplans wiederzuverwenden, wo dies sicher ist.
Das kanonische Beispiel für einen Planoperator, der zurückspulen kann, ist die faule Table Spool . Seine Daseinsberechtigung besteht darin, Ergebniszeilen aus einem Plan-Unterbaum zwischenzuspeichern und diese Zeilen dann bei nachfolgenden Iterationen wiederzugeben, wenn irgendwelche korrelierten Schleifenparameter unverändert sind. Das Wiedergeben von Zeilen kann billiger sein als das erneute Ausführen des Teilbaums, der sie generiert hat. Weitere Hintergrundinformationen zu diesen Leistungsspulen siehe meinen vorherigen Artikel.
Die Dokumentation sagt, dass nur die folgenden Operatoren zurückspulen können:
- Tabellenspule
- Zeilenzähler
- Nonclustered Index Spool
- Tabellenwertfunktion
- Sortieren
- Fernabfrage
- Bestätigen und Filtern Operatoren mit einem Startausdruck
Die ersten drei Elemente sind meistens Leistungsspulen, obwohl sie aus anderen Gründen eingeführt werden können (wenn sie sowohl eifrig als auch faul sein können).
Tabellenwertfunktionen Verwenden Sie eine Tabellenvariable, die unter geeigneten Umständen zum Zwischenspeichern und Wiedergeben von Ergebnissen verwendet werden kann. Wenn Sie sich für das Zurückspulen von Tabellenwertfunktionen interessieren, lesen Sie bitte meine Fragen und Antworten zu Database Administrators Stack Exchange.
Abgesehen davon, geht es in diesem Artikel ausschließlich um Sorten und wann sie zurückspulen können.
Rückläufe sortieren
Sortierungen verwenden Speicherplatz (Arbeitsspeicher und vielleicht Festplatte, wenn sie verschüttet werden), also haben sie eine Einrichtung, die fähig ist Zeilen zwischen Schleifeniterationen zu speichern. Insbesondere die sortierte Ausgabe kann grundsätzlich wiedergegeben (zurückgespult) werden.
Dennoch ist die kurze Antwort auf die Titelfrage „Do Sorts Rewind?“ ist:
Ja, aber Sie werden es nicht oft sehen.
Sortierungstypen
Sortierungen gibt es intern in vielen verschiedenen Arten, aber für unsere aktuellen Zwecke gibt es nur zwei:
- In-Memory-Sortierung (
CQScanInMemSortNew).- Immer im Speicher; kann nicht verschütten auf die Festplatte.
- Verwendet die Schnellsortierung der Standardbibliothek.
- Maximal 500 Zeilen und zwei 8-KB-Seiten insgesamt.
- Alle Eingaben müssen Laufzeitkonstanten sein. Typischerweise bedeutet dies, dass der gesamte Sortier-Unterbaum aus nur bestehen muss Ständiger Scan und/oder Skalar berechnen Betreiber.
- In Ausführungsplänen nur explizit unterscheidbar, wenn ausführlicher Showplan aktiviert ist (Ablaufverfolgungsflag 8666). Dies fügt der Sortierung zusätzliche Eigenschaften hinzu Operator, einer davon ist „InMemory=[0|1]“.
- Alle anderen Sorten.
(Beide Arten von Sortieren Betreiber enthalten ihre Top N Sort und Eindeutige Sortierung Varianten).
Rücklaufverhalten
-
In-Memory-Sortierungen kann immer zurückspulen wenn es sicher ist. Wenn es keine korrelierten Schleifenparameter gibt oder die Parameterwerte gegenüber der unmittelbar vorherigen Iteration unverändert sind, kann diese Art von Sortierung ihre gespeicherten Daten wiedergeben, anstatt die darunter liegenden Operatoren im Ausführungsplan erneut auszuführen.
-
Nicht im Speicher befindliche Sortierungen kann zurückspulen wenn sicher, aber nur, wenn die Sortierung Operator enthält höchstens eine Zeile . Bitte beachten Sie eine Sortierung input kann bei einigen Iterationen eine Zeile bereitstellen, bei anderen jedoch nicht. Das Laufzeitverhalten kann daher eine komplexe Mischung aus Rewinds und Rebinds sein. Es hängt ganz davon ab, wie viele Zeilen für die Sortierung bereitgestellt werden bei jeder Iteration zur Laufzeit. Sie können im Allgemeinen nicht vorhersagen, was für eine Sortierung bei jeder Iteration tun, indem sie den Ausführungsplan überprüfen.
Das Wort „sicher“ in den obigen Beschreibungen bedeutet:Entweder wurde keine Parameteränderung vorgenommen, oder es gab keine Operatoren unterhalb der Sortierung haben eine Abhängigkeit vom geänderten Wert.
Wichtiger Hinweis zu Ausführungsplänen
Ausführungspläne melden Rewinds (und Rebinds) nicht immer korrekt für Sortieren Betreiber. Der Betreiber wird melden ein Zurückspulen, wenn irgendwelche korrelierten Parameter unverändert sind, andernfalls ein erneutes Binden.
Bei Nicht-Speicher-Sortierungen (bei weitem die häufigsten) gibt ein gemeldeter Rücklauf die gespeicherten Sortierergebnisse nur dann tatsächlich wieder, wenn höchstens eine Zeile im Sortierausgabepuffer vorhanden ist. Andernfalls wird die Sortierung melden ein Zurückspulen, aber der Teilbaum wird immer noch vollständig neu ausgeführt (eine Neubindung).
Unter Anzahl der Ausführungen können Sie überprüfen, wie viele gemeldete Zurückspulen tatsächlich zurückgespult wurden -Eigenschaft für Operatoren unterhalb von Sortieren .
Geschichte und meine Erklärung
Die Sortierung Das Rewind-Verhalten des Operators mag seltsam erscheinen, aber es war (mindestens) von SQL Server 2000 bis einschließlich SQL Server 2019 (sowie Azure SQL Database) so. Ich konnte keine offizielle Erklärung oder Dokumentation dazu finden.
Meine persönliche Ansicht ist das Sortieren Zurückspulen ist aufgrund der zugrunde liegenden Sortiermaschinerie, einschließlich Überlaufeinrichtungen, und der Verwendung von Systemtransaktionen in tempdb ziemlich teuer .
In den meisten Fällen ist es für den Optimierer besser, einen expliziten Performance-Spool einzuführen wenn es die Möglichkeit doppelter korrelierter Schleifenparameter erkennt. Spools sind die kostengünstigste Möglichkeit, Teilergebnisse zwischenzuspeichern.
Es ist möglich das Wiedergeben eines Sortierens Ergebnis wäre nur kostengünstiger als eine Spule beim Sortieren enthält höchstens eine Zeile. Schließlich beinhaltet das Sortieren einer Zeile (oder keiner Zeilen!) überhaupt keine Sortierung, so dass viel Overhead vermieden werden kann.
Reine Spekulation, aber irgendjemand musste fragen, also da ist es.
Demo 1:Ungenaues Zurückspulen
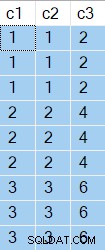
Dieses erste Beispiel enthält zwei Tabellenvariablen. Die erste enthält drei Werte, die dreimal in Spalte c1 dupliziert wurden . Die zweite Tabelle enthält zwei Zeilen für jede Übereinstimmung auf c2 = c1 . Die beiden übereinstimmenden Zeilen werden durch einen Wert in Spalte c3 unterschieden .
Die Aufgabe besteht darin, die Zeile aus der zweiten Tabelle mit dem höchsten c3 zurückzugeben Wert für jede Übereinstimmung auf c1 = c2 . Der Code ist wahrscheinlich klarer als meine Erklärung:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
INSERT @T2
(c2, c3)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Der NO_PERFORMANCE_SPOOL Hint ist da, um zu verhindern, dass der Optimierer eine Performance-Spule einführt. Dies kann bei Tabellenvariablen passieren, wenn z.B. Das Trace-Flag 2453 ist aktiviert, oder die verzögerte Kompilierung von Tabellenvariablen ist verfügbar, sodass der Optimierer die wahre Kardinalität der Tabellenvariablen sehen kann (aber nicht die Werteverteilung).
Die Abfrageergebnisse zeigen den c2 und c3 die zurückgegebenen Werte sind für jeden einzelnen c1 gleich Wert:
Der eigentliche Ausführungsplan für die Abfrage ist:
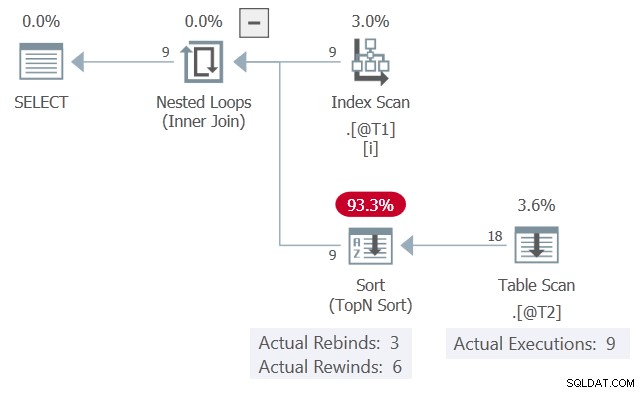
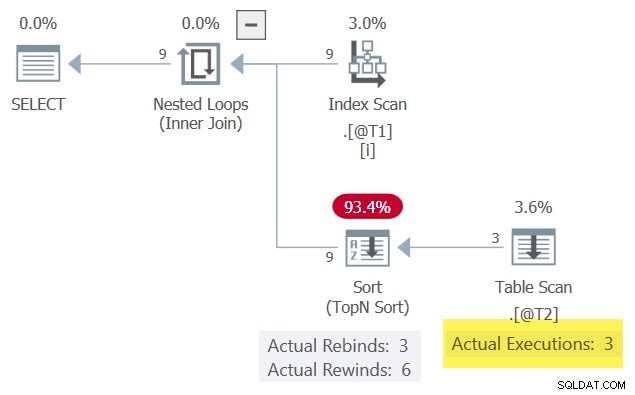
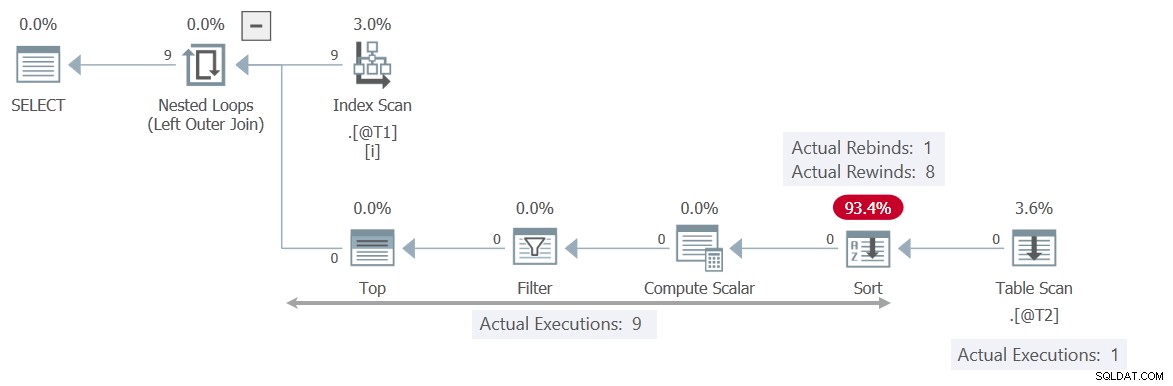
Der c1 Werte, die der Reihe nach präsentiert werden, stimmen 6 Mal mit der vorherigen Iteration überein und ändern sich 3 Mal. Die Sortierung meldet dies als 6 Rückspulungen und 3 Neubindungen.
Wenn das wahr wäre, dann der Table Scan würde nur 3 mal ausführen. Die Sortierung würde seine Ergebnisse bei den anderen 6 Gelegenheiten wiederholen (zurückspulen).
So wie es ist, können wir den Table Scan sehen wurde 9 Mal ausgeführt, einmal für jede Zeile aus Tabelle @T1 . Hier wurde nicht zurückgespult .
Demo 2:Rückspulen sortieren
Das vorherige Beispiel ließ die Sortierung nicht zu zurückspulen, weil (a) es keine In-Memory-Sortierung ist; und (b) bei jeder Iteration der Schleife das Sortieren enthielt zwei Reihen. Plan Explorer zeigt insgesamt 18 Zeilen aus dem Table Scan , zwei Zeilen für jede von 9 Iterationen.
Optimieren wir das Beispiel jetzt so, dass es nur einen gibt Zeile in der Tabelle @T2 für jede übereinstimmende Zeile von @T1 :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Only one matching row per iteration now
INSERT @T2
(c2, c3)
VALUES
--(1, 1),
(1, 2),
--(2, 3),
(2, 4),
--(3, 5),
(3, 6);
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
CROSS APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Die Ergebnisse sind die gleichen wie zuvor gezeigt, da wir die übereinstimmende Zeile beibehalten haben, die in Spalte c3 am höchsten sortiert wurde . Der Ausführungsplan ist auch oberflächlich ähnlich, aber mit einem wichtigen Unterschied:
Mit einer Zeile in der Sortierung Es kann jederzeit zurückgespult werden, wenn der korrelierte Parameter c1 ändert sich nicht. Der Table Scan wird dadurch nur 3 mal ausgeführt.
Beachten Sie die Sortierung erzeugt mehr Zeilen (9) als es (3) erhält. Dies ist ein guter Hinweis darauf, dass eine Sortierung hat es geschafft, eine Ergebnismenge ein- oder mehrmals zwischenzuspeichern – ein erfolgreicher Rücklauf.
Demo 3:Nichts zurückspulen
Ich erwähnte zuvor eine Nicht-Speicher-Sortierung kann zurückspulen, wenn es höchstens enthält eine Zeile.
Um das in Aktion mit null Zeilen zu sehen , wechseln wir zu einem OUTER APPLY und fügen Sie keine Zeilen in die Tabelle @T2 ein . Aus Gründen, die in Kürze ersichtlich werden, werden wir auch die Projektion der Spalte c2 einstellen :
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- No rows added to table @T2
-- No longer projecting c2
SELECT
T1.c1,
--CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
--T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
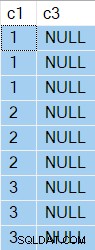
Die Ergebnisse haben jetzt NULL in Spalte c3 wie erwartet:
Der Ausführungsplan ist:
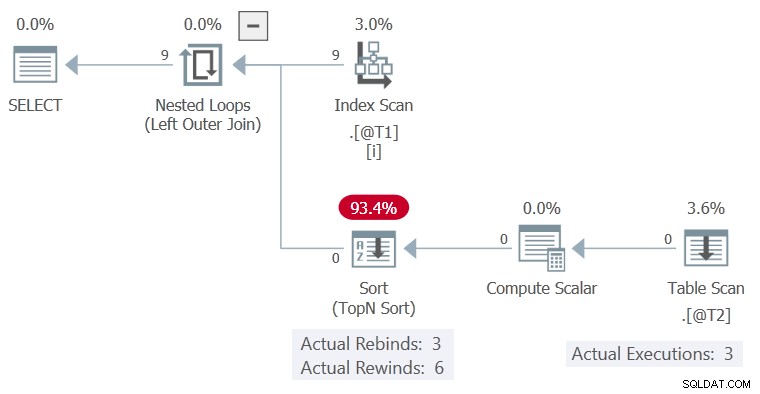
Die Sortierung konnte ohne Zeilen in seinem Puffer zurückspulen, also der Table Scan wurde nur 3 mal ausgeführt, jeweils Spalte c1 geänderter Wert.
Demo 4:Maximaler Rücklauf!
Wie die anderen Operatoren, die Zurückspulen unterstützen, ist ein Sortieren wird nur neu gebunden seinen Teilbaum, wenn sich ein korrelierter Parameter und geändert hat der Unterbaum hängt irgendwie von diesem Wert ab.
Wiederherstellung der Spalte c2 Projektion auf Demo 3 zeigt dies in Aktion:
DECLARE @T1 table (c1 integer NOT NULL INDEX i);
DECLARE @T2 table (c2 integer NOT NULL, c3 integer NOT NULL);
INSERT @T1
(c1)
VALUES
(1), (1), (1),
(2), (2), (2),
(3), (3), (3);
-- Still no rows in @T2
-- Column c2 is back!
SELECT
T1.c1,
CA.c2,
CA.c3
FROM @T1 AS T1
OUTER APPLY
(
SELECT TOP (1)
T2.c2,
T2.c3
FROM @T2 AS T2
WHERE
T2.c2 = T1.c1
ORDER BY
T2.c3 DESC
) AS CA
ORDER BY T1.c1 ASC
OPTION (NO_PERFORMANCE_SPOOL);
Die Ergebnisse zeigen jetzt zwei NULL Spalten natürlich:
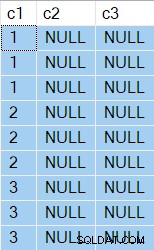
Der Ausführungsplan ist ganz anders:
Diesmal der Filter enthält die Prüfung T2.c2 = T1.c1 , indem Sie den Table Scan erstellen unabhängig des aktuellen Werts des korrelierten Parameters c1 . Die Sortierung kann sicher 8 Mal zurückspulen, was bedeutet, dass der Scan nur einmal ausgeführt wird .
Demo 5:In-Memory-Sortierung
Das nächste Beispiel zeigt eine In-Memory Sortierung Betreiber:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
(REPLICATE('Z', 1390)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL); Die Ergebnisse, die Sie erhalten, variieren von Ausführung zu Ausführung, aber hier ist ein Beispiel:
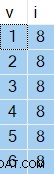
Das Interessante sind die Werte in Spalte i wird immer gleich sein – trotz ORDER BY NEWID() Klausel.
Sie werden es wahrscheinlich schon erraten haben, der Grund dafür ist die Sortierung Zwischenspeichern von Ergebnissen (Zurückspulen). Der Ausführungsplan zeigt den Konstanten Scan nur einmal ausführen und insgesamt 11 Zeilen erzeugen:
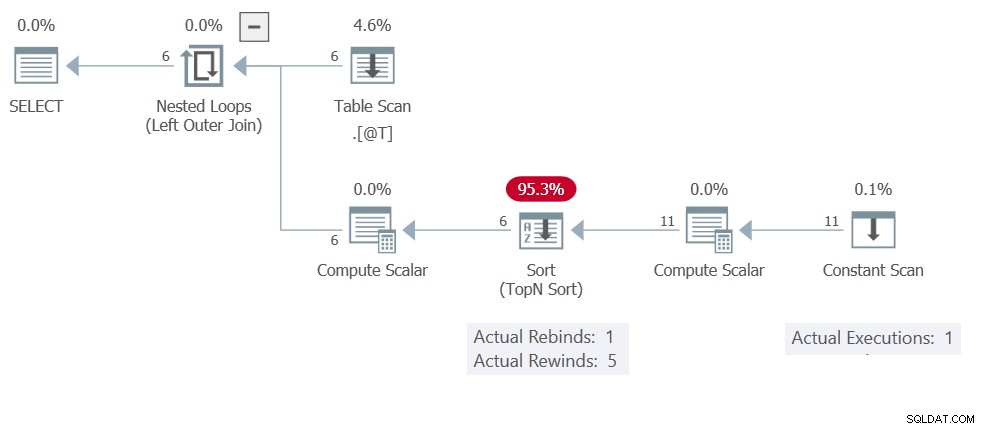
Diese Sortierung hat nur Skalar berechnen und Konstanter Scan Operatoren bei seiner Eingabe, so dass es sich um eine In Memory Sort handelt . Denken Sie daran, dass diese nicht auf höchstens eine einzelne Zeile beschränkt sind – sie können 500 Zeilen und 16 KB aufnehmen.
Wie bereits erwähnt, ist nicht explizit ersichtlich, ob ein Sort ist In-Memory oder nicht, indem Sie einen regulären Ausführungsplan überprüfen. Wir brauchen ausführliche Showplan-Ausgabe , aktiviert mit dem undokumentierten Ablaufverfolgungsflag 8666. Wenn dies aktiviert ist, werden zusätzliche Operatoreigenschaften angezeigt:
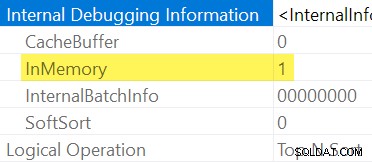
Wenn es nicht praktikabel ist, undokumentierte Ablaufverfolgungs-Flags zu verwenden, können Sie daraus eine Sortierung ableiten ist „InMemory“ durch seinen Input Memory Fraction Null ist, und Speichernutzung Elemente, die im Showplan nach der Ausführung nicht verfügbar sind (auf SQL Server-Versionen, die diese Informationen unterstützen).
Zurück zum Ausführungsplan:Es gibt keine korrelierten Parameter, also die Sortierung kann 5 Mal zurückgespult werden, was den Konstanten Scan bedeutet wird nur einmal ausgeführt. Fühlen Sie sich frei, den TOP (1) zu ändern bis TOP (3) oder was auch immer du magst. Das Zurückspulen bedeutet, dass die Ergebnisse für jede Eingabezeile gleich sind (zwischengespeichert/zurückgespult).
Möglicherweise stört Sie die ORDER BY NEWID() Klausel, die das Zurückspulen nicht verhindert. Dies ist in der Tat ein umstrittener Punkt, aber keineswegs auf eine Art beschränkt. Für eine ausführlichere Diskussion (Warnung:mögliches Kaninchenloch) lesen Sie bitte diese Fragen und Antworten. Die Kurzversion besagt, dass dies eine bewusste Entscheidung für das Produktdesign ist, um die Leistung zu optimieren, aber es gibt Pläne, das Verhalten im Laufe der Zeit intuitiver zu gestalten.
Demo 6:Keine In-Memory-Sortierung
Dies ist dasselbe wie Demo 5, außer dass die replizierte Zeichenfolge ein Zeichen länger ist:
DECLARE @T table (v integer NOT NULL);
INSERT @T
(v)
VALUES
(1), (2), (3),
(4), (5), (6);
SELECT
T.v,
OA.i
FROM @T AS T
OUTER APPLY
(
SELECT TOP (1)
X.i
FROM
(
VALUES
-- 1391 instead of 1390
(REPLICATE('Z', 1391)),
('0'), ('1'), ('2'), ('3'), ('4'),
('5'), ('6'), ('7'), ('8'), ('9')
) AS X (i)
ORDER BY NEWID()
) AS OA
OPTION (NO_PERFORMANCE_SPOOL);
Auch hier variieren die Ergebnisse je nach Ausführung, aber hier ist ein Beispiel. Beachten Sie das i Werte sind jetzt nicht alle gleich:

Das zusätzliche Zeichen reicht gerade aus, um die geschätzte Größe der sortierten Daten auf über 16 KB zu erhöhen. Dies bedeutet eine In-Memory-Sortierung kann nicht verwendet werden und die Rückspulungen verschwinden.
Der Ausführungsplan ist:
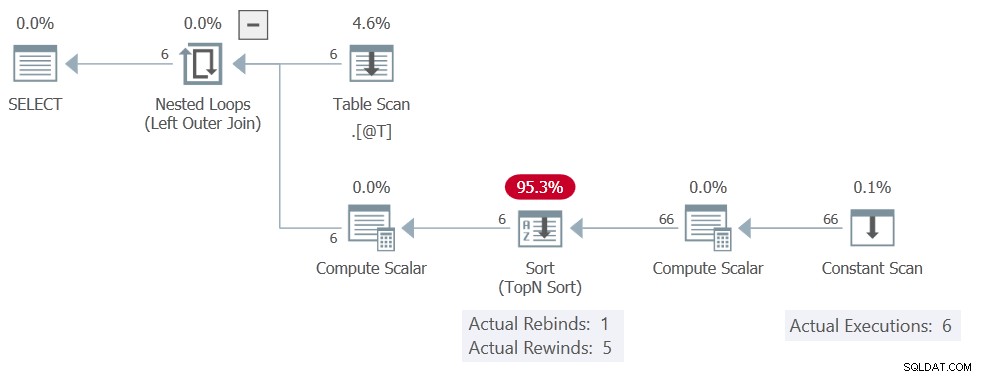
Die Sortierung noch Berichte 5 Rückspulen, aber der Konstante Scan wird 6 Mal ausgeführt, was bedeutet, dass wirklich kein Zurückspulen stattgefunden hat. Es erzeugt alle 11 Zeilen bei jeder der 6 Ausführungen, was insgesamt 66 Zeilen ergibt.
Zusammenfassung und abschließende Gedanken
Sie werden keine Sortierung sehen Betreiber wirklich sehr oft zurückspulen, obwohl Sie sehen werden, dass es sagt, dass es so ist ziemlich viel.
Denken Sie daran, eine regelmäßige Sortierung kann nur zurückspulen, wenn es sicher ist und Es gibt zu diesem Zeitpunkt maximal eine Zeile in der Sortierung. „Sicher“ bedeutet entweder keine Änderung der Schleifenkorrelationsparameter oder nichts unterhalb der Sortierung von den Parameteränderungen betroffen ist.
Eine In-Memory-Sortierung kann mit bis zu 500 Zeilen und 16 KB an Daten aus Constant Scan arbeiten und Skalar berechnen nur Betreiber. Es wird auch nur zurückgespult, wenn es sicher ist (Produktfehler beiseite!), ist aber nicht auf maximal eine Zeile beschränkt.
Dies mag wie esoterische Details erscheinen, und ich nehme an, dass sie es sind. Sie haben mir also geholfen, einen Ausführungsplan zu verstehen und mehr als einmal gute Leistungsverbesserungen zu finden. Vielleicht werden Sie die Informationen eines Tages auch nützlich finden.
Achten Sie auf Sorten die mehr Zeilen erzeugen, als sie in ihrer Eingabe haben!
Wenn Sie ein realistischeres Beispiel für Sortieren sehen möchten Rückspulen basierend auf einer Demo, die Itzik Ben-Gan in Teil eins seines Closest Match bereitgestellt hat Serien finden Sie unter Nächste Übereinstimmung mit Sort Rewinds.