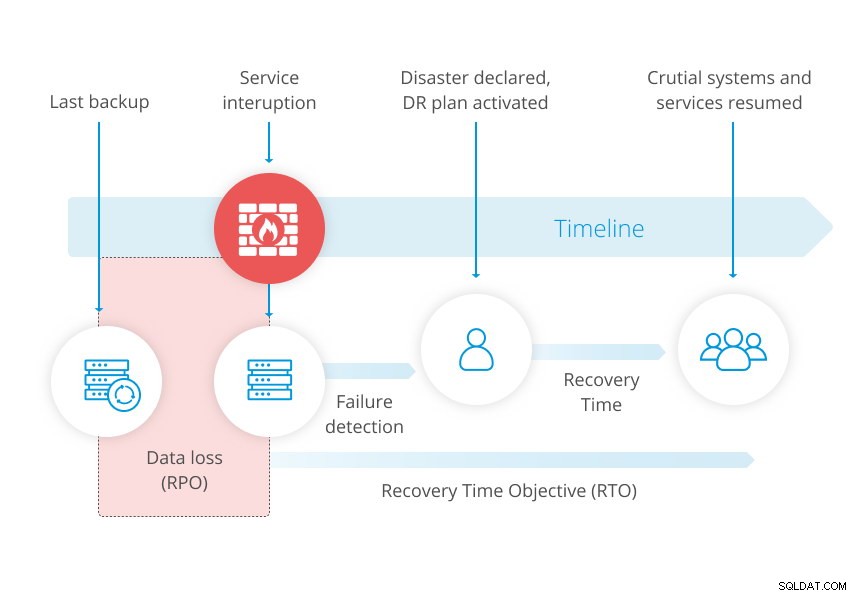
In einem Disaster-Recovery-Plan ist Ihr Recovery Point Objective (RPO) ein wichtiger Wiederherstellungsparameter, der bestimmt, wie viele Daten Sie sich leisten können, zu verlieren. RPO wird in der Zeit aufgelistet, von Sekunden bis zu Tagen. Tatsächlich ist RPO direkt von Ihrem Backup-System abhängig. Es kennzeichnet das Alter Ihrer Sicherungsdaten, die Sie wiederherstellen müssen, um den normalen Betrieb wieder aufzunehmen.
Wenn Sie eine nächtliche Sicherung um 22:00 Uhr durchführen und Ihr Datenbanksystem stürzt um 15:00 Uhr irreparabel ab. Am nächsten Tag verlieren Sie alles, was seit Ihrer letzten Sicherung geändert wurde. Ihr RPO in diesem speziellen Kontext ist die Sicherung des Vortages, was bedeutet, dass Sie es sich leisten können, die Änderungen eines Tages zu verlieren.
Das folgende Diagramm aus unserem Whitepaper zur Notfallwiederherstellung veranschaulicht das Konzept.
Für ein engeres RPO reicht ein Backup jedoch möglicherweise nicht aus. Wenn Sie Ihre Datenbank sichern, erstellen Sie tatsächlich eine Momentaufnahme der Daten zu einem bestimmten Zeitpunkt. Wenn Sie also eine Sicherung wiederherstellen, werden Sie die Änderungen verpassen, die zwischen der letzten Sicherung und dem Fehler aufgetreten sind.
Hier kommt das Konzept der Point-In-Time-Recovery (PITR) ins Spiel.
Was ist PITR?
Point-In-Time-Recovery (PITR) beinhaltet, wie der Name schon sagt, die Wiederherstellung der Datenbank zu einem beliebigen Zeitpunkt in der Vergangenheit. Um dies tun zu können, müssen wir ein Backup wiederherstellen und dann alle Änderungen, die nach dem Backup vorgenommen wurden, bis unmittelbar vor dem Ausfall anwenden.
Bei PostgreSQL werden die Änderungen in den WAL-Protokollen gespeichert (weitere Einzelheiten zu WALs und den darin gespeicherten Daten finden Sie in diesem Blog).
Es gibt also zwei Dinge, die wir sicherstellen müssen, um ein PITR durchführen zu können:Die Backups und die WALs (wir müssen eine kontinuierliche Archivierung für sie einrichten).
Zur Durchführung des PITR müssen wir die Sicherung wiederherstellen und dann die WALs anwenden.
Wann könnte es nützlich sein?
Sie können diese Strategie verwenden, wenn Sie nach einem Problem wiederherstellen, das zur Beschädigung der Daten geführt hat. Sie müssen bedenken, dass Sie versuchen, den Datenverlust zu minimieren, aber es gibt einige Probleme, die dazu führen können, dass die Daten danach nicht mehr nützlich sind.
Einige Beispiele hierfür können ungeplante Datenänderungen (DMLs oder DDLs), Medienfehler oder Datenbankwartungen (wie Upgrades) sein, die zu Datenbeschädigungen führen. Sie können die Datenänderungen, die nach dem Problem vorgenommen wurden, nicht wiederherstellen.
Nehmen wir an, ein Benutzer hat fälschlicherweise eine DML ausgeführt, wodurch die Daten einer ganzen Tabelle fälschlicherweise geändert oder gelöscht wurden. Sie können eine PITR der Datenbank an einem separaten Ort durchführen und dann den Inhalt der Tabelle exportieren. Sie können diese Tabelle dann in der vorhandenen Datenbank wiederherstellen und so effektiv auf eine Kopie des Zustands der Tabelle vor dem Auftreten des Problems zurückgreifen.
Natürlich ist es nicht immer möglich, nur einen Teil der Datenbank auf diese Weise wiederherzustellen, daher müssen Sie in diesem Fall die gesamte Datenbank bis zu einem bestimmten Punkt wiederherstellen und haben einen minimalen, aber unvermeidlichen Datenverlust (Sie werden es verpassen alle Änderungen, die nach Auftreten des Problems vorgenommen wurden).
Wie verwende ich es mit ClusterControl?
In einem früheren Blog konnten wir sehen, wie PITR manuell implementiert wird, nun sehen wir uns an, wie ClusterControl verwendet wird, um diese Aufgabe auszuführen.
Point-in-Time-Wiederherstellung aktivieren
Um die PITR-Funktion zu aktivieren, muss die WAL-Archivierung aktiviert sein. Dazu können wir zu ClusterControl gehen -> PostgreSQL-Cluster auswählen -> Knotenaktionen -> WAL-Archivierung aktivieren oder einfach zu ClusterControl gehen -> PostgreSQL-Cluster auswählen -> Backup -> Einstellungen und die Option „Point-In-Time-Wiederherstellung aktivieren“ aktivieren (WAL-Archivierung)“, wie wir im folgenden Bild sehen werden.
Wir müssen bedenken, dass wir unsere Datenbank neu starten müssen, um die WAL-Archivierung zu aktivieren. Auch das kann ClusterControl für uns erledigen.
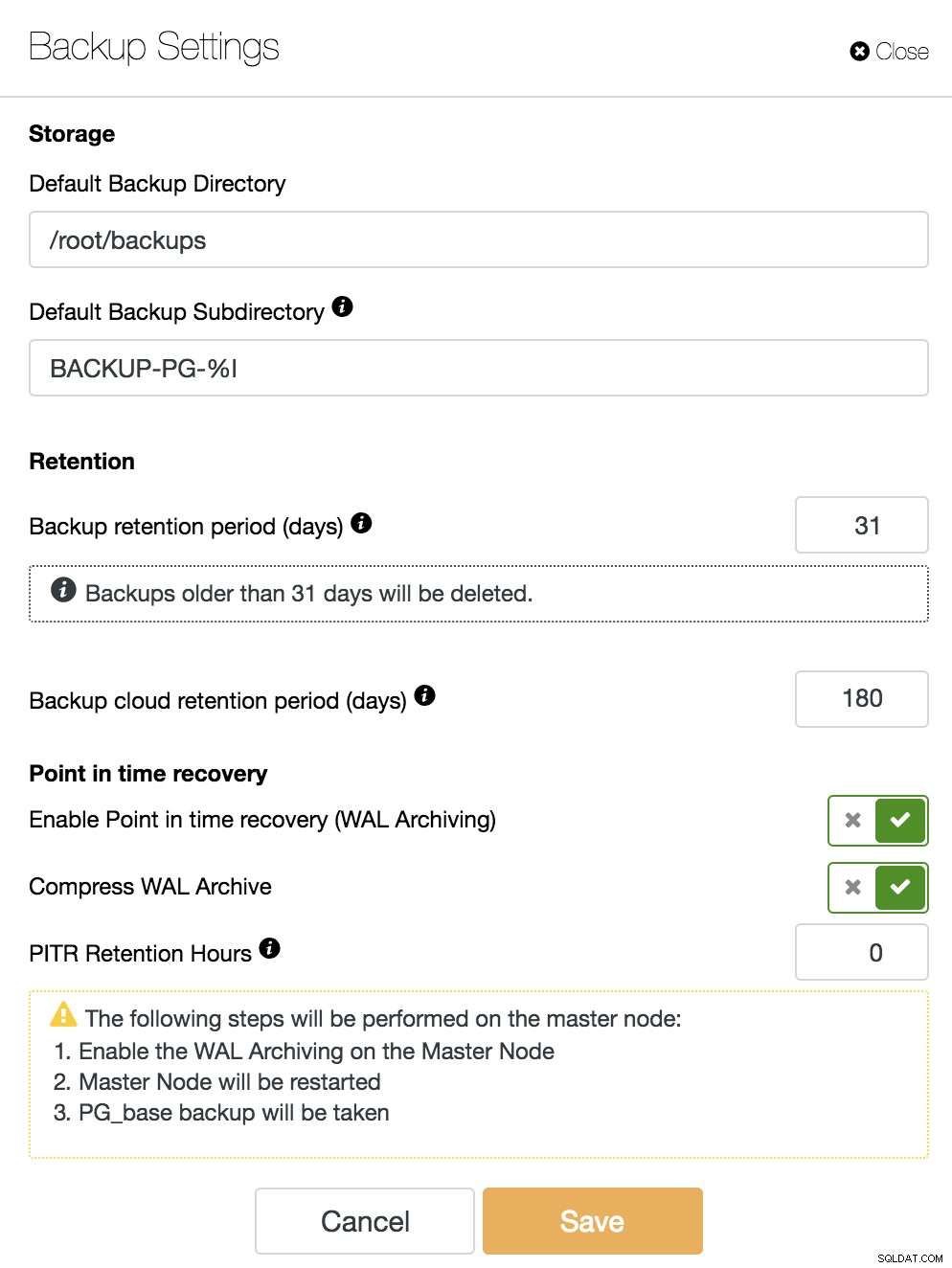
Neben den allen Backups gemeinsamen Optionen wie „Backup Directory“ und „Backup Retention Period“ können wir hier auch die WAL Retention Period festlegen. Standardmäßig ist 0, was für immer bedeutet.
Um zu bestätigen, dass wir die WAL-Archivierung aktiviert haben, können wir unseren Master-Knoten in ClusterControl auswählen -> PostgreSQL-Cluster auswählen -> Knoten, und wir sollten die Meldung WAL-Archivierung aktiviert sehen, wie wir im folgenden Bild sehen können.
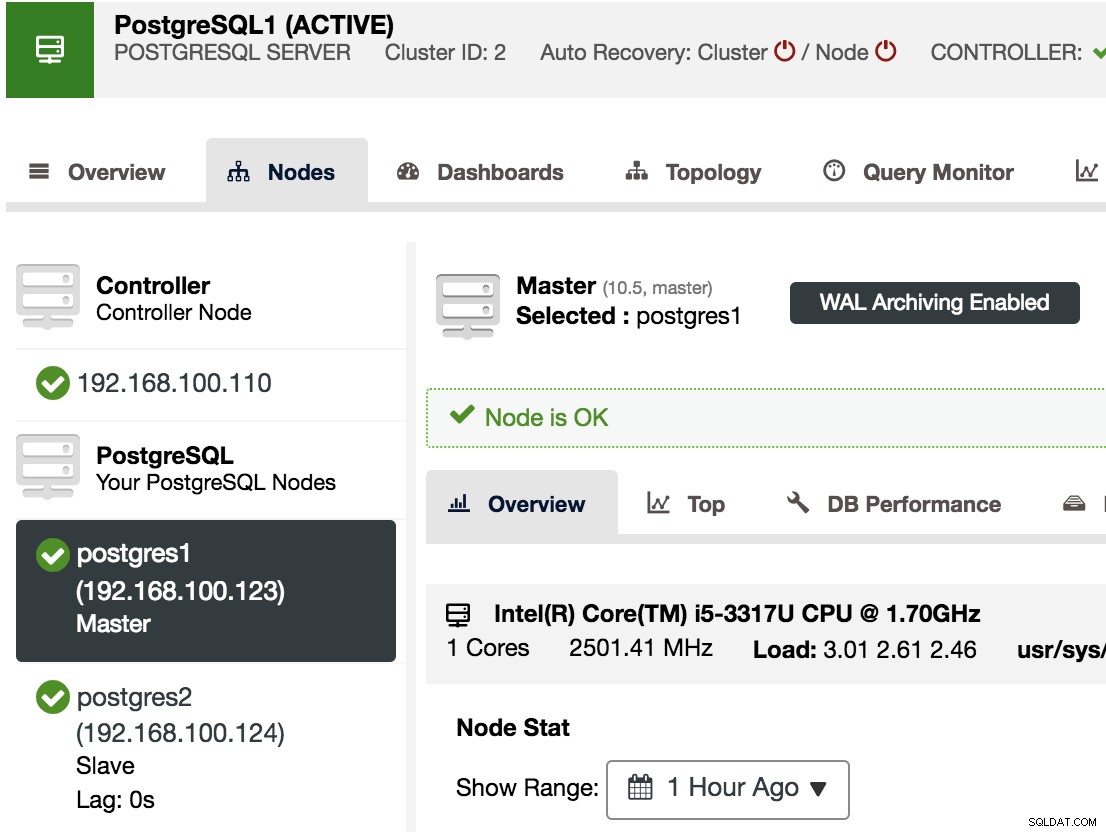
Erstellen einer mit Point-in-Time-Recovery kompatiblen Sicherung
Wenn die WAL-Archivierung aktiviert ist, wie wir im vorherigen Schritt gesehen haben, können wir unser Backup erstellen, das mit PITR kompatibel ist. Gehen Sie dazu zu ClusterControl -> PostgreSQL-Cluster auswählen -> Backup -> Backup erstellen.
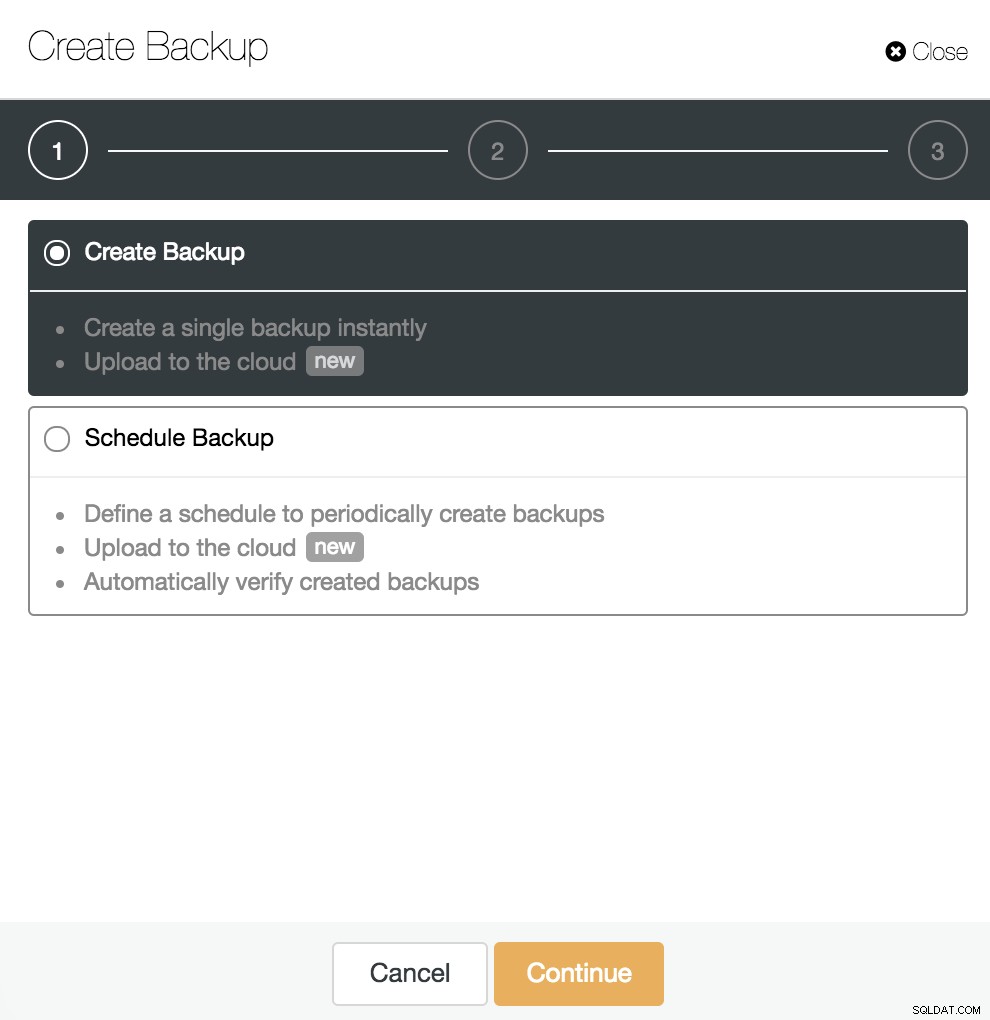
Wir können ein neues Backup erstellen oder ein geplantes konfigurieren. Für unser Beispiel erstellen wir sofort ein einzelnes Backup.
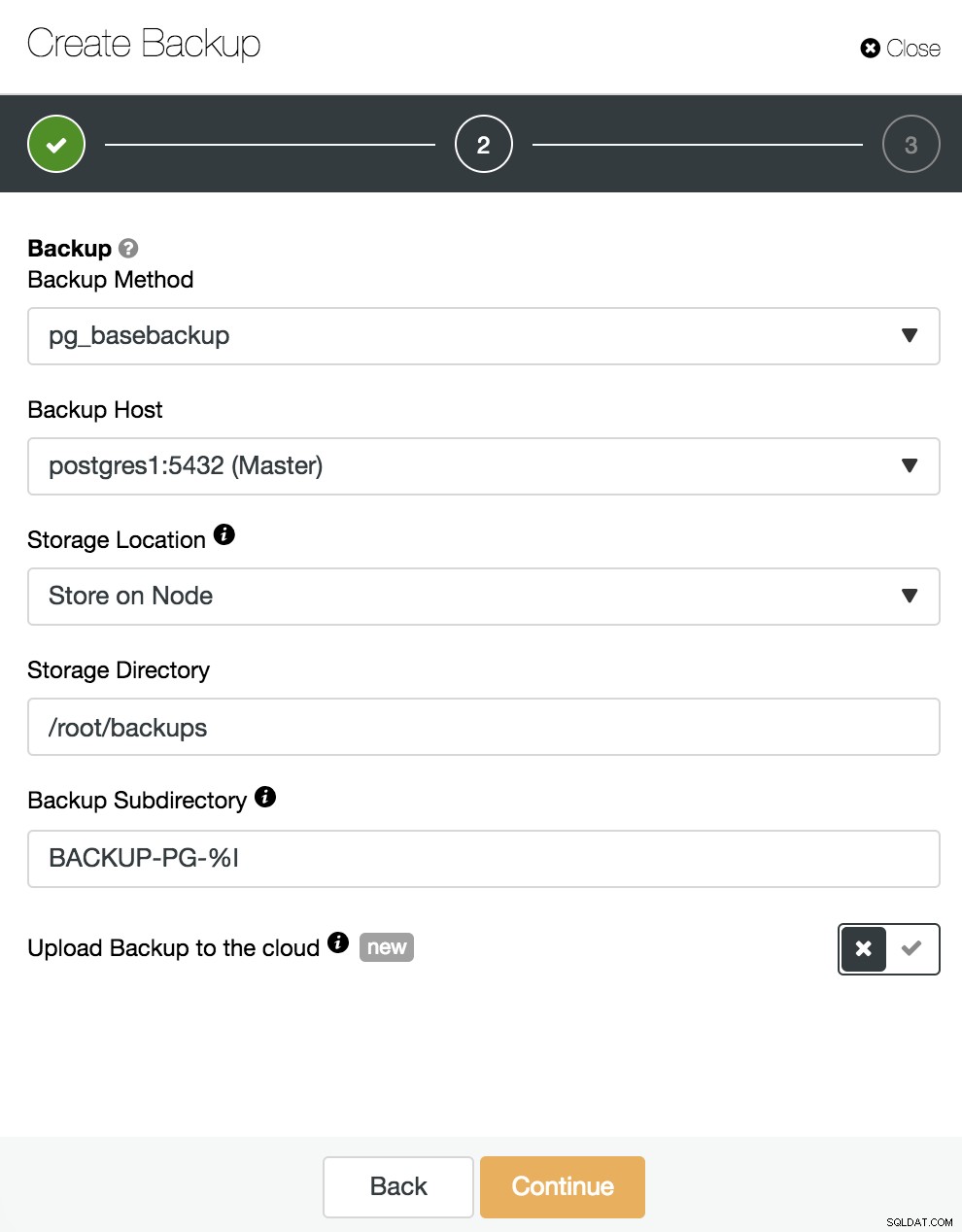
Hier müssen wir die Methode „pg_basebackup“ auswählen, die mit PITR kompatibel ist, den Server, von dem das Backup genommen wird (um mit PITR kompatibel zu sein, muss es der Master sein) und wo wir das Backup speichern möchten. Wir können unser Backup auch in die Cloud (AWS, Google oder Azure) hochladen, indem wir die entsprechende Schaltfläche aktivieren.
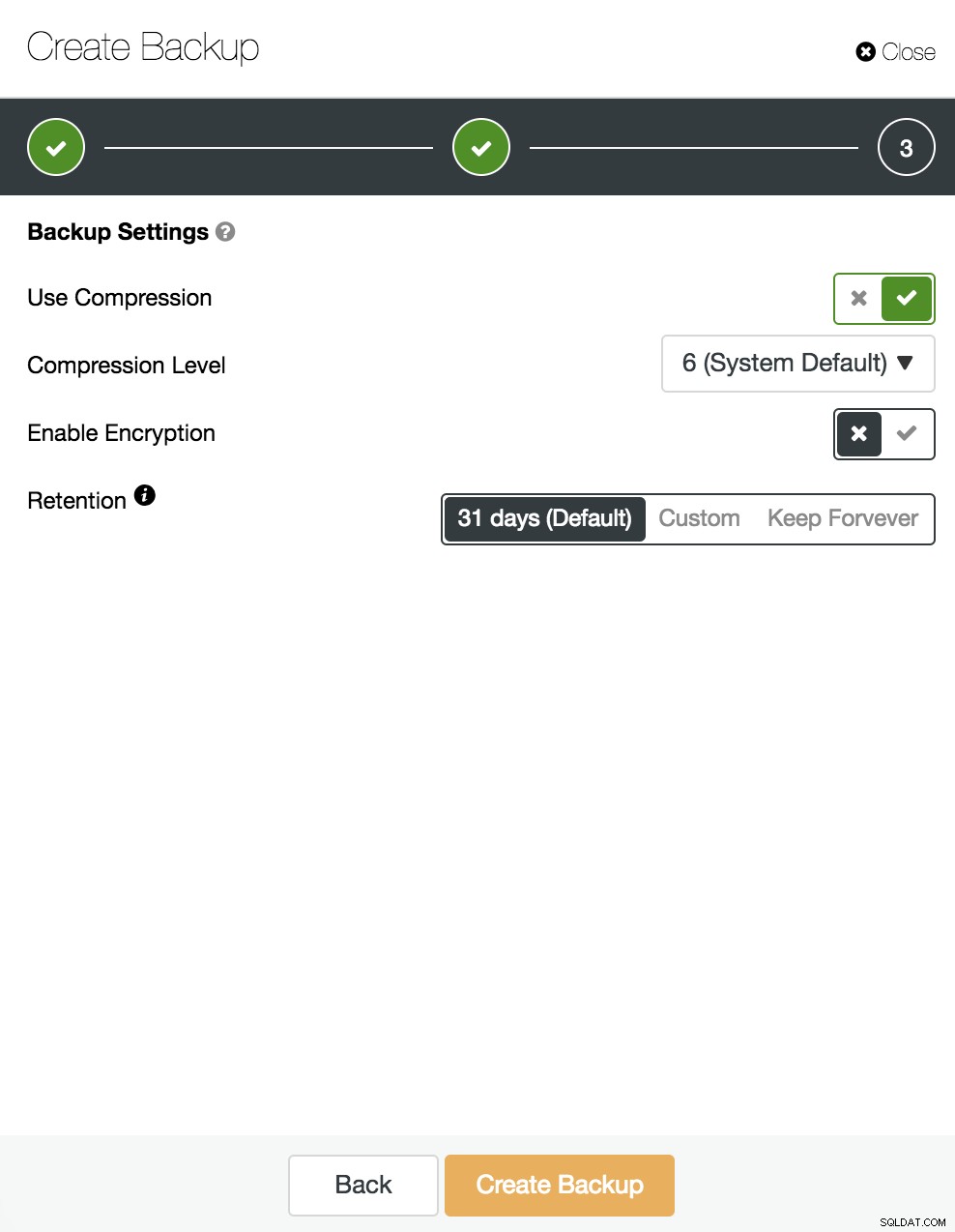
Dann legen wir die Verwendung von Komprimierung, Verschlüsselung und Aufbewahrung unseres Backups fest.
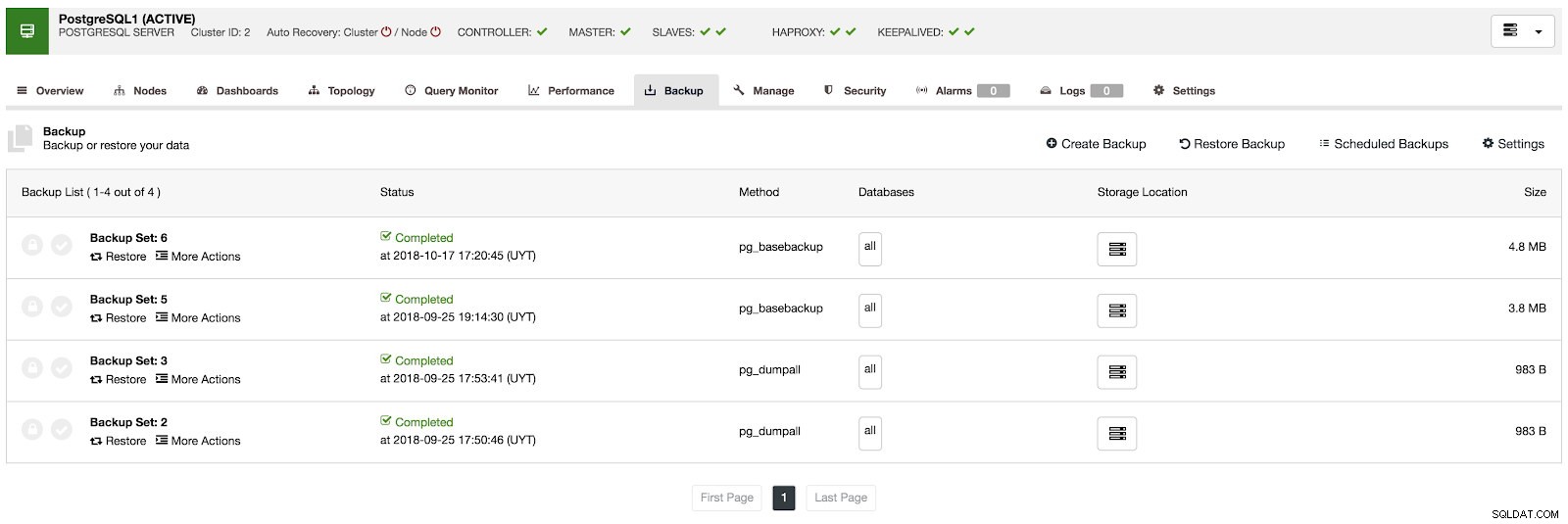
Im Backup-Bereich können wir den Fortschritt des Backups und Informationen wie Methode, Größe, Speicherort und mehr sehen.
Point-in-Time-Recovery von einem Backup
Sobald die Sicherung abgeschlossen ist, können wir sie mit der ClusterControl PITR-Funktion wiederherstellen. Dazu können wir in unserem Backup-Bereich (ClusterControl -> PostgreSQL-Cluster auswählen -> Backup) „Backup wiederherstellen“ oder direkt „Wiederherstellen“ für das Backup auswählen, das wir wiederherstellen möchten.
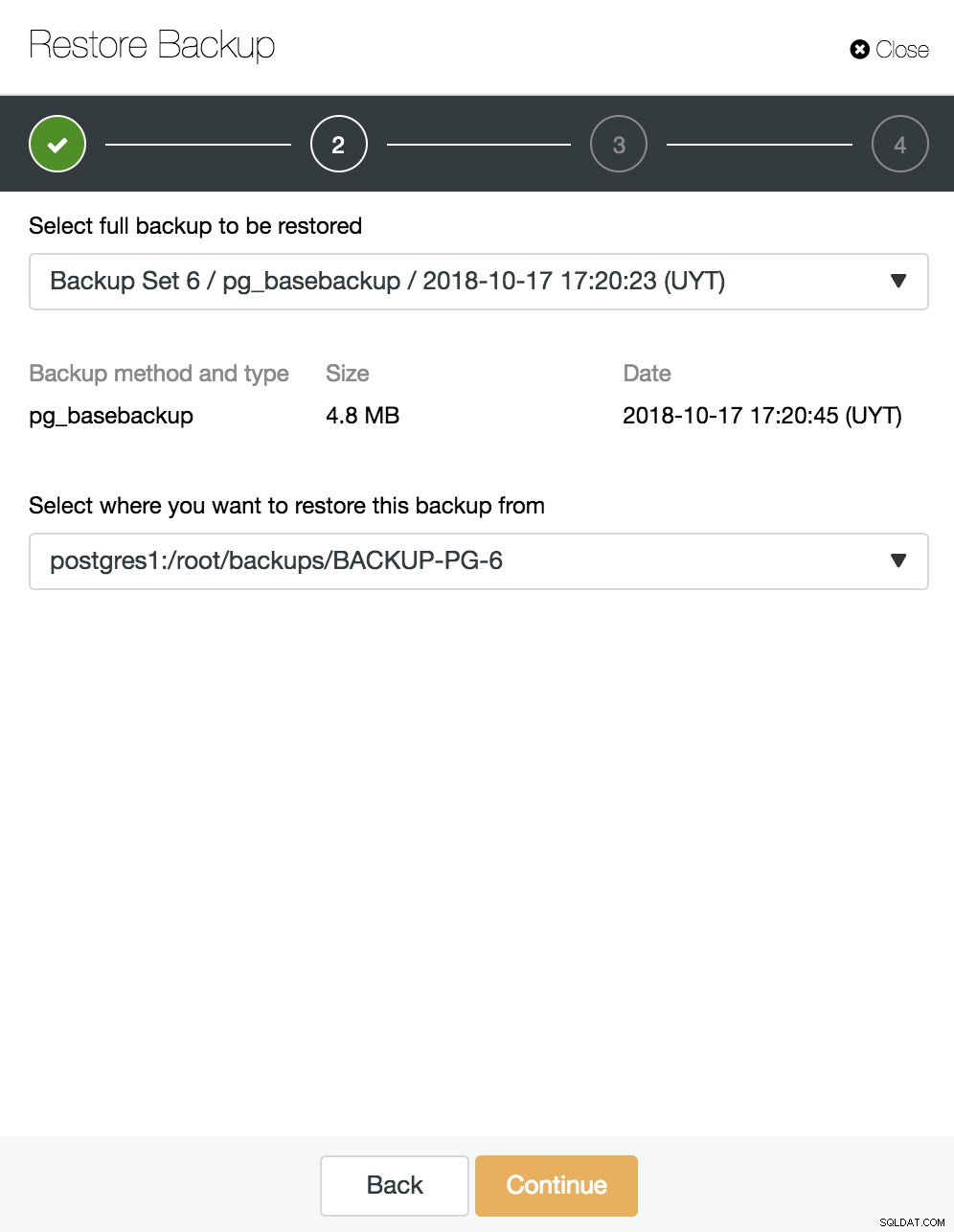
Hier wählen wir aus, welches Backup wir wiederherstellen möchten und aus welchem Verzeichnis.
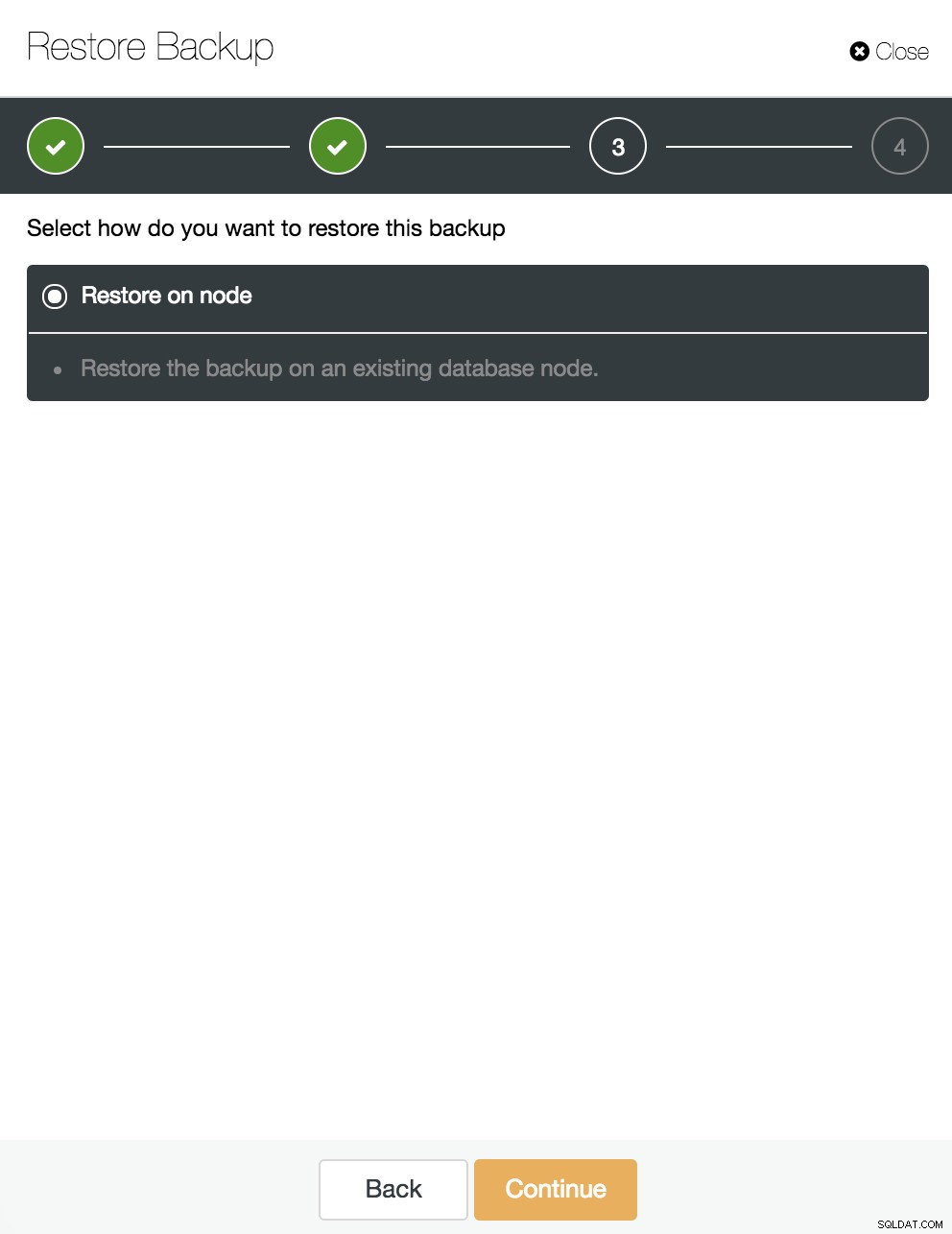
Wir lassen die Option „Auf Knoten wiederherstellen“ ausgewählt und fahren fort.
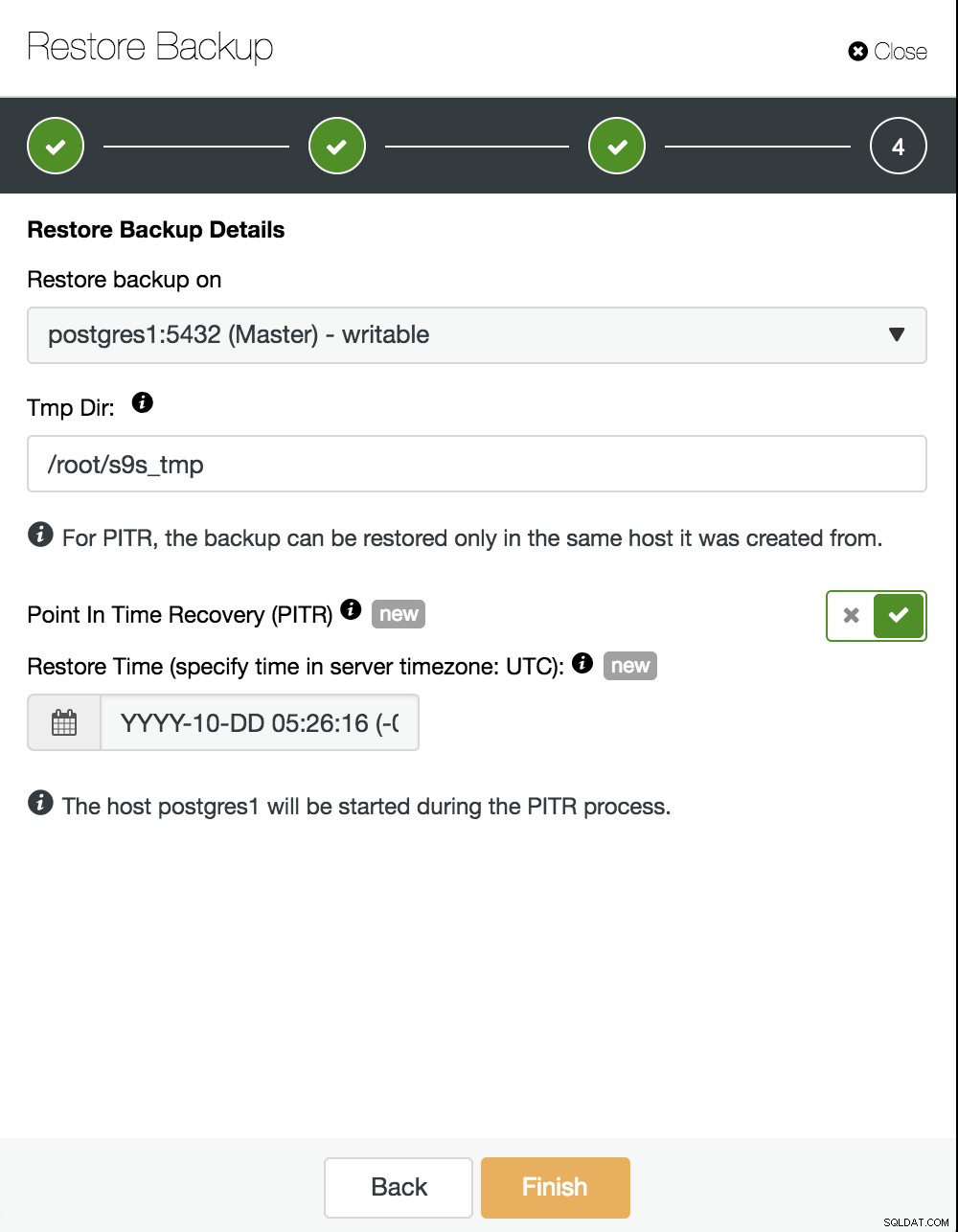
Jetzt müssen wir auswählen, wo wir unser Backup wiederherstellen und die PITR-Option aktivieren. Durch die Angabe der Uhrzeit wird die Zeit angegeben, bis zu der wir uns erholen werden. Berücksichtigen Sie, dass die UTC-Zeitzone verwendet wird und dass unser PostgreSQL-Dienst im Master neu gestartet wird.
Wir können den Fortschritt unserer Wiederherstellung im Aktivitätsbereich in unserem ClusterControl überwachen.
Schlussfolgerung
PITR ist eine notwendige Funktion, um ein enges RPO zu erfüllen. Wir müssen es richtig einrichten, um einen korrekten Notfallwiederherstellungsplan sicherzustellen. ClusterControl bietet eine benutzerfreundliche Oberfläche, die Ihnen hilft, PITR für Ihre PostgreSQL-Datenbanken zu implementieren.