In einem früheren Artikel haben wir die Indexanforderungen und Leistungsüberlegungen von SQL Server untersucht. Wenn es um die Datenbank-Performance geht, ist Performance-Tuning ohne Frage eine der wichtigsten und komplexesten Funktionen. Es besteht aus vielen verschiedenen Bereichen wie SQL-Abfrageoptimierung, Indexoptimierung und Systemressourcenoptimierung, die alle korrekt ausgeführt werden müssen, um Daten schnell und erfolgreich abzurufen.
Bei SQL Server-Indizes sind mehrere wichtige Bereiche zu berücksichtigen, da sie einen erheblichen Einfluss sowohl auf Ihre Bemühungen zur Leistungsoptimierung als auch auf die Gesamtleistung der Datenbank haben können. Unten finden Sie einige Details zu jedem und den entscheidenden Rollen, die sie spielen.
Best Practices für SQL Server-Indizes
1. Verstehen, wie sich das Datenbankdesign auf SQL Server-Indizes auswirkt
Die Indizierungsanforderungen variieren zwischen Online Transaction Processing (OLTP)- und Online Analytical Processing (OLAP)-Datenbanken.
In einer OLTP-Datenbank führen Benutzer häufig Lese-/Schreibvorgänge durch, fügen neue Daten ein und ändern vorhandene Daten. Sie verwenden Sprachabfragen zur Datenmanipulation (Insert, Update, Delete) zusammen mit Select-Anweisungen zum Abrufen und Ändern von Daten. Für OLTP-Datenbanken ist es am besten, Indizes für die Spalte „Ausgewählt“ einer Tabelle zu erstellen. Mehrere Indizes können sich negativ auf die Leistung auswirken und die Systemressourcen belasten. Stattdessen wird empfohlen, die Mindestanzahl von Indizes zu erstellen, die Ihre Indizierungsanforderungen erfüllen können. In OLAP-Datenbanken hingegen verwenden Sie meist Select-Anweisungen, um Daten für weitere Analysezwecke abzurufen. In diesem Fall können Sie weitere Indizes mit mehreren Schlüsselspalten pro Index hinzufügen. Sie können Columnstore-Indizes auch für einen schnelleren Datenabruf in Data-Warehouse-Abfragen nutzen
2. Erstellen Sie Indizes für Ihre Workload-Anforderungen
Wenn Sie eine neue Tabelle in Ihrer Datenbank erstellen, fügen Sie Indizes nicht einfach blind hinzu. Manchmal fügen Entwickler einen geclusterten Index und einige nicht geclusterte Indexe hinzu, ohne nach den Abfragen zu suchen, die diese Indexe verwenden. Möglicherweise gibt es einen Index, der die Anforderungen des Abfrageoptimierers nicht erfüllt; Daher sollten Sie Ihre Workload und SQL-Abfragen (gespeicherte Prozeduren, Funktionen, Ansichten und Ad-hoc-Abfragen) richtig analysieren. Sie können die Arbeitslast mithilfe von SQL-Profiler, erweiterten Ereignissen und dynamischen Verwaltungsansichten erfassen und dann Indizes erstellen, um ressourcenintensive Abfragen zu optimieren.
3. Erstellen Sie Indizes für die am stärksten und am häufigsten verwendeten Suchanfragen
Es ist wichtig, Workloads für die am häufigsten verwendeten Abfragen in Ihrem System zu gruppieren. Durch die Erstellung der besten Indizes für diese Abfragen wird Ihr System am wenigsten belastet.
4. Best Practices für SQL Server-Indexschlüsselspalten anwenden
Da Sie mehrere Spalten in einer Tabelle haben können, sind hier einige Überlegungen zu Indexschlüsselspalten.
- Spalten mit text, image, ntext, varchar(max), nvarchar(max) und varbinary(max) können nicht in den Indexschlüsselspalten verwendet werden.
- Es wird empfohlen, einen ganzzahligen Datentyp in der Indexschlüsselspalte zu verwenden. Es hat einen geringen Platzbedarf und arbeitet effizient. Aus diesem Grund sollten Sie die Primärschlüsselspalte normalerweise auf einem ganzzahligen Datentyp erstellen.
- Sie können den XML-Datentyp nur in einem XML-Index verwenden.
- Sie sollten erwägen, einen Primärschlüssel für die Spalte mit eindeutigen Werten zu erstellen. Wenn eine Tabelle keine eindeutigen Wertspalten hat, können Sie eine Identitätsspalte für einen ganzzahligen Datentyp definieren. Ein Primärschlüssel erstellt auch einen gruppierten Index für die Zeilenverteilung.
- Sie können eine Spalte mit den Werten Unique und Not NULL als nützlichen Indexschlüsselkandidaten betrachten.
- Sie sollten einen Index basierend auf den Prädikaten in der Where-Klausel erstellen. Beispielsweise können Sie Spalten berücksichtigen, die in der Where-Klausel, SQL-Joins, like, order by, group by Prädikaten usw. verwendet werden.
- Sie sollten Tabellen so verknüpfen, dass die Anzahl der Zeilen für den Rest der Abfrage reduziert wird. Dies hilft dem Abfrageoptimierer, den Ausführungsplan mit minimalen Systemressourcen vorzubereiten.
- Wenn Sie mehrere Spalten für einen Indexschlüssel verwenden, ist es auch wichtig, ihre Position im Indexschlüssel zu berücksichtigen.
- Sie sollten auch erwägen, enthaltene Spalten in Ihren Indizes zu verwenden.
5. Analysieren Sie die Datenverteilung Ihrer SQL Server-Indexspalten
Sie sollten die Datenverteilung in den SQL Server-Indexschlüsselspalten untersuchen. Eine Spalte mit nicht eindeutigen Werten kann eine Verzögerung beim Abrufen der Daten verursachen und zu einer lang andauernden Transaktion führen. Sie können die Datenverteilung mithilfe des Histogramms in der Statistik analysieren.
6. Sortierreihenfolge der Daten verwenden
Sie sollten auch die Datensortierungsanforderungen in Ihren Abfragen und Indizes berücksichtigen. Standardmäßig sortiert SQL Server Daten in einem Index in aufsteigender Reihenfolge. Angenommen, Sie erstellen einen Index in aufsteigender Reihenfolge, aber Ihre Abfragen verwenden die Order By-Klausel, um Daten in absteigender Reihenfolge zu sortieren.
Sehen Sie sich beispielsweise den tatsächlichen Ausführungsplan der folgenden Abfrage an.
SELECT [SalesOrderID],
[UnitPrice]
FROM [AdventureWorks].[Sales].[SalesOrderDetail]
ORDER BY UnitPrice DESC,
SalesOrderID ASC;
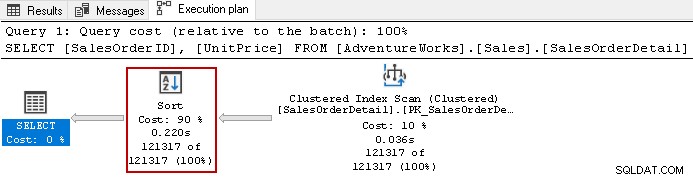
Es verwendet den teuren Sortieroperator mit einem Gesamtaufwand von 90 % in dieser Abfrage. Wir haben uns entschieden, einen nicht geclusterten Index für [UnitPrice] und [SalesOrderID] zu erstellen. Es verwendet eine Standardsortierreihenfolge für beide Spalten im Index.
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice
ON [AdventureWorks].[Sales].[SalesOrderDetail]
(UnitPrice ASC, SalesOrderID ASC);
Wir haben die Select-Anweisung erneut ausgeführt und der Abfrageoptimierer verwendet immer noch den Sortieroperator. Es kann den nicht geclusterten Index verwenden, sortiert aber die Daten, um das Ergebnis vorzubereiten.
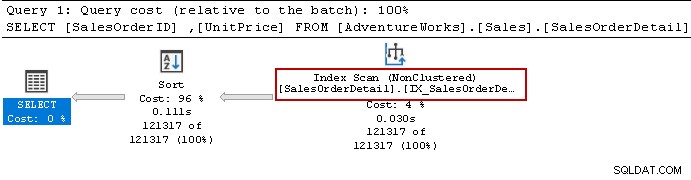
Lassen Sie uns den Index mit der folgenden Abfrage neu erstellen. Dieses Mal werden die Daten in absteigender Reihenfolge für [Unitprice] in der Indexdefinition sortiert.
DROP INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail];
Go CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_Unitprice ON [AdventureWorks].[Sales].[SalesOrderDetail](UnitPrice DESC, SalesOrderID ASC);
Go
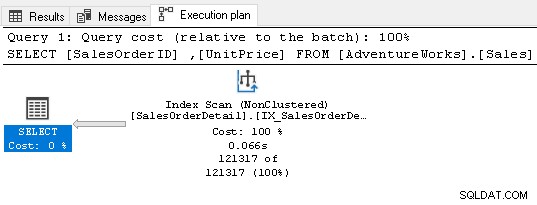
Es erfordert jetzt keinen Sortieroperator, da der Index die Abfrageanforderungen erfüllt.
7. Verwenden Sie Fremdschlüssel für Ihren SQL Server-Index
Sie sollten einen Index für die Fremdschlüsselspalten erstellen. Es ist ratsam, einen gruppierten Index für den Fremdschlüssel zu erstellen, um die Abfrageleistung zu verbessern.
8. Beachten Sie die Überlegungen zur Indexspeicherung in SQL Server
Die Indexspeicherung ist ebenfalls ein nützlicher Aspekt, den es zu berücksichtigen gilt. SQL Server erstellt alle Indizes für dieselbe Dateigruppe der Tabelle. Sie können eine separate Dateigruppe für Indizes in Betracht ziehen und die physische Datei auf einem separaten Datenträger trennen. Dadurch werden die E/A-Leistung und der Durchsatz erhöht.
Auf ähnliche Weise können Sie die Tabellenpartitionierung verwenden, um Daten über mehrere Datenträger und Dateigruppen hinweg zu trennen. Sie können partitionierte Indizes für diese Tabellenpartitionen entwerfen, um den gleichzeitigen Datenzugriff zu verbessern.
Eine andere Möglichkeit besteht darin, den FILLFACTOR beim Erstellen oder Neuerstellen eines Index zu definieren. Ein FILLFACTOR definiert den freien Platz in den Datenseiten der Blattknoten. Es ist nützlich für weitere Dateneinfügungen. Wenn Ihre Daten statisch sind und sich nicht häufig ändern, können Sie einen hohen Wert für FILLFACTOR in Betracht ziehen. Andererseits können Sie bei sich häufig ändernden Daten genug Platz für neue Dateneinfügungen lassen.
9. Fehlende Indizes finden
Manchmal erhalten Sie Informationen über einen fehlenden SQL Server-Index im Abfrageausführungsplan. Sie können auch die dynamischen Verwaltungsansichten ausführen, um diese fehlenden Indizes zu finden. Sie sollten diese Indizes nicht blind erstellen. Es handelt sich lediglich um einen Vorschlag des Abfrageoptimierers, der jedoch weder den vorhandenen Index noch Ihre Workload-Anforderungen berücksichtigt. Es kann auch mehrere Spalten in der Indexdefinition enthalten, also überprüfen Sie diese Vorschläge, bevor Sie sie implementieren.
10. Erstellen Sie einen geclusterten Index immer vor einem nicht geclusterten Index
Als allgemeine Richtlinie sollten Sie einen gruppierten Index erstellen, bevor Sie nicht gruppierte Indizes erstellen. Wenn eine Tabelle keinen Index hat, besteht ein nicht gruppierter Index aus Zeilenbezeichnern. Nachdem Sie einen gruppierten Index erstellt haben, muss SQL Server diese nicht gruppierten Indizes neu erstellen, damit sie auf den Schlüssel des gruppierten Index statt auf die Zeilenbezeichner verweisen können.
11. Indexpflege überwachen und Statistiken aktualisieren
Im Folgenden sind einige Wartungsbereiche aufgeführt, die Sie überwachen sollten, wenn es um SQL Server-Indizes geht.
- Indexfragmentierung entfernen :Sie sollten regelmäßig interne und externe Fragmentierungen überprüfen, insbesondere bei Tabellen mit hohen Transaktionszahlen. Ihre Abfragen reagieren möglicherweise langsam, selbst wenn Sie über geeignete Indizes für Ihre Workloads verfügen. Ein stark fragmentierter Index kann die Leistung beeinträchtigen, da er zusätzliche E/A erfordert. Sie können eine Reorganisation durchführen oder einen Index auf der Grundlage seiner Fragmentierungswerte neu erstellen. Normalerweise sollten Sie den Index neu erstellen, wenn er eine Fragmentierung von mehr als 30 % aufweist, und ihn neu organisieren, wenn er eine Fragmentierung von weniger als 30 % aufweist.
- Nicht verwendete Indexe entfernen: Sie sollten die ungenutzten (leeren) Indizes in Ihrer Datenbank immer überprüfen, da der Abfrageoptimierer sie für jede Abfrage berücksichtigen muss. Ein ungenutzter Index verbraucht außerdem Speicherplatz und erhöht den Wartungsaufwand.
- Statistiken aktualisieren: Sie sollten die Statistiken regelmäßig aktualisieren, selbst wenn Sie die automatische Aktualisierung der Statistiken in Ihrer Datenbankkonfiguration eingestellt haben. Der Abfrageoptimierer bereitet möglicherweise einen fehlerhaften Ausführungsplan vor, wenn die Indexstatistiken nicht aktualisiert werden. Sie können einen Agent-Job planen, um die SQL Server-Statistiken mit einem vollständigen Scan nach Geschäftszeiten zu aktualisieren.
Weitere Informationen zu diesem Thema finden Sie unter SQL-Indexpflege .
Best Practices für SQL Server-Indizes anwenden
Obwohl es nicht immer eine einfache Möglichkeit gibt, einen optimalen SQL Server-Index zu entwerfen, hilft Ihnen die Anwendung der in diesem Beitrag angegebenen Empfehlungen, die unterschiedlichen Indexierungsanforderungen zu bewältigen, denen Sie bei jedem Datenbanktyp und seinen Workloads begegnen werden. Diese Best Practices helfen Ihnen, Ihre Indexe zu optimieren, um die Datenbankleistung zu verbessern und dabei einen reibungsloseren Leistungsoptimierungsprozess zu gewährleisten.