Vor langer Zeit habe ich eine Frage zu NULL auf Stack Exchange mit dem Titel „Warum sollten wir keine NULLen zulassen?“ beantwortet. Ich habe meinen Anteil an Ärgernissen und Leidenschaften, und die Angst vor NULLen steht ziemlich weit oben auf meiner Liste. Ein Kollege sagte kürzlich zu mir, nachdem er seine Präferenz geäußert hatte, einen leeren String zu erzwingen, anstatt NULL zuzulassen:
"Ich mag es nicht, mit Nullen im Code umzugehen."
Tut mir leid, aber das ist kein guter Grund. Wie die Präsentationsschicht mit leeren Zeichenfolgen oder NULL-Werten umgeht, sollte nicht der Treiber für Ihr Tabellendesign und Datenmodell sein. Und wenn Sie einen „Mangel an Wert“ in einer Spalte zulassen, ist es dann logisch für Sie von Bedeutung, ob der „Mangel an Wert“ durch eine Zeichenfolge der Länge Null oder durch eine NULL dargestellt wird? Oder noch schlimmer, ein Token-Wert wie 0 oder -1 für ganze Zahlen oder 1900-01-01 für Datumsangaben?
Itzik Ben-Gan hat kürzlich eine ganze Serie über NULLen geschrieben, und ich empfehle dringend, alles durchzugehen:
- NULL-Komplexitäten – Teil 1
- NULL-Komplexitäten – Teil 2
- NULL-Komplexitäten – Teil 3, Fehlende Standardfunktionen und T-SQL-Alternativen
- NULL-Komplexitäten – Teil 4, Fehlende eindeutige Standardbeschränkung
Aber mein Ziel hier ist etwas weniger kompliziert als das, nachdem das Thema in einer anderen Stack Exchange-Frage aufkam:„Fügen Sie ein Auto-Now-Feld zu einer vorhandenen Tabelle hinzu.“ Dort fügte der Benutzer einer vorhandenen Tabelle eine neue Spalte hinzu, um sie automatisch mit dem aktuellen Datum/der aktuellen Uhrzeit zu füllen. Sie fragten sich, ob sie NULLen in dieser Spalte für alle vorhandenen Zeilen belassen oder einen Standardwert festlegen sollten (wie 1900-01-01, vermutlich, obwohl sie nicht explizit waren).
Es mag für jemanden, der sich auskennt, einfach sein, alte Zeilen basierend auf einem Token-Wert herauszufiltern – wie könnte schließlich irgendjemand glauben, dass eine Art Bluetooth-Doodad am 1.1.1900 hergestellt oder gekauft wurde? Nun, ich habe das in aktuellen Systemen gesehen, wo sie ein willkürlich klingendes Datum in Ansichten verwenden, um als magischer Filter zu fungieren, der nur Zeilen präsentiert, bei denen der Wert vertrauenswürdig ist. Tatsächlich ist in jedem Fall, den ich bisher gesehen habe, das Datum in der WHERE-Klausel das Datum/die Uhrzeit, zu der die Spalte (oder ihre Standardeinschränkung) hinzugefügt wurde. Was alles in Ordnung ist; es ist vielleicht nicht der beste Weg, um das Problem zu lösen, aber es ist ein Weise.
Wenn Sie jedoch nicht über die Ansicht auf die Tabelle zugreifen, ist diese Implikation eines bekannten -Wert kann immer noch sowohl logische als auch ergebnisbezogene Probleme verursachen. Das logische Problem besteht einfach darin, dass jemand, der mit der Tabelle interagiert, wissen muss, dass 1900-01-01 ein falscher Token-Wert ist, der „unbekannt“ oder „nicht relevant“ darstellt. Um ein Beispiel aus der Praxis zu nennen, wie hoch war die durchschnittliche Release-Geschwindigkeit in Sekunden für einen Quarterback, der in den 1970er Jahren spielte, bevor wir so etwas gemessen oder verfolgt haben? Ist 0 ein guter Tokenwert für „unbekannt“? Wie wäre es mit -1? Oder 100? Zurück zu den Daten, wenn ein Patient ohne Ausweis ins Krankenhaus eingeliefert wird und bewusstlos ist, was sollte er als Geburtsdatum eintragen? Ich denke nicht, dass der 01.01.1900 eine gute Idee ist, und es war sicherlich keine gute Idee damals, als das eher ein echtes Geburtsdatum war.
Auswirkungen von Token-Werten auf die Leistung
Aus Leistungssicht können gefälschte oder „Token“-Werte wie 1900-01-01 oder 9999-21-31 Probleme verursachen. Schauen wir uns ein paar davon mit einem Beispiel an, das lose auf der oben erwähnten aktuellen Frage basiert. Wir haben eine Widgets-Tabelle und nach einigen Garantierückgaben haben wir uns entschieden, eine EnteredService-Spalte hinzuzufügen, in der wir das aktuelle Datum/die aktuelle Uhrzeit für neue Zeilen eingeben. In einem Fall belassen wir alle vorhandenen Zeilen auf NULL, und im anderen aktualisieren wir den Wert auf unser magisches Datum 1900-01-01. (Wir lassen vorerst jede Art von Komprimierung aus dem Gespräch.)
CREATE TABLE dbo.Widgets_NULL
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WNULL PRIMARY KEY (WidgetID)
);
CREATE TABLE dbo.Widgets_Token
(
WidgetID int IDENTITY(1,1) NOT NULL,
SerialNumber uniqueidentifier NOT NULL DEFAULT NEWID(),
Description nvarchar(500),
CONSTRAINT PK_WToken PRIMARY KEY (WidgetID)
); Jetzt fügen wir dieselben 100.000 Zeilen in jede Tabelle ein:
INSERT dbo.Widgets_NULL(Description)
OUTPUT inserted.Description INTO dbo.Widgets_Token(Description)
SELECT TOP (100000) LEFT(OBJECT_DEFINITION(o.object_id), 250)
FROM master.sys.all_objects AS o
CROSS JOIN (SELECT TOP (50) * FROM master.sys.all_objects) AS o2
WHERE o.[type] IN (N'P',N'FN',N'V')
AND OBJECT_DEFINITION(o.object_id) IS NOT NULL; Dann können wir die neue Spalte hinzufügen und 10 % der vorhandenen Werte mit einer Verteilung aktueller Daten und die anderen 90 % mit unserem Token-Datum nur in einer der Tabellen aktualisieren:
ALTER TABLE dbo.Widgets_NULL ADD EnteredService datetime;
ALTER TABLE dbo.Widgets_Token ADD EnteredService datetime;
GO
UPDATE dbo.Widgets_NULL
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = DATEADD(DAY, WidgetID/250, '20200101')
WHERE WidgetID > 90000;
UPDATE dbo.Widgets_Token
SET EnteredService = '19000101'
WHERE WidgetID <= 90000; Schließlich können wir Indizes hinzufügen:
CREATE INDEX IX_EnteredService ON dbo.Widgets_NULL (EnteredService); CREATE INDEX IX_EnteredService ON dbo.Widgets_Token(EnteredService);
Verwendeter Platz
Ich höre immer „Speicherplatz ist billig“, wenn wir über Datentypauswahl, Fragmentierung und Tokenwerte im Vergleich zu NULL sprechen. Meine Sorge gilt nicht so sehr dem Speicherplatz, den diese zusätzlichen bedeutungslosen Werte beanspruchen. Es ist mehr so, dass beim Abfragen der Tabelle Speicher verschwendet wird. Hier können wir uns schnell ein Bild davon machen, wie viel Platz unsere Token-Werte verbrauchen, bevor und nachdem die Spalte und der Index hinzugefügt wurden:
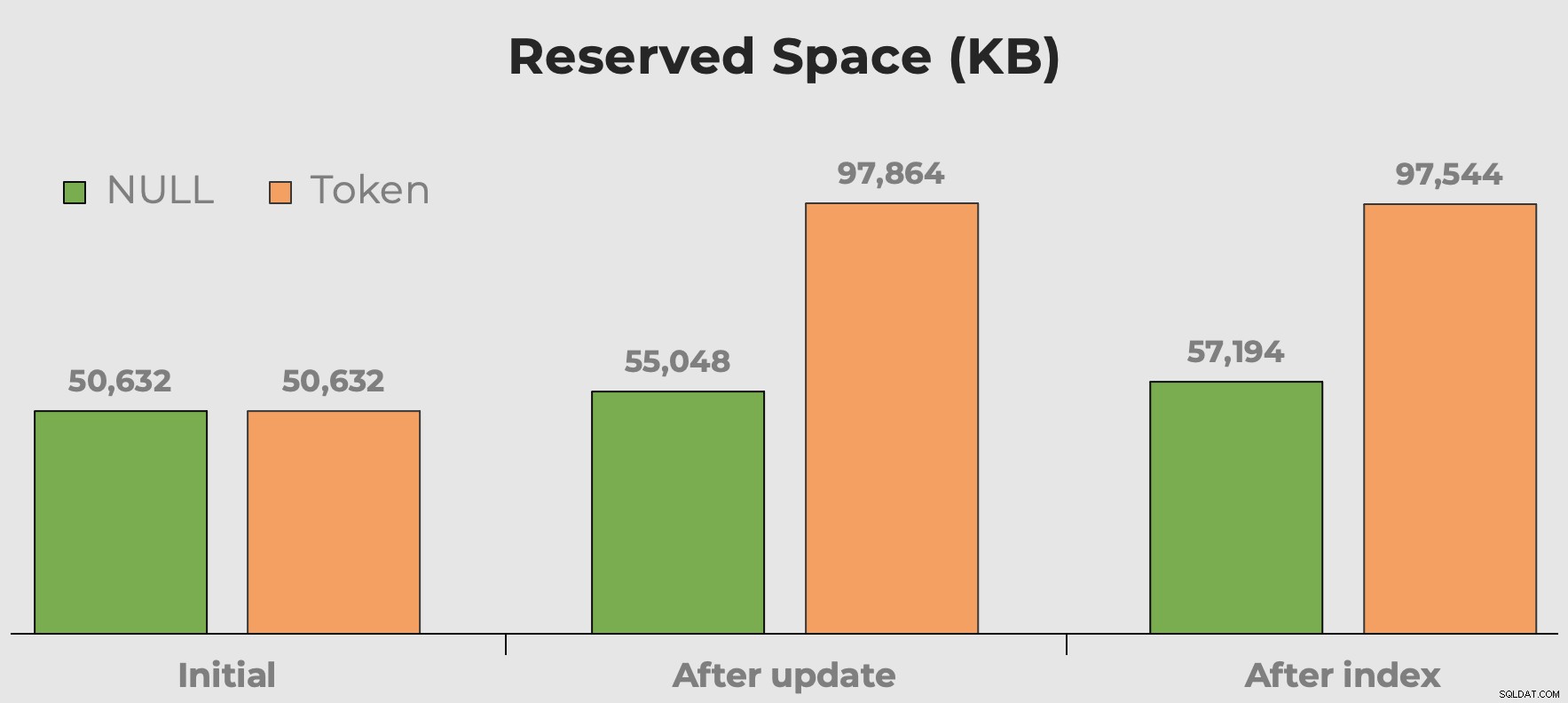 Reservierter Tabellenplatz nach dem Hinzufügen einer Spalte und eines Indexes. Der Platz verdoppelt sich fast mit Token-Werten.
Reservierter Tabellenplatz nach dem Hinzufügen einer Spalte und eines Indexes. Der Platz verdoppelt sich fast mit Token-Werten.
Abfrageausführung
Unweigerlich wird jemand Annahmen über die Daten in der Tabelle treffen und die Spalte „EnteredService“ abfragen, als ob alle Werte dort legitim wären. Zum Beispiel:
SELECT COUNT(*) FROM dbo.Widgets_Token
WHERE EnteredService <= '20210101';
SELECT COUNT(*) FROM dbo.Widgets_NULL
WHERE EnteredService <= '20210101'; Die Token-Werte können in einigen Fällen mit Schätzungen in Konflikt geraten, aber was noch wichtiger ist, sie werden zu falschen (oder zumindest unerwarteten) Ergebnissen führen. Hier ist der Ausführungsplan für die Abfrage der Tabelle mit Tokenwerten:
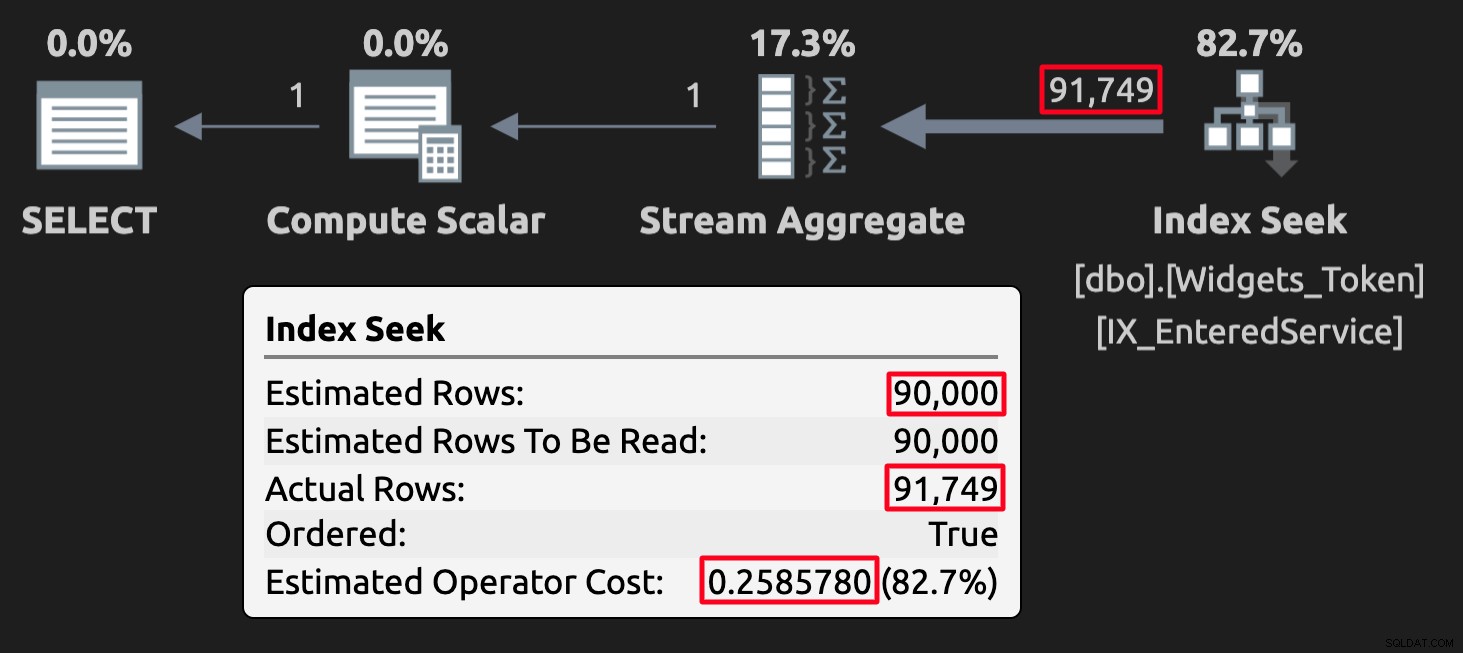 Ausführungsplan für die Token-Tabelle; Beachten Sie die hohen Kosten.
Ausführungsplan für die Token-Tabelle; Beachten Sie die hohen Kosten.
Und hier ist der Ausführungsplan für die Abfrage der Tabelle mit NULL-Werten:
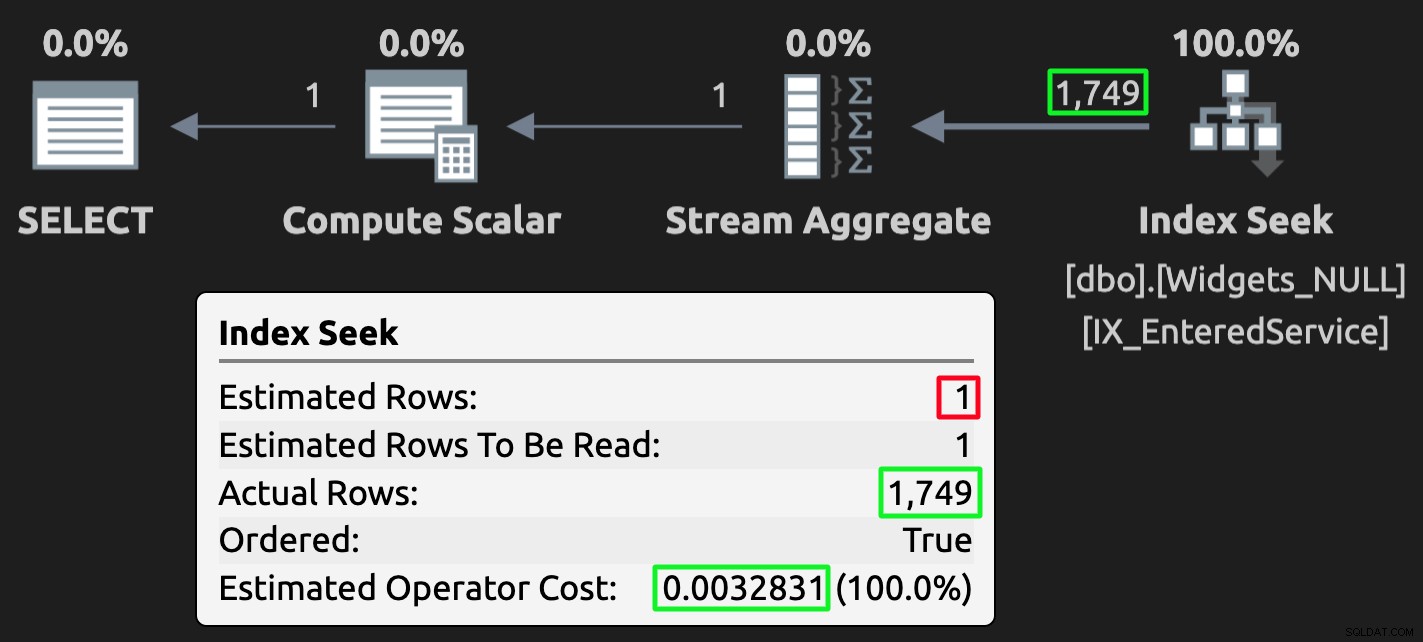 Ausführungsplan für die NULL-Tabelle; falsche Schätzung, aber viel niedrigere Kosten.
Ausführungsplan für die NULL-Tabelle; falsche Schätzung, aber viel niedrigere Kosten.
Dasselbe würde umgekehrt passieren, wenn die Abfrage nach>={some date} fragen würde und 9999-12-31 als magischer Wert verwendet würde, der unbekannt darstellt.
Nochmals, für die Leute, die zufällig wissen, dass die Ergebnisse falsch sind, insbesondere weil Sie Token-Werte verwendet haben, ist dies kein Problem. Aber alle anderen, die das nicht wissen – einschließlich zukünftiger Kollegen, anderer Erben und Betreuer des Codes und sogar Sie mit Gedächtnisproblemen – werden wahrscheinlich stolpern.
Schlussfolgerung
Die Entscheidung, NULLen in einer Spalte zuzulassen (oder NULLen ganz zu vermeiden), sollte nicht auf eine ideologische oder angstbasierte Entscheidung reduziert werden. Es gibt echte, greifbare Nachteile bei der Architektur Ihres Datenmodells, um sicherzustellen, dass kein Wert NULL sein kann, oder die Verwendung bedeutungsloser Werte, um etwas darzustellen, das leicht überhaupt nicht hätte gespeichert werden können. Ich schlage nicht vor, dass jede Spalte in Ihrem Modell NULL-Werte zulassen sollte; nur dass Sie nicht gegen die Idee sind von NULLen.



