Die Verfügbarkeit, Zugänglichkeit und Performance von Daten sind entscheidend für den Geschäftserfolg. Leistungsoptimierung und SQL-Abfrageoptimierung sind knifflige, aber notwendige Praktiken für Datenbankexperten. Sie erfordern die Betrachtung verschiedener Datensammlungen unter Verwendung von erweiterten Ereignissen, Leistungen, Ausführungsplänen, Statistiken und Indizes, um nur einige zu nennen. Manchmal bitten Anwendungseigentümer darum, die Systemressourcen (CPU und Arbeitsspeicher) zu erhöhen, um die Systemleistung zu verbessern. Möglicherweise benötigen Sie diese zusätzlichen Ressourcen jedoch nicht, und sie können mit Kosten verbunden sein. Manchmal sind lediglich geringfügige Verbesserungen erforderlich, um das Abfrageverhalten zu ändern.
In diesem Artikel besprechen wir einige Best Practices zur Optimierung von SQL-Abfragen, die beim Schreiben von SQL-Abfragen anzuwenden sind.
SELECT * vs. SELECT-Spaltenliste
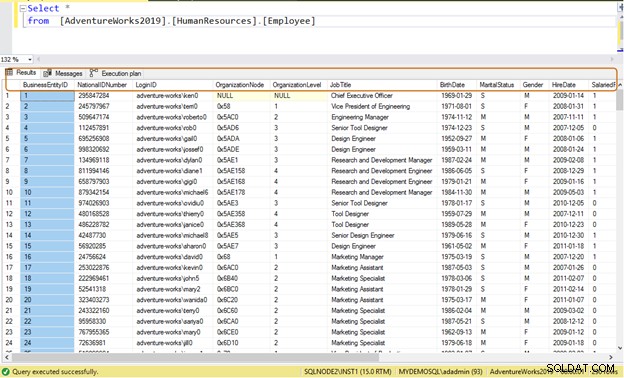
Normalerweise verwenden Entwickler die SELECT *-Anweisung, um Daten aus einer Tabelle zu lesen. Es liest alle verfügbaren Daten der Spalte in der Tabelle. Angenommen, eine Tabelle [AdventureWorks2019].[HumanResources].[Employee] speichert Daten für 290 Mitarbeiter und Sie müssen die folgenden Informationen abrufen:
- Nationale ID-Nummer des Mitarbeiters
- Geburtstag
- Geschlecht
- Einstellungsdatum
Ineffiziente Abfrage: Wenn Sie die Anweisung SELECT * verwenden, werden alle Daten der Spalte für alle 290 Mitarbeiter zurückgegeben.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
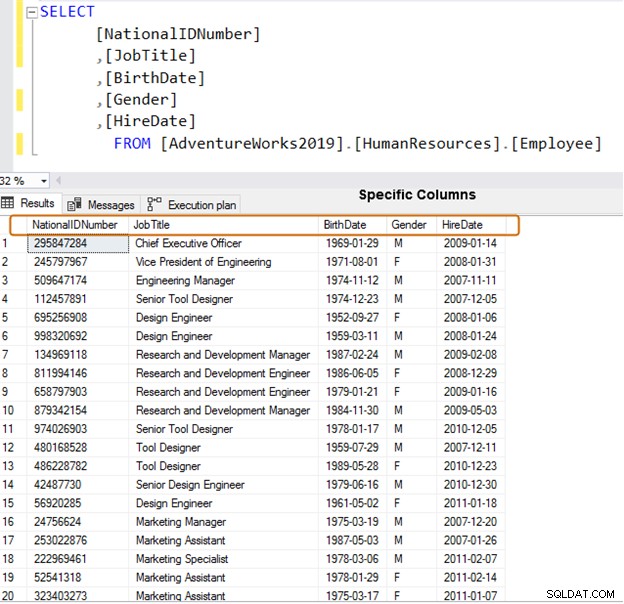
Verwenden Sie stattdessen bestimmte Spaltennamen für den Datenabruf.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
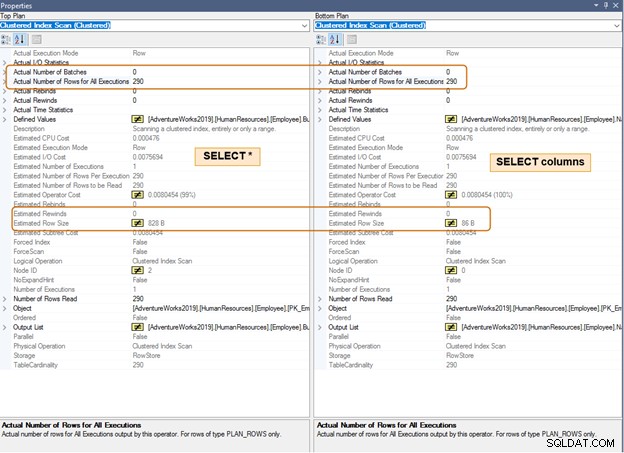
Beachten Sie im folgenden Ausführungsplan den Unterschied in der geschätzten Zeilengröße für die gleiche Anzahl von Zeilen. Sie werden auch für eine große Anzahl von Zeilen einen Unterschied in CPU und IO bemerken.
Verwendung von COUNT() vs. EXISTS
Angenommen, Sie möchten prüfen, ob ein bestimmter Datensatz in der SQL-Tabelle vorhanden ist. Normalerweise verwenden wir COUNT (*), um den Datensatz zu überprüfen, und es gibt die Anzahl der Datensätze in der Ausgabe zurück.
Zu diesem Zweck können wir jedoch die Funktion IF EXISTS() verwenden. Für den Vergleich habe ich die Statistik aktiviert, bevor ich die Abfragen ausgeführt habe.
Die Abfrage für COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
Die Abfrage für IF EXISTS()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
Ich habe Statisticsparser verwendet, um die Statistikergebnisse beider Abfragen zu analysieren. Sehen Sie sich die Ergebnisse unten an. Die Abfrage mit COUNT(*) hat 276 logische Lesevorgänge, während IF EXISTS() 83 logische Lesevorgänge hat. Mit IF EXISTS() können Sie sogar eine deutlichere Reduzierung der logischen Lesevorgänge erzielen. Daher sollten Sie es verwenden, um SQL-Abfragen für eine bessere Leistung zu optimieren.

Vermeiden Sie die Verwendung von SQL DISTINCT
Wann immer wir eindeutige Datensätze aus der Abfrage wünschen, verwenden wir gewöhnlich die SQL DISTINCT-Klausel. Angenommen, Sie haben zwei Tabellen miteinander verbunden, und in der Ausgabe werden die doppelten Zeilen zurückgegeben. Eine schnelle Lösung besteht darin, den DISTINCT-Operator anzugeben, der die duplizierte Zeile unterdrückt.
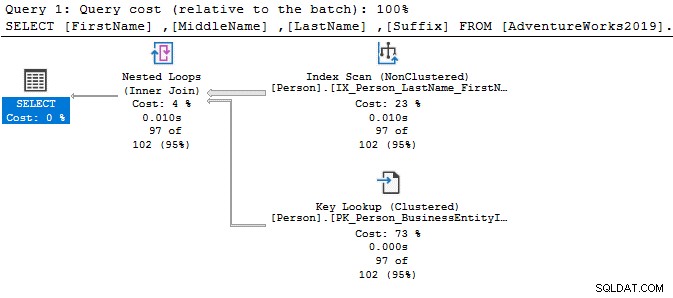
Schauen wir uns die einfachen SELECT-Anweisungen an und vergleichen die Ausführungspläne. Der einzige Unterschied zwischen beiden Abfragen ist ein DISTINCT-Operator.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
Mit dem DISTINCT-Operator betragen die Abfragekosten 77 %, während die frühere Abfrage (ohne DISTINCT) nur 23 % Batch-Kosten hat.
Sie können GROUP BY, CTE oder eine Unterabfrage verwenden, um effizienten SQL-Code zu schreiben, anstatt DISTINCT zu verwenden, um eindeutige Werte aus der Ergebnismenge zu erhalten. Darüber hinaus können Sie zusätzliche Spalten für eine bestimmte Ergebnismenge abrufen.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Verwendung von Platzhaltern in der SQL-Abfrage
Angenommen, Sie möchten nach bestimmten Datensätzen suchen, die Namen enthalten, die mit der angegebenen Zeichenfolge beginnen. Entwickler verwenden einen Platzhalter, um nach übereinstimmenden Datensätzen zu suchen.
In der folgenden Abfrage wird in der Vornamensspalte nach der Zeichenfolge Ken gesucht. Diese Abfrage ruft die erwarteten Ergebnisse von Ken ab dra und Ken Netto. Aber es liefert auch unerwartete Ergebnisse, zum Beispiel Macken zie und Nken ge.
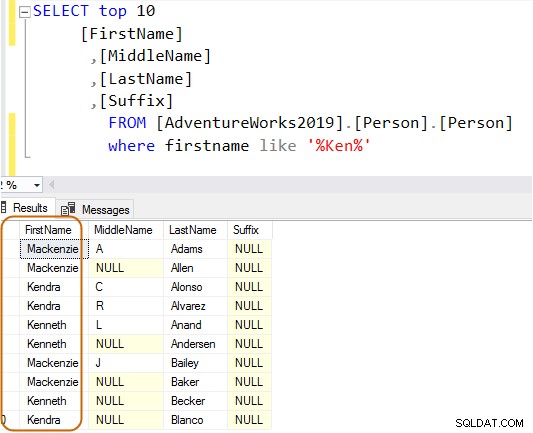
Im Ausführungsplan sehen Sie den Index-Scan und die Schlüsselsuche für die obige Abfrage.
Sie können das unerwartete Ergebnis vermeiden, indem Sie das Platzhalterzeichen am Ende der Zeichenfolge verwenden.
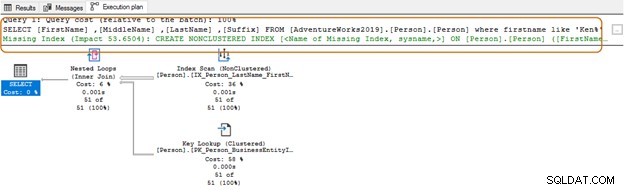
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Jetzt erhalten Sie das gefilterte Ergebnis basierend auf Ihren Anforderungen.
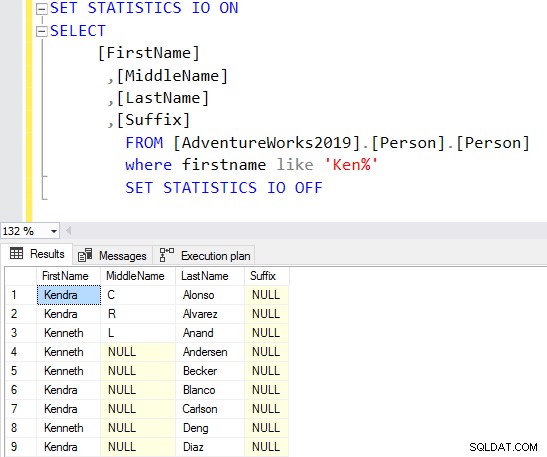
Bei Verwendung des Platzhalterzeichens am Anfang kann der Abfrageoptimierer möglicherweise nicht den passenden Index verwenden. Wie im folgenden Screenshot gezeigt, schlägt der Abfrageoptimierer mit einem nachgestellten Wildzeichen auch einen fehlenden Index vor.
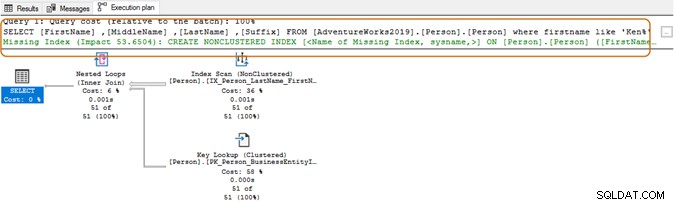
Hier sollten Sie Ihre Bewerbungsanforderungen bewerten. Sie sollten versuchen, die Verwendung von Platzhalterzeichen in den Suchzeichenfolgen zu vermeiden, da dies den Abfrageoptimierer dazu zwingen könnte, einen Tabellenscan zu verwenden. Wenn die Tabelle riesig ist, würde dies höhere Systemressourcen für E/A, CPU und Arbeitsspeicher erfordern und Leistungsprobleme für Ihre SQL-Abfrage verursachen.
Verwendung der WHERE- und HAVING-Klauseln
Die Klauseln WHERE und HAVING werden als Datenzeilenfilter verwendet. Die WHERE-Klausel filtert die Daten, bevor die Gruppierungslogik angewendet wird, während die HAVING-Klausel Zeilen nach den aggregierten Berechnungen filtert.
In der folgenden Abfrage verwenden wir beispielsweise einen Datenfilter in der HAVING-Klausel ohne eine WHERE-Klausel.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
Die folgende Abfrage filtert die Daten zuerst in der WHERE-Klausel und verwendet dann die HAVING-Klausel für den aggregierten Datenfilter.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Als Best Practice empfehle ich die Verwendung der WHERE-Klausel für die Datenfilterung und der HAVING-Klausel für Ihren aggregierten Datenfilter.
Verwendung der IN- und EXISTS-Klauseln
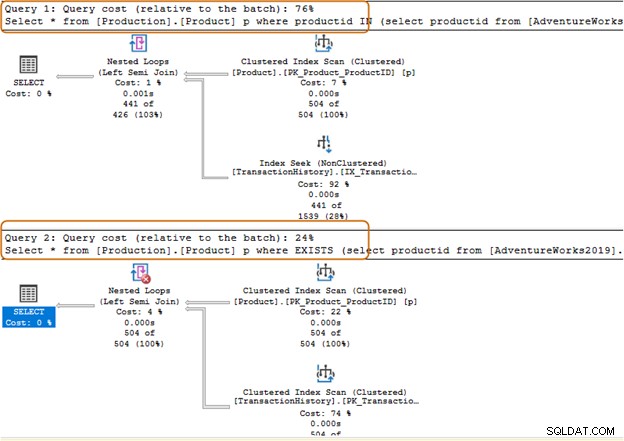
Sie sollten die IN-Operator-Klausel für Ihre SQL-Abfragen vermeiden. In der folgenden Abfrage haben wir beispielsweise zuerst die Produkt-ID aus der Tabelle [Production].[TransactionHistory]) gefunden und dann nach den entsprechenden Datensätzen in der Tabelle [Production].[Product] gesucht.
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
In der folgenden Abfrage haben wir die IN-Klausel durch eine EXISTS-Klausel ersetzt.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
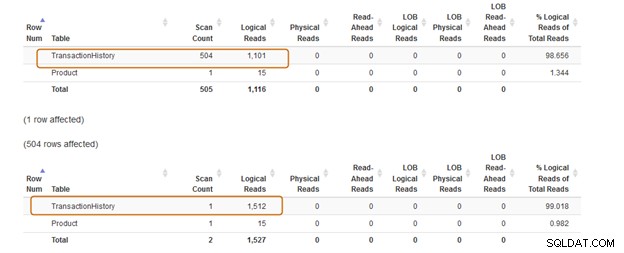
Vergleichen wir nun die Statistiken nach der Ausführung beider Abfragen.
Die IN-Klausel verwendet 504 Scans, während die EXISTS-Klausel 1 Scan für die [Production].[TransactionHistory])-Tabelle].
verwendet
Der Abfragebatch für die IN-Klausel kostet 74 %, während die Kosten für die EXISTS-Klausel 24 % betragen. Daher sollten Sie die IN-Klausel vermeiden, insbesondere wenn die Unterabfrage einen großen Datensatz zurückgibt.
Fehlende Indizes
Manchmal, wenn wir eine SQL-Abfrage ausführen und in SSMS nach dem tatsächlichen Ausführungsplan suchen, erhalten Sie einen Vorschlag zu einem Index, der Ihre SQL-Abfrage verbessern könnte.
Alternativ können Sie die dynamischen Verwaltungsansichten verwenden, um die Details fehlender Indizes in Ihrer Umgebung zu überprüfen.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Normalerweise folgen DBAs den Ratschlägen von SSMS und erstellen die Indizes. Es könnte die Abfrageleistung im Moment verbessern. Sie sollten den Index jedoch nicht direkt auf der Grundlage dieser Empfehlungen erstellen. Es kann andere Abfrageleistungen beeinträchtigen und Ihre INSERT- und UPDATE-Anweisungen verlangsamen.
- Überprüfen Sie zuerst die vorhandenen Indizes für Ihre SQL-Tabelle.
- Beachten Sie, dass Über- und Unterindizierung schlecht für die Abfrageleistung sind.
- Wenden Sie die fehlenden Indexempfehlungen mit der größten Wirkung an, nachdem Sie Ihre vorhandenen Indizes überprüft haben, und implementieren Sie sie in Ihrer unteren Umgebung. Wenn Ihre Workload nach der Implementierung des neuen fehlenden Index gut funktioniert, lohnt es sich, it. hinzuzufügen
Ich schlage vor, dass Sie sich auf diesen Artikel mit detaillierten Best Practices für die Indexierung beziehen:11 SQL Server Index Best Practices for Improved Performance Tuning.
Abfragehinweise
Entwickler geben die Abfragehinweise explizit in ihren t-SQL-Anweisungen an. Diese Abfragehinweise setzen das Verhalten des Abfrageoptimierers außer Kraft und zwingen ihn, einen Ausführungsplan basierend auf Ihrem Abfragehinweis zu erstellen. Häufig verwendete Abfragehinweise sind NOLOCK, Optimize For und Recompile Merge/Hash/Loop. Sie sind kurzfristige Lösungen für Ihre Fragen. Sie sollten jedoch daran arbeiten, Ihre Abfrage, Indizes, Statistiken und Ihren Ausführungsplan für eine dauerhafte Lösung zu analysieren.
Gemäß Best Practices sollten Sie die Verwendung von Abfragehinweisen minimieren. Sie sollten die Abfragehinweise in der SQL-Abfrage verwenden, nachdem Sie zunächst die Auswirkungen verstanden haben, und sie nicht unnötig verwenden.
Erinnerungen zur SQL-Abfrageoptimierung
Wie wir besprochen haben, ist die SQL-Abfrageoptimierung ein Weg mit offenem Ende. Sie können Best Practices und kleine Korrekturen anwenden, die die Leistung erheblich verbessern können. Beachten Sie die folgenden Tipps für eine bessere Abfrageentwicklung:
- Schauen Sie sich immer die Zuweisungen von Systemressourcen (Festplatten, CPU, Arbeitsspeicher) an
- Überprüfen Sie Ihre Start-Trace-Flags, Indizes und Datenbankwartungsaufgaben
- Analysieren Sie Ihre Arbeitslast mit erweiterten Ereignissen, Profilern oder Datenbanküberwachungstools von Drittanbietern
- Implementieren Sie immer zuerst eine Lösung (auch wenn Sie sich zu 100 % sicher sind) in der Testumgebung und analysieren Sie ihre Auswirkungen. Sobald Sie zufrieden sind, planen Sie Produktionsimplementierungen