In relationalen Datenbanken erstellen wir Tabellen, um Daten in verschiedenen Formaten zu speichern. SQL Server speichert Daten in einem Zeilen- und Spaltenformat, das einen Wert enthält, der jedem Datentyp zugeordnet ist. Wenn wir SQL-Tabellen entwerfen, definieren wir Datentypen wie Integer, Float, Dezimal, Varchar und Bit. Beispielsweise kann eine Tabelle, die Kundendaten speichert, Felder wie Kundenname, E-Mail, Adresse, Bundesland, Land usw. enthalten. Verschiedene SQL-Befehle werden auf eine SQL-Tabelle ausgeführt und können in die folgenden Kategorien unterteilt werden:
- Datendefinitionssprache (DDL): Diese Befehle werden verwendet, um die Datenbankobjekte in einer Datenbank zu erstellen und zu ändern.
- Erstellen: Erstellt Objekte
- Ändern: Ändert Objekte
- Ablegen: Löscht Objekte
- Abschneiden: Löscht alle Daten aus einer Tabelle
- Datenmanipulationssprache (DML): Diese Befehle fügen Daten in die Datenbank ein, rufen sie ab, ändern, löschen und aktualisieren sie.
- Auswählen: Ruft Daten aus einer einzelnen oder mehreren Tabellen ab
- Einfügen: Fügt neue Daten in einer Tabelle hinzu
- Aktualisierung: Ändert vorhandene Daten
- Löschen: Löscht bestehende Datensätze in einer Tabelle
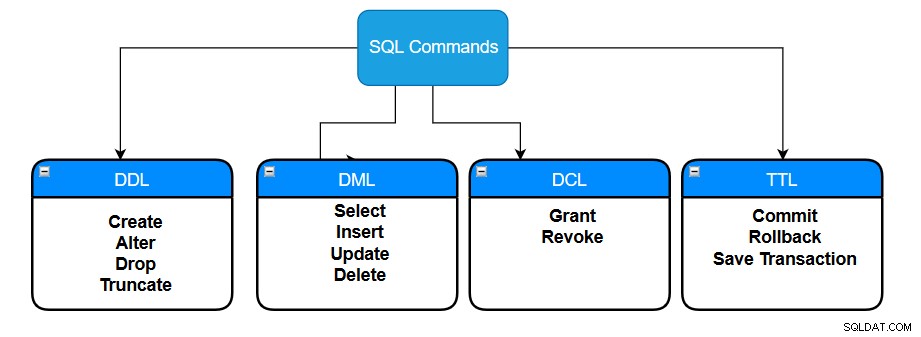
- Data Control Language (DCL): Diese Befehle sind mit Rechten oder Berechtigungskontrollen in einer Datenbank verknüpft.
- Erteilung: Weist einem Benutzer Berechtigungen zu
- Widerrufen: Entzieht einem Benutzer Berechtigungen
- Transaktionskontrollsprache (TCL): Diese Befehle steuern Transaktionen in einer Datenbank.
- Verpflichten: Speichert die durch die Abfrage vorgenommenen Änderungen
- Zurücksetzen: Setzt eine explizite oder implizite Transaktion zum Anfang der Transaktion oder zu einem Sicherungspunkt innerhalb der Transaktion zurück
- Transaktionen speichern: Setzt einen Sicherungspunkt oder Marker innerhalb einer Transaktion
Angenommen, Sie haben Kundenauftragsdaten in einer SQL-Tabelle gespeichert. Wenn Sie kontinuierlich Daten in diese Tabelle einfügen, könnte die Tabelle Millionen von Datensätzen enthalten, was zu Leistungsproblemen in Ihren Anwendungen führen würde. Ihre Indexpflege kann auch extrem zeitaufwändig werden. Oft müssen Sie Bestellungen, die älter als drei Jahre sind, nicht aufbewahren. In diesen Fällen könnten Sie diese Datensätze aus der Tabelle löschen. Dies würde Speicherplatz sparen und Ihren Wartungsaufwand reduzieren.
Sie können Daten auf zwei Arten aus einer SQL-Tabelle entfernen:
- Eine SQL-Löschanweisung verwenden
- Verwendung einer Kürzung
Wir werden uns später den Unterschied zwischen diesen SQL-Befehlen ansehen. Sehen wir uns zuerst die SQL-Löschanweisung an.
Eine SQL-Löschanweisung ohne Bedingungen
In DML-Anweisungen (Data Manipulation Language) entfernt eine SQL-Löschanweisung die Zeilen aus einer Tabelle. Sie können eine bestimmte Zeile oder alle Zeilen löschen. Eine einfache Löschanweisung erfordert keine Argumente.
Lassen Sie uns mit dem folgenden Skript eine Orders-SQL-Tabelle erstellen. Diese Tabelle hat drei Spalten [OrderID], [ProductName] und [ProductQuantity].
Create Table Orders( OrderID int,ProductName varchar(50),ProductQuantity int)
Fügen Sie einige Datensätze in diese Tabelle ein.
Insert into Orders values (1,'ABC books',10),(2,'XYZ',100),(3,'SQL book',50)
Angenommen, wir möchten die Tabellendaten löschen. Sie können den Tabellennamen angeben, um Daten mit der Löschanweisung zu entfernen. Beide SQL-Anweisungen sind gleich. Wir können den Tabellennamen aus dem (optionalen) Schlüsselwort angeben oder den Tabellennamen direkt nach dem Löschen angeben.
Delete OrdersGoDelete from OrdersGO
Eine SQL-Löschanweisung mit gefilterten Daten
Diese SQL-Löschanweisungen löschen alle Daten der Tabelle. Normalerweise entfernen wir nicht alle Zeilen aus einer SQL-Tabelle. Um eine bestimmte Zeile zu entfernen, können wir eine where-Klausel mit der delete-Anweisung hinzufügen. Die where-Klausel enthält die Filterkriterien und bestimmt schließlich, welche Zeile(n) entfernt werden sollen.
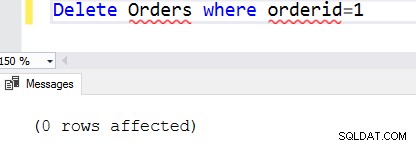
Angenommen, wir möchten die Bestell-ID 1 entfernen. Sobald wir eine where-Klausel hinzufügen, überprüft SQL Server zuerst die entsprechenden Zeilen und entfernt diese spezifischen Zeilen.Delete Orders where orderid=1
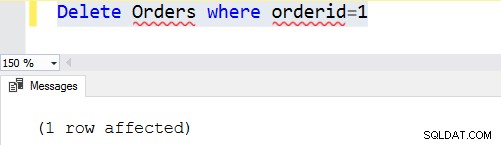
Wenn die Bedingung der Where-Klausel falsch ist, werden keine Zeilen entfernt. Zum Beispiel haben wir die bestellte 1 aus der Auftragstabelle entfernt. Wenn wir die Anweisung erneut ausführen, findet sie keine Zeilen, die die Bedingung der where-Klausel erfüllen. In diesem Fall gibt es 0 betroffene Zeilen zurück.
SQL-Löschanweisung und TOP-Klausel
Sie können die TOP-Anweisung auch verwenden, um die Zeilen zu löschen. Die folgende Abfrage löscht beispielsweise die obersten 100 Zeilen aus der Tabelle "Bestellungen".
Delete top (100) [OrderID]from Orders
Da wir kein „ORDER BY“ angegeben haben, werden zufällige Zeilen ausgewählt und gelöscht. Wir können die Order by-Klausel verwenden, um die Daten zu sortieren und die obersten Zeilen zu löschen. In der folgenden Abfrage wird die [OrderID] in absteigender Reihenfolge sortiert und dann aus der Tabelle [Orders] gelöscht.
Delete from Orders where [OrderID] In(Select top 100 [OrderID] FROM Ordersorder by [OrderID] Desc)
Löschen von Zeilen basierend auf einer anderen Tabelle
Manchmal müssen wir Zeilen basierend auf einer anderen Tabelle löschen. Diese Tabelle kann in derselben Datenbank vorhanden sein oder nicht.
- Tabellensuche
Wir können die Tabellensuchmethode oder den SQL-Join verwenden, um diese Zeilen zu löschen. Beispielsweise möchten wir Zeilen aus der Tabelle [Bestellungen] löschen, die die folgende Bedingung erfüllen:
Es sollte entsprechende Zeilen in der Tabelle [dbo].[Customer] haben.
Schauen Sie sich die folgende Abfrage an, hier haben wir eine select-Anweisung in der where-Klausel der delete-Anweisung. SQL Server ruft zuerst die Zeilen ab, die die select-Anweisung erfüllen, und entfernt diese Zeilen dann mit der SQL-Löschanweisung aus der Tabelle [Orders].
Delete Orders where orderid in(Select orderidfrom Customer)
- SQL-Join
Alternativ können wir SQL-Joins zwischen diesen Tabellen verwenden und die Zeilen entfernen. In der folgenden Abfrage verbinden wir die Tabellen [Orders]] mit der Tabelle [Customer]. Ein SQL-Join funktioniert immer auf einer gemeinsamen Spalte zwischen den Tabellen. Wir haben eine Spalte [OrderID], die beide Tabellen zusammenführt.
DELETE OrdersFROM Orders oINNER JOIN Customer c ON o.orderid=c.orderid
Um die obige Löschanweisung zu verstehen, sehen wir uns den tatsächlichen Ausführungsplan an.
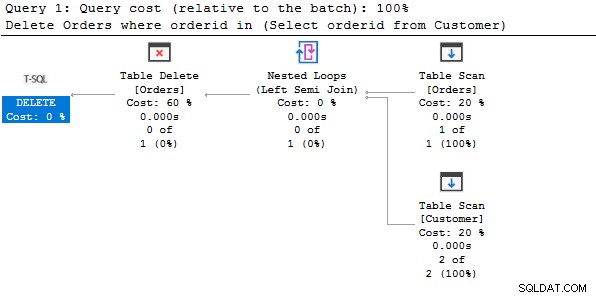
Gemäß dem Ausführungsplan führt es einen Tabellenscan für beide Tabellen durch, ruft die übereinstimmenden Daten ab und löscht sie aus der Orders-Tabelle.
- Gemeinsamer Tabellenausdruck (CTE)
Wir können auch einen gemeinsamen Tabellenausdruck (CTE) verwenden, um die Zeilen aus einer SQL-Tabelle zu löschen. Zuerst definieren wir einen CTE, um die Zeile zu finden, die wir entfernen möchten.
Dann verknüpfen wir den CTE mit der SQL-Tabelle Orders und löschen die Zeilen.
WITH cteOrders AS(SELECT OrderIDFROM CustomerWHERE CustomerID = 1 )DELETE OrdersFROM cteOrders spINNER JOIN dbo.Orders o ON o.orderid = sp.orderid;
Auswirkungen auf den Identitätsbereich
Identitätsspalten in SQL Server generieren eindeutige, sequenzielle Werte für Ihre Spalte. Sie werden hauptsächlich verwendet, um eine Zeile in der SQL-Tabelle eindeutig zu identifizieren. Eine Primärschlüsselspalte ist auch eine gute Wahl für einen gruppierten Index in SQL Server.
Im folgenden Skript haben wir eine [Employee]-Tabelle. Diese Tabelle hat eine Identitätsspalten-ID.
Create Table Employee(id int identity(1,1),[Name] varchar(50))
Wir haben 50 Datensätze in diese Tabelle eingefügt, die die Identitätswerte für die ID-Spalte generiert haben.
Declare @id int=1While(@id<=50)BEGINInsert into Employee([Name]) values('Test'+CONVERT(VARCHAR,@ID))Set @id=@id+1END
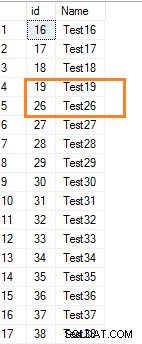
Wenn wir einige Zeilen aus der SQL-Tabelle löschen, werden die Identitätswerte für die nachfolgenden Werte nicht zurückgesetzt. Löschen wir beispielsweise einige Zeilen mit den Identitätswerten 20 bis 25.
Delete from employeewhere id between 20 and 25
Sehen Sie sich jetzt die Tabellendatensätze an.
Select * from employee where id>15Es zeigt die Lücke im Bereich der Identitätswerte.
SQL-Löschanweisung und das Transaktionsprotokoll
SQL delete protokolliert jede Zeilenlöschung im Transaktionsprotokoll. Angenommen, Sie müssen Millionen von Datensätzen aus einer SQL-Tabelle löschen. Sie möchten nicht eine große Anzahl von Datensätzen in einer einzigen Transaktion löschen, da dies dazu führen kann, dass Ihre Protokolldatei exponentiell anwächst und Ihre Datenbank möglicherweise auch nicht verfügbar ist. Wenn Sie eine Transaktion mittendrin abbrechen, kann es Stunden dauern, eine Löschanweisung rückgängig zu machen.
In diesem Fall sollten Sie Zeilen immer in kleinen Blöcken löschen und diese Blöcke regelmäßig festschreiben. Sie können beispielsweise einen Stapel von 10.000 Zeilen gleichzeitig löschen, festschreiben und mit dem nächsten Stapel fortfahren. Wenn SQL Server den Chunk festschreibt, kann das Wachstum des Transaktionsprotokolls kontrolliert werden.
Best Practices
- Sie sollten immer eine Sicherung durchführen, bevor Sie Daten löschen.
- Standardmäßig verwendet SQL Server implizite Transaktionen und schreibt die Datensätze fest, ohne den Benutzer zu fragen. Als Best Practice sollten Sie eine explizite Transaktion mit Begin Transaction starten. Es gibt Ihnen die Kontrolle, die Transaktion festzuschreiben oder rückgängig zu machen. Sie sollten auch häufig Sicherungen des Transaktionsprotokolls durchführen, wenn sich Ihre Datenbank im vollständigen Wiederherstellungsmodus befindet.
- Sie möchten Daten in kleinen Blöcken löschen, um eine übermäßige Nutzung des Transaktionsprotokolls zu vermeiden. Es vermeidet auch Blockierungen für andere SQL-Transaktionen.
- Sie sollten die Berechtigungen einschränken, damit Benutzer keine Daten löschen können. Nur autorisierte Benutzer sollten Zugriff haben, um Daten aus einer SQL-Tabelle zu entfernen.
- Sie möchten die Löschanweisung mit einer Where-Klausel ausführen. Es entfernt gefilterte Daten aus einer SQL-Tabelle. Wenn Ihre Anwendung häufiges Löschen von Daten erfordert, empfiehlt es sich, die Identitätswerte regelmäßig zurückzusetzen. Andernfalls könnten Probleme mit der Erschöpfung des Identitätswertes auftreten.
- Falls Sie die Tabelle leeren möchten, ist es ratsam, die truncate-Anweisung zu verwenden. Die truncate-Anweisung entfernt alle Daten aus einer Tabelle, verwendet minimale Transaktionsprotokollierung, setzt den Identitätswertbereich zurück und ist schneller als die SQL-Löschanweisung, da sie alle Seiten für die Tabelle sofort freigibt.
- Falls Sie Fremdschlüsseleinschränkungen (Eltern-Kind-Beziehung) für Ihre Tabellen verwenden, sollten Sie die Zeile aus einer untergeordneten Zeile und dann aus der übergeordneten Tabelle löschen. Wenn Sie die Zeile aus der übergeordneten Zeile löschen, können Sie auch die Option Cascade on Delete verwenden, um die Zeile automatisch aus einer untergeordneten Tabelle zu löschen. Weitere Informationen finden Sie im Artikel Kaskade löschen und Kaskade in SQL Server-Fremdschlüssel aktualisieren.
- Wenn Sie die oberste Anweisung zum Löschen der Zeilen verwenden, löscht SQL Server die Zeilen nach dem Zufallsprinzip. Sie sollten immer die oberste Klausel mit der entsprechenden Order by- und Group by-Klausel verwenden.
- Eine delete-Anweisung erwirbt eine exklusive Absichtssperre für die Referenztabelle; daher können während dieser Zeit keine anderen Transaktionen die Daten ändern. Sie können den NOLOCK-Hinweis verwenden, um die Daten zu lesen.
- Sie sollten es vermeiden, den Tabellenhinweis zu verwenden, um das standardmäßige Sperrverhalten der SQL-Löschanweisung zu überschreiben; Es sollte nur von erfahrenen DBAs und Entwicklern verwendet werden.
Wichtige Überlegungen
Die Verwendung von SQL-Löschanweisungen zum Entfernen von Daten aus einer SQL-Tabelle hat viele Vorteile, aber wie Sie sehen können, erfordert dies einen methodischen Ansatz. Es ist wichtig, Daten immer in kleinen Stapeln zu löschen und beim Löschen von Daten aus einer Produktionsinstanz mit Vorsicht vorzugehen. Eine Sicherungsstrategie zur Wiederherstellung von Daten in kürzester Zeit ist ein Muss, um Ausfallzeiten oder zukünftige Leistungseinbußen zu vermeiden.